PostgreSQL Architecture
Overview
Do you know how Postgres architecture handles multiple clients connecting to the server? How does Postgres architecture ensure efficient querying through indexing?
PostgreSQL is an open-source relational database management system that is known for its robustness and extensibility. It follows a client-server architecture, where multiple clients can connect to a PostgreSQL server simultaneously. The server-side process acts as a conductor, overseeing operations within the database, handling client connections, and executing tasks such as complex queries and data management.
Physical Structure of PostgreSQL
Now, let’s understand the physical structure of Postgres architecture in parts:
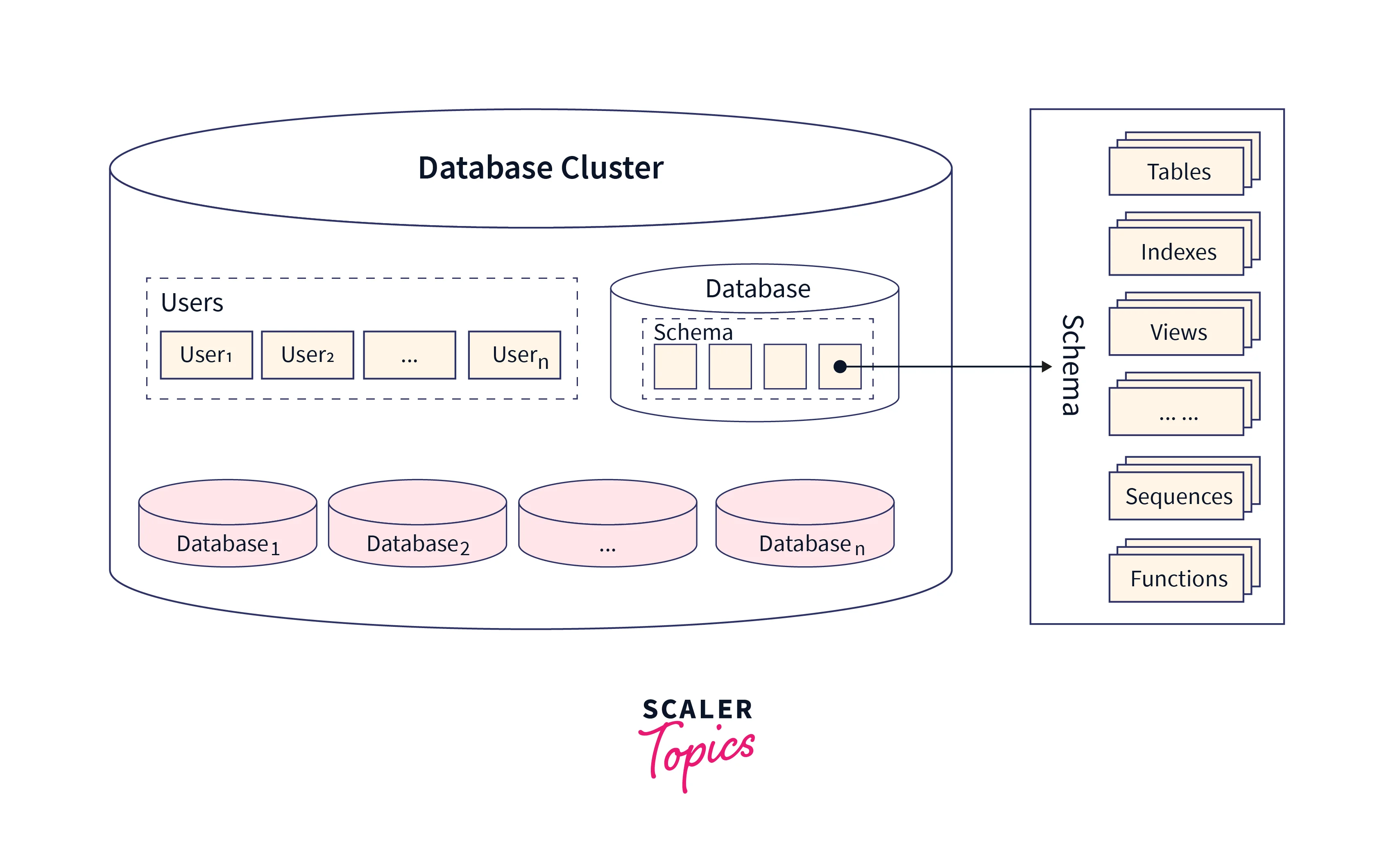
- Storage:
PostgreSQL stores data on a disk in files. These files can be thought of as large containers where information is kept. - Cluster:
A cluster is a collection of databases managed by a single instance of PostgreSQL. It's like a big box that holds all the databases and their associated files. - Database:
Within a cluster, you have individual databases. Each database is like a separate compartment where you organize your data. You can think of them as folders in a file system. - Tablespaces:
Tablespaces are like special folders. They allow you to define different physical locations (like drives or directories) to store data. This can be useful for managing storage space. - Relation Files (Tables):
Inside each database, you have tables. A table is like a spreadsheet, with rows and columns. Each table has its file where the data is stored. - WAL (Write-Ahead Logging):
This keeps track of changes before they're permanently saved to the table. It helps ensure data integrity, especially in case of a crash. - Indexes:
Imagine an index in a book. In PostgreSQL, indexes help locate specific rows quickly. They're like a reference guide for the database. - Free Space Map (FSM):
This keeps track of available space within relation files. It's like knowing how much space is left on a page in a notebook. - Background Processes:
PostgreSQL has various background processes that handle tasks like cleaning up old data, managing connections, and more. They're like invisible helpers that keep things running smoothly.
Shared Memory
Shared memory is a mechanism used by operating systems to allow multiple processes to access and manipulate a common area of physical memory. This shared region acts as a communication channel between processes, enabling them to exchange data more efficiently and rapidly than other forms of inter-process communication.
In Shared memory each process can read from and write to this whiteboard, allowing them to share information directly without the need for complex data transfers or file-based communication.
This method is especially valuable for tasks that demand high-speed communication between processes. For example, in database systems like PostgreSQL, shared memory facilitates swift data exchange between different components, contributing to improved performance.
Shared memory serves as a vital tool for enhancing the efficiency and speed of inter-process communication, making it an important feature in modern operating systems.
WAL Buffer
The Write-Ahead Logging (WAL) buffer is a vital feature in database systems like PostgreSQL. It serves to guarantee data integrity and recoverability in case of system failures.
To put it simply, think of the WAL buffer as a temporary storage area for important changes. Instead of immediately updating the main data files, PostgreSQL first records these changes in the WAL buffer. Later, at specific intervals or when the buffer is full, the changes are transferred to the main data files.
This approach offers a crucial advantage: In the event of a system crash, the database can recover by reapplying the changes from the WAL buffer to the main data files. This ensures that no data is lost or compromised.
The WAL buffer functions as a safeguard, enabling PostgreSQL to maintain a reliable record of changes before committing them to permanent storage. This guarantees both data consistency and the ability to recover from unforeseen events.
Server-side Process
In Postgres architecture, a Server-Side Process refers to a program or task that operates on the server side. It facilitates communication between client applications and the database, managing requests from clients and coordinating with the database engine for execution.
The server-side process interprets requests from client applications and interacts with the database engine to carry out operations. This includes tasks such as processing SQL queries, managing connections, overseeing transactions, and ensuring data integrity.
Additionally, the server-side process is responsible for critical functions like security validations, access control enforcement, and resource management to maintain fair usage among all clients.
Client-side Process
The client-side process in Postgres architecture plays a crucial role in enabling users to interact with the database server. It contains several key components:
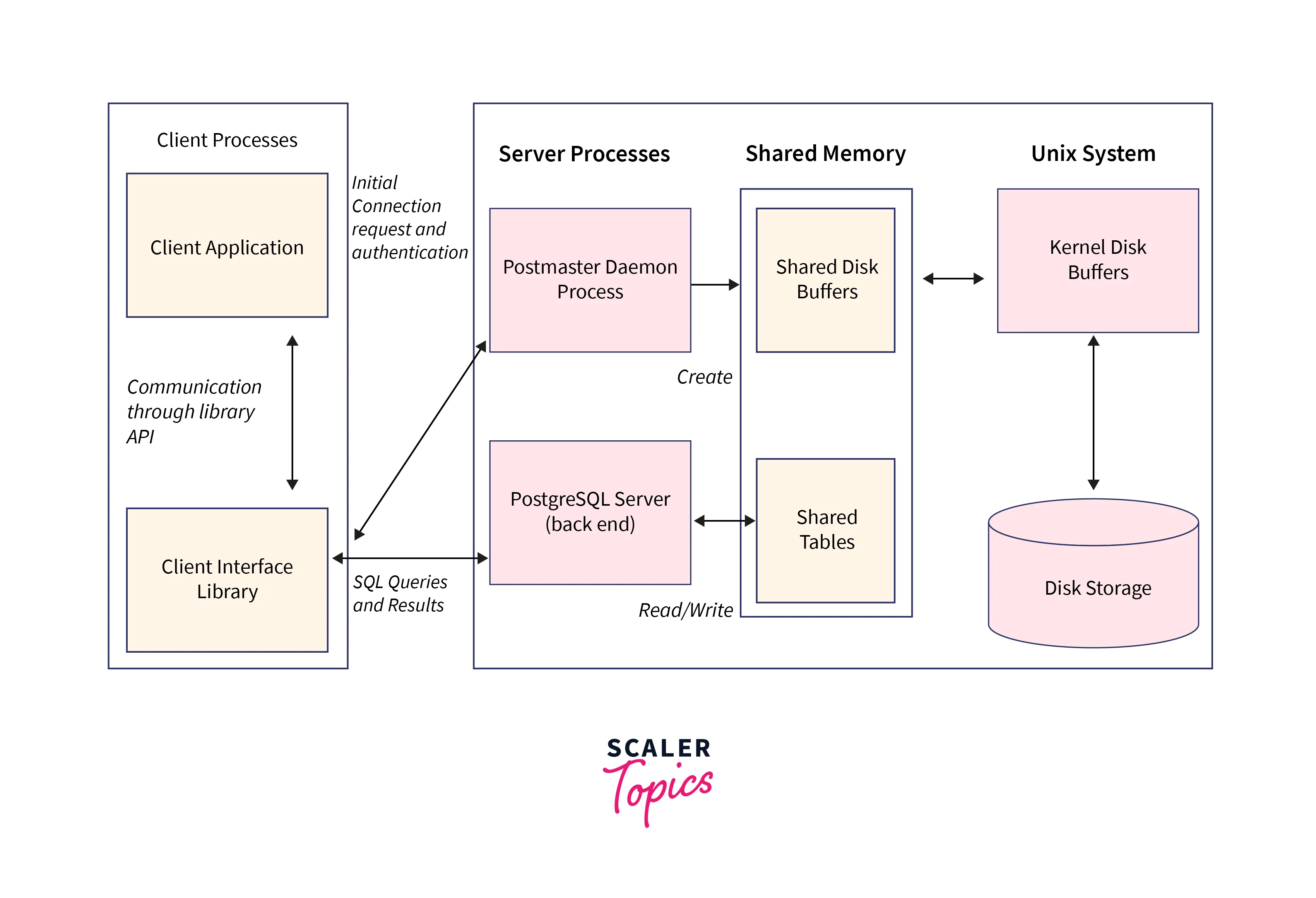
- Client Application and Interface in Postgres architecture:
When a user runs queries on PostgreSQL, a Client Application connects to the PostgreSQL server via the Postmaster Daemon Process. This connection is facilitated through various Database Client Application interfaces like JDBC, Perl DBD, ODBC, etc. These interfaces provide the necessary libraries for client-side operations. - Postmaster Daemon Process:
The Postmaster Daemon Process is the central coordinating element in PostgreSQL's architecture, following a Process-Per-Transaction Model (Client/Server Model). Also known as the Server Process, it has several critical responsibilities:- Initializing the server.
- Handling connection requests from new clients.
- Performing system shutdowns.
- Initiating recovery processes.
- Overseeing the execution of background tasks.
- Communication and Library API:
Within the Client Process, communication occurs between the Client Application and the Client Application library. This communication is facilitated through the Library API. The API acts as an intermediary, ensuring seamless interaction between the client-side components.
The client-side process serves as the gateway for users to interact with the Postgres architecture. It manages the connection, query submission, and communication between the client application and the server. The Postmaster Daemon Process, acting as the central coordinator, is responsible for initializing, managing connections, and executing essential background tasks in the PostgreSQL system.
Merits & Demerits of PostgreSQL
Merits of PostgreSQL
- ACID Compliance:
PostgreSQL ensures data integrity and consistency through ACID (Atomicity, Consistency, Isolation, Durability) compliance. - Extensibility:
It supports custom functions, data types, and procedural languages, allowing for adaptability to specific use cases. - Advanced Indexing:
Offers various indexing techniques for efficient querying and data retrieval. - Complex Query Support:
Supports complex queries through SQL and procedural languages like PL/pgSQL. - High Availability Features:
Provides features like replication and failover support for continuous operation.
Demerits of PostgreSQL
- Resource Intensive:
Can be demanding on system resources, especially with large datasets. - Complex Configuration:
Setting up and configuring PostgreSQL may require more expertise compared to some other database systems. - Learning Curve:
For beginners, understanding advanced features and optimization techniques might take time. - Performance in Some Scenarios:
While generally high-performing, in certain scenarios, specialized databases might offer better performance (e.g., for specific NoSQL use cases). - Limited GUI Tools:
Compared to some other databases, PostgreSQL may have fewer graphical user interface tools available.
Conclusion
- PostgreSQL follows a client-server architecture where multiple clients can connect to a central server process simultaneously.
- The Postmaster Daemon Process, also known as the Server Process, is responsible for initializing the server, handling client connections, performing system shutdowns, initiating recovery processes, and managing background tasks.
- Users interact with the database server through a client application, which connects to the PostgreSQL server via the Postmaster Daemon Process. Various database client application interfaces facilitate this connection.
- Communication between the Client Application and the Client Application library occurs through the Library API, serving as an intermediary for seamless interaction between client-side components.
- PostgreSQL is known for its ACID compliance, ensuring data integrity. It offers extensibility through custom functions, data types, and procedural languages, making it adaptable to specific use cases.