Transformers in NLP
Overview
Natural Language Processing, or NLP, is one of the most important fields of machine learning. NLP linguistically focuses on understanding everything related to human language. The aim of NLP tasks is not only to understand single words individually but to understand the context of those words. A plethora of models in NLP is used to process and get results out of language data. Some of them are ANN, RNN, LSTM, Transformers, etc. Among them, Transformers has revolutionalized how to deal with NLP tasks for the world.
Introduction
The Transformer in NLP is a novel architecture that aims to solve sequence-to-sequence tasks while handling long-range dependencies with ease. Sequence-to-sequence tasks take in a sequence(vector or a collection of vectors) and transform it into another sequence. We will read about long-range dependencies later in this article. The Transformer was proposed in the paper Attention Is All You Need. Since then, many organizations have adopted the concept and completely changed the scenario of dealing with NLP tasks.
Why do we need it?
- It is faster than other sequence-to-sequence models such as RNN, LSTM, etc.
- It processes input sequences parallelly, unlike the others, which process the input sequentially.
- It understands the underlying meaning and context of the text data, whereas the other models learn a particular pattern.
Few Things to Know Before Diving Into Transformers
The transformer in NLP architecture is quite complex. One needs to understand the history of sequence-to-sequence models and the challenges we faced earlier that paved the way for the transformers.
Sequence to Sequence Models
Sequence-to-sequence (seq2seq) models in NLP convert sequences of one type to sequences of another. For example, translating English sentences to French sentences is a sequence-to-sequence task.
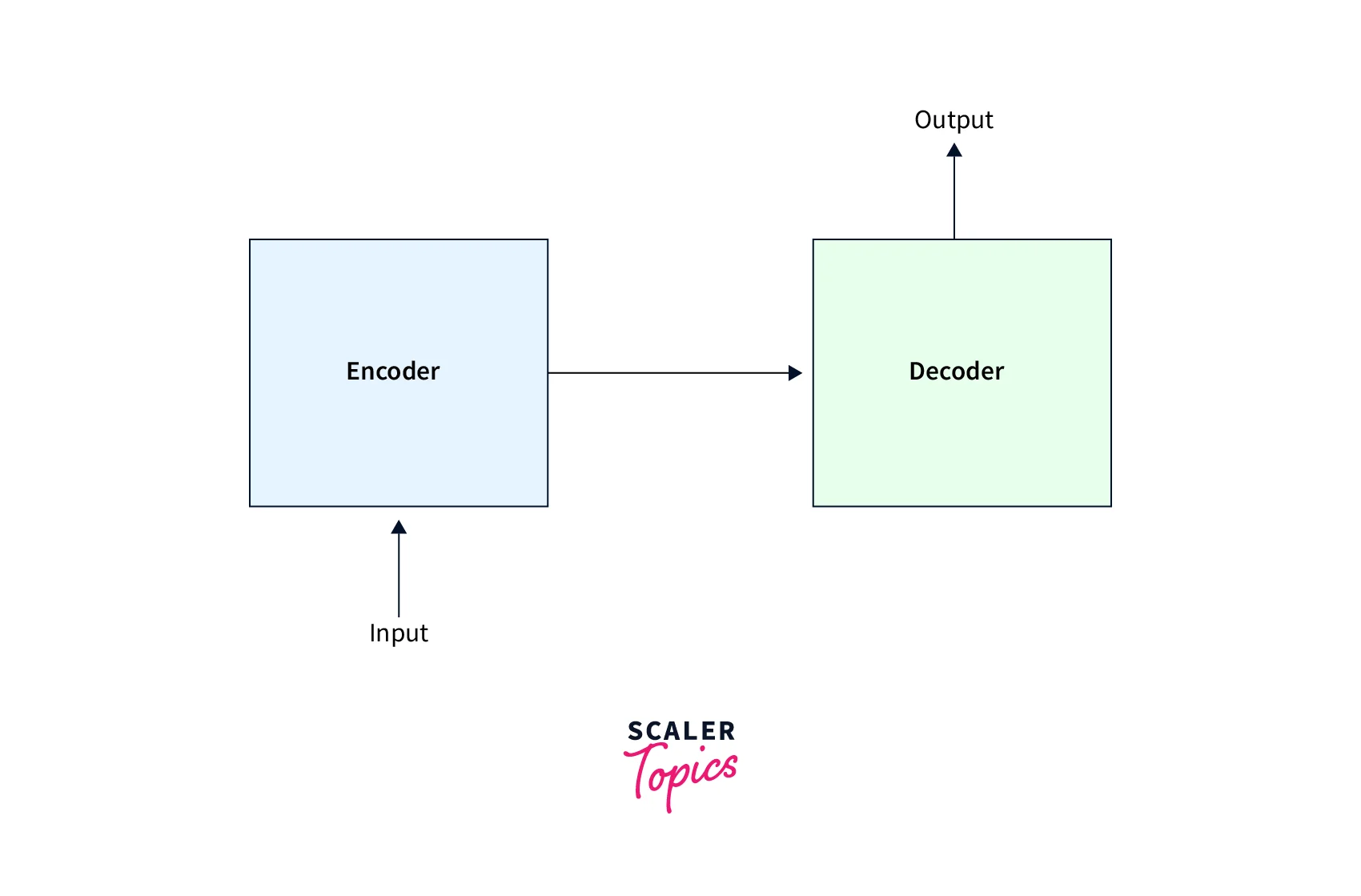
The basic architecture consists of an encoder and a decoder.
Before the concept of transformers was discovered, we used RNNs and LSTMs.
Most of the data in the current world are sequences – a number sequence, a text sequence, a video frame sequence, or an audio sequence. RNN-based sequence-to-sequence models gained much popularity in 2014 and got further enhanced when the Attention Mechanism was introduced in 2015. Since then, the progress in the enhancement of tackling NLP tasks has taken a huge leap.
RNN based sequence to sequence model
A common example of sequence to sequence model is English to French Translation.
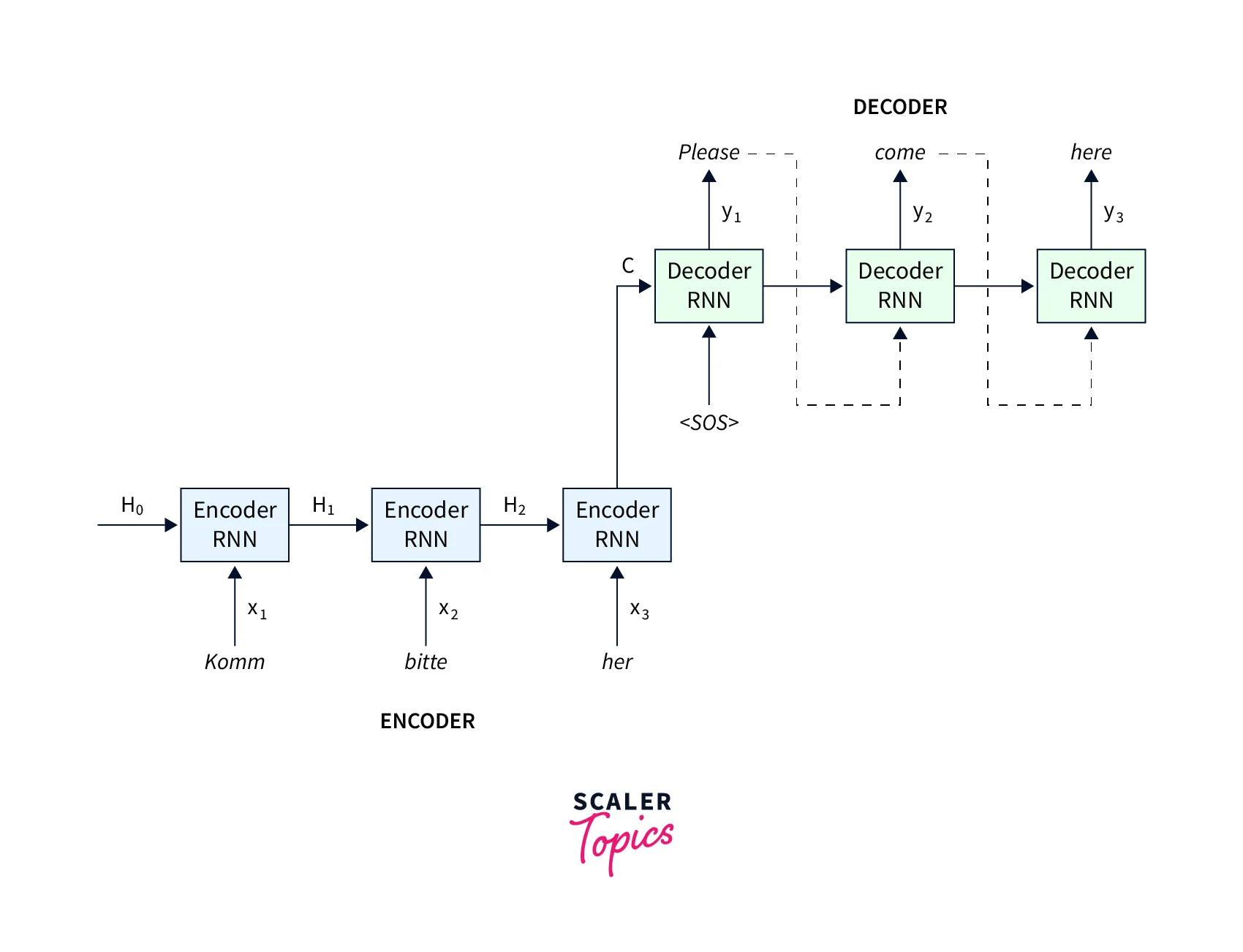
Let's break down the above architecture:
- The encoders and decoders are all RNN based.
- At every time step in the Encoder, the RNN takes a word vector (xi) from the input sequence(sequentially) and a hidden state (Hi) from the previous time step.
- At each time step, the hidden state is updated.
- The hidden state from the last unit is known as the context vector. This contains information about the input sequence's context in the text data.
- This context vector is then passed to the decoder and used to generate the target sequence (English word/phrase).
Drawbacks of the model
- RNN has certain drawbacks. One of the majors is being unable to handle long-term dependencies due to vanishing or exploding gradients. In other words, if the data is huge, RNN cannot capture the contextual information of the whole text data.
- The sequential nature of the model architecture prevents parallelization. For example, the input is a single-word embedding of the French language. Therefore, we can only feed part of the data simultaneously, slowing down the process.
- Hence RNNs are very slow to train.
To overcome the first drawback of not being able to handle the long-term dependencies in the data, LSTMs were introduced.
LSTM Based Sequence to Sequence Models
Just like RNNs, the LSTM seq2seq models have an encoder-decoder architecture. However, an LSTM is an upgradation over RNN as it can handle long-term dependencies.
Here is a quick overview of LSTM:-
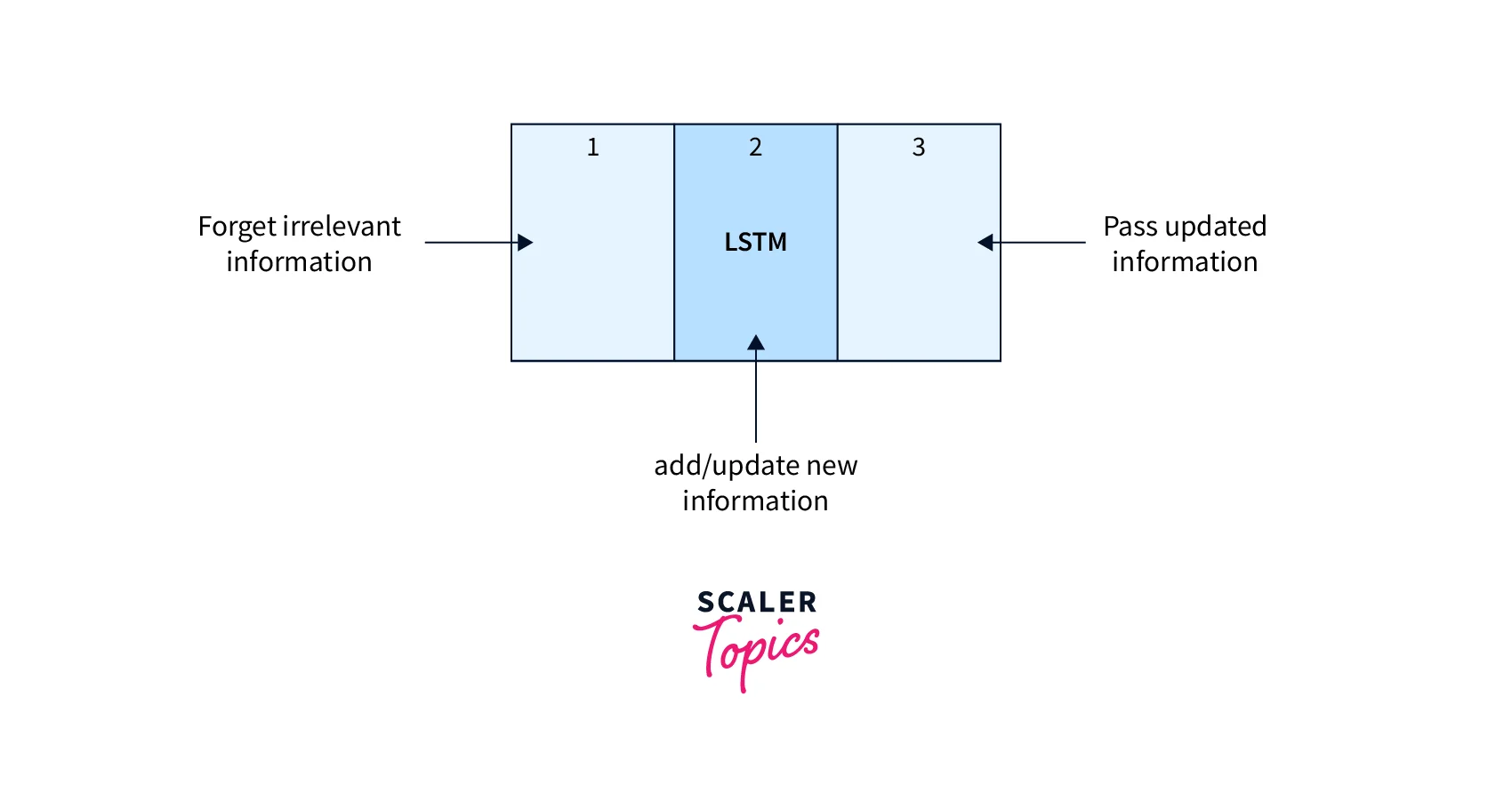
The LSTM consists of three parts, as shown in the image above, and each part performs its important function.
- The first part chooses whether the information coming from the previous timestamp is to be remembered or is irrelevant and can be forgotten.
- In the second part, the cell tries to learn new information from the input to this cell.
- At last, in the third part, the cell passes the updated information from the current timestamp to the next timestamp.
Let's see how LSTM deals with sequence-to-sequence tasks. We will use the same example of English-to-French translation.
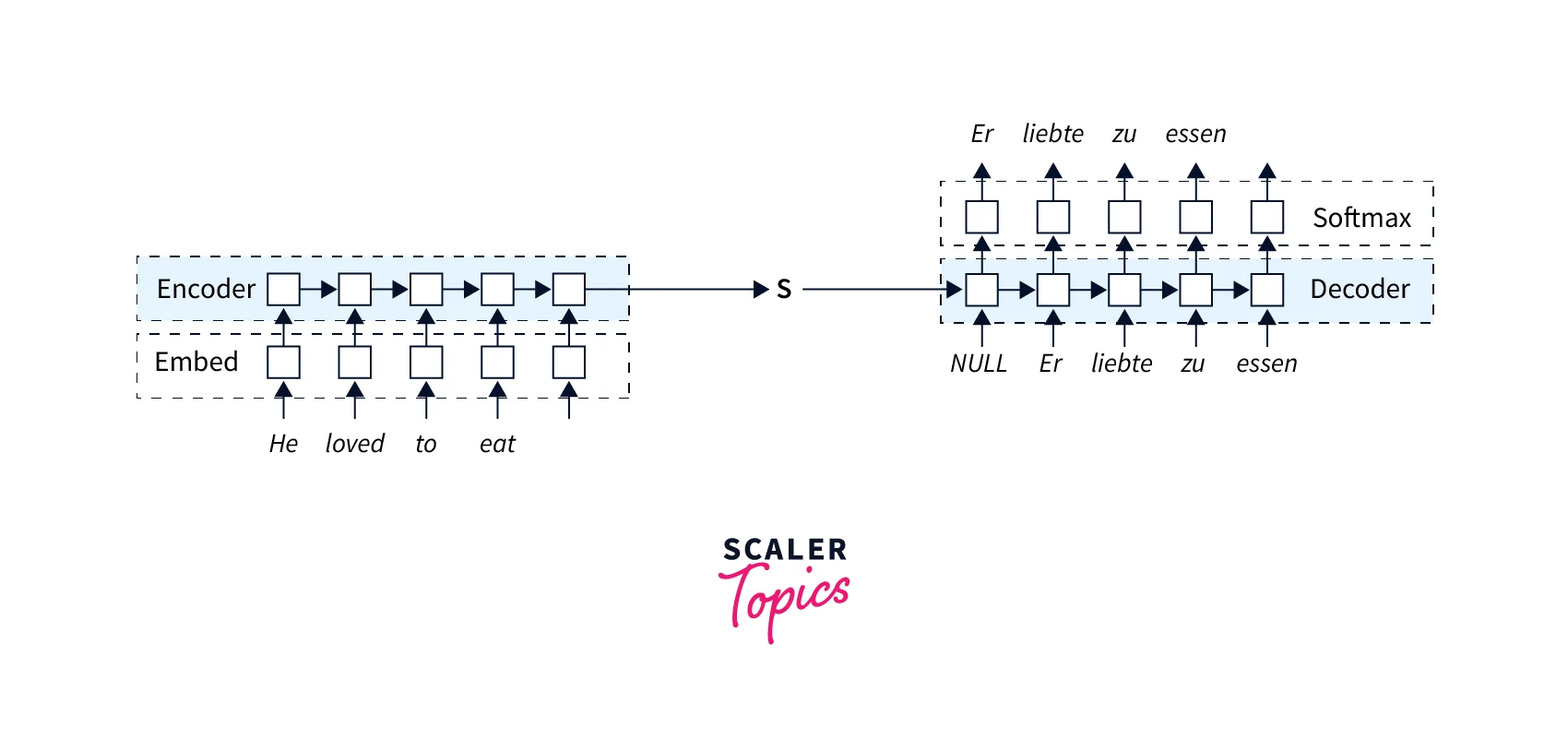
Let's break down the above architecture:-
- Both the Encoder and the decoder are LSTM models
- Encoder reads the input sequence sequentially and summarizes the information in the internal state vectors or context vector. In LSTM language, we call these the hidden and cell state vectors, respectively.
- We ignore the outputs of the Encoder and only preserve the internal states.
- This context vector aims to capture the information for all input elements to help the decoder make accurate predictions.
- This is encoder architecture.
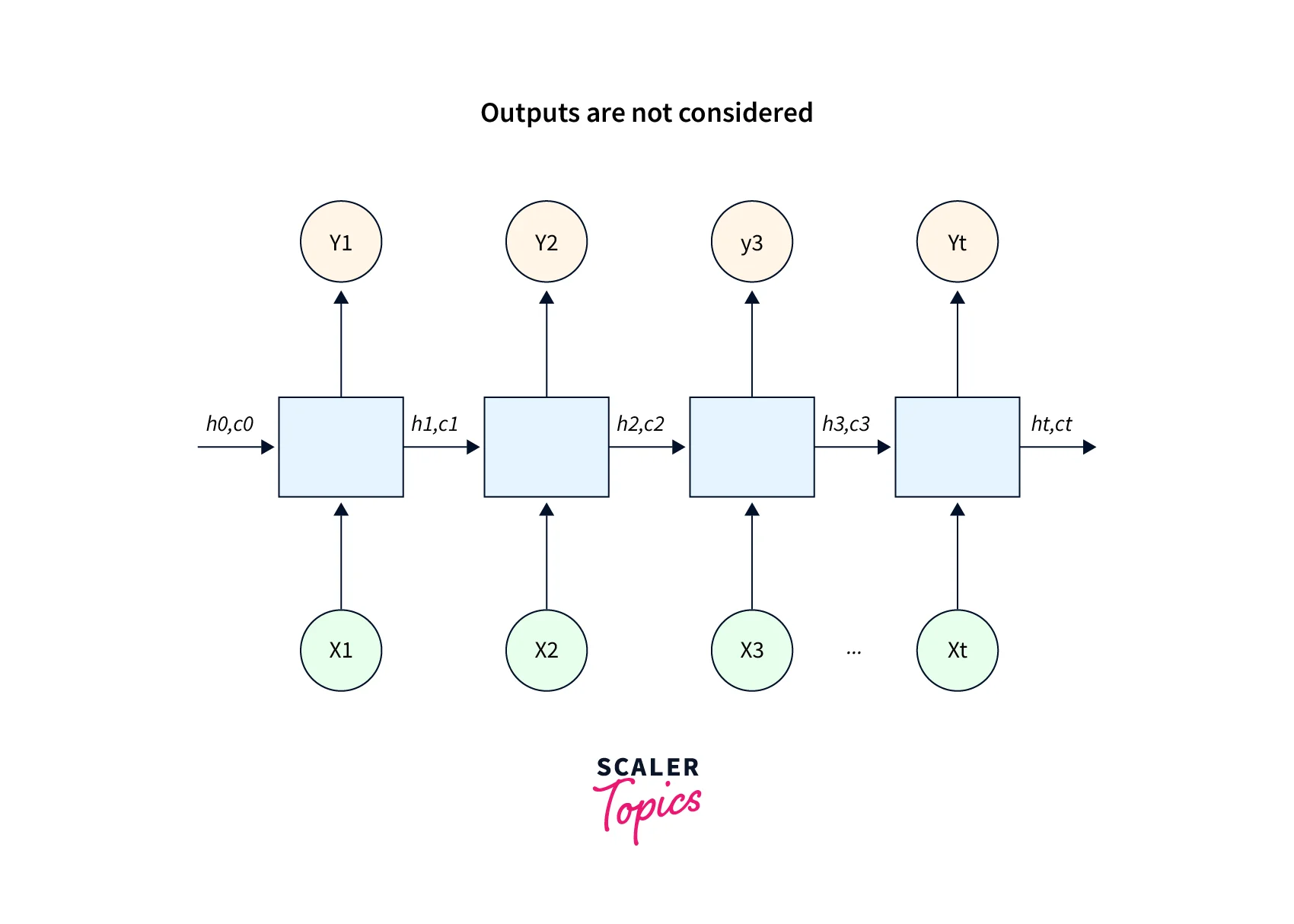 "h" is the hidden state, and "c" is the cell state.
"h" is the hidden state, and "c" is the cell state. - Here's what the decoder looks like:-
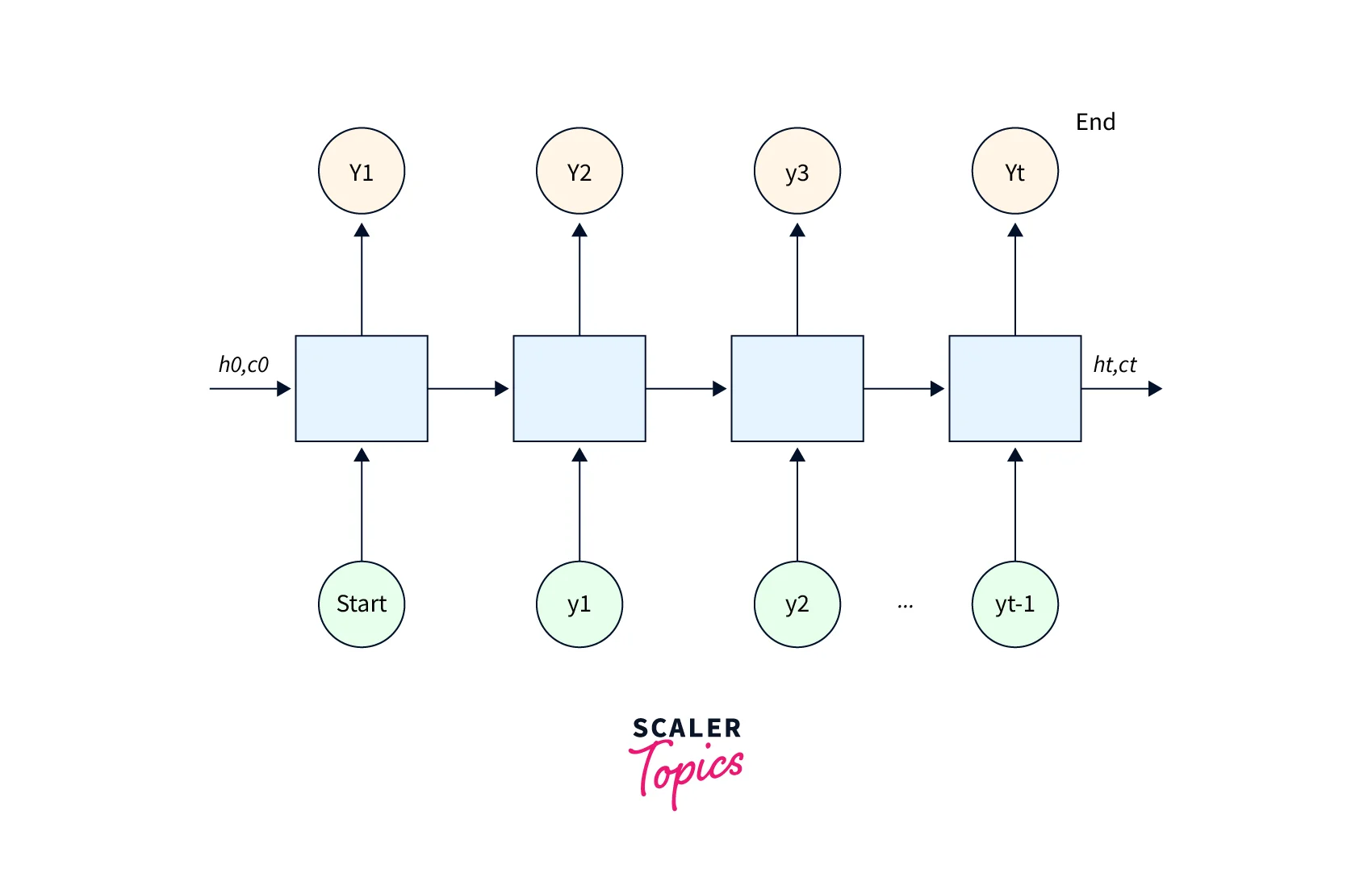
Drawbacks of the LSTM sequence to sequence model
- LSTMs are even slower than RNNs to train, and vanishing gradients remain a fundamental problem.
- The final hidden state of the LSTM is where you're trying to cram the entirety of the sentence you have to translate. They are usually only a few hundred units long. The more you try to force into this fixed dimensionality vector, the lossier the neural network is forced to be.
Self Attention
According to the research paper:- "Self-attention, sometimes called intra-attention, is an attention mechanism relating different positions of a single sequence to compute a representation of the sequence."
In simple words, Attention allows us to focus on parts of our input sequence while we predict our output sequence. For example, in the English-to-French translation task, if the French word is predicted to be "bleu," we will likely find a high weightage for the word "blue" in our input sequence. So Attention, in a way, allowed us to map some connection/correlation between the input word "bleu" and the output word "blue."
Self-attention helps us to create parallel connections within the same sentence.
Look at this example:-
"I poured water from the bottle into the cup until it was full." it --> cup
"I poured water from the bottle into the cup until it was empty."
it --> bottle
The first sentence's "it" refers to the "cup," whereas the second one refers to the "bottle." So a minimal change in the words from "full" to "empty" changed the context of the sentence. If we translate such a sentence, we will want to know what "it" refers to. This may be an easy task for us to understand, but the computer needs the attention mechanism to interpret such complexities in the text data.
There Are Three Kinds of Attention that Are Possible in A Model
- Encoder-Decoder Attention:
This attention model emphasizes the input and output sequences. It works by providing a more weighted or more signified context from the Encoder to the decoder and a learning mechanism where the decoder can interpret where to give more 'attention' to the subsequent encoding network when predicting outputs at each time step in the output sequence. - Self-attention in the input sequence:
It solely attends to all the words in the input sequence. - Self-attention in the output sequence:
While dealing with output sequences, we cannot use the upcoming sequence while processing the data. For example, while translating English to French, we should only use the French words that occur before a given the word. One thing we should be wary of here is that the scope of self-attention is limited to the words that occur before a given the word. This prevents any information leaks during the training of the model. This is done by masking the words that occur after it for each step. So for the first step, only the first word of the output sequence is NOT masked. For the second step, the first two words are NOT masked, and so on.
Keys, Values, and Queries
These three are vectors, created as abstractions, which are useful for calculating self-attention.
These are calculated by multiplying your input vector(X) with weight matrices(W) that are learned while training.
These vectors are explained as follows:-
- Query Vector:
This vector represents the current word that is under consideration. Query vector: q= X * Wq. - Key Vector:
This vector acts as an indexing mechanism for the Value vector. Key Vector: k= X * Wk. Value vector is similar to how we have key-value pairs in hash maps, where keys are used to index the values uniquely. - Value Vector:
This vector represents the information contained in the input word. Value vector:v= X * Wv.
How Do We Go About Calculating Self-Attention?
- We find the most similar key, k, by doing a dot product for q and k.
- The highest value of the query-key product will be the closest one.
- This is followed by a softmax that will drive the q.k with smaller values close to 0 and q.k with larger values towards 1.
- The softmax distribution thus obtained is then multiplied with v.
- The value vectors multiplied with ~1 will get more attention, while the ones ~0 will get less.
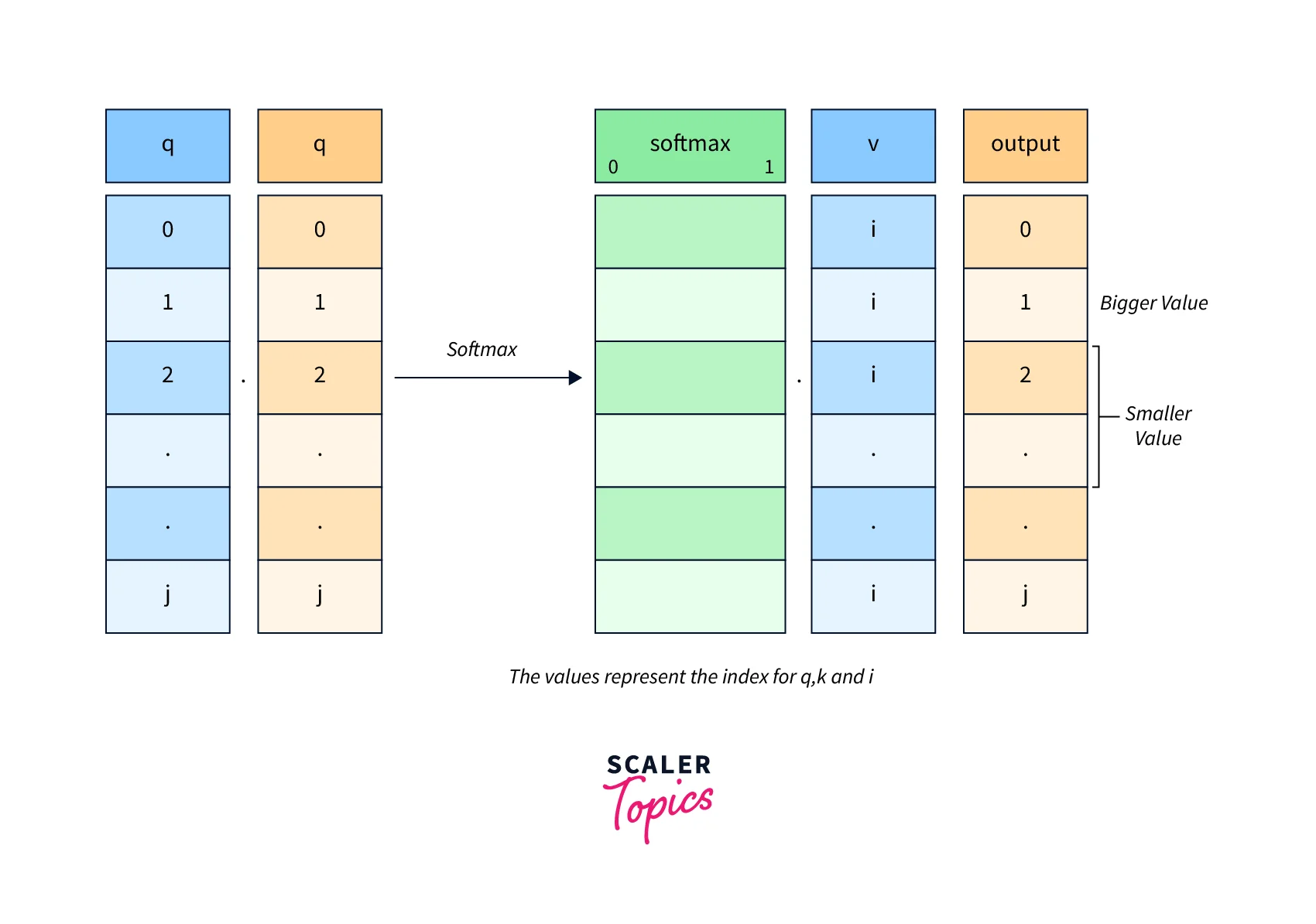
All the matrices Wq, Wk, and Wv are learned while being simultaneously updated during the model training.
Mathematics Behind Self-attention
Given vectors: q,k,v:-
If we are calculating self-attention for an ith input word:
- Step 1:
Multiply qᵢ by the kⱼ key vector of the word. - Step 2:
Then, we divide this product by the square root of the dimension of the key vector. This step is done for better gradient flow. This is because a good gradient flow is especially important in these cases when the value of the dot product in the previous step is too big. As using them directly might push the softmax into regions with very little gradient flow. - Step 3:
Once we have scores for all js, we pass these through a softmax. We get the normalized value for each j. - Step 4:
Multiply softmax scores for each j with the vᵢ vector. The idea here is to get very similar Attention. We need to preserve only the values v of the input word(s) we want to focus on by multiplying them with high probability scores from softmax ~1 and removing the rest by driving them towards 0, i.e., making them very small by multiplying them with the low probability scores ~0 from softmax.
The Transformer in NLP
According to the paper:-
"The Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution."
Here, "transduction" means the conversion of input sequences into output sequences. Transformer's idea is to completely handle the dependencies between input and output with Attention and recurrence.
Next, we will look at the architecture of a standard Transformer in NLP.
The architecture of the Transformer may appear to be complex. The remaining part of this article will break down each of its components and give you an excellent understanding of the same.
Architecture of a Transformer
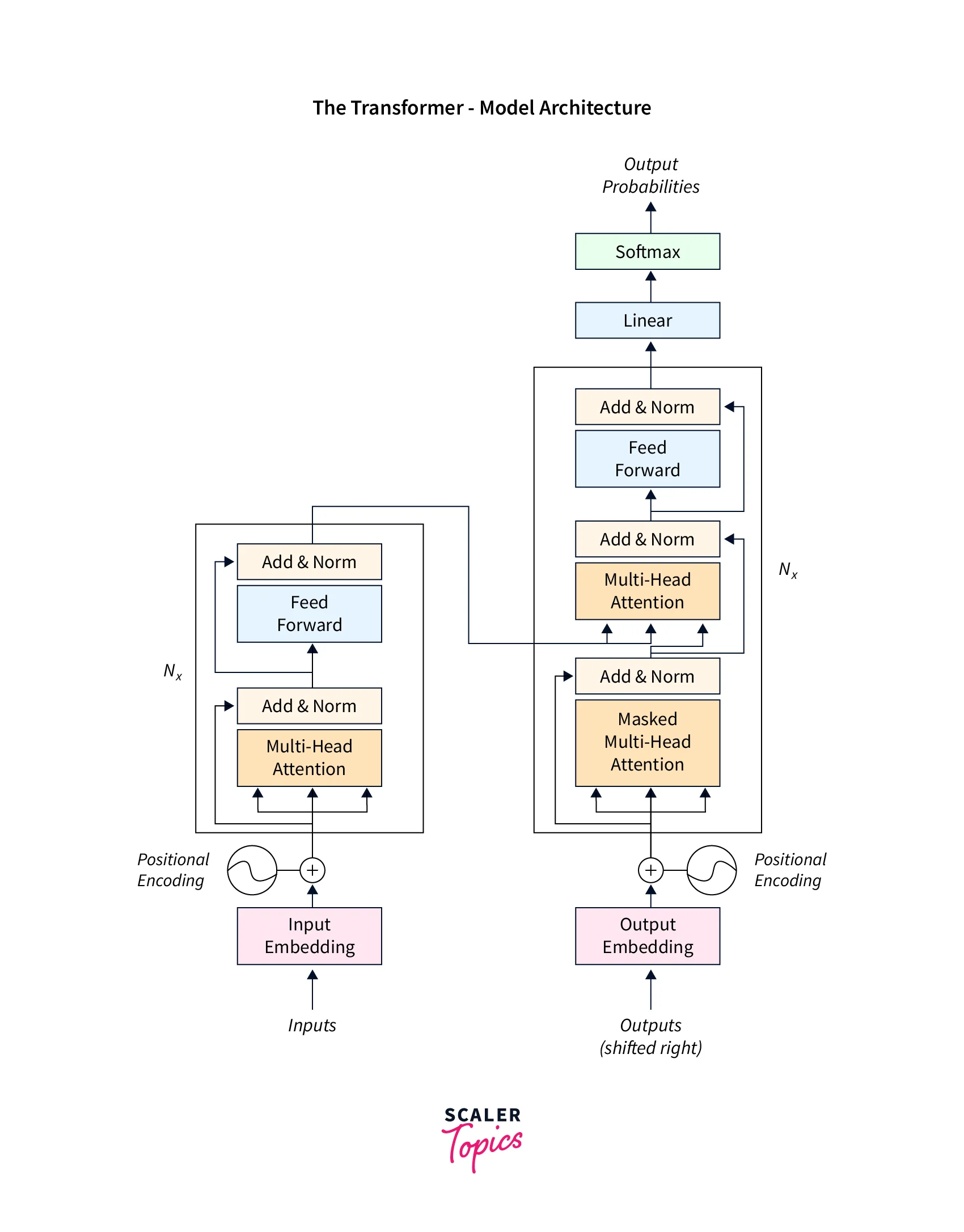
We can break down this complex architecture into several small parts: The Encoder, the decoder, the input and output preprocessing, and the output post-processing.
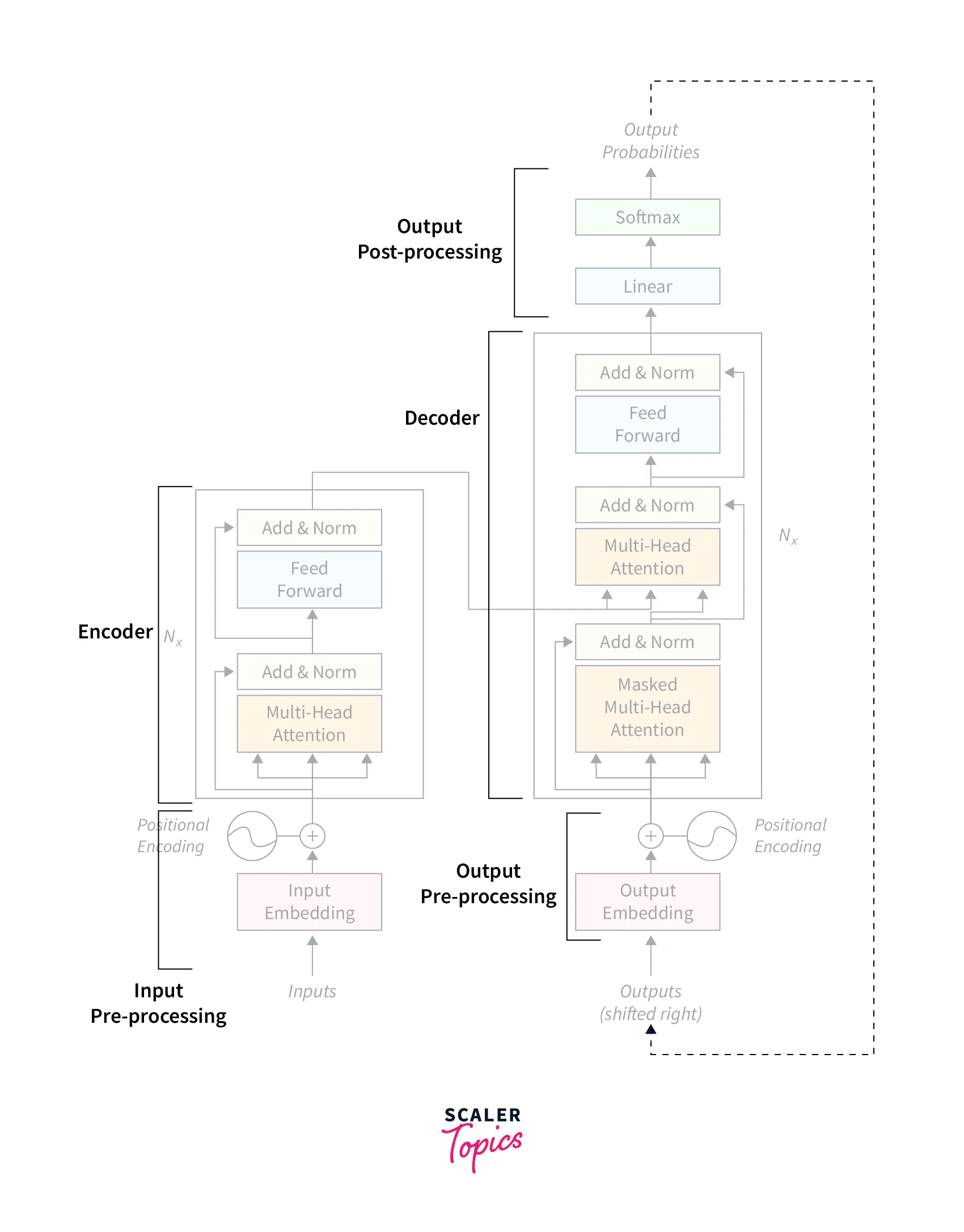
The Encoder-Decoder Stacks
As we have discussed earlier, every sequence-to-sequence model has an encoder-decoder stack.
The Encoder
The Encoder maps an input sequence of symbol representations (x₁, …, xₙ) to a sequence of representations z = (z₁, …, zₙ).
The encoder stack consists of two layers:-
- A multi-head self-attention mechanism on the input vectors. It is just like the self-attention we discussed, with the additional support of parallel inputs.
- A simple, position-wise, fully connected feedforward network that is used for post-processing.
The Decoder
Given z, the decoder then generates an output sequence (y₁, …, yₘ) of symbols one element at a time.
The decoder stack consists of three layers:-
- A masked multi-head self-attention mechanism on the output vectors of the previous iteration.
- A multi-head attention mechanism on the output from the Encoder and masked multi-headed Attention in the decoder.
- A simple, position-wise, fully connected feedforward network that is used for post-processing.
The encoder and decoder blocks are multiple identical encoders and decoders stacked on top of each other. Both the encoder stack and the decoder stack have the same number of units.
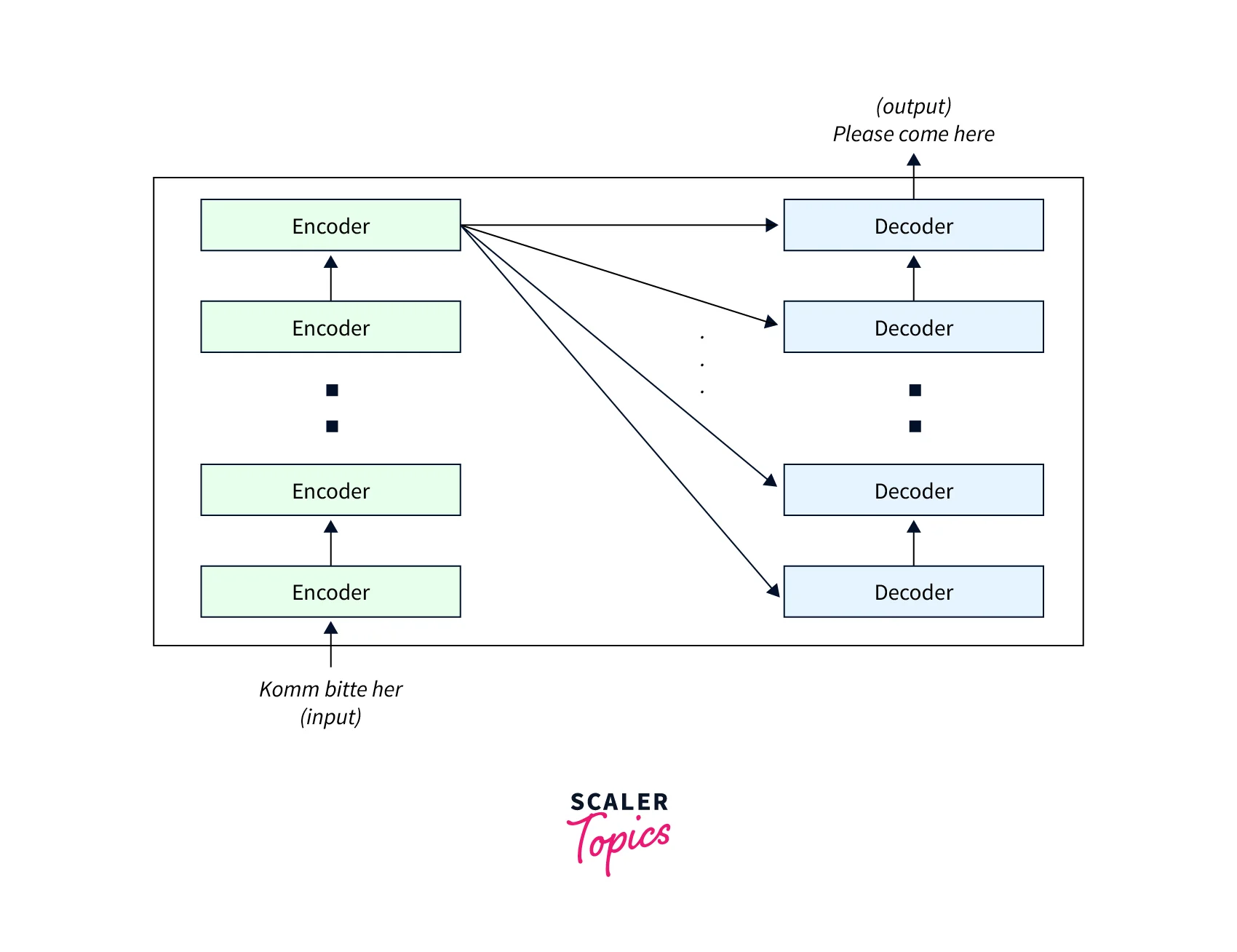
Inside the Encoder-Decoder Architecture
This is how a transformer works:-
- The word embeddings of the input sequence are passed to the first Encoder
- These are then transformed and propagated to the next Encoder
- The output from the last Encoder in the encoder stack is passed to all the decoders in the decoder stack, as shown in the figure below:
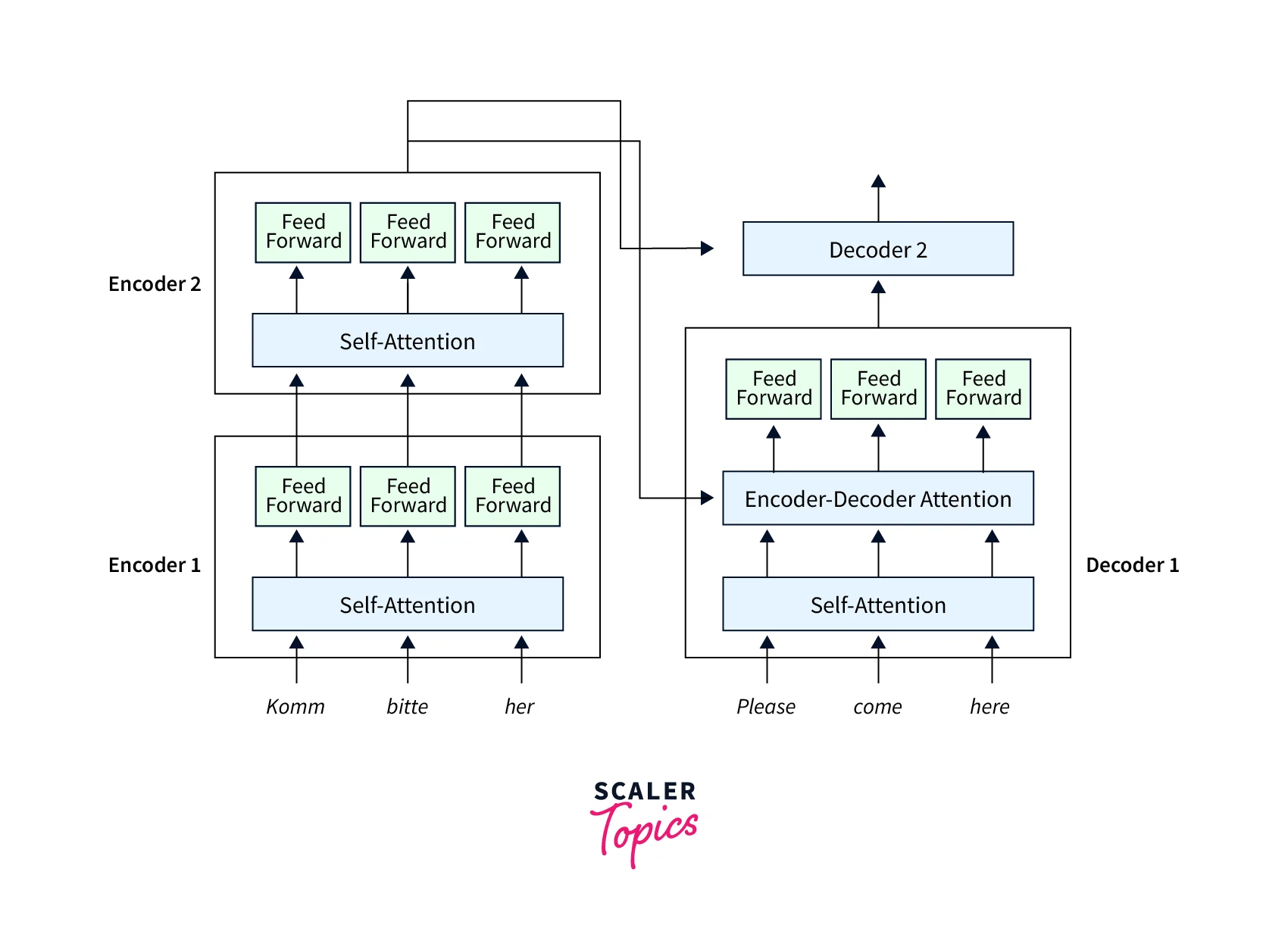
In addition to the self-attention and feedforward layers, the decoders also have one more layer of the Encoder-Decoder Attention layer. This helps the decoder focus on the right parts of the input sequence.
Input and Output Preprocessing
The inputs to the Encoder and decoder stack have to go through some preprocessing to get the full context out of the sequences.
Representing Input Sequence
The transformer revolution started with a simple question: Why don't we feed the entire input sequence? No dependencies between hidden states!
Sets and Tokenization
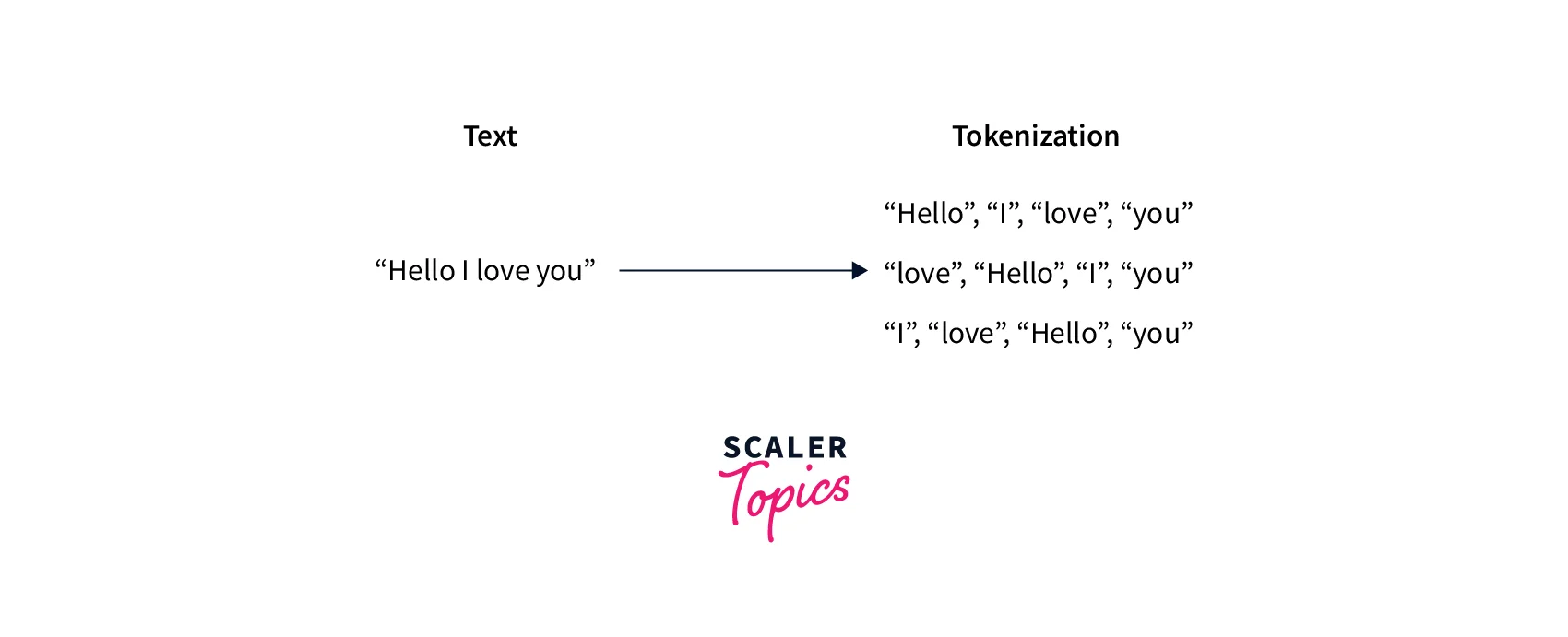 Take a look at this example.
Take a look at this example.
This processing step is usually called tokenization, and it's the first out of three steps before we feed the input into the model. Thanks to this step, we now have a sequence of elements instead of a step.
After tokenization, we project words in a distributed geometrical space or build word embeddings.
Word Embeddings
By definition: an embedding captures the semantics of the input by placing semantically similar inputs close together in the embedding space.
Word embeddings are a type of natural language processing technique used to represent words in a numerical form to facilitate computational processing and analysis of text data. Essentially, word embeddings are vector representations of words that are learned by a machine learning model during a training process, where the vectors capture the semantic meaning and relationships between the words in a given context.
The underlying idea of word embeddings is that words with similar meanings or that tend to occur in similar contexts should be represented by vectors that are close to each other in the embedding space. This allows for efficient computation of relationships between words and for machine learning models to use these representations as features for various text-related tasks, such as sentiment analysis, language translation, and information retrieval.
Moving on, we will devise a funky trick to provide some notion of order in the set.
Positional Encoding
Positional encodings are a type of technique used in natural language processing to capture the positional information of words in a sentence or a sequence of text. The purpose of positional encodings is to augment the word embeddings with information about the relative positions of words in a sequence.
In many cases, more than word embeddings is needed to capture the meaning of a sentence or a sequence of text on their own, especially when the order of the words matters. Positional encodings address this issue by adding a unique vector representation to each word in a sequence based on its position and combining it with the word's embedding.
Typically, the positional encoding vectors are created using a mathematical function that generates a unique set of values for each position in the sequence. These values are then added to the word embeddings before being input into a machine-learning model. By combining the word embeddings with positional encodings, the model can learn the importance of word order and capture the semantic meaning of the entire sequence more accurately.
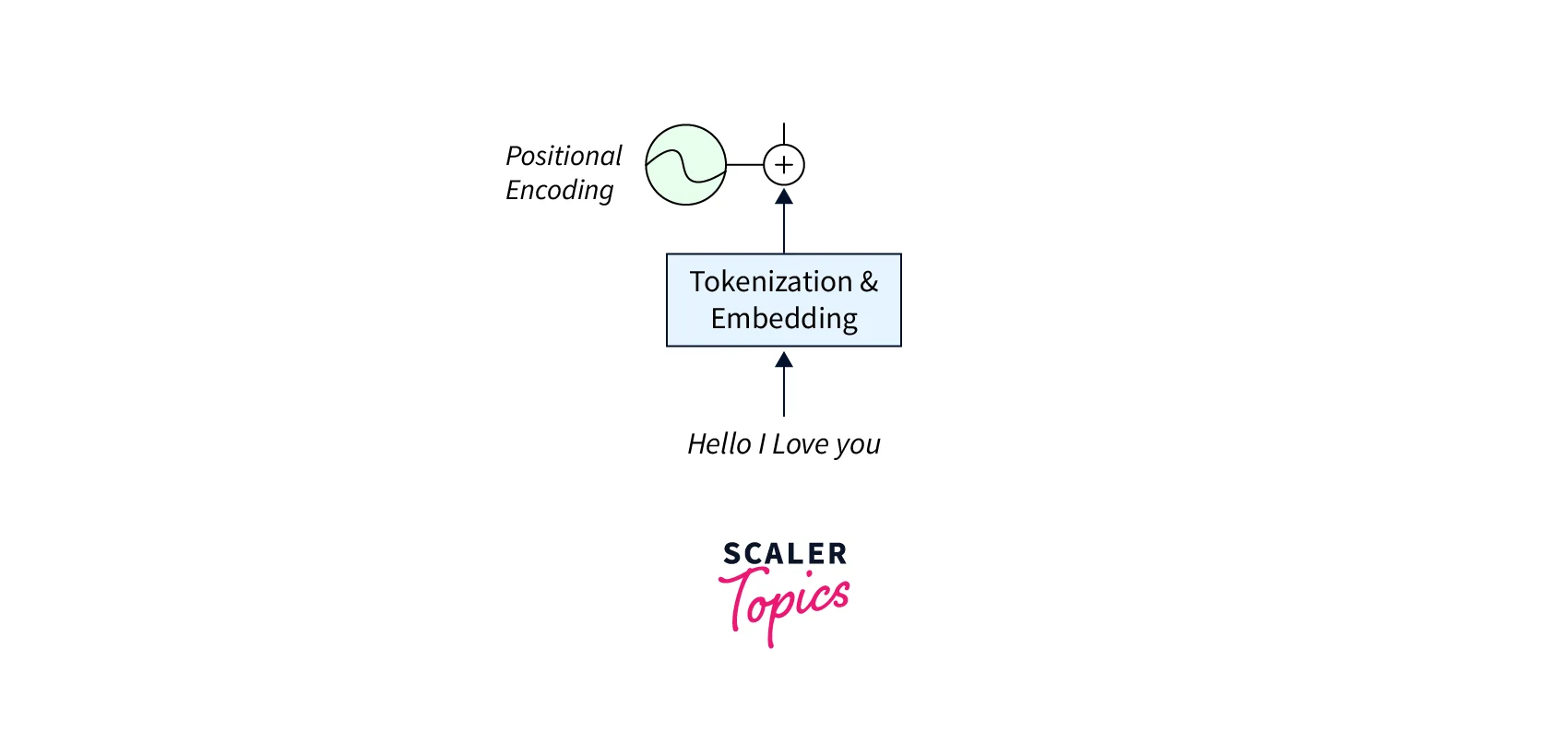
Mathematics behind positional Encoding
The goal of positional Encoding is to add information about the order or position of words in a sequence of text to the word embeddings. This is achieved by adding a positional encoding vector to the word embedding vector for each word in the sequence.
The positional encoding vector is generated using a mathematical function that considers both the position of the word in the sequence and the dimension of the embedding vector. A commonly used function for generating the positional encoding vector is the following:
Where is the word's position in the sequence, is the index of the dimension in the embedding vector, and is the total number of dimensions in the embedding vector.
The positional encoding vector for a word is then the sum of the word's embedding vector and its corresponding positional encoding vector:
Where is the final vector representation of the word that includes both the embedding and the positional Encoding, and is the positional encoding vector for the given position .
Decoder Stack Revisited
The decoder stack is a key component of the Transformer in NLP architecture, a popular neural network architecture used for natural language processing tasks such as machine translation, text generation, and text summarization.
The decoder stack is responsible for generating the output sequence in an autoregressive manner, meaning that it generates each element of the output sequence one at a time based on the previously generated elements.
- It takes as input the output of the encoder stack, a set of contextualized word embeddings that encode the input sequence.
- It consists of multiple layers, each of which includes two sub-layers: a multi-head self-attention layer and a multi-head attention layer that attends to the output of the encoder stack.
The multi-head self-attention layer is similar to the one used in the encoder stack. It allows the decoder to attend to different parts of the input sequence to generate each element of the output sequence. In addition, it attends to the output of the encoder stack and helps the decoder to generate the output sequence based on the information in the input sequence.
In addition to these two sub-layers, each layer in the decoder stack also includes a feedforward neural network layer that applies a non-linear transformation to the output of the attention layers.
The output of the last layer of the decoder stack is passed through a final linear layer and a softmax activation function to generate the probability distribution over the vocabulary of possible output tokens.
The decoder then samples from this probability distribution to generate the next token in the output sequence.
Overall, the decoder stack in the Transformer architecture is responsible for generating the output sequence in an autoregressive manner by attending to the output of the encoder stack and the previously generated elements of the output sequence.
Conclusion
The key takeaways from this article are:-
- Transformers in NLP are a type of neural network architecture that has revolutionized natural language processing (NLP) by enabling models to handle sequential data with long-term dependencies such as text effectively.
- Before transformers, recurrent neural networks (RNNs) were commonly used in NLP, but they suffered from several issues, such as vanishing gradients and difficulty in parallelization. The transformer architecture overcomes these issues and has become the de facto standard in NLP.
- The idea behind Transformer is to completely handle the dependencies between input and output with Attention and recurrence.
- The pre-trained transformer models have achieved state-of-the-art performance on various NLP tasks and have become a standard approach in the field.