Word2Vec in NLP

Overview
The main principle of Word2Vec is that a model that can accurately predict a given word given its neighbors or, conversely, predicts the neighbors of a given word given its neighbors will likely capture the contextual meanings of words very well. These are two variations of Word2Vec models: a continuous bag of words, in which we are given nearby words, and skip-gram, in which we are given the middle word.
What is Word2Vec?
Word embedding is one of the most used methods for expressing document vocabulary. It can determine a word's placement within a text, its relationship to other words, and any semantic and syntactic similarities.
Word2Vec builds word vectors, which are distributed numerical representations of word features. These word features may include words that indicate the context of the specific vocabulary words present individually. Through the generated vectors, word embeddings eventually assist in forming the relationship of a word with another word having a similar meaning.
The Word2Vecpython prediction model is especially effective at learning word embeddings from raw text.
How does Word2Vec Work?
Word2Vec explained employs a machine-learning technique that you may have seen before. Word2Vec is a simple neural network with one hidden layer. It has weights, like all neural networks, and during training, its objective is to modify those weights to lower a loss function. Word2Vec will not be applied to the job for which it was trained; rather, we will use its hidden weights as our word embeddings and discard the remainder of the model.
First of all, Neural networks accept a word as input. As an alternative, we feed words as one-hot vectors, vectors of the same length as the vocabulary that is zeroed out everywhere but the index corresponding to the word we wish to represent, which is given the value "1".
The word embeddings serve as the weights of the hidden layer, which is a typical fully-connected (Dense) layer. Probabilities for the target words in the vocabulary are output by the output layer.
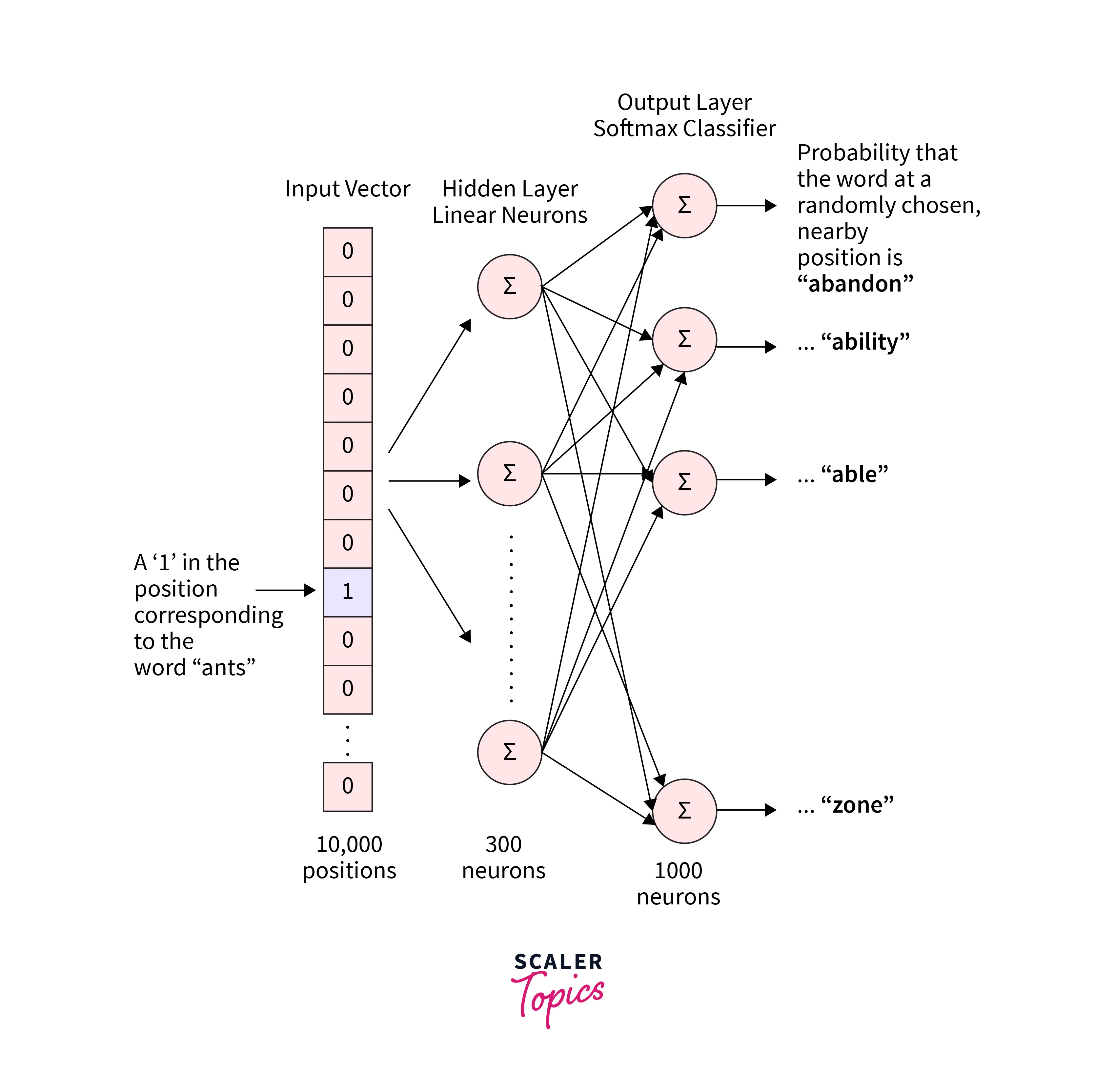
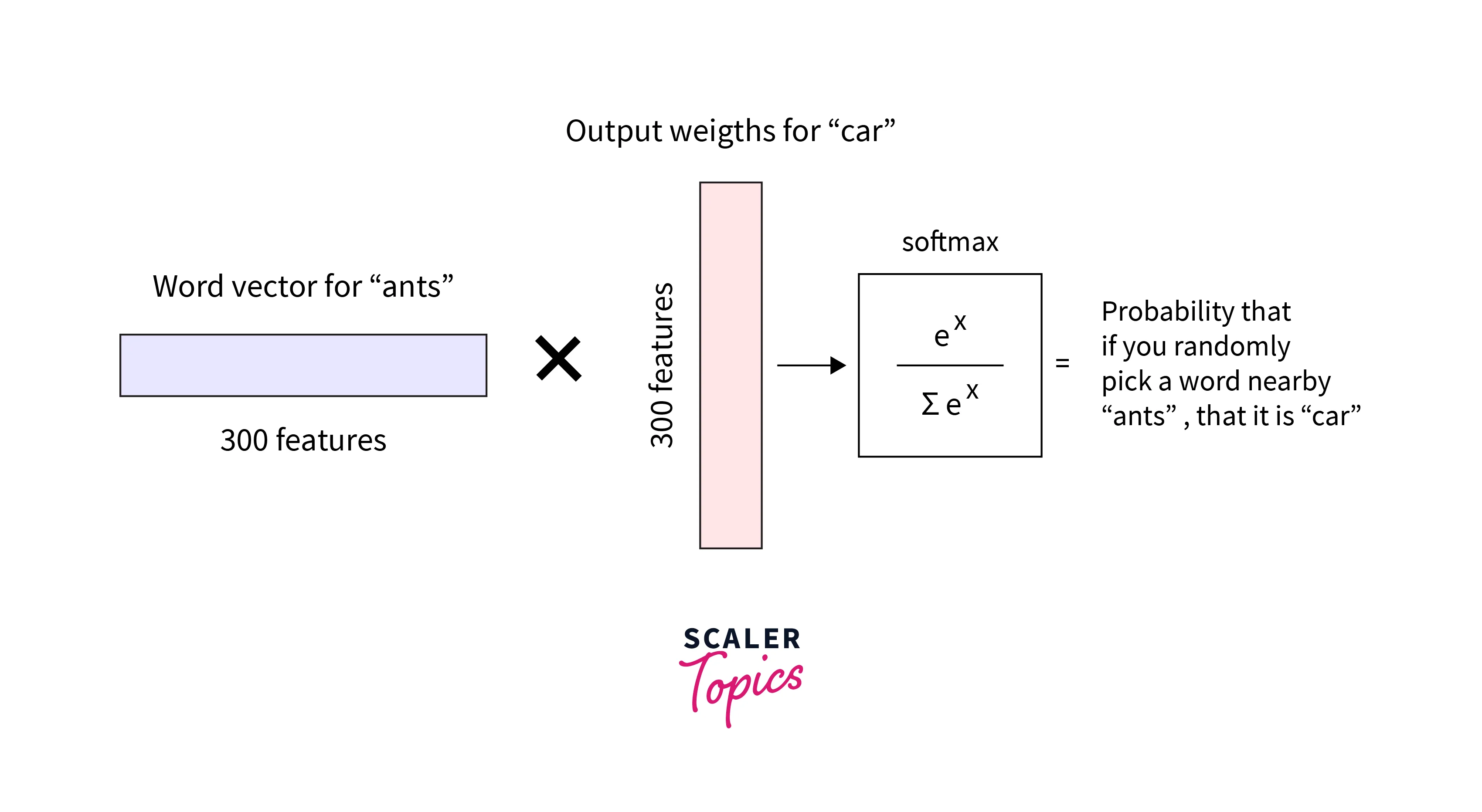
The "word vector" for the input word is all the hidden layer outputs. A 1 x 10,000 one-hot vector will merely select the matrix row corresponding to the number "1" if multiplied by a 10,000 x 300 matrix.
Finding the hidden layer weight matrix is the outcome of all of this, after which we can discard the output layer. Simply a softmax activation algorithm makes up the output layer.
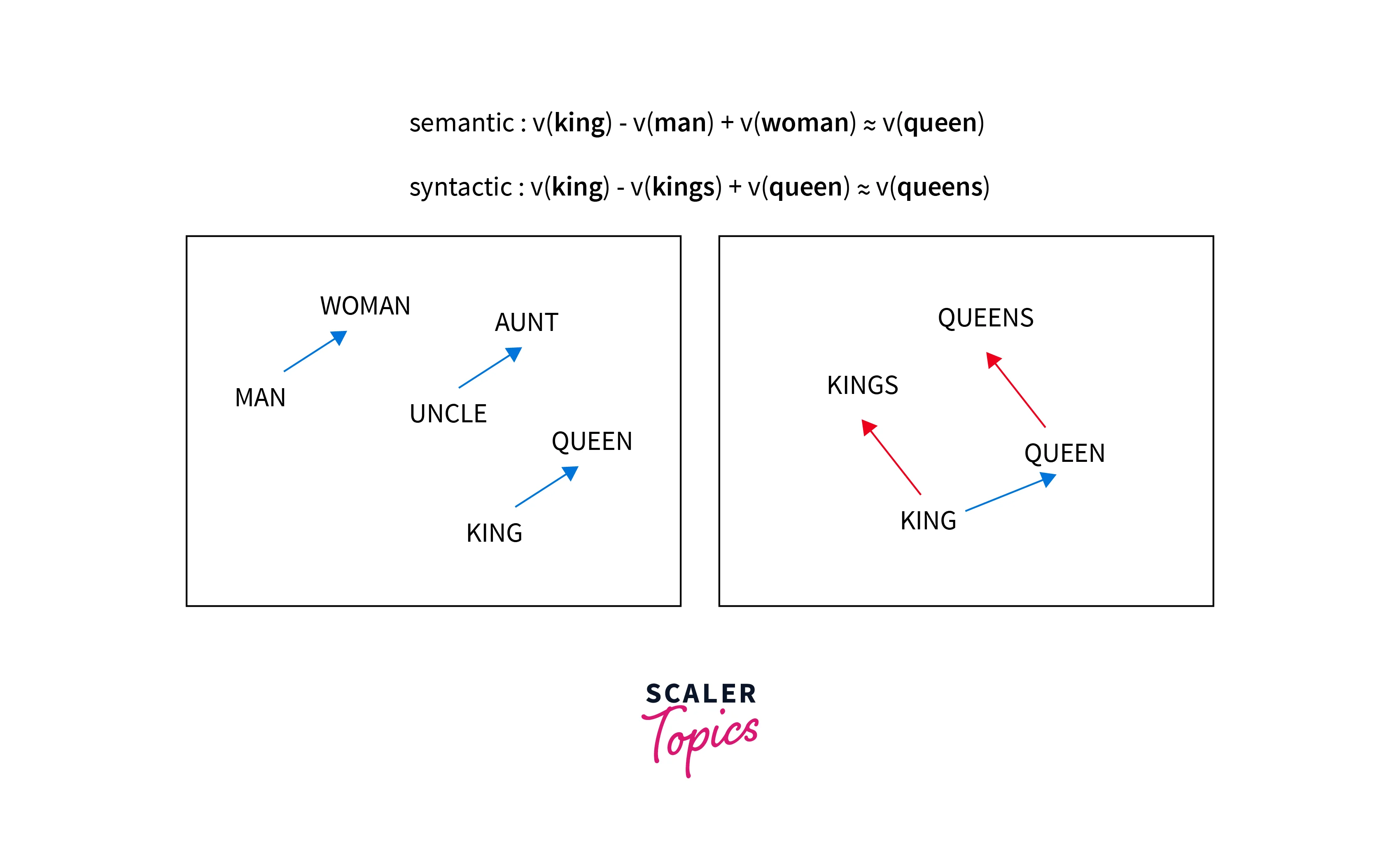
Using vector arithmetic, Word2Vec may replicate semantic and syntactic patterns by capturing numerous levels of similarity between words. By applying algebraic techniques to these words' vector representations, patterns like "Man is to Woman as Brother is to Sister" can be created, where the vector representation of "Brother" - "Man" + "Woman" produces a result that is most similar to the vector representation of "Sister" in the model. Vectors can construct these linkages for various syntactic and semantic relationships, such as Country—Capital and Present Tense—Past Tense.
There are two ways to get word2vec, both requiring neural networks:
- Common Bag of Words (CBOW)
- Skip Gram
How does CBOW Work?
The surrounding context words (such as "the cat sits on the") are used by CBOW to predict target words, such as "mat." For smaller datasets, this is a helpful thing. According to statistics, it has the effect of smoothing out a lot of the distributional data in CBOW (by treating an entire context as one observation).
Take the following sentence as an example: "It is a pleasant day," with the word "pleasant" serving as the neural network's input. Here, our goal is to predict the word "day."
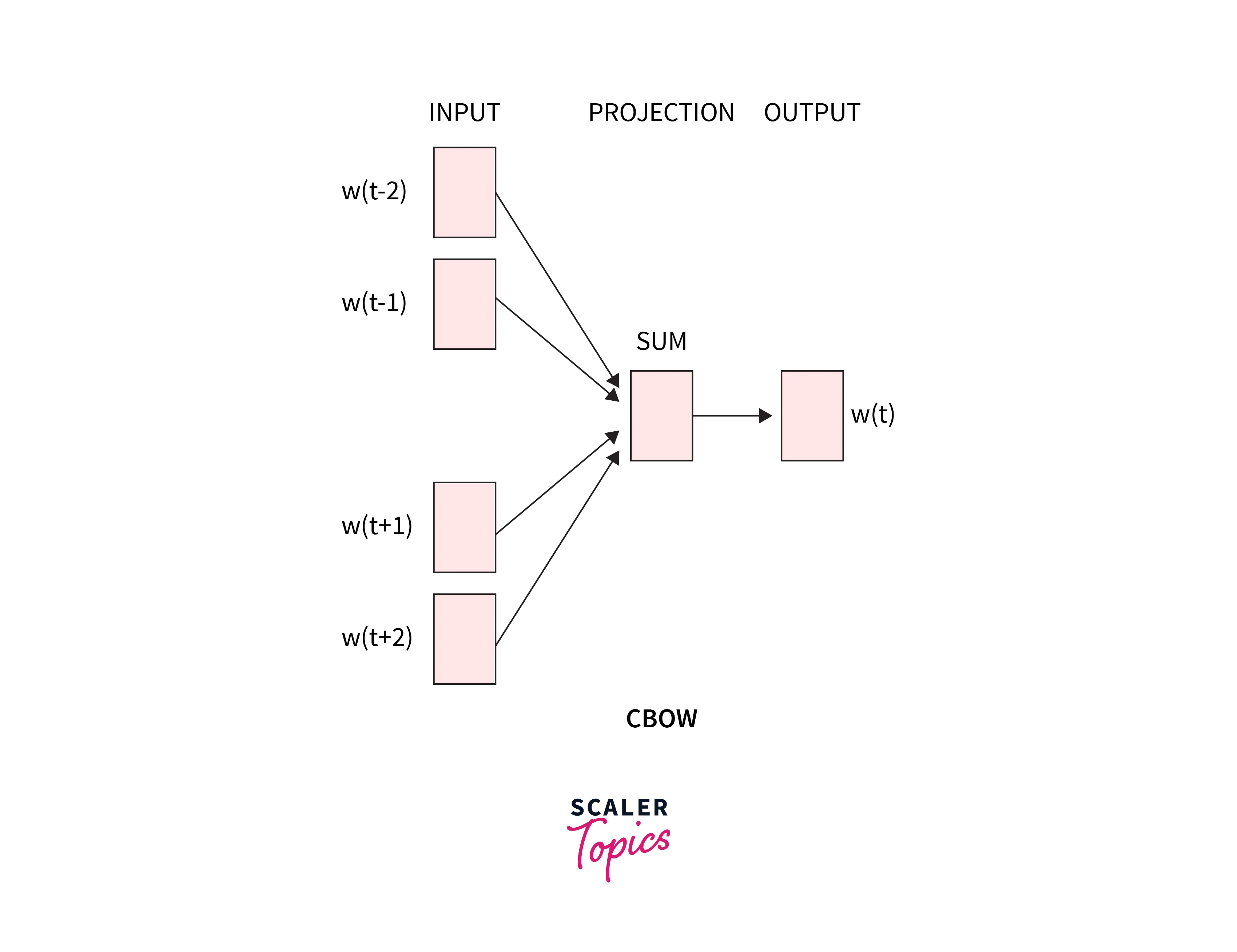
The above-described CBOW model architecture is present. The model makes an effort to analyze the context of the words around the target word to predict it. Consider the previous phrase, "It is a pleasant day." The model transforms this sentence into word pairs (of context words and target words). The user must configure the window size. The word pairings would appear like this if the context word's window were 2: ([it, a], is), ([is, nice], a) ([a, day], pleasant). The model tries to predict the target term using these word pairings while considering the context words.
Four 1XW input vectors will make up the input layer if four context words are utilized to forecast one target word. The hidden layer will receive these input vectors and multiply them by a WXN matrix. The 1XN output from the hidden layer finally enters the sum layer, where the vectors are element-wise summed before a final activation is carried out and the output is obtained.
Skip-Gram and Negative Sampling
From the target words, skip-gram predicts the words in the context around them (inverse of CBOW. When we have larger datasets, skip-gram often performs better since it takes each context-target pair as a new observation from a statistical perspective.
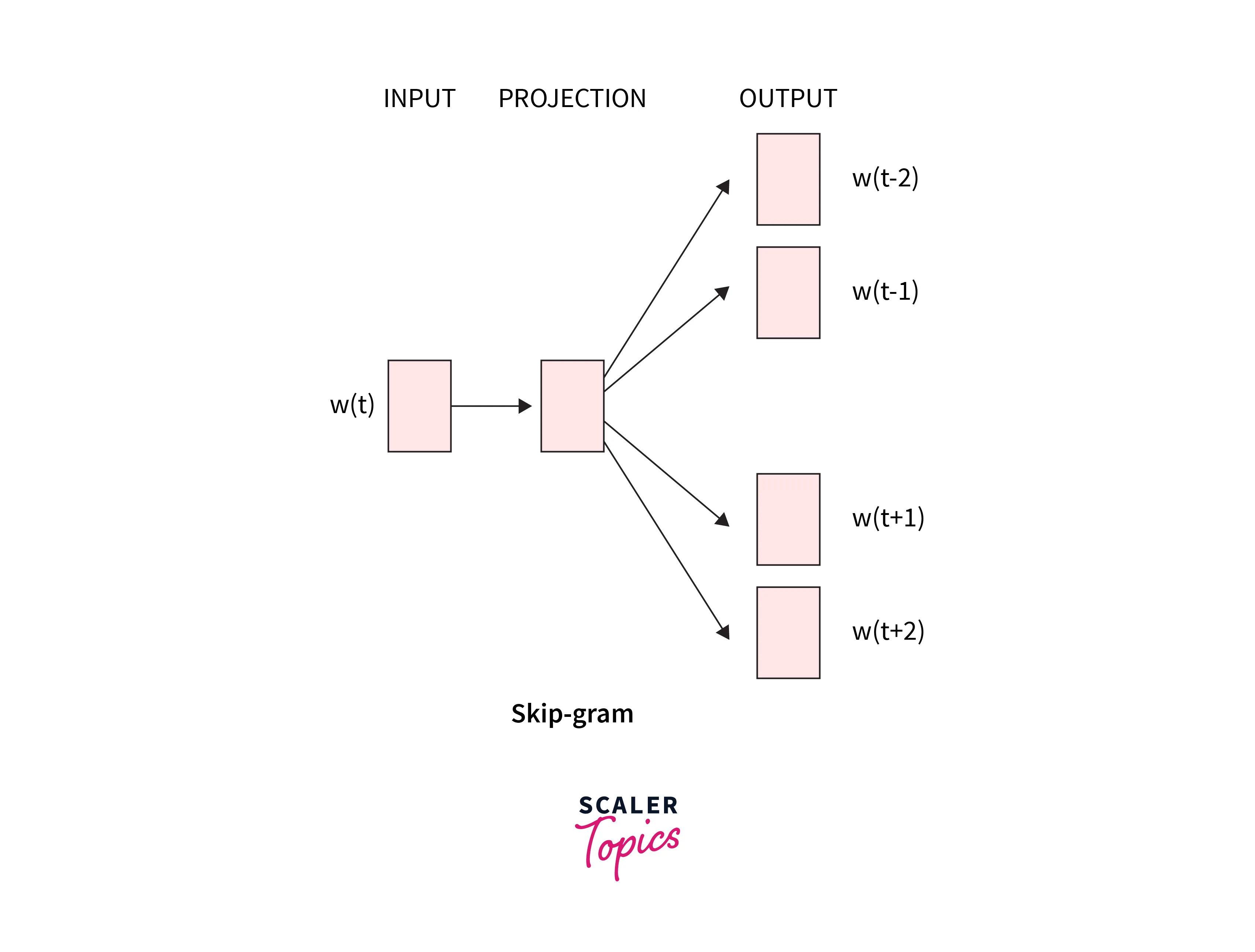
This model tries to learn the context words for each target word.
Sentence : ['Best way to success is through hard work and persistence']
Input for this model will therefore be as follows:
- Target: For Best, Word in context: (way).
- Target: way. Here are two more words: before and after. Therefore, in this case, our context words are: (Best, to).
- Target: to, Here, too, there are two words: i,e before and after (way, success). But if we give it some more thought, the words "to" and "is" can be found in sentences close to one another. "He is heading to the market," for example. Therefore, adding the word "is" to the list of context terms makes sense. However, now that we can debate "Best" or "through," Thus, the idea of "window size" is introduced. The window size determines the number of words in the immediate area to be considered. Consequently, if the window size is 1, our list of context words will be 1. (way, success). Furthermore, if the window size is 2, our list of context terms changes to (Best, way, success, is).
They reduced the sample size by subsampling commonly occurring words. They changed the optimization goal by using a method called "Negative Sampling," which results in each training sample updating just a tiny portion of the model's weights. Similarly to that, we can generate the list for the remaining terms.
The goal of negative sampling is to minimize word similarity when it occurs in different contexts and maximize word similarity when it occurs in the same context. However, depending on the training size, it randomly chooses a small number of words. Then uses them to optimize the objective rather than performing the minimization for every word in the dictionary apart from the context words.
Both models (i.e. CBOW and Skip Gram) have benefits and drawbacks of their own. Mikolov claims Skip Gram performs well with little data and effectively represents uncommon words. However, CBOW is quicker and provides better representations for frequently used words.
How to Implement Word2Vec in Python
The skip-gram model will be used in this article.
Implementing the Skip-Gram Model in Code consists of the following steps:
Step 1: Create a Corpus of Vocabulary
Any NLP-based model must create a corpus in which each word from the vocabulary is extracted and given a unique numerical identifier.
The corpus we use for this post is the King James Version of the Bible, offered without charge through the corpus model in nltk.
Import required libraries
Download the Gutenberg Project from nltk, together with the punkt model and stopwords:
Output
We utilize a user-defined function for text preprocessing that lowercase the text corpus and eliminates unnecessary whitespace, digits, and stopwords.
Next, extract unique words from the corpus and assign a numeric identifier.
Output
Step 2: Build a Skip-Gram using [(Target, Context, Relevance)] Generator
The model skip-gram feature of the Keras functional API creates word tuples :
Step 3: Defining the Skip-Gram Model
We will create a skip-gram deep learning architect utilizing Keras and TensorFlow as the backend support. The input is transferred to a different embedding layer to obtain word embedding for the target and context words. A dense layer that predicts either 1 or 0 based on whether a combination of words is contextually relevant or randomly produced is then created by combining these two layers.
Output
Step 4: Train the Model
Because it takes longer to train the model on a large corpus, we run the model for a few iterations; you can increase the iterations if necessary.
Output
Step 5: To Obtain Word Embeds
We can extract the word embeddings for every word in our vocabulary from our embedding layer. From our word model embedding layer, we will extract the embedding weights.
Output
We can see that the model almost matches the target word with the correct words. More training epochs can improve accuracy, but keep in mind that this will increase computing time.
The embedding would be like the graph below :
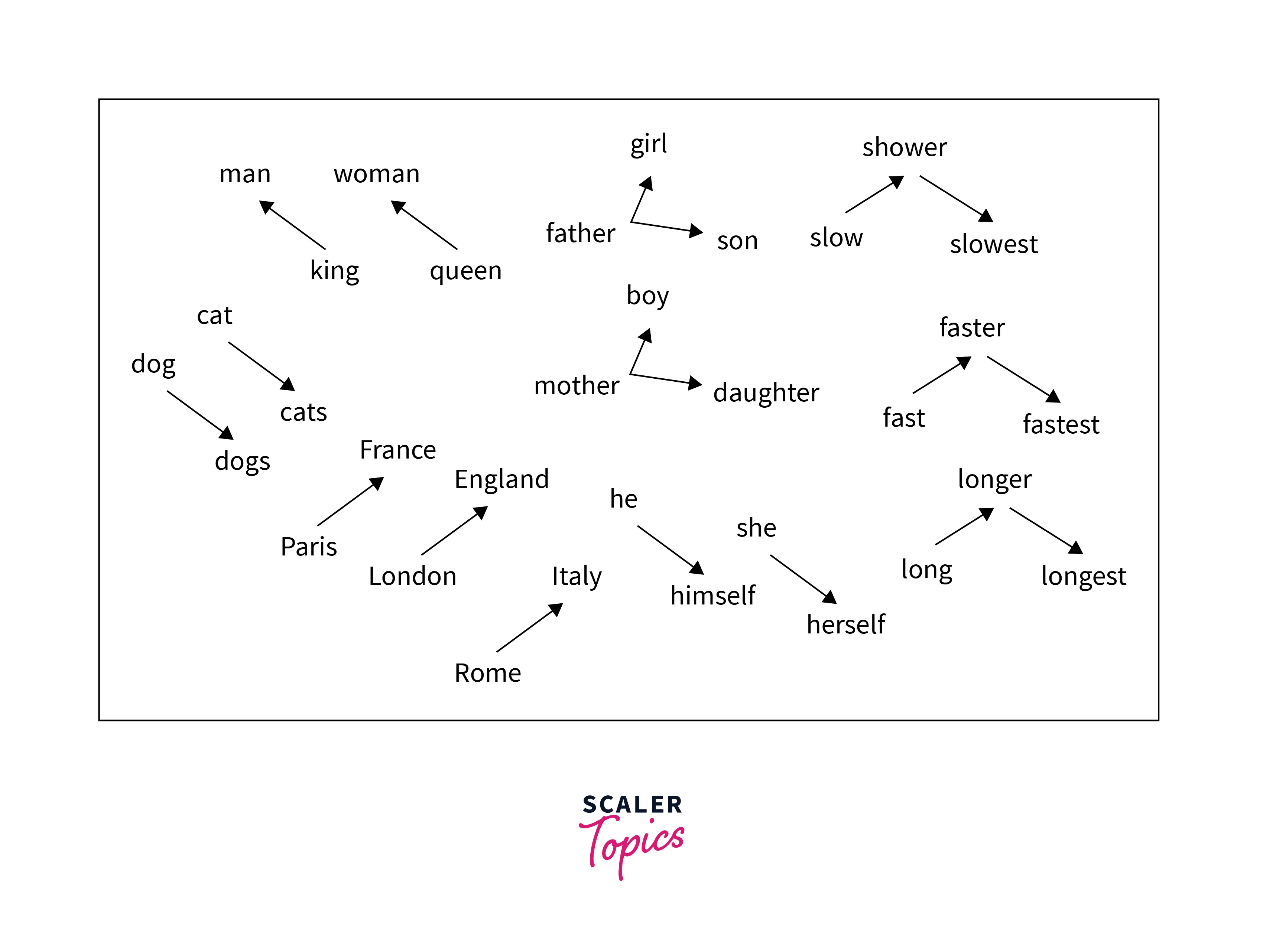
Word2Vec Python Model using Gensim
Gensim word2vec is a topic modelling-focused open-source Python module for natural language processing.
Radim Ehek, a Czech researcher, specialising in natural language processing, and RaRe Technologies are the creators and maintainers of Gensim.
Gensim word2vec is not an all-inclusive NLP research library (like NLTK) but a well-developed, narrowly focused, and practical set of NLP tools for subject modelling. This lesson, in particular, supports the implementation of the Word2Vec python word embedding for learning new word vectors from the text.
Additionally, it offers tools for using and querying a loaded embedding and loading pre-trained word embeddings in various formats.
Conclusion
- This article introduced us to word embeddings and their various forms of them, from the most simple to the most complex.
- Later, A section in the article demonstrated the application of word2vec using the skip-gram architecture.
- Last but not least, we have seen to implementation of work2vec using gensim, which offers tools for using and querying a loaded embedding and for loading pre-trained word embeddings in various formats.