Understanding Transformer Benchmarks
Overview
The field of Natural Language Processing (NLP) has seen remarkable advancements in recent years. The transformer-based models, such as BERT, GPT-3, and their numerous variants, have achieved state-of-the-art results on a wide range of NLP tasks. However, assessing the performance of these models and comparing them effectively requires a standardized set of benchmarks and evaluation metrics. In this blog post, we will delve into the world of transformer benchmarks, exploring common NLP benchmarks and model-specific benchmarks, while also discussing the evaluation metrics that play a crucial role in assessing their performance.
Introduction
Transformer-based models have revolutionized the field of NLP. These models employ a self-attention mechanism to process input data in parallel, making them highly effective at capturing contextual information. As a result, they have become the backbone of various NLP applications, including machine translation, sentiment analysis, question-answering, and more. To gauge the capabilities of these models and drive further advancements, researchers and practitioners have developed a range of benchmarks to evaluate their performance systematically.
Common NLP Benchmarks
1. GLUE (General Language Understanding Evaluation)
GLUE is one of the most well-known benchmark datasets in the NLP community. It consists of nine diverse NLP tasks, including sentence-level and document-level classification, textual entailment, and question-answering. Each task is designed to assess different aspects of language understanding, making GLUE a comprehensive benchmark for evaluating the generalizability of transformer-based models. Some of the tasks included in GLUE are:
-
MNLI (MultiNLI): This task focuses on natural language inference, where models must determine whether one sentence entails, contradicts, or is neutral with respect to another sentence.
-
SST-2 (Stanford Sentiment Treebank): SST-2 involves sentiment analysis, requiring models to predict the sentiment of a given sentence as either positive or negative.
-
QQP (Quora Question Pairs): In this task, models must identify whether a pair of questions is semantically equivalent.
-
RTE (Recognizing Textual Entailment): Similar to MNLI, RTE assesses the ability of models to recognize textual entailment relationships between two sentences.
-
WNLI (Winograd NLI): WNLI is a coreference resolution task where models need to determine if a pronoun in a sentence refers to the correct noun.
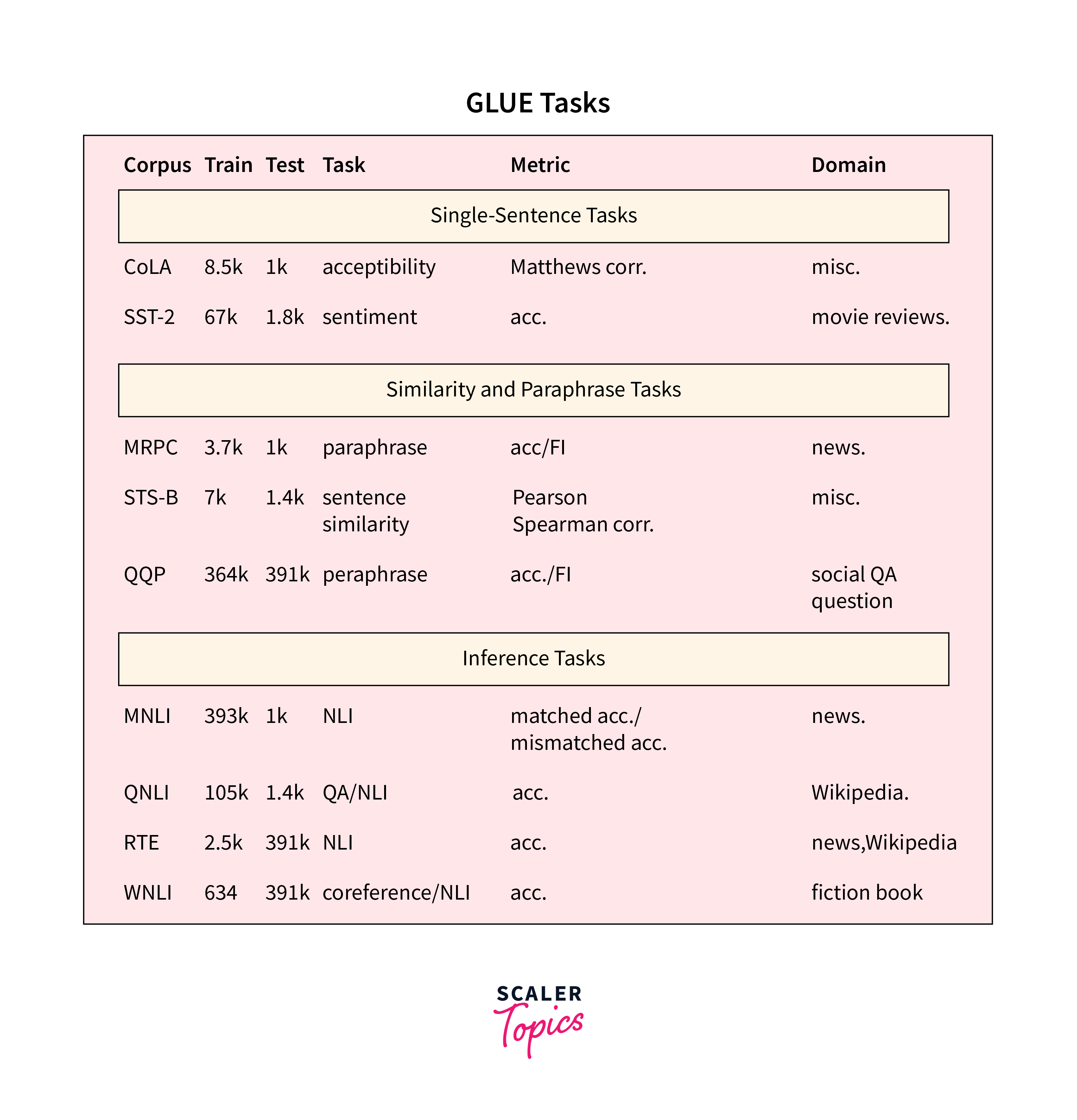
The GLUE benchmark provides a holistic evaluation of a model's ability to perform various NLP tasks, allowing researchers to gauge its general language understanding capabilities.
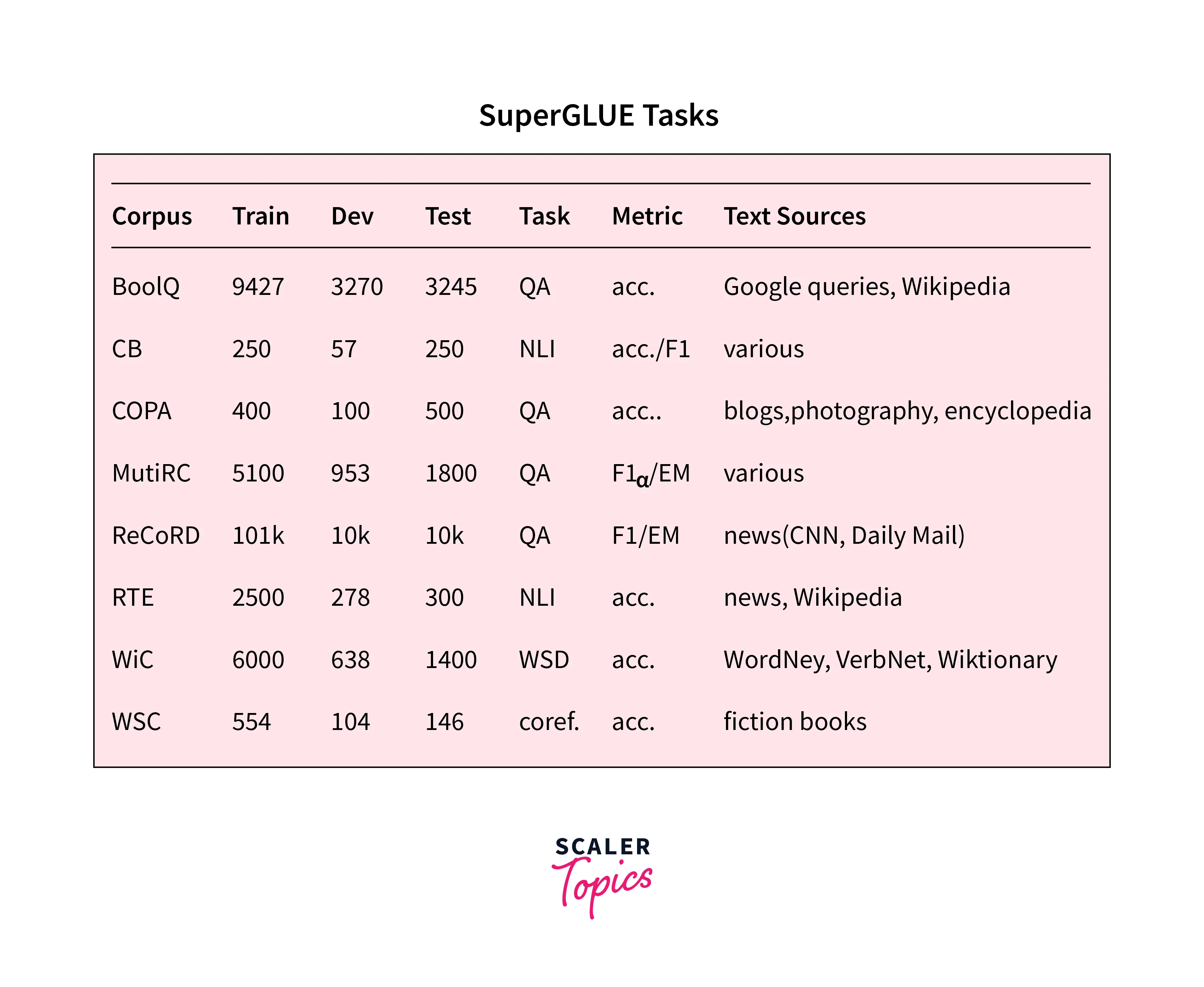
2. SuperGLUE
Building on the success of GLUE, SuperGLUE takes the evaluation of transformer-based models a step further by introducing more challenging tasks. It includes tasks like BoolQ (Boolean Questions), which focuses on answering yes/no questions, and COPA (Choice of Plausible Alternatives), which requires models to choose the correct cause-effect relationship between two sentences. SuperGLUE sets a higher bar for assessing models' reasoning abilities and generalization capabilities.
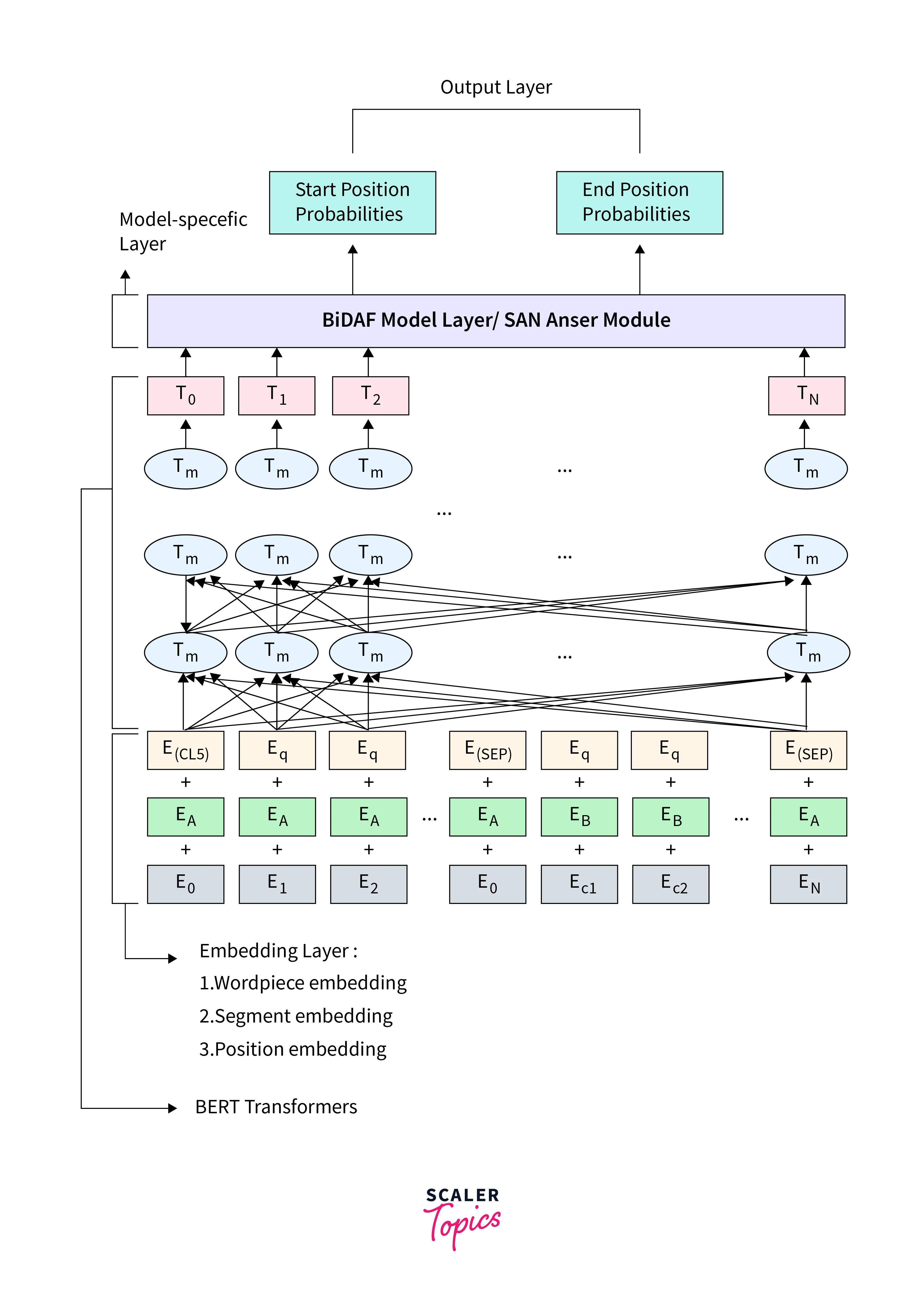
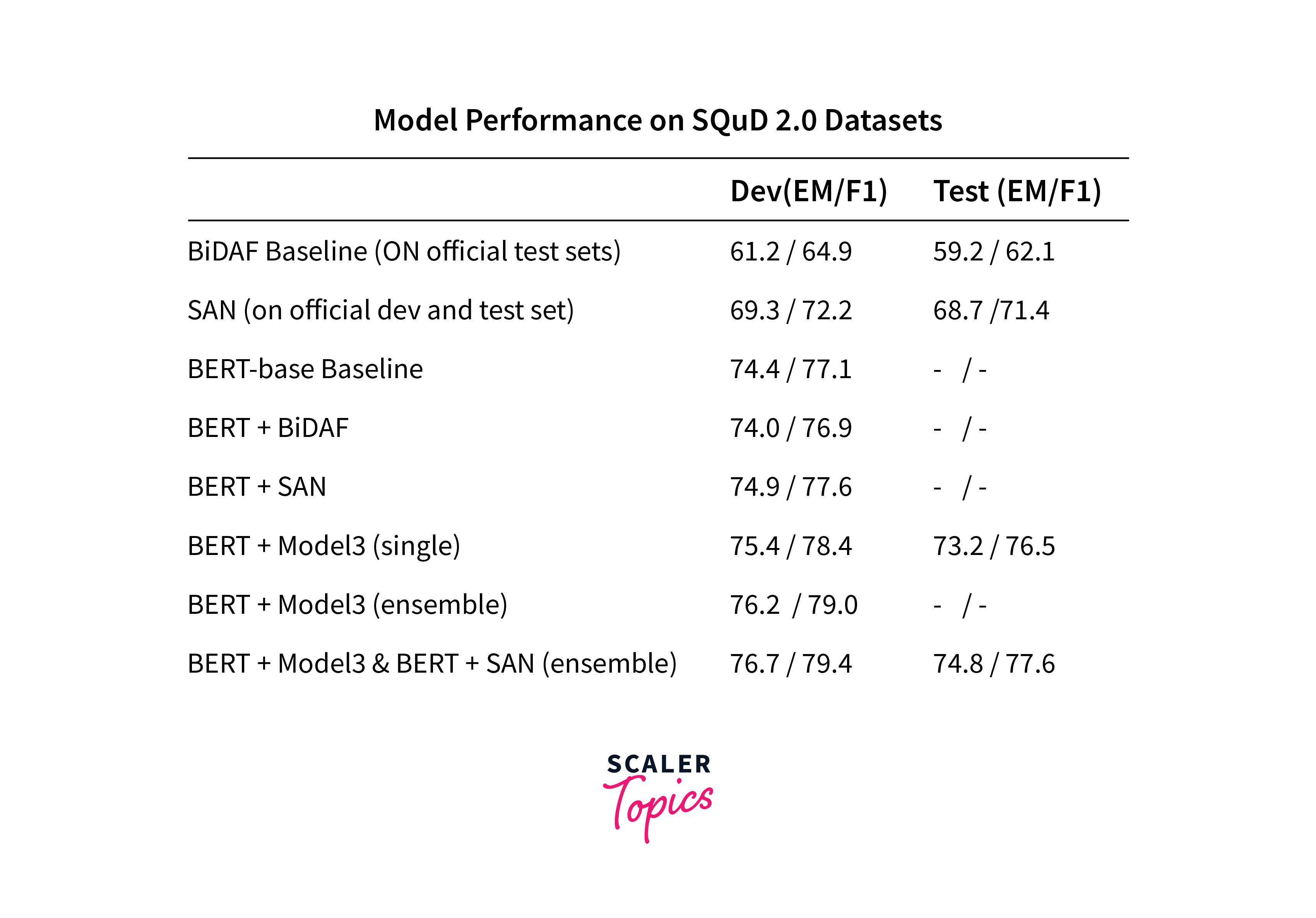
3. SQuAD (Stanford Question Answering Dataset)
SQuAD is a widely used benchmark for evaluating question-answering systems. It consists of a collection of paragraphs from Wikipedia, along with questions that can be answered using the information in the paragraphs. Models are evaluated based on their ability to extract precise answers from the passages. SQuAD has played a pivotal role in advancing the development of models like BERT, which achieved remarkable results on this benchmark.
4. WMT (Workshop on Machine Translation) Benchmarks
Machine translation is another key area where transformer-based models have excelled. The WMT benchmarks consist of tasks related to machine translation, including translating from one language to another. These benchmarks help evaluate models' language generation and translation abilities. Tasks like WMT14 and WMT19 assess models' performance on translating between various language pairs.
Model-Specific Benchmarks
While common benchmarks like GLUE and SQuAD offer a broad evaluation of transformer models, there are also model-specific benchmarks designed to test the unique capabilities of individual models. These benchmarks are tailored to the strengths and characteristics of specific architectures. Here are a few notable examples:
GPT-3's Few-Shot Learning
GPT-3, developed by OpenAI, gained fame for its impressive few-shot learning abilities. It can perform a wide range of language tasks with minimal task-specific training data. Benchmarks like the GPT-3 Few-Shot benchmark evaluate the model's capacity for zero-shot and few-shot learning, where it must generalize from a few examples provided in the prompt.
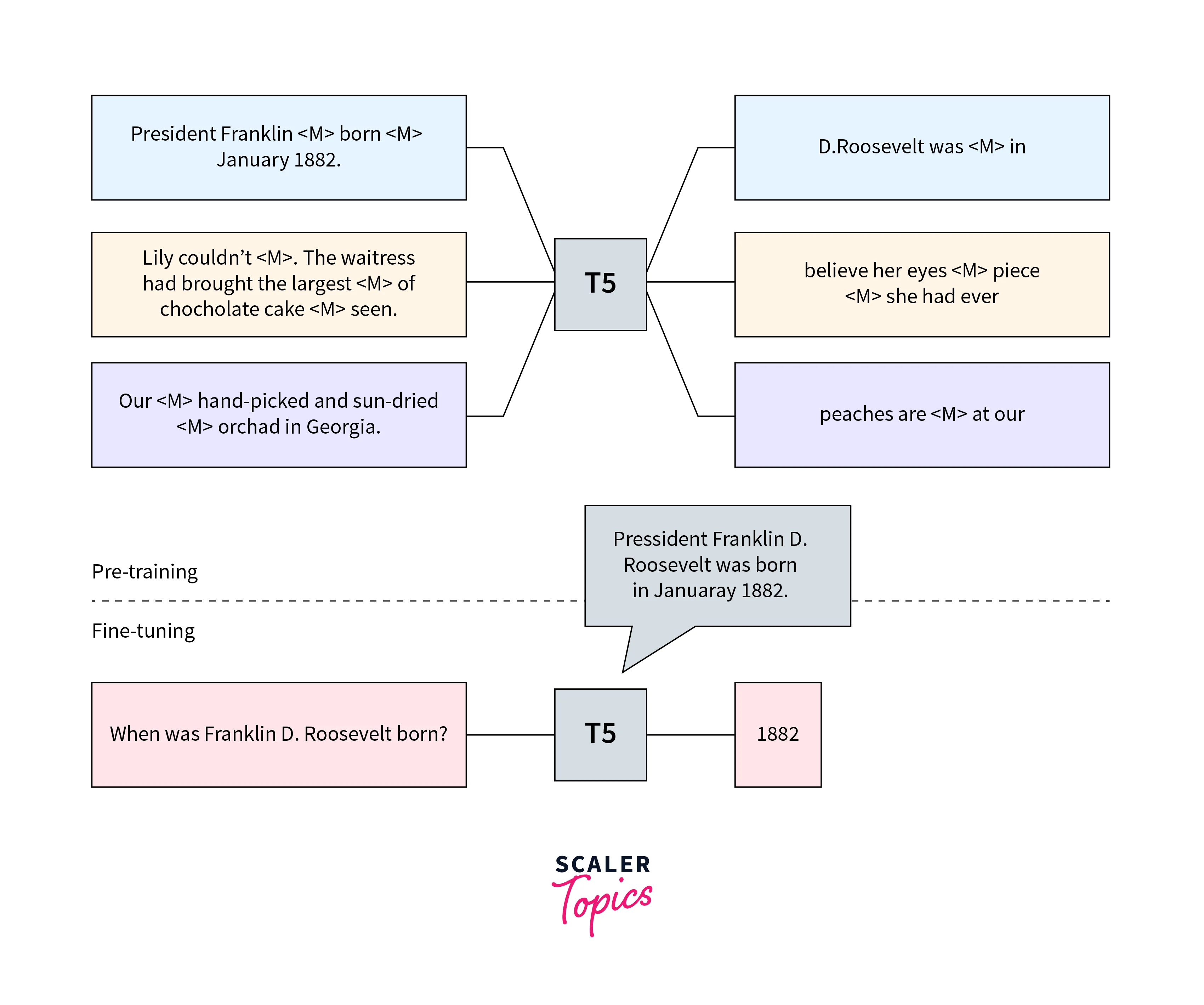
T5's Text-to-Text Framework
The Text-to-Text Transfer Transformer (T5) introduced a novel framework where all NLP tasks are framed as text-to-text problems. This model aims to unify various NLP tasks under a single framework. Model-specific benchmarks for T5 focus on evaluating its performance within this text-to-text paradigm, showcasing its ability to handle diverse tasks with a consistent approach.
Evaluation Metrics
Assessing the performance of transformer-based models on benchmarks requires the use of appropriate evaluation metrics. These metrics provide quantitative measures of a model's effectiveness on specific tasks. Here are some commonly used evaluation metrics:
1. Accuracy
Accuracy is a straightforward metric used for classification tasks. It measures the proportion of correctly predicted instances out of the total instances. The equation for accuracy is:
2. F1 Score
The F1 score combines precision and recall and is often used for imbalanced datasets or tasks where false positives and false negatives have different costs. It provides a balanced measure of a model's performance. The equation for the F1 score is:
where precision is the number of true positives divided by the sum of true positives and false positives, and recall is the number of true positives divided by the sum of true positives and false negatives.
3. BLEU Score
The BLEU (Bilingual Evaluation Understudy) score is commonly used for machine translation tasks. It measures the similarity between the machine-generated translation and one or more reference translations. The BLEU score is calculated based on the precision of n-grams (sequences of words) in the generated translation compared to the reference translations. The equation for the BLEU score is:
where BP is the brevity penalty, w_n is the weight assigned to the precision of n-grams, and p_n is the precision of n-grams.
4. ROUGE Score
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score is a metric used for evaluating the quality of machine-generated text in tasks such as text summarization. It assesses the overlap of n-grams (sequences of words) between the generated text and reference summaries. The ROUGE score is calculated based on the precision, recall, and F1 score of n-grams. The equation for the ROUGE score depends on the specific variant of ROUGE being used.
| Metric | Description | Formula |
|---|---|---|
| ROUGE Score | Measures the quality of machine-generated text, commonly used for text summarization. | Depends on precision, recall, and F1 score of n-grams. |
| Precision | Ratio of overlapping n-grams between the generated text and reference summaries to the total n-grams in the generated text. | (Number of overlapping n-grams) / (Total n-grams in generated text) |
| Recall | Ratio of overlapping n-grams between the generated text and reference summaries to the total n-grams in the reference. | (Number of overlapping n-grams) / (Total n-grams in reference) |
| F1 Score | The harmonic mean of precision and recall. | (2 * Precision * Recall) / (Precision + Recall) |
5. Exact Match (EM) and F1 for SQuAD
In the SQuAD benchmark, models are evaluated based on their ability to provide exact answers to questions. The Exact Match (EM) metric measures the percentage of questions for which the model's answer is an exact match to the ground-truth answer. The equation for the EM metric is:
The F1 score in this context measures the overlap between the model's answer and the ground-truth answer. The equation for the F1 score is the same as mentioned earlier, which combines precision and recall.
| Metric | Description | Formula |
|---|---|---|
| Accuracy | Measures correct predictions in classification tasks. | Accuracy = (Number of correctly predicted instances) / (Total number of instances) |
| F1 Score | Balances precision and recall. | F1 score = 2 * (precision * recall) / (precision + recall) |
| ROUGE Score | Evaluates machine-generated text quality. | Depends on precision, recall, and F1 score of n-grams |
| Exact Match (EM) | Measures exact answers in SQuAD. | EM = (Number of questions with exact match answers) / (Total number of questions) |
| F1 Score (SQuAD) | Measures answer overlap in SQuAD. | F1 score = 2 * (precision * recall) / (precision + recall) |
Conclusion
- Understanding transformer benchmarks is crucial for researchers, practitioners, and enthusiasts in the NLP community.
- Common benchmarks like GLUE, SuperGLUE, SQuAD, and WMT provide a standardized way to evaluate models' performance on various tasks, while model-specific benchmarks offer tailored assessments.
- With the right evaluation metrics, we can systematically measure and compare the capabilities of these models, driving further progress in the field of NLP.
- As transformer-based models continue to evolve, so too will the benchmarks and metrics used to evaluate their performance, making the journey of understanding transformer benchmarks an ongoing and exciting one.