Introduction to Topic Modelling in NLP
Overview
Topic modeling is a collection of text-mining techniques that uses statistical and machine learning models to automatically discover hidden abstract topics in a collection of documents.
Topic modeling is also an amalgamation of a set of unsupervised techniques that’s capable of detecting word and phrase patterns within documents and automatically cluster word groups and similar expressions helping in best representing a set of documents.
Introduction to Topic Modeling in NLP
There are many cases where humans or machines generate a huge amount of text over time and it is not prudent nor possible to go through the entire text for gaining an understanding of what is important or to come to an opinion of the entire process of generating the data.
In such cases, NLP algorithms and in particular topic modeling are useful to extract a summary of the underlying text and discover important contexts from the text.
The Objective of Topic Modeling
The main objective of topic modeling NLP is to discover topics that are a cluster of words expressed as a combination of strongly related words.
Since each topic belongs to one or more documents, one other objective is to in turn express each document as a combination of one or more balanced topics.
The Curse of Dimensionality
Curse of Dimensionality (CoD): The phenomenon of CoD states that as we add more features to the model, the amount of data needed to train the model to maintain the same performance increases exponentially.
- Dimensions are features in the context of NLP & ML models.
- This is especially important when training machine learning algorithms where, the accuracy of the model initially increases as the number of features is increased but starts worsening as the dimensionality is increased keeping data constant due the to curse of dimensionality.
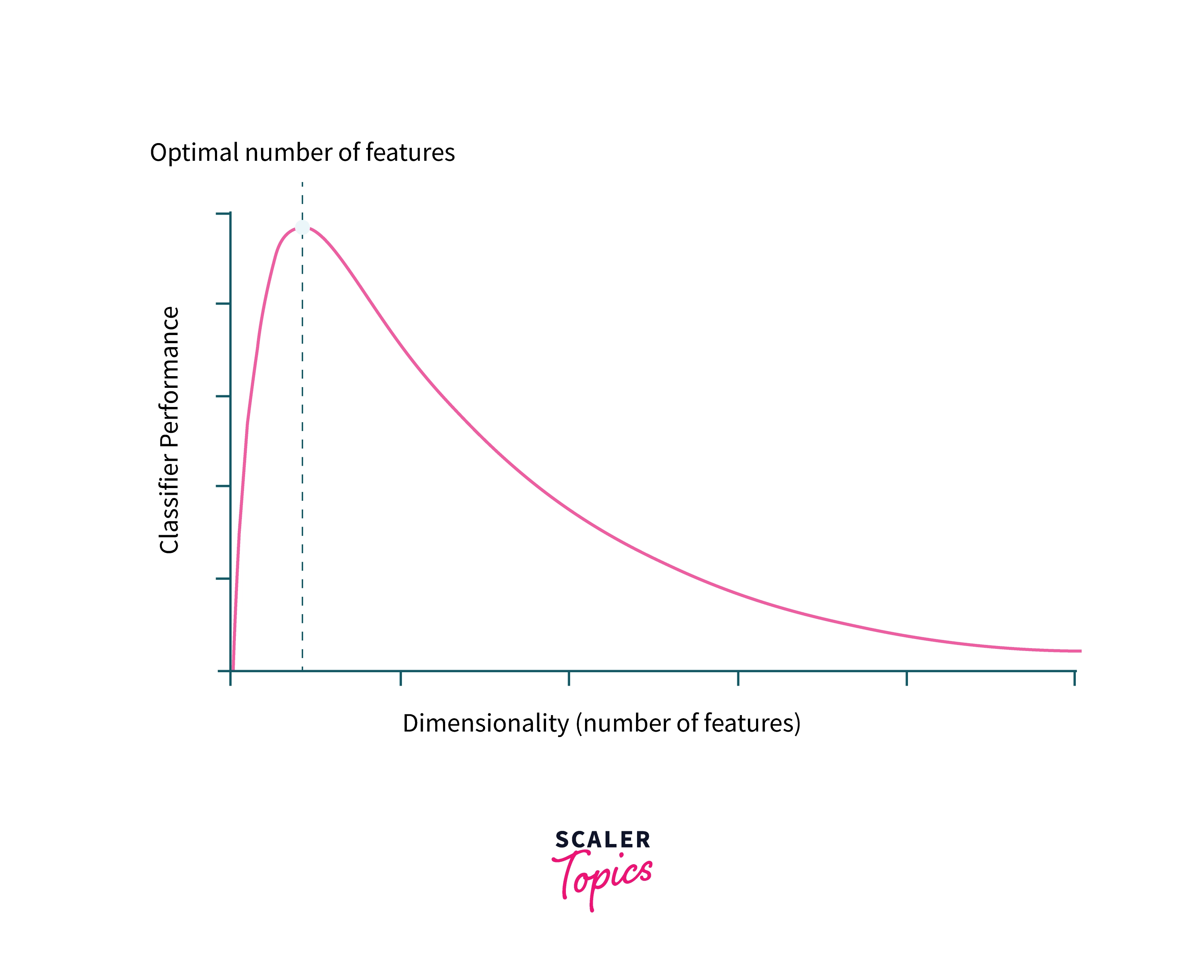
Curse of dimensionality is especially important in the case of topic modeling based NLP models as we have a huge number of features owing to a huge corpus of words. Hence it is necessary to employ feature selection or dimensionality reduction techniques when handling models with huge dimensionality which we will see further.
How does Topic Modeling in NLP work?
When looking at a set of documents, each document can be a combination of multiple opinions or ideas where words pertaining to that particular opinion are found in different proportions across documents. We can look at the statistics of words in each document and create topics which are clusters of similar words.
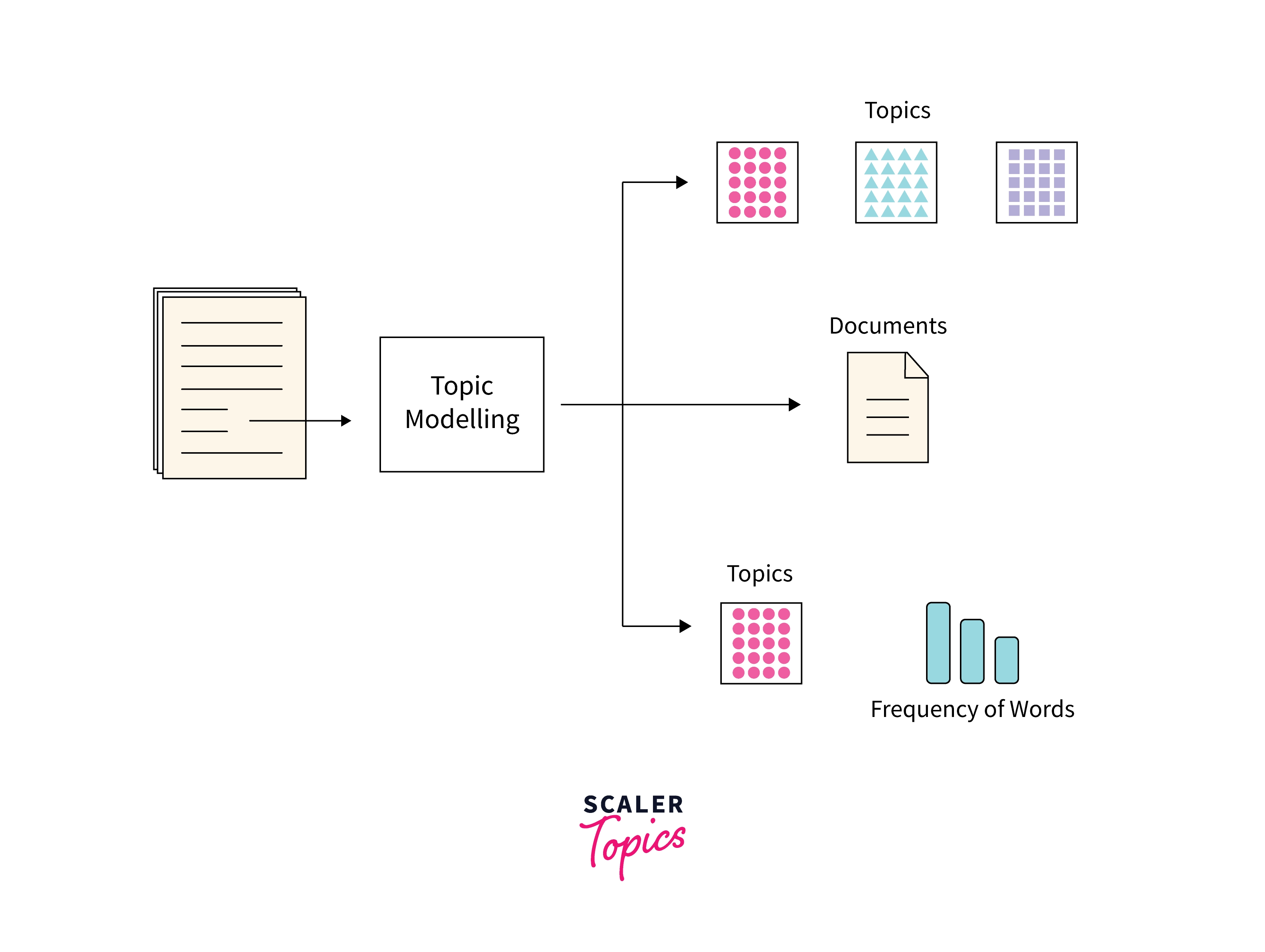
Topic models help us in discovering potential topics hidden in the entire text of documents as a combination of words with similar meanings and each given document as combination of topics.
PCA
Introduction to PCA
Principal Component Analysis (PCA) is a statistical technique where the main idea is to reduce the dimensionality of a data set consisting of a large number of interrelated variables, while retaining as much as possible of the variation present in the data set.
Working of PCA algorithm:
- Transform the columns in the data set to a new set of variables called the principal components (PCs).
- The main property of PCs is that they are uncorrelated, and can be ordered based on their characteristic values so that we can first few PC's alone while retaining most of the variation present in all of the original variables.
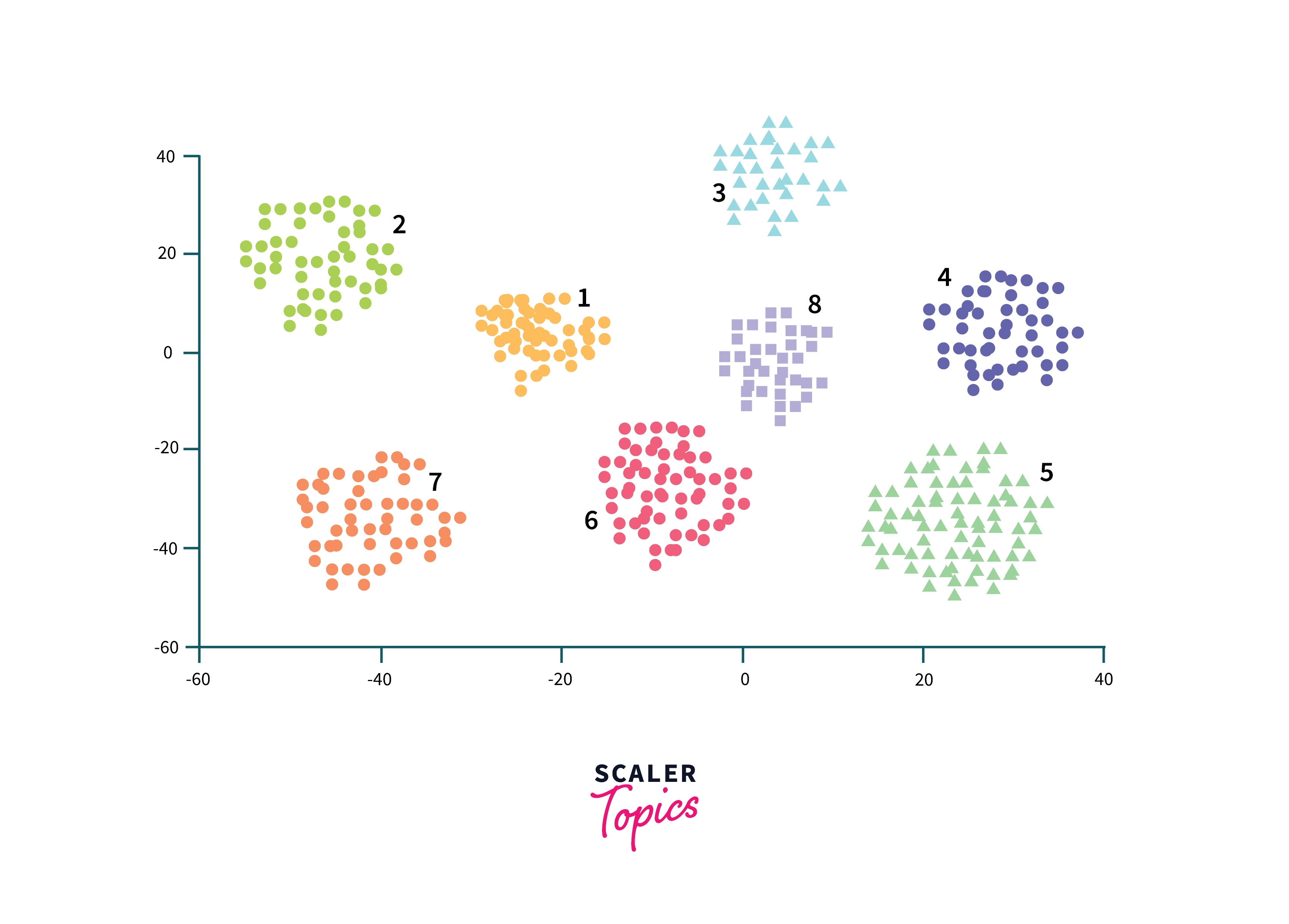
The colors in the illustration represent the labels of target variables/groups/clusters in the dataset, axes represent the first two principal components obtained using PCA.
Advantages of PCA:
- PCA is a versatile and widely used technique for pre-processing in machine learning.
- PCA helps in speeding up the model training & evaluation time as it reduces the number of input variables considerably.
- PCA also helps in improving the accuracy of the models in treating the curse of dimensionality and also saves the space needed to store the data with minimal loss.
As it also serves the purpose of analyzing the data by visualizing a huge number of dimensions in 2D or 3D space along with their labels, it is widely used in multiple techniques for EDA and post-model explanation.
Introduction to Clustering
Clustering is an unsupervised machine learning technique for finding subgroups or clustering clusters in a data set.
- Central idea in clustering: Partition the observations in a data set into different distinct groups such that observations within each group are quite similar to each other and those in different groups are quite different from each other.
- We need to select suitable criteria for defining the similarity between observations and there are multiple techniques available for cluster analysis.
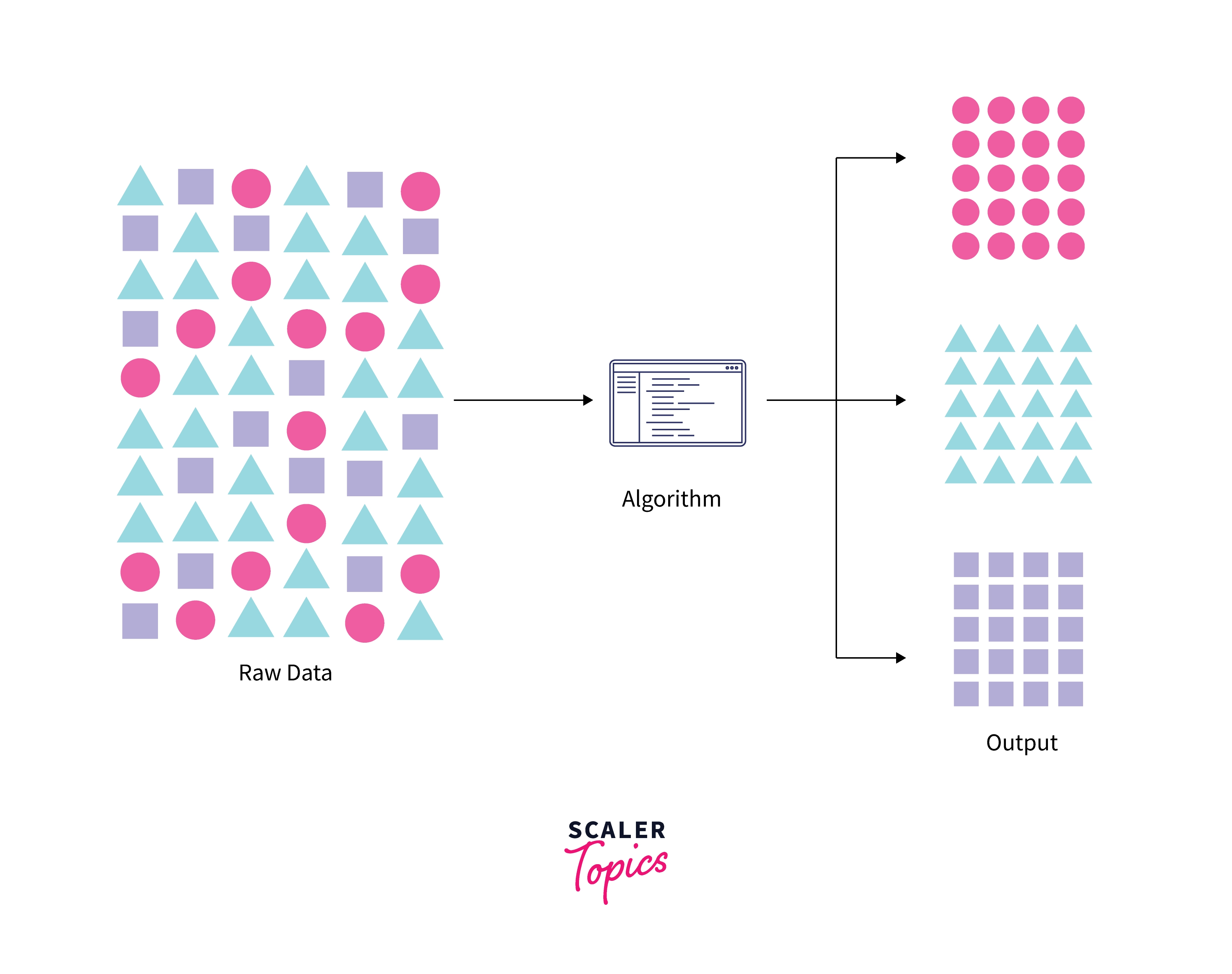
Clustering by rows vs columns:
- We can cluster observations on the basis of the features in order to identify subgroups among the observations
- We can also cluster features on the basis of the observations in order to discover subgroups among the columns (grouping features together).
Clustering is used majorly for marketing for market segmentation and in some other areas of computer vision.
Is Topic Modeling, Clustering, and PCA the Same?
All three algorithms, topic modeling, clustering, and PCA are unsupervised and used to simplify the data set with a small number of summaries, the major difference lies in how they are used:
- LDA (topic modeling) and PCA both can be used for dimensionality reduction but LDA provides better accuracies and explainability in terms of text.
- PCA looks to find a low-dimensional representation of the observations that explain a good fraction of the variance. Since output representations are unrelated, they can also be used as input to clustering.
- Clustering looks to find homogeneous subgroups among the observations by maximizing the distance between clusters, clusters are not known in advance.
Non-Negative Matrix Factorization
NMF is a technique for decomposing a matrix into two matrices with the property that all three matrices have no negative elements. This is used majorly in recommender systems, signal processing, and bioinformatics fields.
The central idea in NMF is that original input matrix is made of a set of hidden features represented which are essentially interactions between two (usually) matrices (like users and movies) and the associations are the weights in the input matrix.
One advantage of Non-negative Matrix Factorization is that we can find which interactions are potentially gonna happen or rank them (like for use in recommender systems).
LDA - Latent Dirichlet Allocation
Topic modeling in NLP using LDA discovers topics that are hidden (hence the name latent) in a set of text documents by inferring possible topics based on the words in the documents.
- In Latent Dirichlet Allocation, the relationships between each text document and each word, each topic, and words in the corpus are modeled using hidden variables
- Each document within the corpus is represented using a Dirichlet distribution over the latent variables (topics) and each topic is again represented by another Dirichlet Distribution over all the words contained in all the documents.
- The overall model LDA is based on Bayesian framework with a generative probabilistic model trained on Dirichlet distributions in LDA. With the Bayesian assumption, we can model the topics based on observed data (words) through the use of conditional probabilities on the words.
Advantages of LDA
- Latent Dirichlet Allocation (LDA) is the most popular approach for topic modeling among all other varieties of applications.
- It has good support and is implemented in a variety of frameworks like Python, R, Java, C and very easy to deploy.
Implementation of Topic Modeling Using LDA
When using LDA for topic modeling NLP, we take bag of words as input matrix since it is a probabilistic model. The algorithm then decomposes the matrix into two smaller matrices:
- A document to topic matrix and a word to topic matrix.
- These two matrices are optimized such that when multiplied together, it then reproduces the bag of words matrix with the lowest error.
Since each topic is a combination of words, each keyword contributes some weightage to each topic. Let us implement LDA with one of the popular implementations in scikit-learn.
LSA – Latent Semantic Allocation
LSA is a technique for topic modeling in NLP and also dimensionality reduction that uses the concept of distributional semantics, words that are similar in meaning occur together.
We discover the hidden (latent) concepts in document data by expressing the words in each document as term document matrix (vector representation of text), converting into the of-IDF matrix, and then decomposing it into a separate document-topic matrix and a topic-term matrix using Singular Value Decomposition.
This way documents and terms are broken into their low-rank vector representations so that document-document, document-term, or term-term similarities or semantic relationships which are otherwise hidden can be computed using the latent semantic dimensions.
Once main difference with other topic modeling NLP algorithms is that in the latent semantic space, a query and a document can have high cosine similarity even if they do not share any terms - as long as their terms are semantically similar in a sense to be described later.
PLSA – Probabilistic Latent Semantic Analysis
When comparing with LSA, Probabilistic Latent Semantic Analysis (LSA) uses a probabilistic method instead of SVD for decomposition.
- The idea is to find a probabilistic model with latent topics that can generate the data we observe in our document-term matrix.
- In particular, we want a model P(D,W) such that for any document d and word w, P(d,w) corresponds to that entry in the document-term matrix.
When compared with the intuition of topic models where each document is a combination of multiple topics, and each topic as a collection of words, LSA adds a probabilistic element to these assumptions:
- Given a document d, topic z is present in that document with probability P(z|d)
- Given a topic z, word w is drawn from z with probability P(w|z)
lda2vec – Deep Learning Model
lda2vec is a topic modeling NLP algorithm that builds representations over both words and documents by mixing word2vec’s skip-gram architecture with Dirichlet-optimized sparse topic mixtures.
- With lda2vec, instead of using the word vector directly to predict context words, we leverage a context vector to make the predictions.
- The context vector is created as the sum of the word vectors and the document vectors.
- The word vector is generated by skip-gram architecture whereas the document vector is a combination of document weight vector representing the weights of each topic in the document and the topic matrix representing each topic and its corresponding vector embedding.
lda2vec is hybrid and powerful as it combinedly learns word embeddings (and context vector embeddings) for words, and simultaneously learns topic representations and document representations as well which are easily understandable.
tBERT – Topic BERT
Bert is another topic modeling NLP model for topic modeling in NLP combining topics (in models like LDA) with pretrained contextual representations such as BERT.
- It is shown that combining typical topic modeling NLP-based models like LDA with Bert Base improves performance over strong neural baselines across a variety of English language datasets.
- It is also shown that the addition of topics to BERT helps particularly with resolving domain specific cases very well.
Topic Modeling vs Topic Classification
The main difference is that topic modeling is unsupervised whereas topic classification is supervised and needs hand-crafted data:
- Topic modeling is preferred when there is not a lot of time to analyze texts and there is no need for fine-grained analysis and we need a few topics of what texts are talking about.
- Topic classification on the other hand is preferred when there is a list of automatically defined topics for a set of texts and the need to label them automatically and accurately without reading each document text.
Use Cases & Applications of Topic Modeling
- Topic Modeling using NLP is ubiquitously used in the industry in important fields such as the medical industry, and scientific research understanding to answer big-picture questions quickly, cheaply, and without human intervention.
- Once the models are trained, they provide a framework for humans to understand document collections both directly by reading models or indirectly by using topics as input variables for further analysis in sentiment analysis, understanding reports, and text summarization tasks.
- Topic models are also used in novel applications like recommender systems, chatbots, search, and virtual assistants in use cases like query expansion of search engines, for handling customer service, feedback, etc.
Conclusion
- Topic modeling in NLP is a set of algorithms that can be used to summarise automatically over a large corpus of texts.
- Curse of dimensionality makes it difficult to train models when the number of features is huge and reduces the efficiency of the models.
- Latent Dirichlet Allocation is an important decomposition technique for topic modeling in NLP that can automatically discover hidden topics from documents.
- Principal Component Analysis is a dimensionality reduction technique for helping with the curse of dimensionality and visually understanding data to separate noise from the signal.
- Clustering is another unsupervised technique to discover grouping from features or observations.
- Both topic modeling and dimensionality reduction can be implemented with a variety of algorithms like Non-negative Matrix Factorization, LSA – Latent Semantic Allocation, PLSA – Probabilistic Latent Semantic Analysis, lda2vec – deep learning model, Bert – Topic BERT.
- Topic modeling is a versatile algorithm used in different use cases across the industry.