Secure Hashes and Messages Using Python Hashlib

Overview
A hashing algorithm converts data into a fixed-length hash value, hash code, or hash. In essence, the output hash value is a summary of the original value. These hash values are important because they cannot be used to retrieve the original input data. You may think why use hashing algorithms and not encryption? Even though encryption is important for data protection, it is sometimes necessary to be able to prove that no one has modified the data you're sending. You can tell if a file hasn't been modified since it was created by using hash values.
Python Hashlib Module
Python Hashlib is a Python module that makes hashing messages easy. Numerous methods are provided for hashing raw messages into encrypted formats. Python Hashlib module uses a hash function on a string to encrypt it so that it is very difficult to decrypt.
A string that is encrypted is typically so long that it is difficult to recover the original string. In our application, we can store passwords securely using the below block diagram.
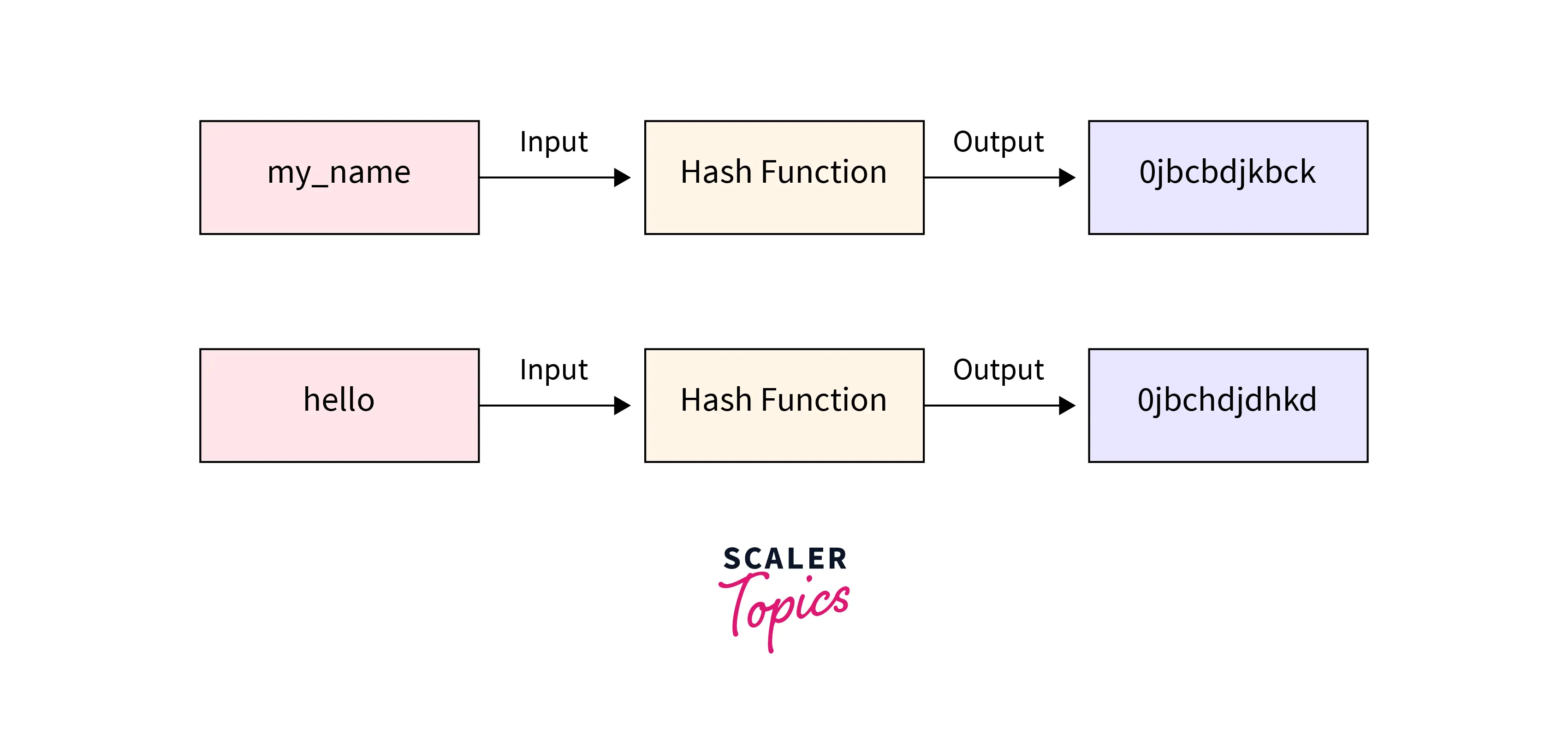
The hash function ensures that the hashed output is much longer than the input string and remains the same length. This makes brute force cracking of such hashes very difficult.
Hash Algorithms in Hashlib Module
The generated value is referred to as the hash. Typically, the length of the string converted to a hash is less than the hash code. Furthermore, the hash value is obtained using a hash function, and the process of obtaining a hash code includes a series of steps. As a result, the algorithm that describes how to use hash functions is referred to as a hashing algorithm.
Because hashing is a one-way process, it is impossible to recover the original data from the hash. Furthermore, the most widely used hashing algorithms are the MD-5(Message-Digest Algorithm 5) and SHA(Secure Hash Algorithm) families.
MD5(Message-Digest Algorithm 5)
The MD5 algorithm generates a hash value with a length of 128 bits. Furthermore, the MD5 algorithm is easily understood by the following Python example code that generates an MD5 hash for a string.
Note: In python, the 'b' character before a string is used to specify the string as a “byte string“. Now, b_str doesn't store a String object, instead, it stores a Byte String object.
Output:
The above code generates a hash value of 8950ce00e298dd4f44761e4d6fdc8560 for the string "Scaler Academy".
We must import Python Hashlib in order to use the hashing algorithm. The function b is used here to convert the string to bytes because the hashing function only accepts bytes. Furthermore, the hexdigest() function converts the encoded data to hexadecimal format. MD5 algorithms are faster than SHA algorithms, but their security is inferior to the other algorithm.
Let's go over the SHA family algorithms one by one.
SHA256
The SHA256 hashing algorithm is the most widely used and is more secure than the MD5 algorithm.
The example code below generates a SHA256 algorithm:
Output:
The SHA256 algorithm is a member of the SHA-2 family. Furthermore, the encode() function is used to convert the string to bytes that the hash function accepts.
The main reasons for using the SHA256 algorithm are as follows:
- It is safer than other hashing algorithms.
- Because there are 256 possibilities for hash value, the possibility of having the same hash value for two different strings is reduced.
SHA384
The SHA384 algorithm generates a 384-bit hash value. The example code below generates a SHA384 algorithm:
Output:
SHA224
The SHA224 algorithm produces a hash value of 224 bits. It is a member of the SHA2 family.
The example code below generates an SHA224 algorithm:
Output:
SHA512
The SHA512 algorithm generates a hash value of 512 bits in length. It is a member of the SHA2 family.
The example code below generates an SHA512 algorithm:
Output:
SHA-1
The SHA-1 algorithm generates a hash value of 160 bits. The use of MD5 began to decline after the introduction of SHA-1.
The Python code below computes the hash value for the given string "Satyam":
Output:
Furthermore, the SHA-1 hashing algorithm has flaws that make it less resistant to attacks.
Python Hashlib SHAKE Variable Length Digests
The shake_128() and shake_256() algorithms generate variable length digests with (length in bits) divided by 2 security up to 128 or 256 bits. As a result, their digestion methods necessitate a length. The SHAKE algorithm does not impose a maximum length limit.
Shake.digest(length)
Return the digest of the data passed to the update() method so far. This is a bytes object of size length which may contain bytes in the whole range from 0 to 255.
Shake.hexdigest(length)
Like digest() the digest is returned as a string object of double length, containing only hexadecimal digits. This may be used to exchange the value safely in email or other non-binary environments.
File Hashing in Python Hashlib
The Python Hashlib module includes a helper function for hashing a file or file-like object efficiently.
Hashlib.file_digest(fileobj, digest, /):
It return a digest object that has been updated with the file object's contents.
fileobj must be a file-like object that has been opened in binary mode for reading. It accepts file objects from the built-in open() function, BytesIO instances, SocketIO objects from socket.socket.makefile(), and other similar objects. The function may bypass Python's I/O and directly use the file descriptor returned by fileno(). After this function returns or raises, fileobj must be assumed to be in an unknown state. It is the caller's responsibility to close fileobj.
digest must be either a str-named hash algorithm, a hash constructor, or a callable that returns a hash object.
Derivation of Key
For secure password hashing, key derivation and key stretching algorithms are used. Simple algorithms, such as sha1(password), are vulnerable to brute-force attacks. A good password hashing function should be adjustable, slow, and contain a salt.
Note: A salt is a random string added to the plaintext password and hashed together to generate the irreversible hash. An attacker without knowledge of the salt can not generate a matching hash. In Python, the Python Hashlib module provides a Key Derivative Functions(KDF) we can use to achieve this.
Hashlib.pbkdf2_hmac(hash_name, password, salt, iterations, dklen=None):
The function implements a PKCS#5-based password-based key derivation function. HMAC is used as a pseudorandom function.
The string hash name is the desired name of the HMAC hash digest algorithm, such as 'sha1' or 'sha256'. Password and salt are interpreted as bytes buffers. Passwords should be kept to a reasonable length in applications and libraries (e.g., 1024). Salt should be 16 or more bytes from a reliable source, such as os.urandom().
Hashlib.scrypt(password, *, salt, n, r, p, maxmem=0, dklen=64)
The function implements the RFC 7914 scrypt password-based key derivation function.
Both the password and the salt must be bytes-like objects. Passwords should be kept to a reasonable length in applications and libraries (e.g. 1024). Salt should be 16 or more bytes from a reliable source, such as os.urandom.
BLAKE2 Function
RFC 7693 defines BLAKE2 as a cryptographic hash function that comes in two flavors:
- BLAKE2b is optimized for 64-bit platforms and generates digests ranging in size from 1 to 64 bytes.
- BLAKE2s is optimized for 8- to 32-bit platforms and generates digests ranging in size from 1 to 32 bytes.
Keyed mode (a faster and simpler replacement for HMAC), salted hashing, personalization, and tree hashing are all supported by BLAKE2.
This module's hash objects adhere to the API of the standard library's Python Hashlib objects.
Creating Objects for Hashing
Constructor functions are used to generate new hash objects:
hashlib.blake2b(data=b'', , digestsize=64, key=b'', salt=b'', person=b'', fanout=1, depth=1, leafsize=0, nodeoffset=0, nodedepth=0, innersize=0, lastnode=False, usedforsecurity=True)
hashlib.blake2s(data=b'', , digestsize=32, key=b'', salt=b'', person=b'', fanout=1, depth=1, leafsize=0, nodeoffset=0, nodedepth=0, innersize=0, lastnode=False, usedforsecurity=True)
These functions return hash objects that can be used to calculate BLAKE2b or BLAKE2s. They may also take the following general parameters:
- data: initial chunk of data to hash, which must be bytes-like object. It can be passed only as positional argument.
- digest_size: size of output digest in bytes.
- key: key for keyed hashing (up to 64 bytes for BLAKE2b, up to 32 bytes for BLAKE2s).
- salt: salt for randomized hashing (up to 16 bytes for BLAKE2b, up to 8 bytes for BLAKE2s).
- person: personalization string (up to 16 bytes for BLAKE2b, up to 8 bytes for BLAKE2s).
Constants Involved
blake2b.SALT_SIZE blake2s.SALT_SIZE
Salt length (maximum length accepted by constructors).
blake2b.PERSON_SIZE blake2s.PERSON_SIZE
Personalization string length (maximum length accepted by constructors).
blake2b.MAX_KEY_SIZE blake2s.MAX_KEY_SIZE
Maximum key size.
blake2b.MAX_DIGEST_SIZE blake2s.MAX_DIGEST_SIZE
Maximum digest size that the hash function can output.
Examples
Tree Mode
As an example, consider hashing a minimal tree with two leaf nodes:
This example employs 64-byte internal digests and returns the 32-byte final digest:
Personalization in Python Hashlib
For different purposes, it is sometimes useful to force a hash function to produce different digests for the same input. According to the Skein hash function's creators.
Note: Skein is a cryptographic hash function and one of five finalists in the NIST hash function competition.
By passing bytes to the person argument, BLAKE2 can be customized:
Personalization together with the keyed mode can also be used to derive different keys from a single one:
Randomized Hashing
Users can randomize the hash function by setting the salt parameter. Randomized hashing is useful for preventing collision attacks on digital signature hash functions.
Randomized hashing is intended for situations in which one party, the message preparer, generates all or part of a message that will be signed by another party, the message signer. If the message preparer discovers cryptographic hash function collisions (two messages with the same hash value), they may prepare meaningful versions of the message with the same hash value and digital signature but different results (e.g., transferring $1,000,000 to an account rather than $10).
Collision resistance has been a major goal in the design of cryptographic hash functions, but the current focus on attacking cryptographic hash functions may result in a given cryptographic hash function providing less collision resistance than expected. Randomized hashing provides additional protection to the signer by reducing the likelihood that a preparer will generate two or more messages that ultimately yield the same hash value during the digital signature generation process — even if collisions for the hash function are possible. However, when the signer prepares all portions of the message, the use of randomized hashing may reduce the amount of security provided by a digital signature.
Simple Hashing
To calculate the hash of some data, first create a hash object by calling the appropriate constructor function (blake2b() or blake2s()), then update it with the data by calling update() on the object, and finally obtain the digest by calling digest() (or hexdigest() for hex-encoded string).
As a shortcut, you can pass the first chunk of data to update as the positional argument directly to the constructor:
To iteratively update the hash, call hash.update() as many times as necessary:
Keyed Hashing
As a faster and simpler replacement for Hash-based message authentication code, keyed hashing can be used for authentication (HMAC). Because of the indifferentiability property inherited from BLAKE, BLAKE2 can be used safely in prefix-MAC mode.
This example shows how to obtain a 128-bit authentication code for message b'message data' using key b'pseudorandom key':
Despite the fact that there is a native keyed hashing mode, BLAKE2 can be used in HMAC construction with the hmac module:
Hashing Using Different Digest Sizes
BLAKE2 digests can be configured to be up to 64 bytes for BLAKE2b and up to 32 bytes for BLAKE2s. For example, to replace SHA-1 with BLAKE2b without changing the output size, we can instruct BLAKE2b to generate 20-byte digests:
Hash objects with varying digest sizes produce entirely different results (shorter hashes are not prefixes of longer hashes). Even though the output length is the same, BLAKE2b and BLAKE2s produce different results:
Conclusion:
Let's conclude our topic by mentioning some of the important points:
- A hashing algorithm converts data into a fixed-length hash value, hash code, or hash. In essence, the output hash value is a summary of the original value.
- Python Hashlib is a Python module that makes hashing messages easy. Numerous methods are provided for hashing raw messages into encrypted formats. This module uses a hash function on a string to encrypt it so that it is very difficult to decrypt.
- Since hashing is a one-way process, it is impossible to recover the original data from the hash. Furthermore, the most widely used hashing algorithms are the MD-5(Message-Digest Algorithm 5) and SHA(Secure Hash Algorithm) families.
- For secure password hashing, key derivation and key stretching algorithms are used. Simple algorithms, such as sha1(password), are vulnerable to brute-force attacks. A good password hashing function should be adjustable, slow, and contain a salt.
- RFC 7693 defines BLAKE2 as a cryptographic hash function that comes in two flavors: BLAKE2b is optimized for 64-bit platforms and generates digests ranging in size from 1 to 64 bytes.
- Users can randomize the hash function by setting the salt parameter. Randomized hashing is useful for preventing collision attacks on digital signature hash functions.
- To calculate the hash of some data, first create a hash object by calling the appropriate constructor function (blake2b() or blake2s()).