Advanced Topics in Transformers
Overview
Transformers have revolutionized the world of natural language processing and beyond, setting new benchmarks in tasks ranging from language translation to image recognition. Initially designed for sequence-to-sequence tasks, these architectures have demonstrated unparalleled prowess due to their self-attention mechanisms. As research progresses, various advanced topics surrounding transformers have emerged, delving deeper into optimization, model variants, efficiency, and applications beyond NLP. This article will traverse these advanced terrains, offering insights into the current frontier of transformer models and hinting at the vast potential that awaits in the AI landscape.
Introduction
The transformative era of deep learning introduced many models, but none have been as influential as the Transformer architecture. First introduced in the paper "Attention is All You Need" by Vaswani et al., transformers signaled a departure from recurrent neural networks, focusing instead on self-attention mechanisms to process input data in parallel rather than sequentially. This fundamental shift brought forth rapid advancements, not just in terms of model performance but also in how we perceive and tackle complex problems in AI. As we delve deeper, we'll unearth advanced facets of transformers, exploring nuances, challenges, and cutting-edge adaptations that continue to redefine the boundaries of what's possible.
Transfer Learning and Pre-trained Transformers
Transfer learning is a powerful machine learning technique that has taken the transformer world by storm. It involves leveraging the knowledge acquired from a previously trained model on a large dataset to solve a different yet somewhat related task without starting the learning process from scratch. With the computational cost of training transformers, transfer learning offers a cost-effective and efficient solution, especially for tasks with limited data.
Pre-trained transformers, such as BERT, GPT-2, and T5, have emerged as popular choices in various NLP tasks. These models are trained on massive text datasets and can be fine-tuned for specific tasks like sentiment analysis, text classification, or question-answering. After being trained on large-scale data, the underlying idea is that these models capture the intricacies of language, which can be repurposed with minimal adjustments for specific tasks. This section will delve into the intricacies of transfer learning, its importance in transformer architecture, and the utilization of pre-trained models for different NLP challenges.
Transformer Variants and Architectures
The success of the initial transformer architecture has spurred a plethora of variants, each tailored to address specific challenges or improve upon the original design. These variants have broadened the horizon for tasks transformers can tackle, from pure language tasks to more visually oriented applications.
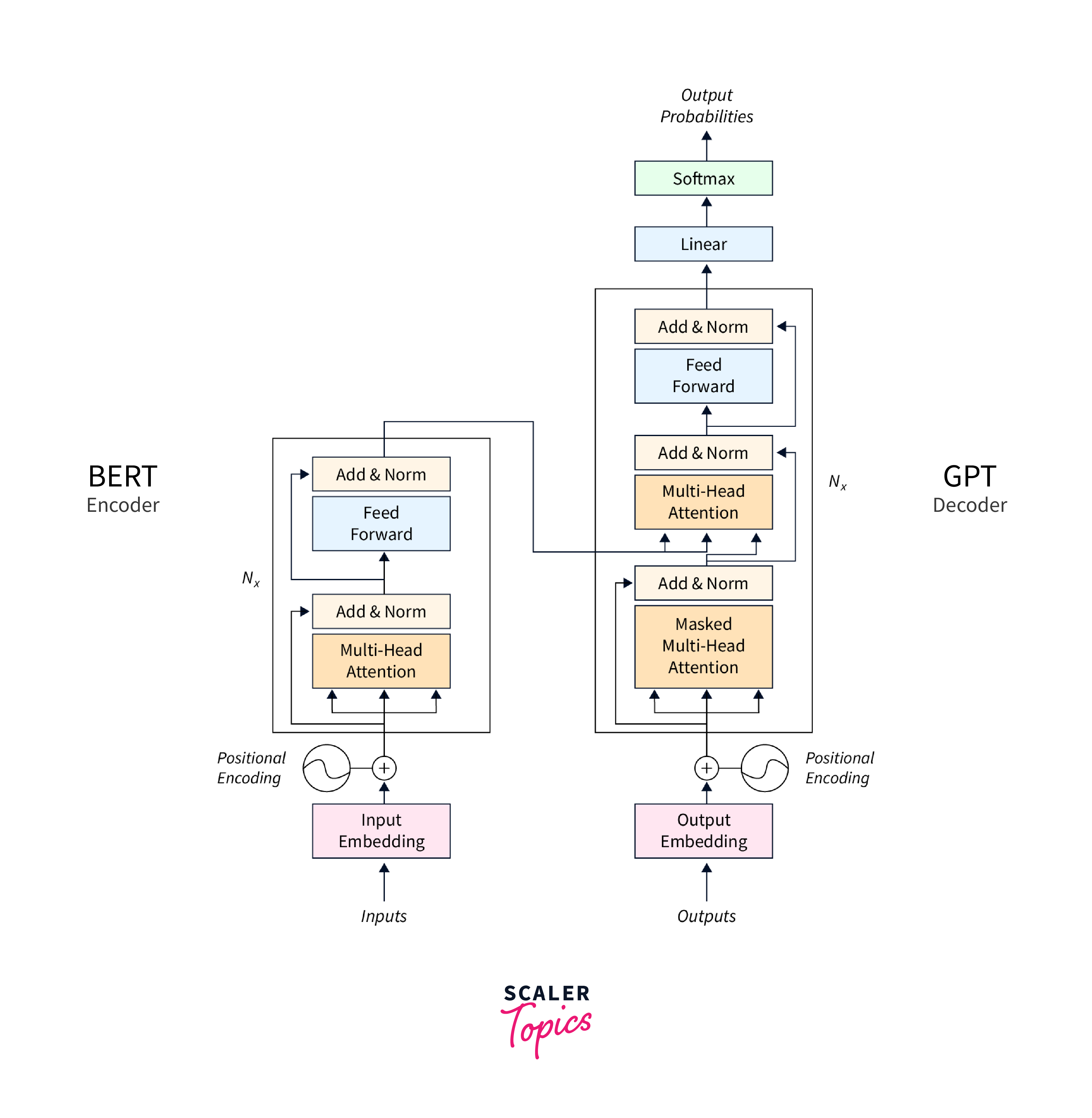
- BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT revolutionized NLP tasks by training bidirectionally, allowing it to understand the context from both the left and right of a word in a sentence.
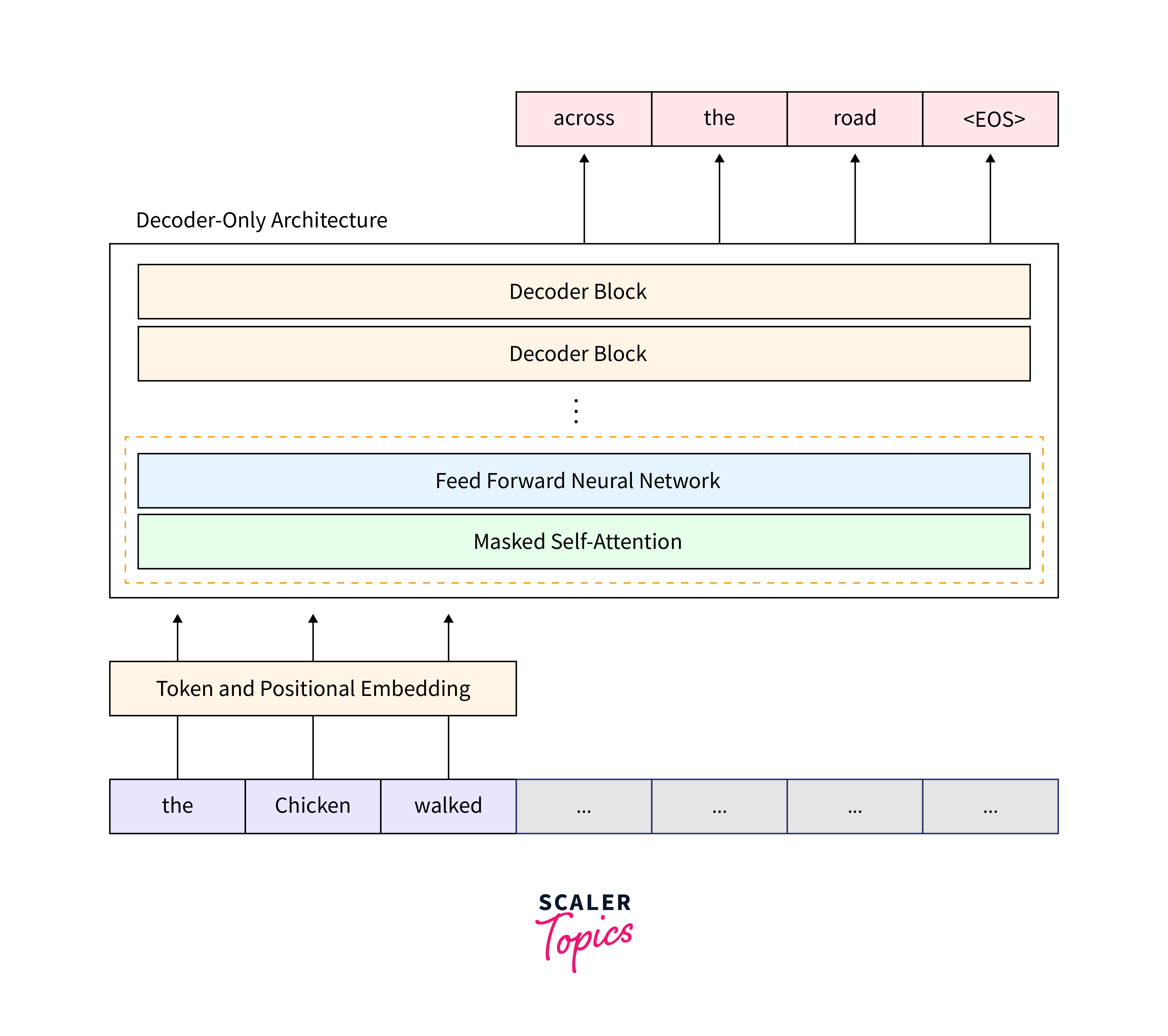
- GPT (Generative Pre-trained Transformer): OpenAI's GPT models focus on a left-to-right training approach and have shown immense potential in generation tasks.
- T5 (Text-to-Text Transfer Transformer): Instead of designing a specific model for each task, T5 treats every NLP problem as a text-to-text problem, making it incredibly versatile.
![]()
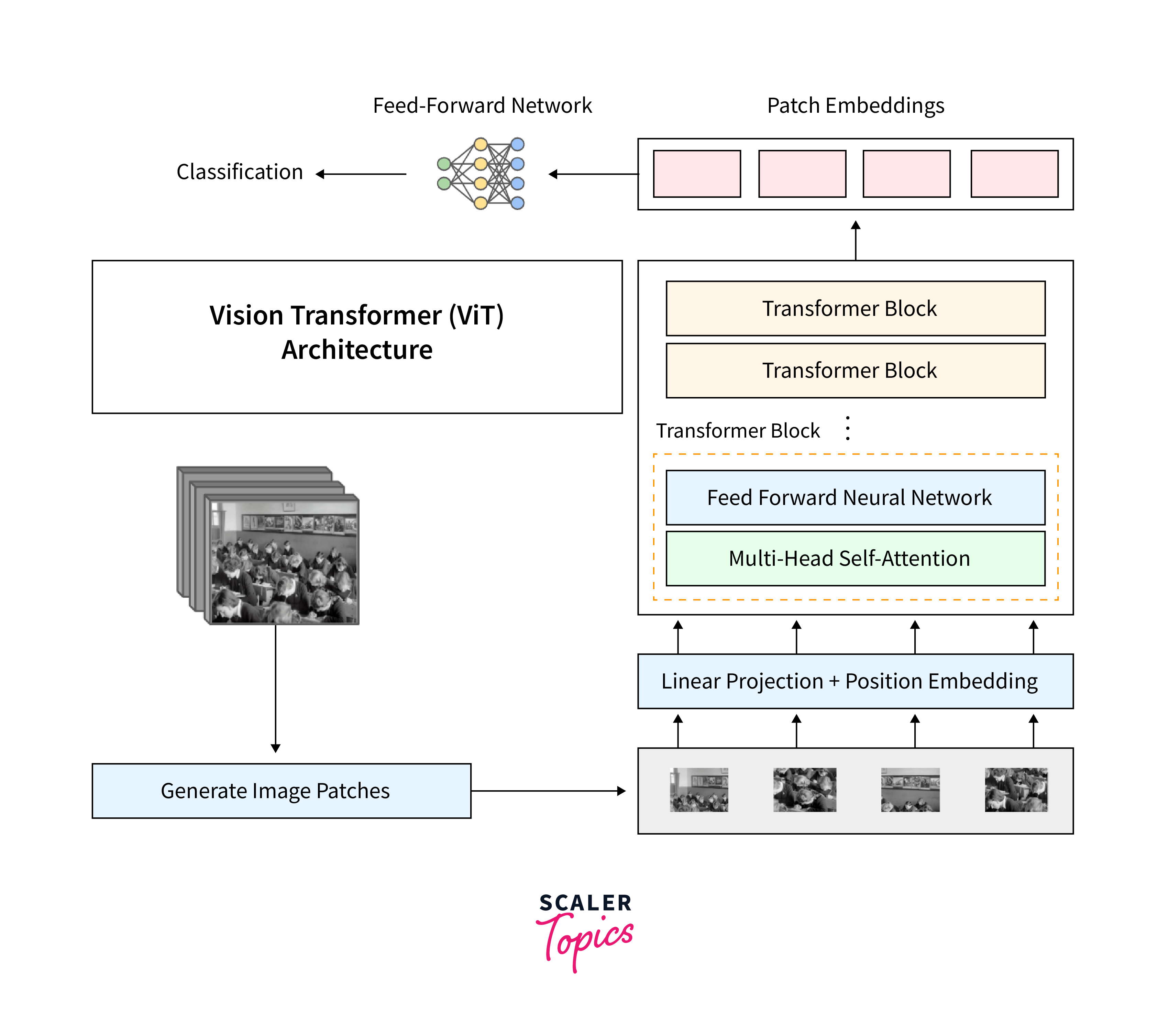
- Vision Transformers (ViTs): Moving beyond text, ViTs divide images into fixed-size patches, linearly embed them, and then process them sequentially, proving that transformers can be potent for computer vision tasks.
-
RoBERTa, DistilBERT, and ALBERT are refinements of BERT, with tweaks in training strategies, model size, and data volume to optimize performance and efficiency.
-
Longformer and Linformer: These variants address the limitation of transformers in processing long sequences, making them more suitable for tasks like document classification or coreference resolution.
| Model Architecture | Parameter Size | Language Generation Quality | Computational Requirements | Few-Shot and Zero-Shot Learning |
|---|---|---|---|---|
| BERT | Moderate | High | Moderate | Limited |
| GPT | Large | High | High | Limited |
| T5 | Large | High | High | Moderate |
| Vision Transformers (ViTs) | Varies | High | Varies | Limited |
| RoBERTa, DistilBERT, ALBERT | Moderate | High | Moderate | Limited |
| Longformer, Linformer | Moderate | Moderate | Moderate | Limited |
This section will dissect these architectures, discussing their unique features, training strategies, and their respective strengths and weaknesses in various applications.
Multimodal Transformers
Multimodal Transformers mark a paradigm shift in AI, aiming to process and generate information across multiple modalities, primarily text and images, in a unified manner. These models acknowledge the interconnected nature of real-world data and aspire to provide more contextually enriched outcomes.
- ViLBERT (Vision-and-Language BERT): ViLBERT incorporates dual streams of transformers - one for vision and another for language. These streams interact at intermediate levels, allowing for mutual context enrichment.
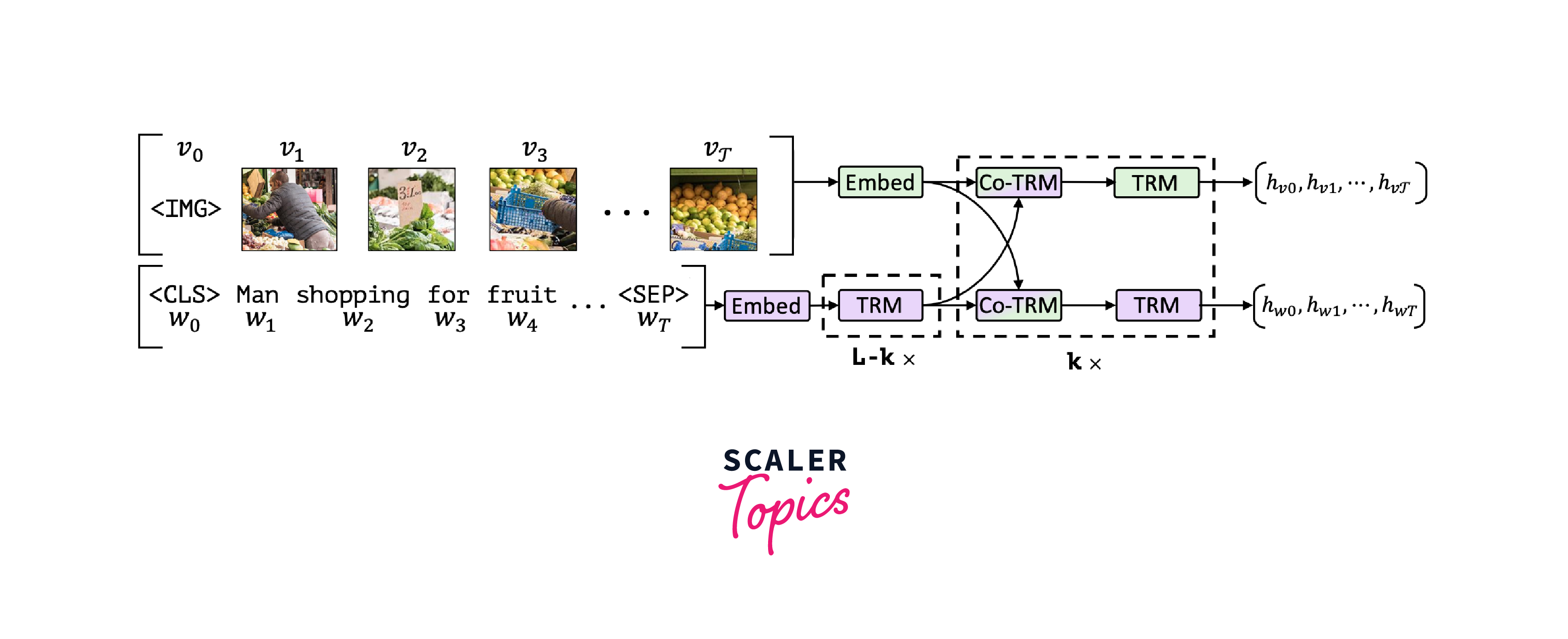
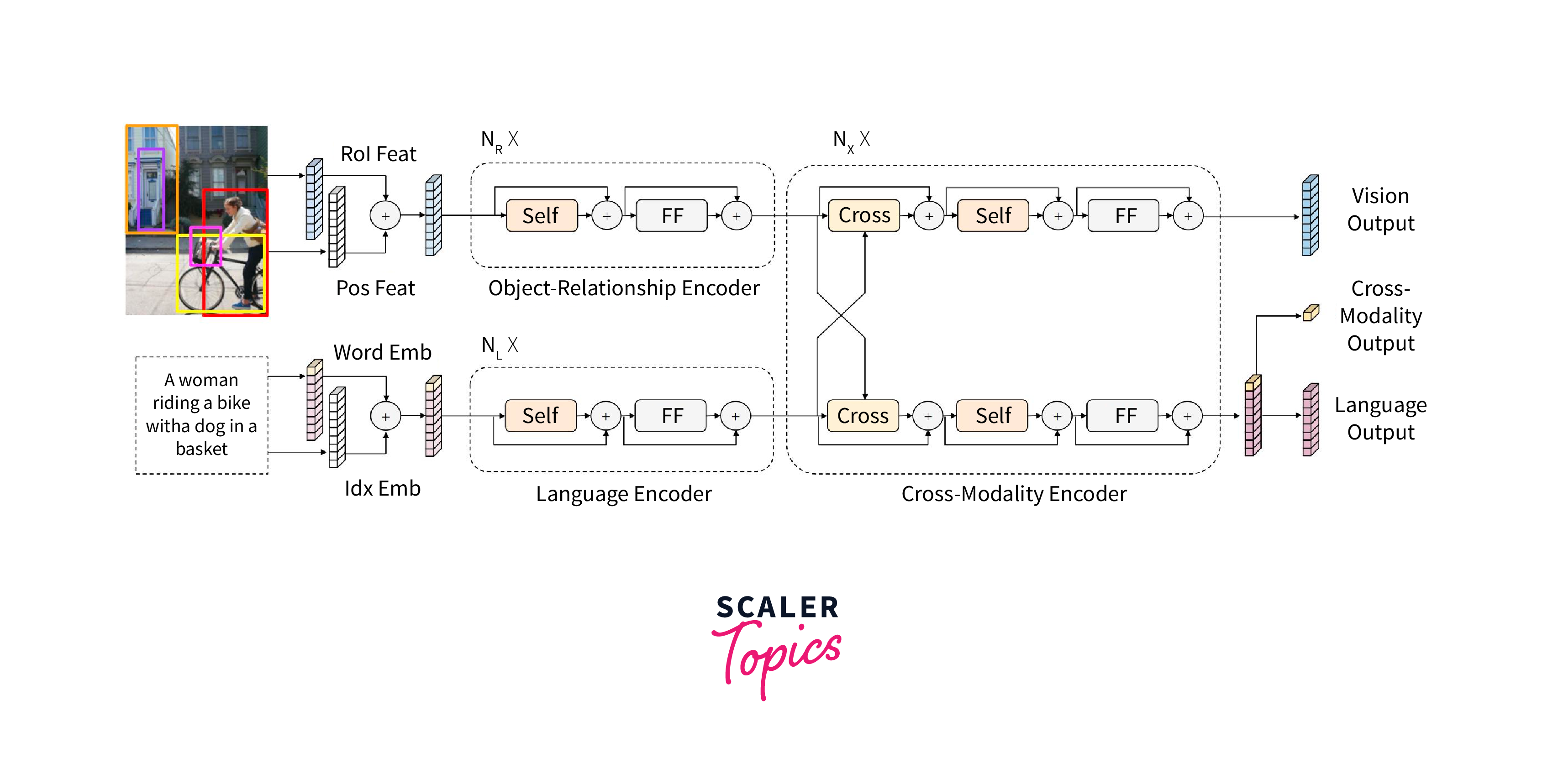
- LXMERT (Learning Cross-Modality Encoder Representations from Transformers): LXMERT also employs a dual-stream approach but integrates a larger number of cross-attention layers, making it particularly adept at tasks like visual question answering.
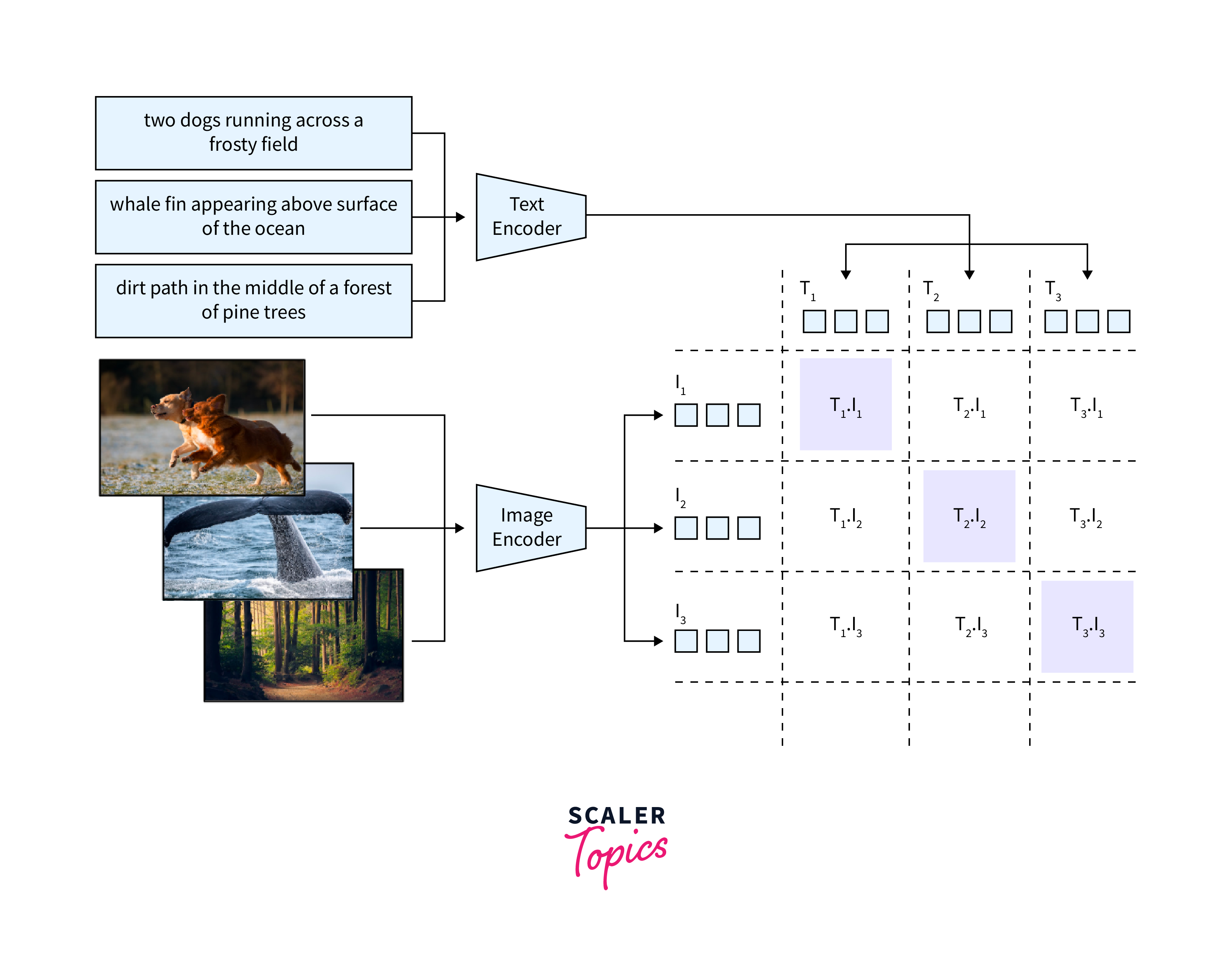
- CLIP (Contrastive Language–Image Pre-training): Introduced by OpenAI, CLIP leverages a contrastive objective to understand visual concepts from natural language supervision. It can learn visual concepts from any internet text, making it highly versatile.
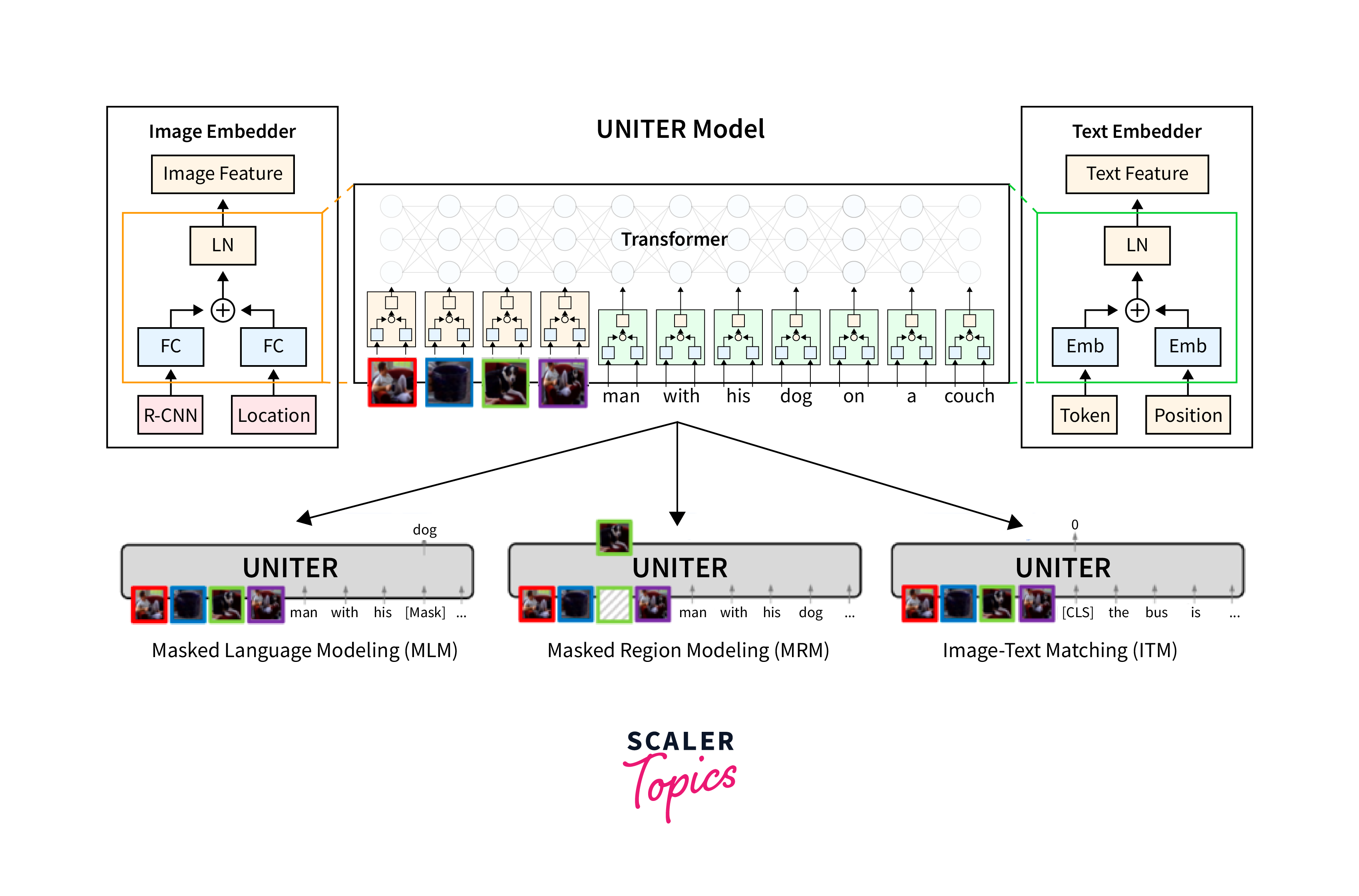
- UNITER (UNiversal Image-TExt Representation learning): UNITER pretrains on several vision-and-language tasks simultaneously, incorporating a wide variety of data to create a well-rounded, multifaceted model.
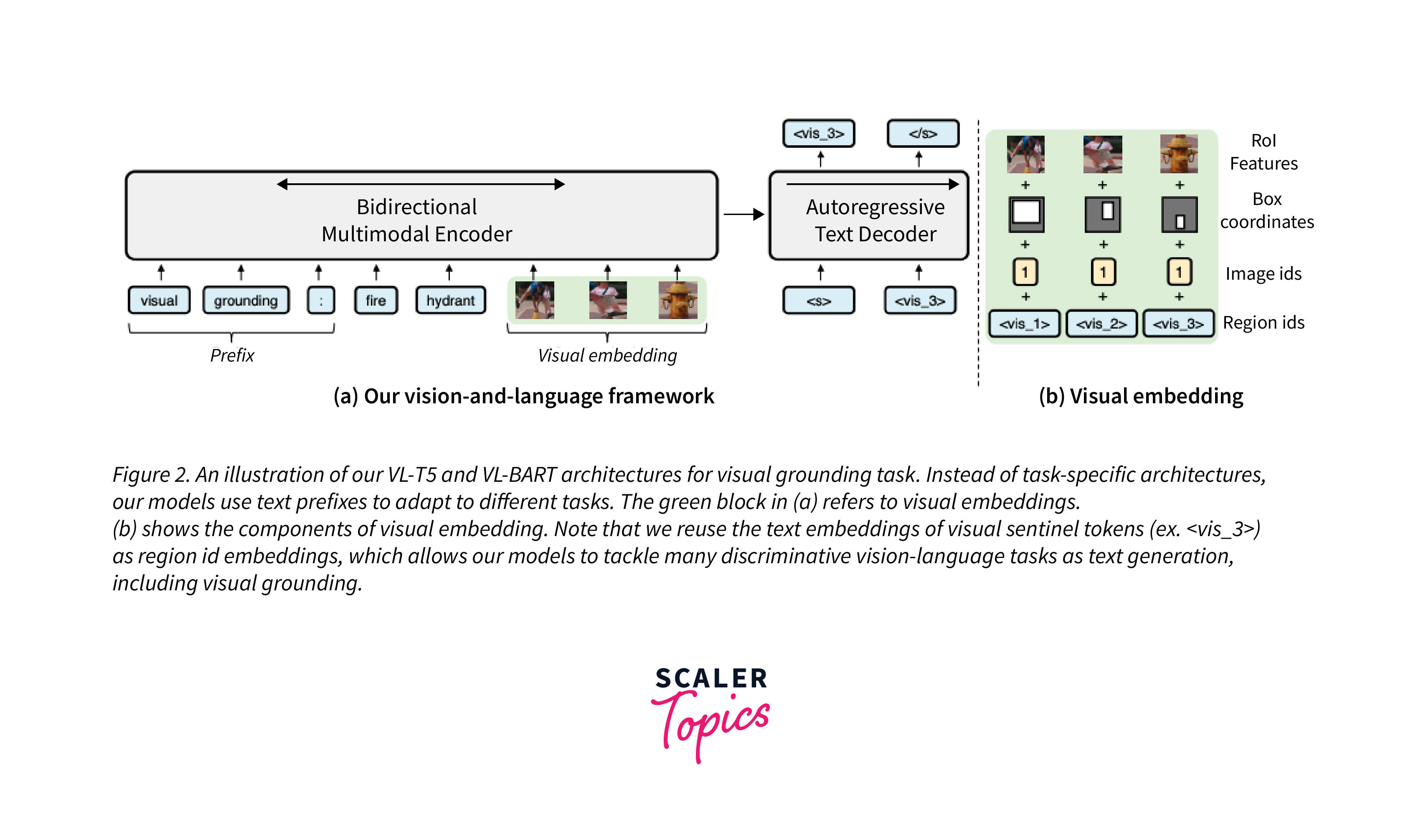
- VL-T5 (Vision-Language T5): An extension of the T5 model, VL-T5 integrates visual inputs into the text-to-text framework, treating images as another form of token sequence.
These multimodal transformer models represent the next frontier in AI, pushing toward a more holistic understanding of complex, intertwined data sources. Their applications range from enhancing accessibility features on platforms to refining content discovery algorithms based on text and imagery.
Transformer Interpretability and Explainability
With the rapid advancement and complexity of transformer models, understanding the mechanisms behind their predictions becomes crucial for model refinement and gaining trust in their deployments, especially in sensitive applications. Interpretability and explainability can be thought of as peeling back the layers of these intricate models to make their operations understandable to humans.
-
Attention Visualization: One of the earliest methods to understand what a transformer focuses on is by visualizing the attention weights. This gives a preliminary idea about which parts of the input the model deemed important for a particular prediction.
-
Feature Attribution: Techniques like Integrated Gradients or LIME can be applied to transformers. They aim to attribute the prediction output to specific input features, thus giving a sense of which words or tokens were most influential.
-
BERTViz: A tool specifically designed for BERT, BERTViz helps visualize the model's attention scores. It's especially useful for deep-diving into individual layers and heads of the transformer.
-
Probing Tasks: These are auxiliary tasks designed to understand what kind of information is captured by transformer representations. For instance, one might train a classifier on top of BERT embeddings to see if it can predict parts of speech, thereby understanding if BERT captures syntactic information.
-
Distillation and Pruning: By training smaller models (students) using the outputs of a larger model (teacher) or removing certain parts of the model, we can often gain insights into which parts of the model are crucial for its performance.
-
Counterfactual Explanations: This involves making minimal changes to the input and observing how the output changes, thus providing an understanding of the model's decision boundaries.
The quest for model transparency isn't just a technical challenge but an ethical imperative. As transformers find their way into more real-world applications, ensuring their decisions can be understood and justified will be paramount.
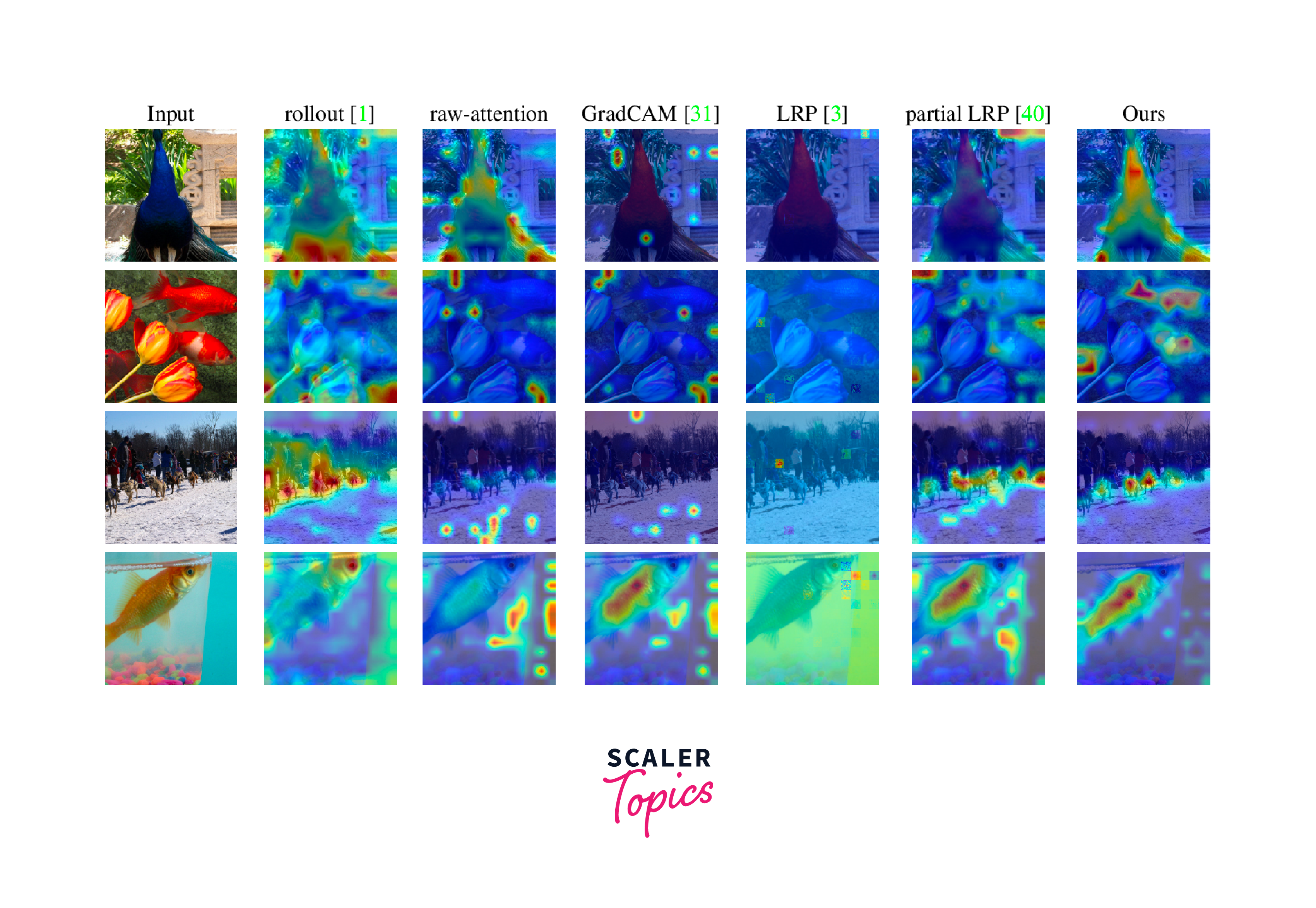
Long-range Transformers
The scalability of transformers, particularly when dealing with long sequences, has been a significant challenge. Traditional transformers have a quadratic computational complexity concerning sequence length, which makes processing long documents computationally expensive. The introduction of architectures like Longformer and others aims to address this limitation, allowing transformers to process longer sequences efficiently.
-
Longformer:
- Introduction: Longformer is designed to handle long sequences using a combination of global and local attention mechanisms.
- Attention Mechanism: While most tokens use local attention (attending to nearby tokens), some tokens can attend globally to all other tokens, ensuring that essential text parts are always considered.
- Applications: This model is suitable for tasks that require reading long documents or retaining context over extended passages, such as coreference resolution or document classification.
-
Other Approaches:
- Linformer: It approximates the attention mechanism to be linear, making the attention weights computation more efficient over longer sequences.
- Sparse Transformers: Introduced by OpenAI, Sparse Transformers use sparse fixed patterns to attend over long distances, breaking the quadratic barrier in processing long sequences.
- Reformer: It combines locality-sensitive hashing (LSH) with the attention mechanism to achieve efficient long-range attention.
-
Benefits of Long-range Transformers:
- Efficiency: They can handle longer sequences without significantly increasing computational cost.
- Contextual Understanding: By attending over longer distances, these models can retain and utilize more extended context, which is crucial for some NLP tasks.
- Flexibility: These architectures can be applied to various tasks, from document summarization to genome sequence analysis.
-
Challenges and Limitations:
- Complexity: Implementing long-range attention mechanisms often requires intricate architectural changes and can be harder to parallelize.
- Training Stability: Training these models, especially with sparse attention patterns, can sometimes be less stable than their dense counterparts.
The advent of long-range transformers showcases the NLP community's continual push towards models that are not only powerful but also efficient and versatile. As the need to process lengthy texts grows, these models will become even more critical in the transformer landscape.
Multilingual and Cross-lingual Transformers
As we strive towards creating a truly interconnected digital world, there's a pressing need to design models that can understand and generate content in multiple languages. Multilingual and cross-lingual transformers are a significant step in that direction. These models aim to generalize across languages, understanding the nuances and intricacies of each while providing a unified representation.
-
Multilingual Transformers:
- Definition: These are models trained on data from multiple languages. They aim to handle multiple languages without being explicitly designed for a specific one.
- BERT Multilingual: One of the early and prominent examples. It's trained on text from 104 languages and can handle tasks in any of them.
- Applications: Can be fine-tuned for specific tasks in any supported language, providing a single model solution for multiple languages.
-
Cross-lingual Transformers:
- Definition: Cross-lingual models are trained in one language but can generalize and perform tasks in other languages, often with the help of parallel data.
- XLM (Cross-lingual Language Model): A significant leap in cross-lingual understanding. XLM leverages parallel data and has shown competitive performance across multiple languages, even with low-resource ones.
- Applications: Especially valuable for low-resource languages where training a dedicated model isn't feasible. It can be used for translation, cross-lingual text classification, and more.
-
Shared Embedding Space:
- A hallmark of these models is their ability to map words or sentences from different languages into a shared embedding space. This shared space ensures that semantically similar content, irrespective of the language, is closer in representation.
-
Benefits of Multilingual and Cross-lingual Transformers:
- Resource Efficiency: Organizations can use a single model to cater to multiple languages instead of maintaining a model for each language.
- Support for Low-resource Languages: Languages with limited data can benefit from models trained on richer languages.
- Improved Generalization: Exposure to multiple languages during training can lead to better generalization, even in monolingual tasks.
-
Challenges and Limitations:
- Training Data: The quality of multilingual models is often bound by the quality and diversity of training data. Biased or imbalanced data can lead to suboptimal performance.
- Model Size: These models often become large to accommodate the intricacies of multiple languages, leading to increased computational costs.
In the global context, the capability to understand and generate content in various languages is crucial. Multilingual and cross-lingual transformers pave the way for this universal understanding, bridging linguistic barriers and bringing content from different languages onto :::
Transformers in Multitask Learning and Few-shot Learning
In recent times, the power of transformers is more than just mastering a single task. Their expansive parameter space and deep architectures have demonstrated efficacy in multitask learning (simultaneously solving multiple tasks) and few-shot learning (performing tasks with limited examples). Let's delve deeper into how transformers have revolutionized these domains.
-
Multitask Learning with Transformers:
- Definition: Multitask learning involves training models on multiple tasks simultaneously, where the model learns a shared representation beneficial for all tasks.
- Unified Model: Instead of training separate models for every task, multitask learning aims to train a single model that can handle various tasks, from sentiment analysis to named entity recognition.
- Shared Representations: Tasks share some underlying patterns. By training on multiple tasks, transformers can learn richer representations, generalizing better on individual tasks.
- Applications: BERT, with its masked language model, can be fine-tuned on various NLP tasks, demonstrating the power of multitasking learning.
-
Few-shot Learning with Transformers:
- Definition: Few-shot learning refers to training models on a very limited dataset, often just a handful of examples.
- GPT-3 and Few-shot Learning: OpenAI's GPT-3 showcased impressive few-shot learning abilities. By providing just a few examples, GPT-3 can perform a range of tasks, from translation to question-answering, without any task-specific fine-tuning.
- Implicit Knowledge: A significant aspect of few-shot learning is the model's ability to leverage the vast knowledge it has gained during pre-training to generalize from a few examples.
-
Challenges in Multitask and Few-shot Learning:
- Task Interference: In multitask learning, there's a risk that the model might prioritize one task over others, leading to suboptimal performance on lesser-prioritized tasks.
- Data Imbalance: If tasks have imbalanced data, the model might lean towards tasks with more data.
- Generalization in Few-shot Learning: While models like GPT-3 demonstrate potential, ensuring consistent performance across diverse few-shot tasks remains challenging.
-
Future Directions:
- Adaptive Task Weighting: Research is ongoing to adaptively adjust the importance of tasks in multitask learning, ensuring balanced learning.
- Meta-learning: Learning to learn can be a potential solution for few-shot tasks, where models are trained to adapt to new tasks with limited data quickly.
The capabilities of transformers in multitasking and few-shot learning present a paradigm shift in how we perceive machine learning models. Instead of being restricted by data limitations or task-specific constraints, transformers herald an era where models can adapt, learn, and generalize across a spectrum of tasks and data scenarios.
Training Transformers
The training process for transformers, especially large ones like BERT, GPT, and their variants, is intricate and demands a systematic approach. While these models bring unprecedented capabilities, they also come with unique challenges. Let's journey through the end-to-end process of training transformers.
-
Data Preparation and Preprocessing:
- Collecting Data: Depending on the task, gather relevant datasets. For language models, this could be vast text corpora.
- Tokenization: Transform the raw text into tokens using subword tokenization techniques like SentencePiece or Byte-Pair Encoding (BPE).
- Data Augmentation: Techniques such as back-translation can enhance the dataset, especially if limited.
-
Choosing the Right Architecture:
- Selecting Model Variant: Decide between models such as BERT (bidirectional), GPT (unidirectional), etc., based on the task.
- Configuration: Determine the model size—number of layers, heads in multi-head attention, and hidden units.
-
Model Initialization:
- Random Initialization: For training from scratch.
- Pre-trained Weights: For transfer learning, initialize with weights from a model pre-trained on a large corpus.
-
Training Strategy:
- Learning Rate and Scheduling: Start with a warm-up phase, then reduce the learning rate over time.
- Regularization: Techniques like layer normalization, dropout, and gradient clipping help prevent overfitting.
- Loss Function: choose an appropriate loss, e.g., cross-entropy, for classification depending on the task.
-
Evaluation and Fine-tuning:
- Validation Set: Use a separate dataset to evaluate the model's performance during training.
- Fine-tuning: further train the model on task-specific data for specific tasks.
Output
-
Model Optimization:
- Quantization and Pruning: Reduce the model size without significant performance drops.
- Distillation: Train smaller models to mimic the behavior of larger ones.
-
Deployment:
- On-cloud vs. On-device: Decide between deploying on cloud platforms or edge devices.
- Inference Optimization: Use frameworks like ONNX for faster inference.
-
Monitoring and Continuous Learning:
- Performance Metrics: Monitor the model's real-world performance metrics.
- Feedback Loop: Incorporate user feedback and errors to retrain and update the model continually.
Training transformers is a resource-intensive process, often requiring powerful GPUs or TPUs. Yet, with the right strategy and tools, it's possible to train them efficiently, ensuring state-of-the-art performance across many tasks. As the research community continues to innovate, the process will likely become even more streamlined, making these powerful models accessible to a broader audience.
Conclusion
- The world of transformers has witnessed rapid advancements in recent years, from architecture innovations to diverse application areas.
- initially designed for NLP tasks, these models have now expanded across various domains, showcasing their versatility.
- Multitasking and multimodality have become central in the transformer evolution, enabling models to work seamlessly across different data types.
- The significance of interpretability has gained traction, ensuring that while models get complex, they remain understandable.
- Lastly, as transformers push boundaries in multitasking and few-shot learning, the horizon for their potential applications only broadens, cementing their place in the future of AI and machine learning.