Optimal Page Replacement Algorithm
Overview
"Optimal page replacement algorithm" is the most desirable page replacement algorithm that we use for replacing pages. This algorithm replaces the page whose demand in the future is less as compared to other pages from frames (secondary memory). The replacement occurs when the page fault appears. The purpose of this algorithm is to minimize the number of page faults. Also, one of the most famous abnormalities in the paging technique is "Belady's Anomaly", which is least seen in this algorithm.
What Is The Optimal Page Replacement Algorithm?
As we know, when a process is executed in our system, the operating system divides this process into small parts known as 'pages'. These pages are loaded into secondary memory known as RAMs. Also, the secondary memory is divided into several frames in which the pages are loaded. The size of the page is always equal to the size of the frames. When a system calls a page and it is not available in the frame, "page fault" occurs. The optimal page replacement algorithm is used to reduce these page faults. It uses the principle that- "when a page is called by the system and it is not available in the frames, the frame which is not in demand for the longest future time is replaced by the new page".
How Does An Optimal Page Replacement Algorithm Work?
The page replacement algorithm aims to reduce page faults as much as possible. To do this, this algorithm searches for the page from reference, which is not going to be used earliest, and considers this page useless for that instant of time. And that page is replaced by the new page in the frame.
Suppose we have a reference page ( 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 3) and number of frames is 4. The first pages(7,0,1,2) will be loaded into the first 4 frames.
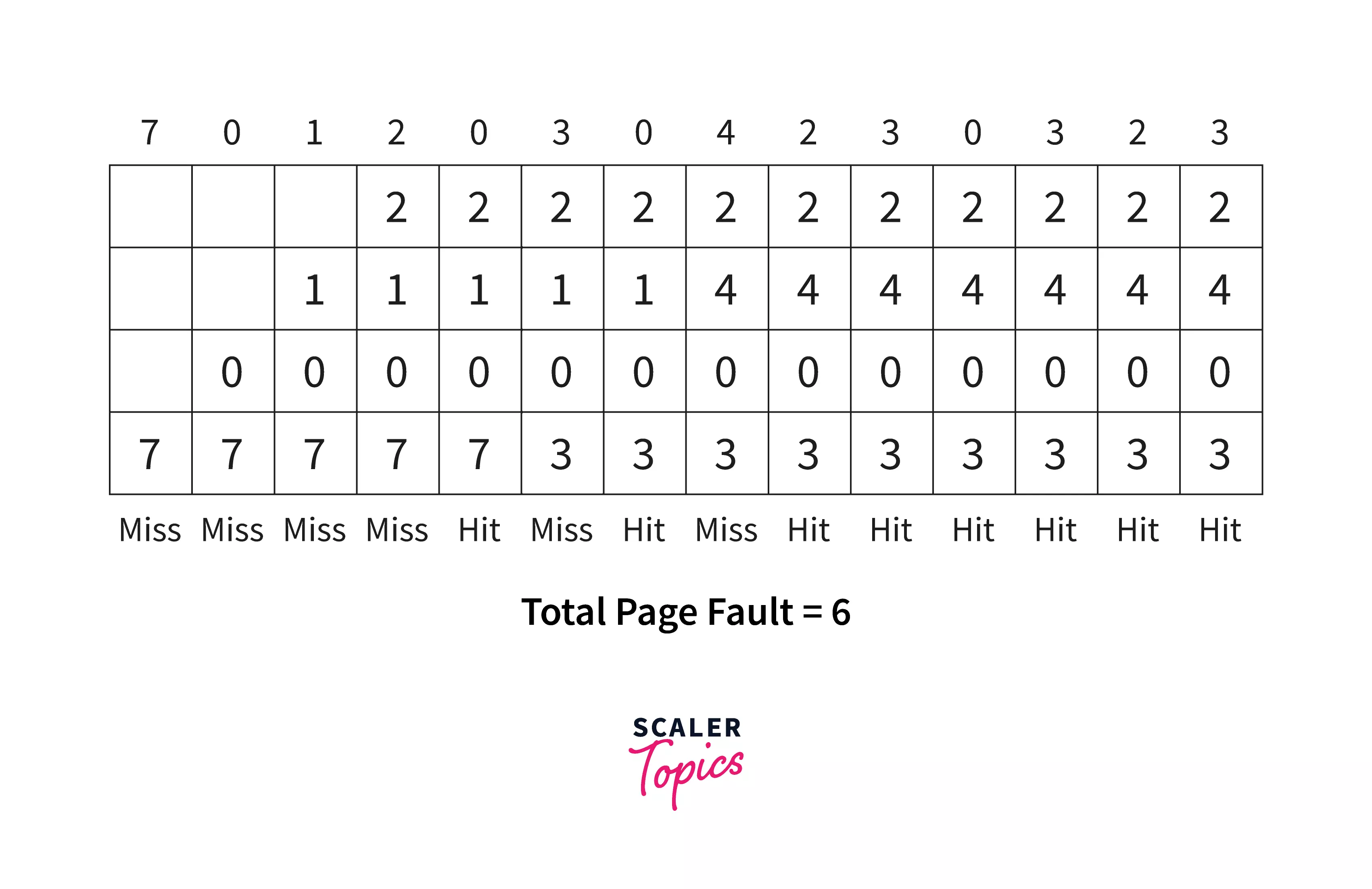
After that, we need to load page '0' but it is already present in frames, so there will be a "Hit". Then page '3' needs to be loaded but it is not available in frames so, the algorithm will go through the reference and search for that page that is not going to be used in the future. Here, page 7 is not going to be used in the future and hence the algorithm will replace 'page 7' with 'page 3'. It will be again a "Miss". Now, the system will call for page 3, and it is already present so there will be a "Hit". After that, we need to load 'page 4' but it is not present in the frames. So, the algorithm will again start searching for the page which is in the least demand in the future i.e.- 'page 1'. So, page 1 will be replaced by 'page4' in the frame.
Optimal Page Replacement Algorithm Pseudocode:
The 'optimal page replacement algorithm' is not practical because it cannot predict whether the page it is going to remove will not be used in the future. Maybe it removes a page and then immediately after an iteration, we will again need that removed page in a frame. Given below is pseudocode to understand how the algorithm works and find the number of "misses" and "hits" in frames.
Pseudocode:
Implementation Of Optimal Page Replacement Algorithm Using A Programming Language:
Now, let us see an example in C++ language to understand how this algorithm works.
Output:
Explanation: A function 'predict()'' is defined that takes a frame vector, index, and page array. It returns the farthest predicted page. Then, a function boolSearch() takes a frame vector, and a key that has to be searched in the frame. It returns true if the key is found else it returns false. A function find() is defined that takes a page array, frame number, and page number. It finds and prints the page hits and page misses. Initially, from the main() function we will be calling the find() function that will find the hits and misses and display the result.
Example Of Optimal Page Replacement Algorithm In OS:
Let us see an example to understand the algorithm working:
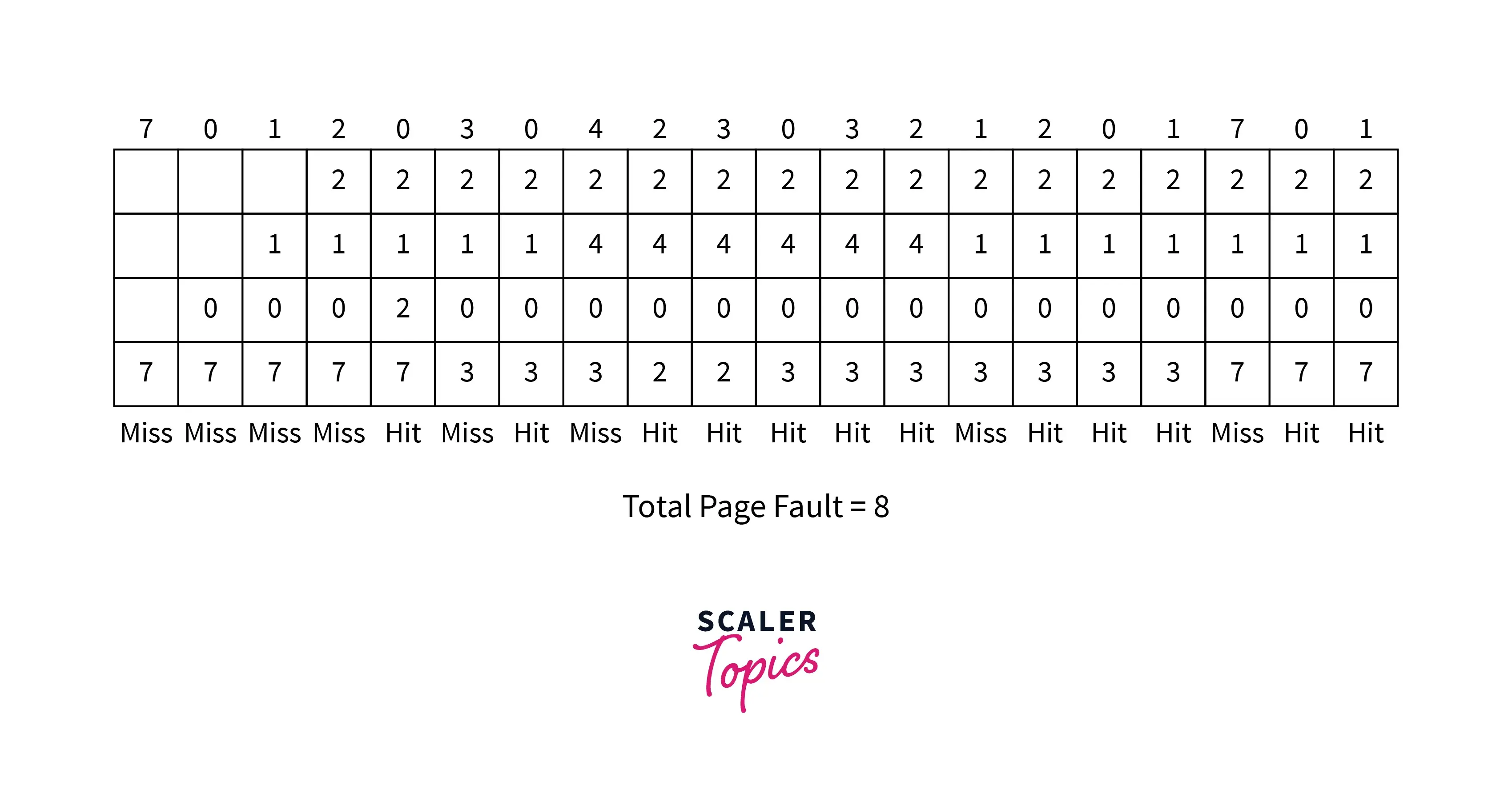
In the given figure, the reference string is (7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1) and the number of frames in secondary memory is 4. We will see how the "optimal page replacement algorithm" works and also calculate the Page Hit ratio.
 Explanation:
Explanation:
- Initially, all four frames are empty, so the first pages will be loaded into the frames and it will count as "page-miss" or "page fault". We got four-page faults in the beginning.
- Then we need to load the 'page 0' which is available in the frames. So it will be a page hit.
- Next for 'page 3', from (7,0,1,2), page 7 is present farthest from the current position, so it will be considered as least useful for the future and will be replaced by 'page 3'. It will be a "page fault" again.
- Next, we need to load 'page 0' which is already present. It will be counted as a 'page-hit'.
- Now, 'page 4' needs to be loaded into the frames. And it is not present in secondary memory. So, the algorithm will again start searching for the page that is farthest from the current position. From loaded pages (3,0,1,2), page 1 is farthest in the reference string. Hence, it will be replaced by 'page 4'.
- This process will continue until the last page of reference is loaded into the frames.
We Can Also Calculate The Page Hit Ratio As Given Below:
The total reference string is 20. The total page faults is 8. ∴ Total page Hits= .
Therefore, Page-Hit ratio = KaTeX parse error: Expected 'EOF', got '%' at position 11: 12/20 = 60%̲
Advantages Of Optimal Page Replacement Algorithm:
The following are the advantages of the Optimal page replacement algorithm:
- Least page fault occurs as this algorithm replaces the page that is not going to be used for the longest time in the future.
- In this algorithm, Belady's Anomaly (the number of page faults increases when we increase the number of frames in secondary storage) does not occur because this algorithm uses a 'stack-based algorithm' for page replacement. The data structure used in this algorithm is easy to understand.
- The page that will not be in demand in the future time is replaced by a new page in the frames.
Disadvantages Of Optimal Page Replacement Algorithm:
The following are the disadvantages of the optimal page replacement algorithm:
- This algorithm is limited to some specific operating systems. All OS can not use this.
- Detecting errors in this algorithm is not so easy.
- Sometimes, the page which is used recently is replaced which takes much time.
- This algorithm is difficult to implement because the operating system can't predict the future reference strings.
Conclusion
- Optimal page replacement algorithm aims to reduce the no of page faults.
- It reduces the page faults by replacing the page that is not in demand in the future.
- Optimal page replacement algorithm uses a "stack-based algorithm" for replacing pages.
- Using this algorithm, Belady's Anomaly can be removed.
- In this algorithm, the page fault is at least equal to the minimum number of frames and number of pages. Ex- we have a number of frames=4 for a reference string, then the number of page faults will be at least 4 or more than 4.
- The optimal page replacement algorithm is only a parameter to compare them with other algorithms' capability of reducing page faults. As we know, this algorithm replaces the page that is not in demand for the longest time in the future for a particular reference string. But what if a new reference string is in a queue and the page we replaced is again in demand? So, this algorithm cannot predict the future.
- Because it is not practically possible for an operating system to predict the future string and make decisions.