Understanding the Inner Workings of PostgreSQL
Introduction
Brief Overview of PostgreSQL
Have you ever been to a library? What do you notice about how books are organised? PostgreSQL is a powerful system for organising and managing data, just like a library. PostgreSQL acts as your trusted data manager. It simplifies the complex inner Postgresql working to manage large databases. Similarly, PostgreSQL helps you to organise and manage large data simply. It efficiently retrieves what you need. It's like a data navigator that effortlessly guides you to the right shelves and serves up the requested information.
Importance of Understanding its Internal Working Mechanism
PostgreSQL working is like having a magic key for smooth and efficient data management. Knowing the Internal Working PostgreSQL lets you make data work better, find problems early, and fine-tune things for top performance. You can customize your data solutions just right and come up with new ideas.
PostgreSQL: A Quick History
Origins and Development of PostgreSQL
PostgreSQL's story starts back in the 1980s when a group of brilliant minds at the University of California started working on a project called Ingres. This was the foundation for what would become PostgreSQL. They wanted a database system that could handle complex data with finesse. As time went on, this project grew and evolved, embracing open-source ideals – which means it's free for anyone to use and improve.
In 1996, PostgreSQL officially got its name, symbolizing its strong roots in the SQL world. Over the years, an army of developers worldwide joined forces, tirelessly enhancing its features and stability. The community spirit helped PostgreSQL become a powerful tool for businesses, researchers, and developers to manage data flexibly and robustly.
The Current Status of PostgreSQL in the Database Industry
Today, PostgreSQL stands tall as one of the most respected players in the database arena. It's not just about storing data anymore it's a platform that empowers companies to manage, analyze, and draw insights from their data. Its ability to handle complex queries support various data types, and its focus on compliance with industry standards have earned it a prime spot in the tech world.
Businesses of all sizes – from startups to giants – rely on PostgreSQL for their data management needs. Its open-source nature means it's not tied to any particular company, which keeps it adaptable and community-driven. With each passing year, new versions introduce advanced features, performance improvements, and security enhancements. PostgreSQL's journey from its humble beginnings to its current status is a testament to the power of collaboration and the remarkable impact of open-source innovation in the dynamic landscape of databases.
The Architecture of PostgreSQL
High-level Overview of the PostgreSQL Architecture
The architecture of PostgreSQL is a well-structured framework designed to facilitate efficient data management, high concurrency, and extensibility. Postgresql working contains a client-server model, where client applications interact with a central PostgreSQL server. Let's dive into the key components of this architecture in the next section.
The below figure shows the Architecture of PostgreSQL:
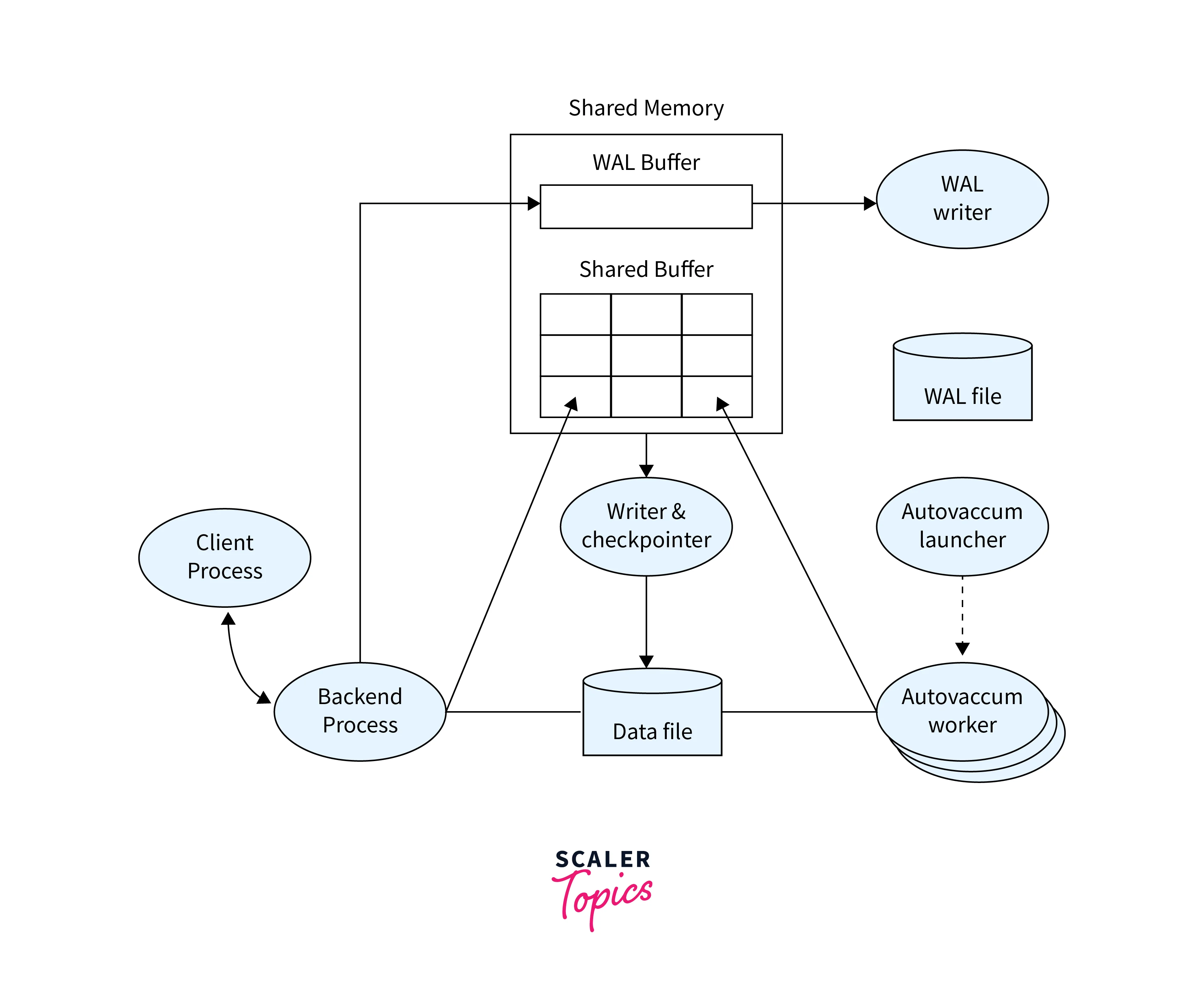
Discussion on Various Components like PostgreSQL Backend, Transaction log, Buffer Manager, etc.
- PostgreSQL Backend:
The PostgreSQL backend forms the core of the system. It manages client connections, query execution, transaction handling, and more. Each client connection is assigned a dedicated backend process, ensuring isolation between clients. The backend parses incoming SQL queries, optimises their execution plans, and executes them. This component serves as the bridge between clients and the underlying data storage. - Transaction Log (Write-Ahead Logging - WAL):
The transaction log, often referred to as the Write-Ahead Log (WAL), plays a critical role in PostgreSQL's architecture. Before any modifications are applied to the database, they are recorded in the WAL. This sequential log serves two purposes: it ensures the durability of transactions by persisting changes before they are written to the database, and it enables crash recovery by allowing the system to replay changes from the log after a failure. - Buffer Manager:
PostgreSQL's buffer manager is responsible for enhancing performance by reducing disk I/O operations. It maintains a cache of frequently accessed data in memory, known as shared buffers. By storing data in memory, the buffer manager minimises the need to fetch data from disk, resulting in faster query execution times. This caching mechanism significantly improves overall system responsiveness. - Storage Management:
Data in PostgreSQL is organized into fixed-size blocks called pages. The storage management component handles reading and writing data to these pages, allocating and deallocating space, and ensuring transaction isolation. PostgreSQL's support for Multi-Version Concurrency Control (MVCC) enables concurrent transactions by managing multiple versions of data. - Background Processes:
PostgreSQL working uses background processes to manage essential maintenance tasks:- Auto-Vacuum Process:
This process automatically reclaims space by removing obsolete data and helps maintain optimal performance. - Background Writer:
The background writer alleviates I/O pressure by asynchronously writing dirty pages from shared buffers to disk. - WalWriter:
WalWriter ensures that the changes captured in the WAL are consistently written to disk, enhancing data durability and supporting replication.
- Auto-Vacuum Process:
- Extensibility:
Extensibility is the Postgresql defining feature. Users can create custom data types, functions, and operators, enabling the database to adapt to specific application requirements. This extensibility fosters a high degree of customization and versatility.
Understanding PostgreSQL Data Storage
Explanation of How PostgreSQL Stores Data on Disk
PostgreSQL employs a well-structured approach to store data on disk, aiming for efficiency, reliability, and extensibility. Data is organised into fixed-size blocks called pages, which are the fundamental unit of storage. These pages are typically 8KB in size. PostgreSQL's storage architecture involves several layers that work together to ensure data integrity and retrieval:
- Relation Files:
PostgreSQL uses relation files to store tables, indexes, and other objects. These files are managed by the storage subsystem. - Pages:
Data within relation files is organised into pages. Each page contains a header, metadata, and actual data rows or index entries. - Tablespaces:
PostgreSQL uses tablespaces to manage physical storage. Each table, index, or object can belong to a specific tablespace, allowing for better control over data placement.
Deep Dive into PostgreSQL's Table and Index Structure
PostgreSQL's table structure follows a row-based storage model. Each table's data is stored in its corresponding heap file. Within a heap file, pages store rows of data. The table structure includes:
- Row Storage:
Rows are stored as records within data pages. Columns are serialised in a format that PostgreSQL can understand. - Tuple Header:
Each row has a tuple header containing metadata such as the length of the row and a pointer to the row's data. - Null Bitmap:
A null bitmap is used to efficiently represent which columns of a row contain NULL values. - System Columns:
PostgreSQL adds system columns to each row, such as the unique row identifier and transaction information for MVCC.
Now let’s discuss the index structure which is essential for efficient data retrieval in PostgreSQL. Let’s discuss how the index structure works:
- B-Tree Indexes:
PostgreSQL commonly uses B-tree indexes, which are well-suited for range queries and equality searches. - Index Pages:
Indexes are composed of index pages, which are similar to table data pages but contain index entries instead of actual data.
Index key, internal nodes leaf nodes and maintenance overhead are also the essential part of the index structure.
PostgreSQL's Transaction System
Overview of PostgreSQL's MVCC (Multiversion Concurrency Control) System
PostgreSQL's transaction system is a fundamental aspect of its relational database management architecture. It ensures data integrity, concurrency control, and consistency in a multi-user environment. MVCC is a sophisticated technique that allows multiple transactions to work concurrently without interfering with each other while still maintaining data consistency.
Description of How Transactions are Managed and How Isolation is Ensured?
In PostgreSQL, transactions are managed through a systematic process that ensures data integrity, concurrency control, and isolation among multiple concurrent transactions. This is achieved primarily through the implementation of the Multiversion Concurrency Control (MVCC) mechanism.
- Transaction Management:
When a transaction begins, PostgreSQL creates a unique transaction identifier (transaction ID) for it. This ID helps in tracking and managing the transaction's changes. Transactions follow the ACID properties (Atomicity, Consistency, Isolation, Durability), which ensure that database operations are reliable and maintain data integrity. - Snapshot Creation:
At the start of each transaction, PostgreSQL generates a snapshot of the database. This snapshot represents the state of the data at that particular moment. The snapshot contains a timestamp or a transaction ID, which serves as a reference point for the transaction's view of the data. This snapshot is consistent and isolated from the changes made by other concurrent transactions. - Isolation Among Transactions:
PostgreSQL ensures isolation among transactions by adhering to the snapshot isolation principle. Each transaction operates based on its snapshot, and this snapshot remains unchanged throughout the transaction's duration. This means that any changes made by other concurrent transactions are not visible to the current transaction, even if they commit their changes before the current transaction completes. - Read Consistency:
Within a transaction, all reads are based on the initial snapshot, ensuring read consistency. Even if other transactions are concurrently modifying data, the current transaction's view remains consistent, preventing dirty reads or inconsistent data observations. - Handling Concurrent Modifications:
When a transaction modifies data, it creates new versions of affected rows (tuple versioning) rather than directly modifying the existing data. This maintains data integrity and allows concurrent transactions to work independently without causing conflicts. Each transaction's changes are isolated from others until they are committed.
Query Processing in PostgreSQL
Detailed Explanation on How PostgreSQL Executes a Query
Query processing in PostgreSQL working is a complex yet systematic procedure that involves various stages, including parsing, optimization, and execution. This process aims to retrieve data efficiently while considering factors such as data distribution, indexes, and execution plans. Below is a detailed breakdown of how PostgreSQL executes a query:
- Parsing:
When a query is submitted to PostgreSQL, the query parser breaks it down into a structured format that the database can understand. It verifies the query's syntax and prepares an internal representation for further processing. - Query Rewriting:
During this stage, PostgreSQL might rewrite the query to optimize its execution. This can involve transforming subqueries, simplifying expressions, and applying various rules to improve performance. - Query Optimization:
The query optimizer plays a crucial role in PostgreSQL's query processing. It explores different execution plans and selects the most efficient one based on statistics, indexes, and available resources. The optimizer's goal is to minimize the cost of executing the query.
Understanding PostgreSQL's Query Optimizer
In PostgreSQL, the query optimizer is a critical component responsible for enhancing query performance by selecting the most efficient execution plan. It employs a sophisticated approach that involves cost estimation, plan generation, and plan selection. Below is an insightful look into how PostgreSQL's query optimizer operates:
- Cost-Based Optimization:
PostgreSQL's query optimizer uses a cost-based optimization strategy. This approach involves assigning costs to various query execution plans and evaluating these costs to determine the most efficient plan. The optimizer's goal is to minimize the total execution cost, which includes factors like disk I/O, CPU usage, and memory consumption. - Plan Generation:
Upon receiving a query, the optimizer generates multiple potential execution plans. Each plan represents a different approach to executing the query, involving various join methods, index utilization, and scan types. The optimizer explores different combinations of these elements to find the most promising plans. - Plan Selection:
After generating multiple plans, the optimizer evaluates their estimated costs and selects the one with the lowest cost. This selected plan becomes the blueprint for executing the query. The optimizer's cost estimation considers factors such as data distribution, index selectivity, and system statistics. - Adaptive Optimization:
PostgreSQL's optimizer incorporates adaptive features that allow it to adjust its plan selection during query execution. If the actual runtime behaviour differs from the predicted behaviour, the optimizer can adapt by choosing alternative plans that might be more suitable for the specific query instance.
Scalability and Replication in PostgreSQL
PostgreSQL's Capability to Handle Large Databases
PostgreSQL excels in managing large databases through a combination of features and optimization options. Its scalability is enabled by table partitioning, diverse indexing methods, horizontal scaling via sharding, connection pooling, parallel execution, and query optimization. These tools collectively empower PostgreSQL workings to handle data volumes efficiently and maintain performance.
Overview of Replication Mechanisms in PostgreSQL
Regarding replication, PostgreSQL offers diverse mechanisms for enhanced data availability and fault tolerance. Physical replication ensures real-time copying of the primary database to standby servers, bolstering resilience. Logical replication facilitates individual change replication to multiple subscribers, ideal for distributed architectures. Asynchronous replication, the default mode, ensures minimal primary server impact by not waiting for standby confirmations. Synchronous replication enhances data durability by mandating confirmation from standby servers before the primary server commits. Streaming replication slots prevents data loss and supports catching up between primary and standby servers. Replication lag monitoring tools aid in assessing data consistency.
In essence, PostgreSQL's prowess in managing large datasets and ensuring data availability is fortified by its scalability features and versatile replication mechanisms, making it a robust choice for diverse applications requiring high performance and reliability.
Conclusion
- PostgreSQL's complex architecture drives efficient data handling via parsing, optimization, and execution stages.
- Performance optimization results from comprehensive query analysis, cost-driven optimization, and attention to data distribution and indexes.
- PostgreSQL's scalability, reliability, and replication mechanisms enable effective management of extensive datasets and ensure data accessibility.
- Its adaptable nature equips users to confidently address intricate data scenarios.
- It embraces the opportunity to explore PostgreSQL's features and enhance skills in proficient database management.