Parallelizing Your Pandas Workflow
Overview
Pandas is a crucial library for data scientists and analysts as it is built upon libraries like Numpy, Matplotlib, etc., which are known to be highly optimized, saving a lot of time. But there is still a lot of optimization that can be done on the Pandas library using the Modin Function
Introduction
There are a lot of libraries like Dusk and Modin Functions which are built on top of Pandas library to provide multiprocessing capabilities to Pandas. They use core Pandas functions only, but they narrow down all the functions in the Pandas data frame to just 20 core functions which help to optimize the operations that we do in Pandas.
What is Parallelizing?
Parallelizing means running tasks in parallel so that all cores of our CPU can be used to reach maximum efficiency and save computation time. There are two types of Processing:-
1. Serial Processing
In this type of Processing, we do operations one by one, i.e we wait for one operation to complete, and then we start doing the next operation.
2. Parallel Processing In parallel Processing, we do multiple operations concurrently by utilizing multiple cores of the CPU. Modin Function uses a similar type of Processing on top of the Pandas library to multitask and increase the efficiency of the machine.
Need of Parallelizing Your Pandas Workflow
Pandas library is made to carry out complex operations faster using highly advanced data containers supporting multiple types called Dataframe. But the Pandas library is single-threaded, and thus it is not able to completely utilize the full potential of a multicore CPU. We can do this by using multiprocessing, i.e., simultaneously doing operations to save time. We do not encounter these issues now, but when we work around huge datasets, then doing operations in Pandas can be troublesome.
One way is to transfer all the data to SQL and then run queries, but that is a troublesome task. Therefore we parallelize our Pandas workflow to achieve the full capabilities of our CPU to run tasks faster in Pandas Dataframe only without any changes in the data format.
How Parallelizing Workflow Helps Us to Save Computation Time
For example, we have to find the minimum value in the dataframe. Then rather than going through the whole data frame one by one, we can just divide the dataframe into multiple parts, then find the minimum of those concurrently, thus reducing the time. Then use the result of this operation and find the minimum through that. Let us look at how much time we are saving in this type of operation. Let us assume the total values in a dataframe is n, and we divide this into k sets. So the time taken to serially process this would be of order . Now if we process it parallelly, then the k set of values would be processed at the same time. Thus the time taken would be of order (). Then we will compare the k values that we got in time k Therefore total time complexity will be () Thus we can see that we can save a lot of time even on a simple operation by using the parallel Processing of the Modin Function.
Ways to Parallelize Using Different Libraries
There are many different libraries available to parallelize your Pandas workflow, as converting such a large dataset to SQL for faster queries is a tedious task. These libraries use the concept of parallel Processing only to make the CPU utilize its multi-core to process the data faster and more efficiently. These libraries are open-source, so their source code is available on GitHub if you are interested.
Multiprocessing
Multiprocessing is an open-source module that is used for spawning processes, just like the threading module in python. The source code is available on GitHub. It creates multiple threads to help in multiprocessing. It uses the pool object that helps in distributing the input data and mapping it to the target function for Processing. Multiprocessing and the Pool object can be used as follows.
Dask
Dask is an open-source library whose source code is available on Github. It is a library used for multiprocessing on NumPy, Pandas, and Scikit Learn libraries. Dask can be used on your system or you can deploy your code on a large distributed cluster. The APIs in dask is very similar to the APIs used in these libraries, so the ease of usability is high. It can also be integrated with existing projects. The data structures are derived from these libraries only. For example
- Dask Dataframe - Built on top of Pandas Dataframe
- Dask Array - Built on top of Numpy Array
- Dask Delayed - Built for custom python functions
Dask functions use a task graph. The graph is created so that the values that are dependent on previous values are computed on different levels. Let us see how Dask is similar to a dataframe.
Code
Output:
Here, you can see that we can just import the dask dataframe and execute the code exactly, similar to how we do in Pandas Dataframe. We just have to run compute() with the dask dataframe to operate.
Modin
Modin is a library specifically built on top of the Pandas module to scale up the processing capabilities to all the cores of the CPU to decrease the computation time and increase efficiency. It can be integrated into Pandas very easily, and Modin Function has very similar APIs to that of the Pandas Module. Modin can be easily installed using PIP by using the command. pip install modin[all]. The developers don't have to change anything to use Modin Function. They just have to change the import statement from
to
And they will be able to scale their computation to utilize every core of the CPU. Internally Modin divides the task into many subtasks running simultaneously using threads.
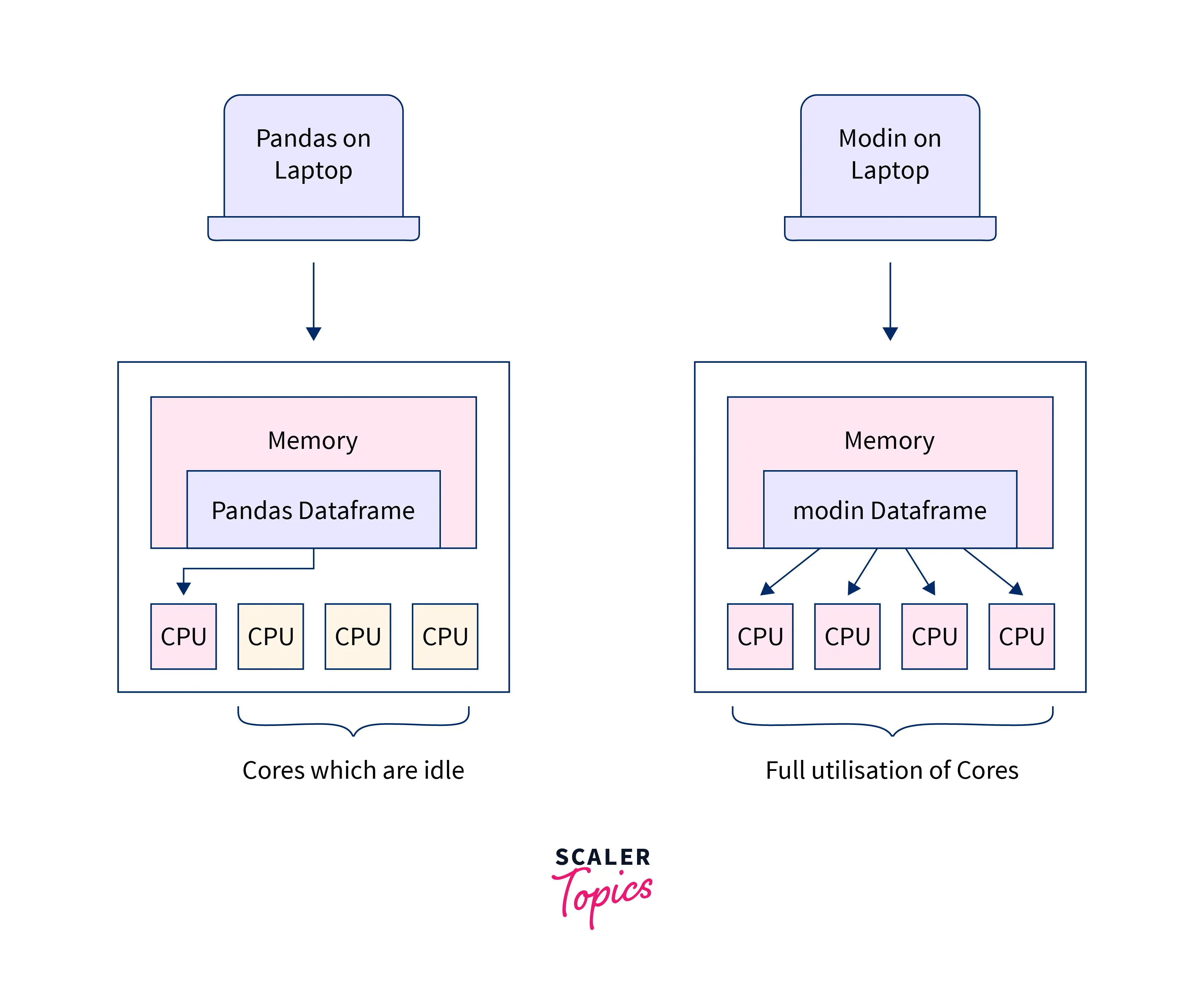
We can see that Pandas Dataframe only uses one core of the CPU, whereas the Modin Function uses all the cores of the CPU. Modin is an open-source Library, so the source code and various benchmarks that show how efficient modin is over pandas are present here on Github. According to Modin's GitHub repository, Modin covers 90.8%of APIs from the Pandas Dataframe and88.05%` of APIs from the Pandas Series. So we can see that the API coverage of the Modin Function is quite high thus, it is a very easy and reliable tool to use for scaling up and parallelizing your panda's workflow.
Ipython Parallel
Ipython Parallel is an open-source library whose source code is available here. This is also a library that is used for parallelizing your workflow, but this is made for interactive iPython notebooks like Jupyter notebook. It has numerous CLI scripts that help to control the Jupyter Notebook to utilize the full potential of the cores present in your CPU. Ipython Parallel has numerous schedulers that help to schedule the task for concurrency in a particular cluster. It also offers the flexibility to the user to run the task remotely or in parallel according to their needs. For a detailed implementation guide, one can refer to their official documentation.
Conclusion
- Parallelization is a process through which we can run processes on all the cores of the CPU to increase efficiency.
- We can parallelize our Pandas' workflow using open-source libraries, which are built on Pandas' module and help us to parallelize our Pandas' Workflow.
- Modin Library is built upon Pandas, and it can help us parallelize our Pandas workflow with a single line change in code.