Transformer Visualization and Explainabilitys
Overview
Understanding and interpreting the inner workings of transformer-based models like BERT, GPT and their variants is crucial for their adoption and trustworthiness in various applications. In this article, we will explore tools and techniques for visualizing and explaining attention mechanisms in transformers, making these models more transformers interpret and transparent.
Tools for Attention Visualization
Understanding how attention mechanisms work in transformer-based models is crucial for gaining insights into decision-making processes. Various tools and libraries have been developed to help visualize and interpret attention patterns within these models. Here are some notable tools and techniques for attention visualization:
Hugging Face Transformers Library
The Hugging Face Transformers Library has emerged as a go-to toolkit for researchers, developers, and practitioners in the field of NLP. It is designed to simplify transformer-based models, making it accessible to a wide audience. Here's a breakdown of the different aspects and features of this library:
- Model Repository: The library hosts a vast repository of pre-trained transformer-based models. These models range from small and efficient ones suitable for mobile devices to large, state-of-the-art models like BERT, GPT, RoBERTa, and more.Researchers and developers can leverage these pre-trained models for various NLP tasks such as text classification, language generation, sentiment analysis, and named entity recognition.
- Easy Model Loading and Inference: Hugging Face Transformers offers a simple and consistent API for loading pre-trained models and using them for inference. Users can easily load a model and pass text inputs for predictions.The library supports both PyTorch and TensorFlow backends, providing flexibility for users who prefer either framework.
- Model Fine-Tuning: In addition to using pre-trained models, the library allows users to fine-tune these models on their custom datasets. This is crucial for adapting models to specific tasks or domains.Fine-tuning is supported for various downstream tasks, and the library provides data preparation and training tools.
- Extensive Tokenizers: Tokenization is a critical step in NLP, and Hugging Face Transformers includes a wide range of tokenizers compatible with its models. These tokenizers can handle various languages and tokenization strategies, making working with diverse text data easier.
- Attention Heatmaps: You can generate attention heatmaps using the library's functions to visualize how the model attends to different parts of the input sequence.
- Interpretability Tools: Hugging Face Transformers interpret offers tools for model interpretability, including visualization of attention heads and attention scores.

TensorFlow Attention Visualization
TensorFlow is widely recognized as a versatile deep-learning framework offering various tools and capabilities for building, training, and interpreting various neural network architectures, including transformer-based models. Visualizing attention in these models is crucial for understanding their behaviour, and TensorFlow provides resources to facilitate this process. Here's a breakdown of the different aspects and features of this library:
- Attention Heatmaps: TensorFlow allows users to create and visualize attention heatmaps for transformer models. These heatmaps offer insights into how the model distributes its attention across different parts of the input sequence.Attention heatmaps visually represent the attention weights assigned to tokens in the input. Brighter regions in the heatmap correspond to higher attention weights, indicating the model's focus on specific input tokens.
- Customization: TensorFlow's tools for attention visualization offer flexibility in terms of customization. Users can focus on specific aspects of attention, such as visualizing attention heads or attention layers within the model.Customization options allow researchers and practitioners to tailor their visualizations to specific research questions or areas of interest.
- Integration with Transformer Models: TensorFlow seamlessly integrates with transformer-based models. Users can load pre-trained transformer models or implement custom architectures using TensorFlow's high-level APIs.This integration ensures that attention visualization tools can be applied to various transformer models, from basic architectures to state-of-the-art variants.
- Open-Source Libraries and Resources: TensorFlow's open-source nature has led to the development of libraries and resources for attention visualization. These libraries often provide pre-built functions and code examples for creating attention heatmaps.Users can use community-contributed tools and expand upon them for their specific needs.
- Interpretability and Debugging: In addition to attention visualization, TensorFlow offers a broader set of interpretability and debugging tools for deep learning models. These tools can aid in understanding model behaviour, identifying issues, and improving model performance.Debugging capabilities ensure that transformer models make reliable and accurate predictions.
- Community Support and Tutorials: TensorFlow boasts a vast and active user community. This community provides support, forums, and tutorials for users interested in attention visualization and model interpretability.TensorFlow's extensive documentation and educational resources make it accessible to beginners and experienced practitioners.

Heatmaps and Saliency Maps
Heatmaps and saliency maps are valuable visualization techniques used to understand and interpret the behaviour of transformer-based models, especially in natural language processing (NLP) tasks. These visualizations provide insights into which parts of the input data the model focuses on and how specific input features contribute to the model's predictions. Let's explore these two techniques in detail:
Heatmaps
Heatmaps are graphical representations that display the relative importance or attention weights the model assigns to different parts of the input sequence. They are particularly useful for visualizing how attention is distributed across tokens or features.
Uses of Heatmaps in Transformers:
-
In transformer models with multi-head attention mechanisms, each attention head produces its heatmap. These heatmaps show which tokens in the input sequence receive the most attention from each head.
-
Heatmaps are often displayed as grids, where rows represent the source tokens, and columns represent the target tokens. Brighter colours or higher values in the grid indicate higher attention weights.
-
Interpretation:
- Identifying Relevance: Attention heatmaps visually represent where the model focuses its attention within the input text. Darker regions indicate lower attention weights, while brighter regions indicate higher ones. By examining these heatmaps, researchers and practitioners can identify which parts of the input text the model considers most relevant for making predictions.
- Understanding Attention Patterns: Attention heatmaps reveal intricate attention patterns within the input text. Researchers can observe how the model allocates attention across different tokens or words. Patterns may include:
- Local Attention: The model may concentrate on nearby tokens, focusing on the local context.
- Global Attention: The model may distribute attention more evenly across the entire input, suggesting a broader context is considered.
-
Applications of Attention Heatmaps:
- Machine Translation: One of the primary applications of attention heatmaps is in machine translation. These heatmaps visualize how the model aligns words in the source language with words in the target language during translation.Heatmaps provide a valuable visual aid for linguists and translators, allowing them to understand how the model generates translations and aligns source and target language tokens.
- Summarization: In text summarization tasks, attention heatmaps help identify which parts of the source document are most influential in generating the summary.Summarization models use attention mechanisms to select and prioritize important sentences or phrases from the source text, and heatmaps reveal this selection process.
- Sentiment Analysis: In sentiment analysis, attention heatmaps can help identify critical phrases or words that influence the model's sentiment prediction.Researchers and analysts can use heatmaps to explain why the model classified a text as positive, negative, or neutral, shedding light on the sentiment cues it relies on.
Saliency Maps
Saliency maps highlight individual input features (e.g., tokens in a text sequence) for the model's predictions. They help identify which features most influence the model's output.
Uses of Saliency Maps in Transformers:
-
Saliency maps are often generated by computing gradients of the model's output concerning the input features in the context of transformer-based models. These gradients indicate how changes in individual features affect the model's prediction.
-
High gradient values for a particular feature suggest that changing or removing that feature would significantly impact the model's prediction.
-
Interpretation:
- Localized Feature Importance: Saliency maps offer a localized view of feature importance within the input sequence, typically a text document or sentence. These maps highlight individual words or tokens that have the most significant impact on a specific prediction made by the model.Bright regions in the saliency map correspond to words or tokens that strongly contribute to the model's output, while darker regions indicate less influential elements.
- Identifying Influential Words/Tokens: By examining saliency maps, researchers and practitioners can pinpoint which specific words or tokens in the input sequence drive a particular prediction or classification.This pinpointing of influential words or tokens is invaluable for understanding why the model made a specific decision, shedding light on the key factors that guided the model's judgment.
- Quantifying Feature Contribution: Saliency maps provide a quantitative measure of how much each word or token contributes to the prediction. High saliency values indicate a substantial contribution, while low values indicate lesser relevance.This quantitative aspect allows for a more precise analysis of feature importance.
-
Applications of Saliency Maps:
- Text Classification: Saliency maps are extensively used in text classification tasks, where the goal is to categorize text documents into predefined classes (e.g., spam vs. not spam, positive vs. negative sentiment, topic classification).These maps help identify the specific words or phrases that influenced the model's decision to assign a particular class label to a document.
- Sentiment Analysis: In sentiment analysis, where the objective is to determine the sentiment expressed in a text (e.g., positive, negative, neutral), saliency maps assist in understanding the keywords or phrases that led to the sentiment prediction.Analysts can use saliency maps to extract sentiment-carrying words, allowing for more precise sentiment interpretation and analysis.
- Keyword Extraction: Saliency maps are a valuable resource for keyword extraction, which is essential in information retrieval and content summarization.Analysts and search engines can use saliency maps to automatically identify and extract the most relevant keywords or phrases from a document, improving search results and content summarization.
LIME (Local Interpretable Model-agnostic Explanations)
LIME is a powerful technique for local interpretability to machine learning models, including transformer-based models like BERT and GPT. It focuses on explaining the predictions of complex models by approximating them with simpler, transformers interpret models at the local level. Let's delve deeper into how LIME works and its significance in understanding transformer model predictions.
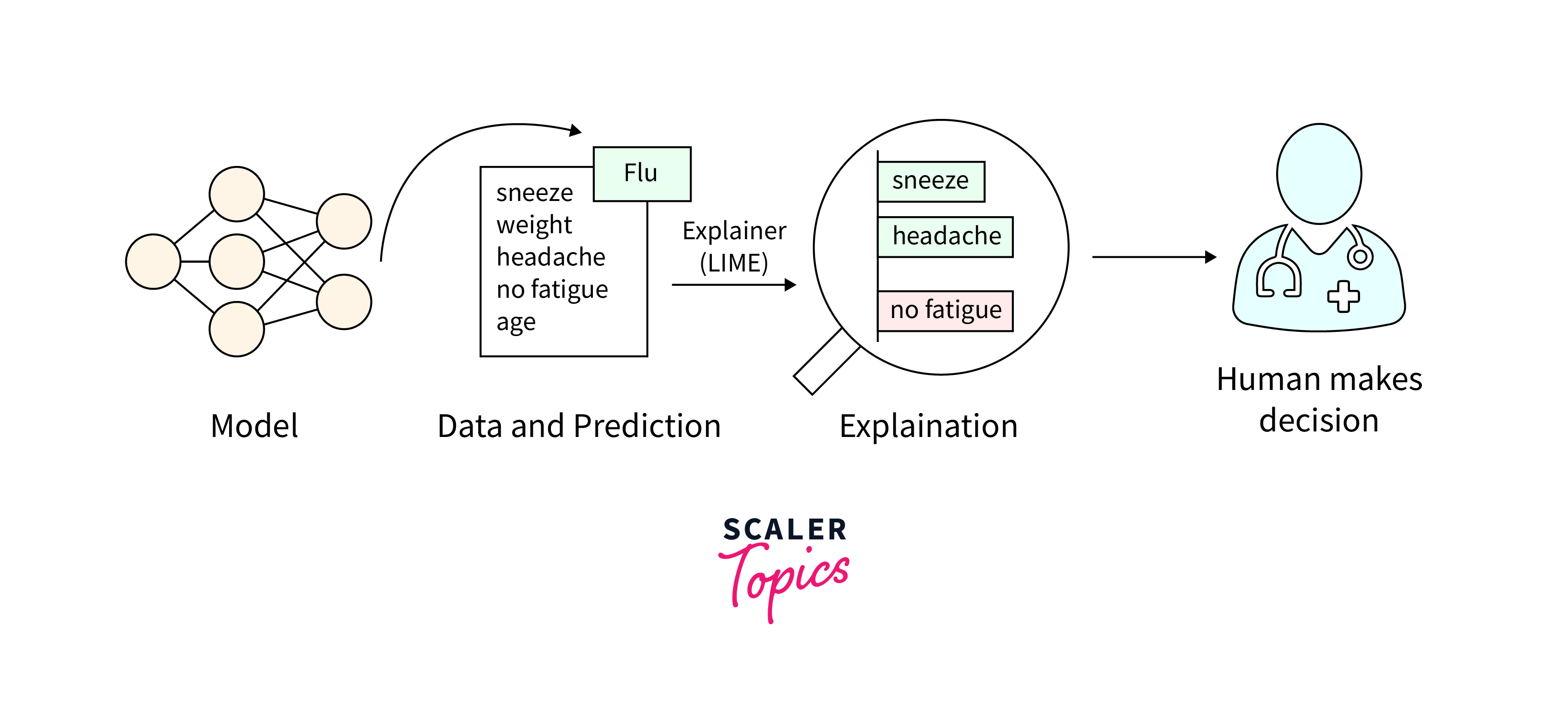
How LIME Works:
- Local Perturbations: LIME starts by taking an instance or input data point for which you want an explanation. In the context of transformer models, this input data point could be a text sequence.
- Random Perturbations: LIME generates multiple perturbed input versions by making random changes. These changes involve removing or replacing words or tokens for text data.
- Model Predictions: The original transformer model (the one you want to explain) predicts both the original and perturbed instances. This step provides pairs of input-output data points.
- Simpler Model: LIME fits a simpler, interpretable model (e.g., linear regression or decision tree) to the pairs of input-output data points from the perturbed instances. This transformers interpret model is called the "local surrogate model."
SHAP (SHapley Additive exPlanations)
SHAP is a powerful framework for explaining the output of machine learning models by attributing the contribution of each input feature to the model's prediction. It provides a unified approach to feature importance and is particularly useful for understanding the behavior of complex models, including transformer-based models like BERT and GPT. Let's explore how SHAP works and its significance in model transformers interpret.
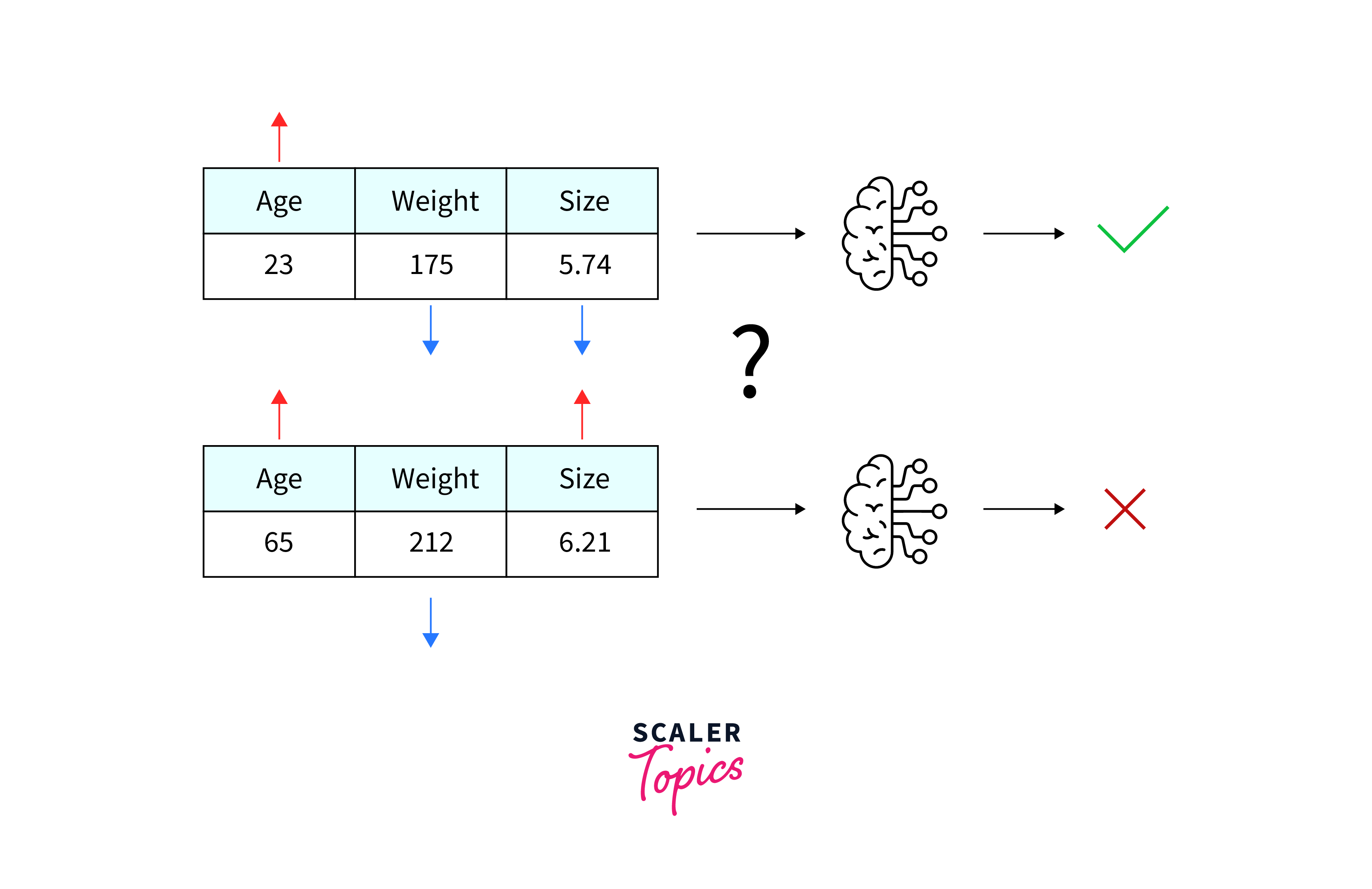
How SHAP Works:
- Concept of Shapley Values: SHAP is based on Shapley values from cooperative game theory. In machine learning, Shapley values represent the average contribution of a feature to all possible coalitions of features. In other words, they quantify the impact of each feature when considering all possible combinations of features.
- Model Agnostic: SHAP is model-agnostic, meaning it can be applied to any machine learning model, regardless of its complexity. This includes black-box models like transformer-based models.
- Explanation for a Single Prediction: To explain a single prediction made by the model (e.g., classifying a text), SHAP computes the Shapley values for each input feature (e.g., words or tokens in the text). These values represent the contribution of each feature to the prediction for that specific instance.
Integrated Gradients
Integrated Gradients is a valuable technique for understanding the importance of input features in machine learning models, including transformer-based models like BERT and GPT. It provides a comprehensive way to attribute a model's prediction to individual features or components of the input data. Integrated Gradients are particularly useful for model interpretability and explaining why a model made a specific prediction.
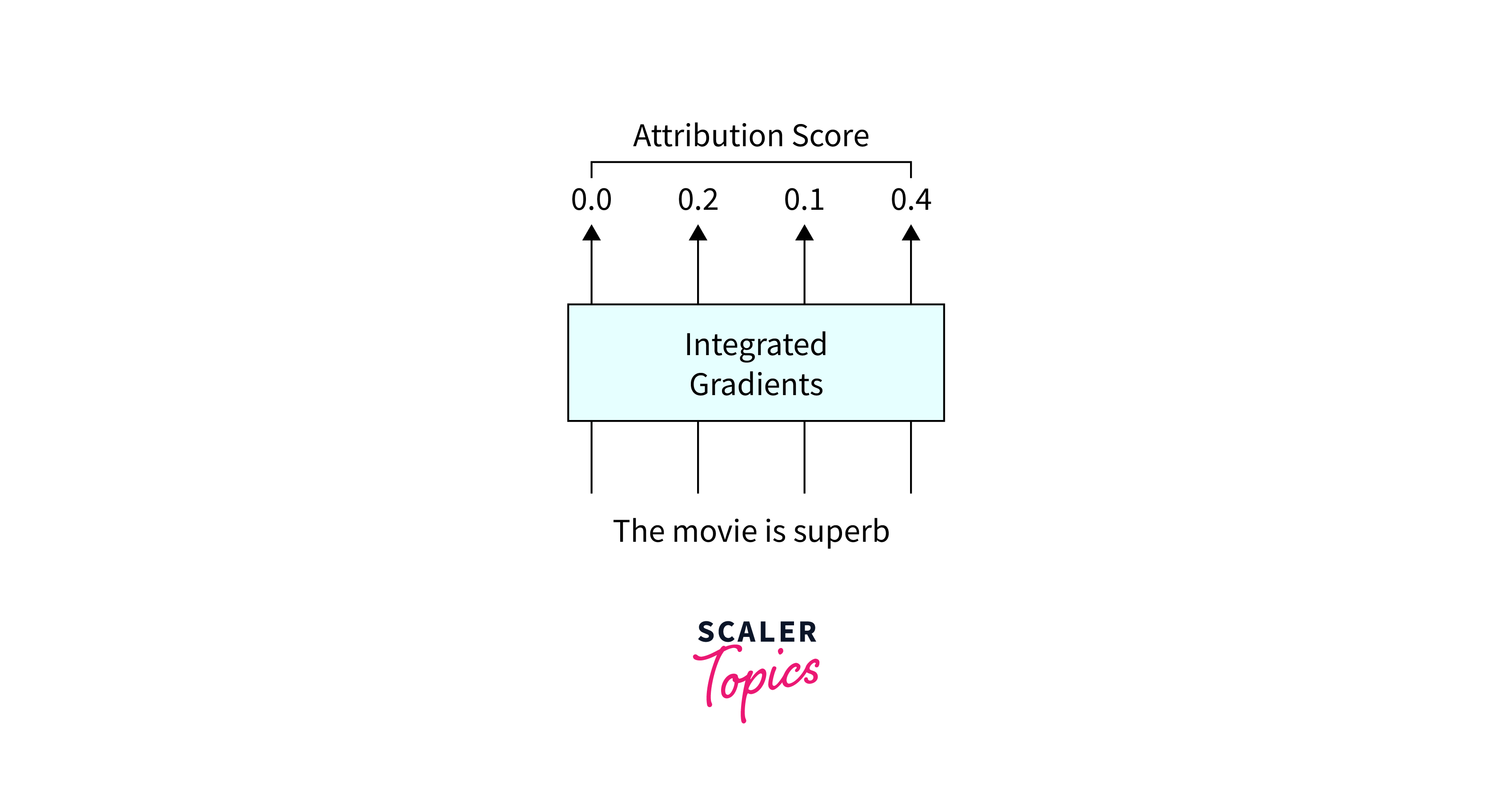
How Integrated Gradients Works:
- Baseline Input: Integrated Gradients start by defining a baseline or reference input. This baseline represents a "neutral" or "zero-impact" state. It is often chosen as a point where some or all input features are set to their minimum or maximum values or a predefined reference point.
- Path Integration: Next, Integrated Gradients compute the gradient of the model's prediction concerning the input features along a straight path from the baseline input to the actual input.
- Integration: The technique integrates the gradients along this path. It calculates the area under the curve formed by the gradients. This integration process measures the cumulative impact of each feature as you move from the baseline to the actual input.
- Feature Attribution: Integrated Gradients results in a set of attribution scores, one for each input feature. These scores represent how each feature contributed to the model's prediction for the given instance. Higher scores indicate more significant contributions.
Interpretability Tools and Libraries
Interpreting the inner workings of transformer-based models and ensuring their transparency is crucial for their practical and ethical use. Several tools and libraries have been developed to facilitate the interpretability of these models. These tools help users visualize attention, feature importance, and other aspects of model behavior. Here are some popular interpretability tools and libraries:
1. Hugging Face Transformers:

Hugging Face Transformers is a comprehensive library for working with pre-trained transformer-based models. It provides built-in support for various NLP tasks and includes tools for model interpretation.
Features:
- Attention Visualization: Hugging Face Transformers allows users to visualize attention mechanisms within transformer models. You can generate attention heatmaps and explore how the model attends to input tokens.
- Interpretability Tools: The library offers functions for extracting and transformers interpret model features, including attention scores and embeddings.
- Model Explainability: Hugging Face Transformers provides support for model explainability techniques like LIME and SHAP.
2.Captum (PyTorch):

Captum is a PyTorch library for transformers interpret. It can be used with transformer models implemented in PyTorch.
Features:
- Integrated Gradients: Captum includes the Integrated Gradients technique for understanding feature importance in models.
- Layer Attribution: It offers layer-wise attribution methods to analyze the impact of different layers in deep models.
- Custom Attribution: Captum allows users to create custom attribution rules for specific interpretability needs.
3. InterpretML:
 InterpretML is a library for model-agnostic interpretability. While it's not specific to transformers, it can be applied to a wide range of models.
InterpretML is a library for model-agnostic interpretability. While it's not specific to transformers, it can be applied to a wide range of models.
Features:
- Feature Importance: InterpretML provides techniques for feature importance analysis.
- Local Interpretability: It supports local transformers interpret methods like LIME and SHAP.
- Model Debugging: InterpretML aids in model debugging by identifying issues in model predictions.
Conclusion
- Transformer-based models have revolutionized NLP, achieving remarkable performance across various tasks.
- Transformer models' complexity necessitates interpretability tools like attention visualization, LIME, SHAP, and Integrated Gradients.
- Libraries such as Hugging Face Transformers, Captum, InterpretML, and AllenNLP Interpret empower users to understand, debug, and trust transformer models.
- transformers interpret is an evolving field, ensuring responsible AI usage and enhancing the transparency of AI-driven decisions.