Normalization of Text in NLP
Overview
Natural Language Processing is one of the hottest topics of artificial intelligence right now. The concept of a computer understanding and reacting to human language is extremely fascinating. There are a plethora of algorithms and techniques in NLP that we have to apply in order to build a good machine-learning model. One of the most important subfields of NLP is text normalization. This is a cornerstone technique for NLP processes dealing with text data.
Introduction
So what is text normalization in NLP? We know that the raw text data is random. Each word has a lot of variations in the form of tenses, superlatives, and many more. These variations increase the complexity of the data and are difficult for the machine learning model to train them. Text normalization reduces this complexity by reducing the text data into a predefined standard, hence improving the efficiency of the model. Any word or a token is made up of two things: The base form(Morpheme) and an inflectional form like the prefix or the suffix. Text normalization reduces the word to its base form by removing the inflectional part. There are two main approaches toward text normalization in NLP: Stemming and Normalization. We will discuss them at a later stage in this article.
Why Do We Need Text Normalization in NLP?
Text normalization is a very important and integral step in Natural Language processing. It is used in speech recognition, text-to-speech, spam email identification, and many other applications of NLP. Consider the words: "collection", "collective","collect", and "collectively".These words are different forms of the base word "collect". Human language has randomness as its inherent feature. We take the base form of a word and use it in its random states. It is important to remove this randomness for our computers as they are not as good as us at handling this. Text normalization is applied to raw text to reduce this randomness. If we reduce the variations of a word in the raw text, there will be fewer input variables for our machine-learning model to deal with, thus increasing efficiency and avoiding false negatives. Text normalization reduces the dimensionality of the input for structures like bag-of-words and tf-idf dicts.
Tokenization
In this process, we break down a piece of input text into smaller units called tokens. This helps in treating each token(word, character, etc.) as an individual component for further processing and analysis. The text is commonly converted into individual tokens by splitting them from whitespaces. Sentence: "I am a big fan of metal music!" Whitespace tokenizer: "I","am","a","big","fan","of","metal","music!" Regular expressions can also be used for tokenization.
Output
The most commonly used way to implement tokenization is by using the NLTK library in python.
Output
What is Stemming?
Stemming is a basic way of implementing text normalization in NLP. In this process, we get rid of the inflectional part of the word(prefixes and suffixes) by stripping them off. In other words, we get a stem of the word. Stemming does not consider the semantic meaning of the words while reducing them. This is a major drawback because the root word formed may have lost its semantic meaning. For example, the word "laziness" will be reduced to "lazy" and not "lazy".
The NLTK library has PorterStemmer for the purpose of stemming.
Output
As you can see the word "however" is reduced to "however" which has no meaning. This occurs due to two conditions:-
- Over-stemming: The stemmer chops the word more than what's required. For example, Both the words "university" and "universe" are chopped to the word "universe", which incorrectly implies that both of them have the same meaning.
- Under-stemming: This happens when two or more words are reduced to different root words but could have been reduced to the same root word. For example, the words "data" and "datum" may be stemmed from "dat" and "datu" by some algorithms.
What is Lemmatization?
This approach of text normalization overcomes the drawback of stemming and hence is perfect for the task. Lemmatization makes use of the vocabulary, parts of speech tags, and grammar to remove the inflectional part of the word and reduce it to lemma. Lemmatization uses a pre-defined dictionary to store the context words and reduces the words in data based on their context. NLTK uses the WordNetLemmatizer for the purpose of lemmatization.
Output
Levenshtein Distance
Levenshtein distance is the distance or the measurement required to transform one string(word) into another. There are three basic steps to convert one word to another:-
- Insert
- Delete
- Replace
These three operations are assigned a particular cost. The overall cost will be the Levenshtein distance of the transformation.
Let's take an example:-
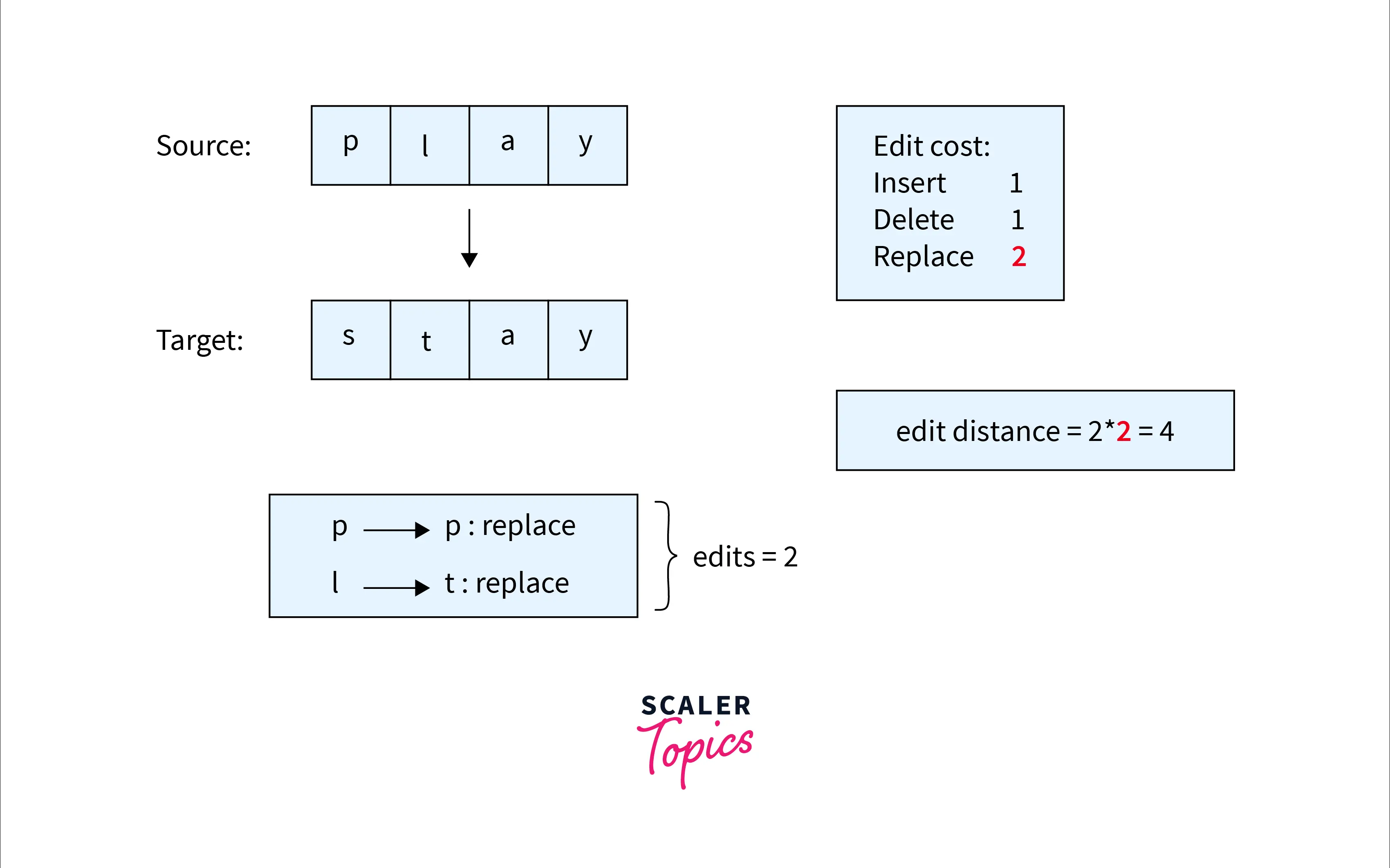
We have to convert the word "play" to "stay". The insert and delete operations cost one unit, whereas the replace operation costs two units. The conversion can be done in two ways:-
- Delete "p" and "l" in the word "play" and insert "s" and "t" respectively. The cost here will be 4(two insert and two delete operations).
- Replace "p" with "s" and "l" with "t". The cost here will be 4(Two replacement operations.)
Soundex
While Levenshtein distance calculates the difference between two words, Soundex, a phonetic algorithm decides the closeness between two words based on their pronunciations. This works by converting the input word to a four or more-character value and then we compare it two the other word. These are the steps involved:-
- Except for the first letter remove all occurrences of a, e, i, o, u, y, h, w.
- Replace all consonants with digits.
- b, f, p, v → 1
- c, g, j, k, q, s, x, z → 2
- d, t → 3
- l → 4
- m, n → 5
- r → 6
- Replace adjacent same digits with the digit.
- If the saved letter’s digit is the same as the resulting first digit, remove the digit (keep the letter).
- Append 3 zeros if the result contains less than 3 digits. Remove all except the first letter and 3 digits after it.
The words "Rupert" and "Robert" have the value R163.
Conclusion
The key takeaways from this article are:-
- Text normalization is crucial before implementing plenty of NLP tasks with text data.
- Without text normalization, there will be a lot of noise and unwanted data left to train the machine learning model.
- We learned about tokenization, where we take a piece of text and reduce it to its individual components.
- The two most important text normalization steps are stemming and lemmatization. Lemmatization, unlike stemming, brings out the root form of a word while keeping the semantic meaning intact.
- Finally, we learned about the intuitive concepts of Levenshtein distance and Soundex.