Understanding Audio Data in PyTorch
Overview
With amazing advancements in AI-based speech applications like Google voice assistant, Amazon's Alexa, Apple's Siri, and so on, audio data is becoming an extremely popular and useful research direction among the deep learning modeling community. This article introduces the reader to PyTorch audio data using PyTorch's TorchAudio API.
Introduction
When we hear the word data, the first thing that comes to mind is large excel files containing millions of records in numerical or textual form. Maybe not as well!
For the deep learning community, data almost always equals images, for Computer Vision practitioners and text, for Natural Language Processing practitioners.
While images and text certainly form useful data for many real-world applications and use cases, data is anything that carries information.
Speech is the prime form of communication, which means it carries information; hence, speech or audio can be called data. And, way ahead from just being termed as data, audios carry a lot of useful information with patterns that could be used to build many applications primarily for the communication industry.
Popular voice assistants like Alexa and Siri are spectacular examples of audio data advancements.
Other than the joy and excitement they bring, applications based on audio data have an important role in bettering human lives. For instance, visually impaired people can benefit a lot from a system that takes input audio/speech data and produces the output in the same form.
Google voice typing is another example that makes communication faster and more efficient. Understanding audio data is the first step towards building audio-based applications that could help technical innovations in many sectors, like the healthcare industry.
We will now move on to understand the form of audio data along with the associated terms, after which we explore how PyTorch, one of the most popular deep learning libraries, could be leveraged to model and use audio data.
What Is Audio Data?
Let us first fundamentally understand what audio data looks like.
Audio is the signal generated when sound waves passing through air molecules are captured by some devices like microphones, etcetera.
The digital signal is generated by capturing the incoming sound waves at specific intervals, resulting in a two-dimensional graph of the amplitude of the sound wave at a particular time instant vs. the time instant. The following image shows on the x-axis the time (in seconds), and the y-axis represents the amplitude of the captured sound wave at that particular second (time instant).
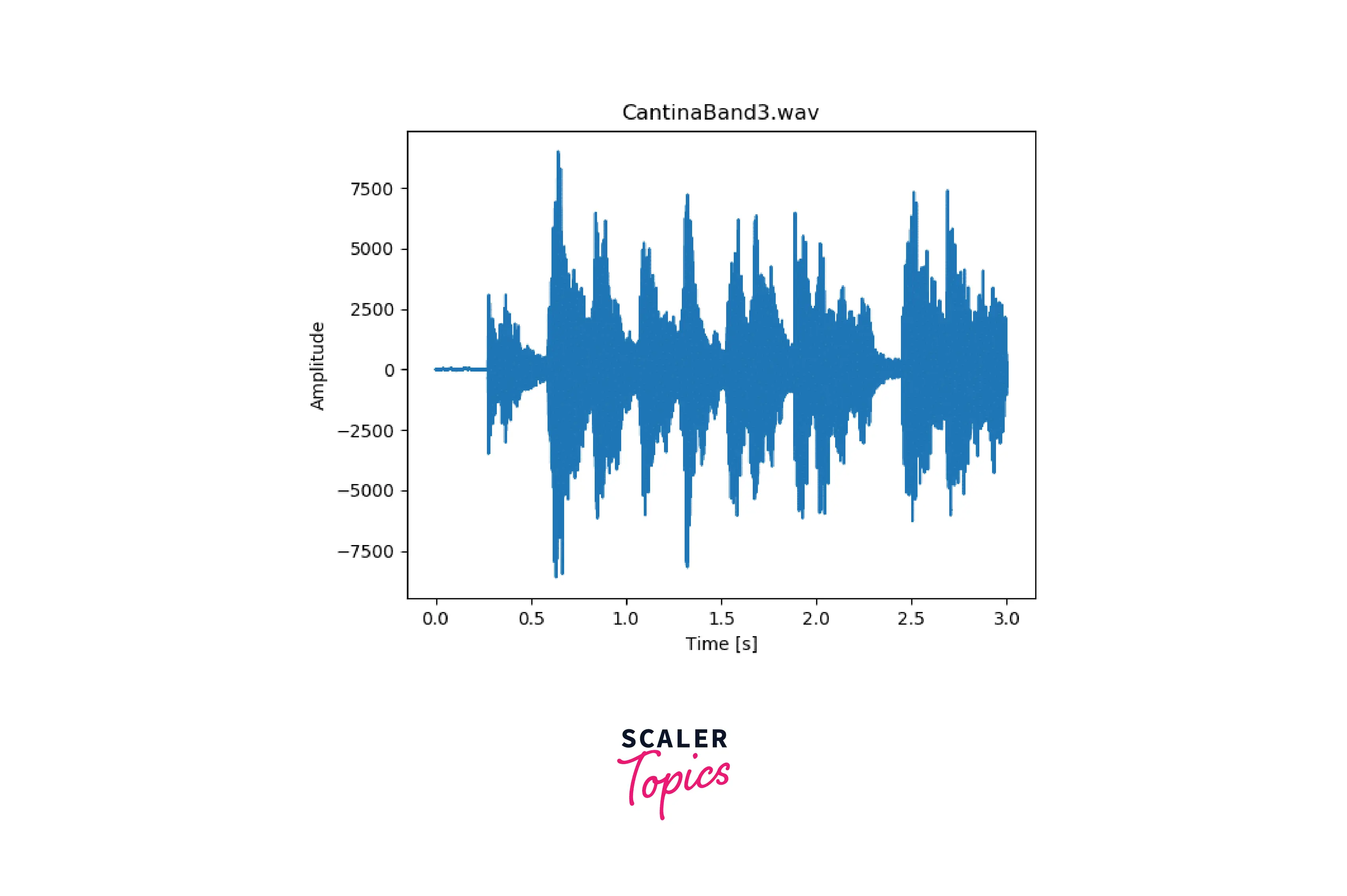
The graphical representation of the sound wave over time is known as a waveform.
Sample Rate
The number of times per second the amplitude of the incoming sound is captured (or processed) by the audio capturing device is called the sampling rate or the frame rate.
It is measured in frames per second, or Hertz (Hz), and some common sampling rates are 16 kHz (common in VoiP), 44.1 kHz (common in CDs), and 96 kHz (common in DVDs and Blu-Rays).
In other words, a sampling rate of 48 kilohertz (kHz) amounts to capturing 48,000 samples or frames per second.
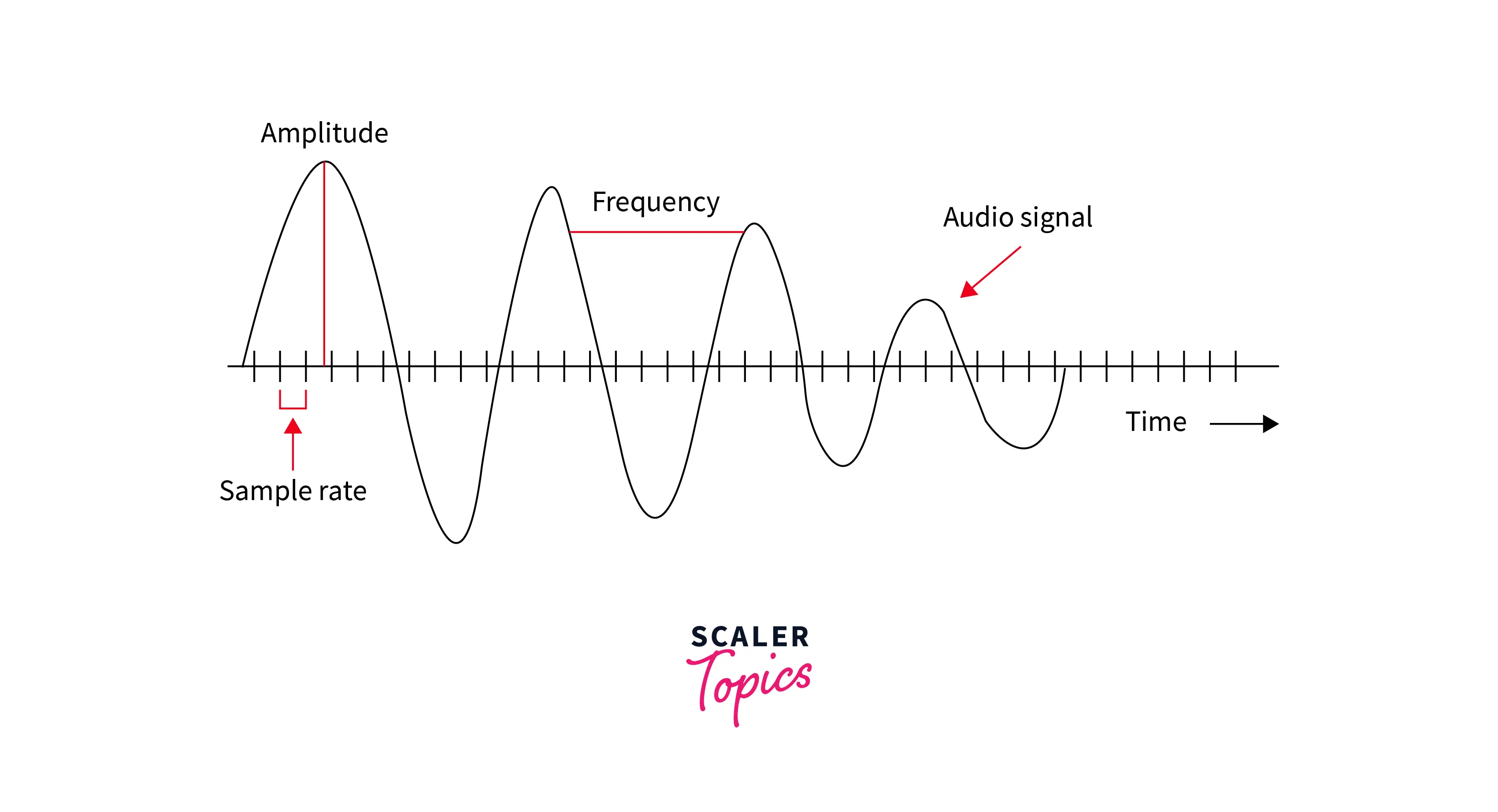
The higher the sample rate of capturing frames, the higher the sound quality produced (recorded) by the capturing device. However, after reaching a certain threshold, the human ear can not detect differences in sound quality.
Ways to Represent Audio Data
While waveforms or audio are easily representable in the form of numbers, there are various formats it can be stored in computers.
The most common file types for storing audio data are .wav and .mp3.
The prime difference between .wav and .mp3 file types is that .wav files are not compressed and are used to store high-quality audio data, while .mp3 files are compressed and best suited for faster streaming.
Other popular file types to store audio data include Audio Interchange File Format (AIFF), which is developed by Apple; raw Pulse Code Modulation (PCM) data which is the raw audio data format; and Advanced Audio Coding (AAC).
What is TorchAudio
We will now look at TorchAudio, a module in the PyTorch library to deal with audio and signal data processing. It provides easy access to common, publicly accessible datasets and functionality like common audio transformations to model and handle audio data in PyTorch. Most of the TorchAudio APIs also support PyTorch's autograd, and most of the APIs can also be serialized using TorchScript to make them executable in non-Python environments.
Let us now learn about the basic API with some code experimentation.
We will first install and import all the dependencies/libraries, etcetera, like so:
We will now use the download_asset API of torchaudio to download standard datasets from it.
Torchaudio provides a simple way to access the metadata associated with a dataset like so :
The sample rate, number of frames in the data, and so on are some metadata displayed using this function. torchaudio.info also works similarly with a file like objects, like so :
TorchAudio provides a function called torchaudio.load() to load audio data in PyTorch.
The function accepts a path-like or file-like object as the input argument and returns as value a tuple of the waveform, which is of the type Tensor, and sample rate, which is of the type int.
By default, the resulting tensor object has dtype=torch.float32, whose value lies in the range [-1.0, 1.0].
We can now use the waveform tensor to visualize our signal in the form of a waveform like so :
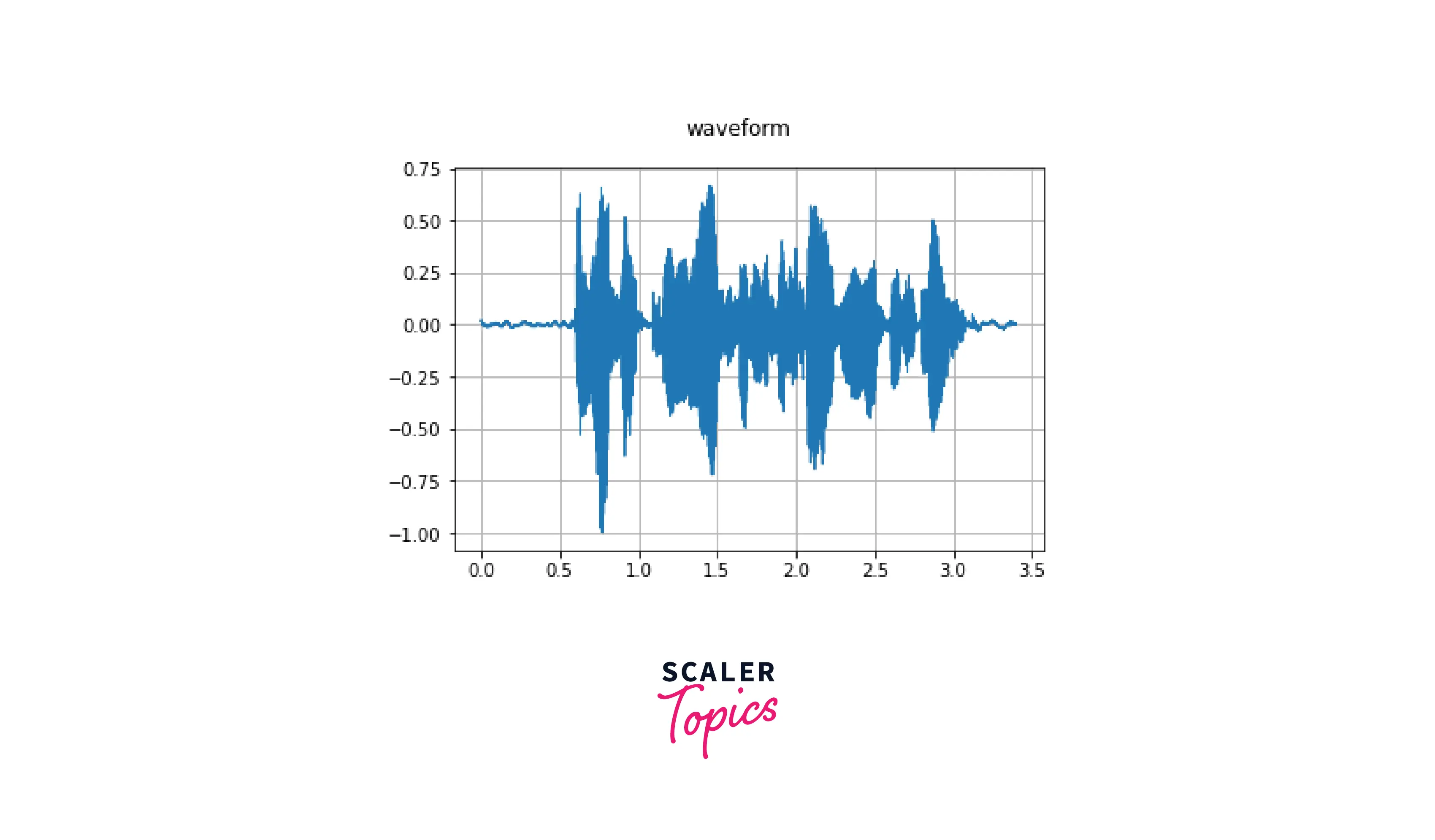
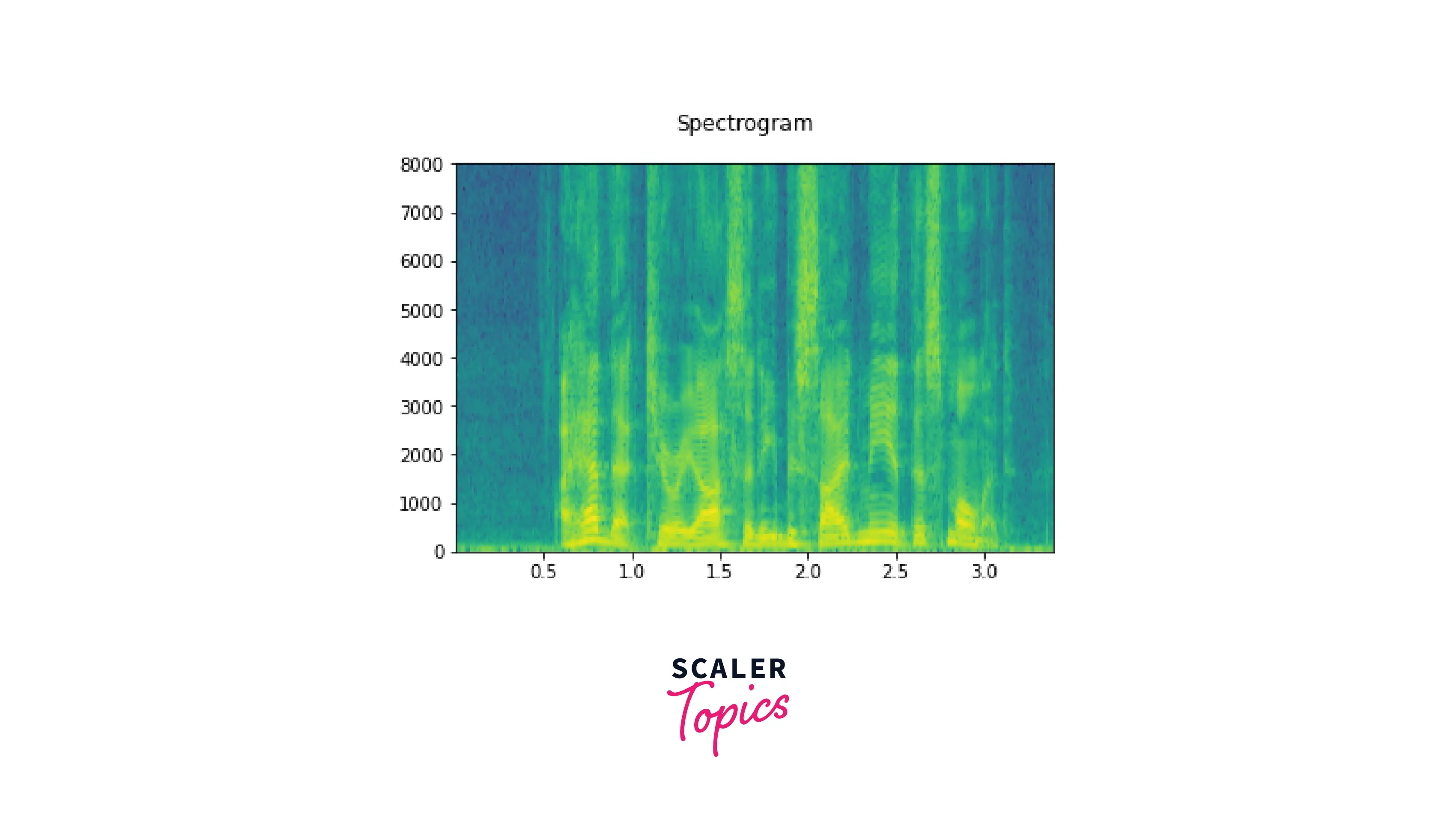
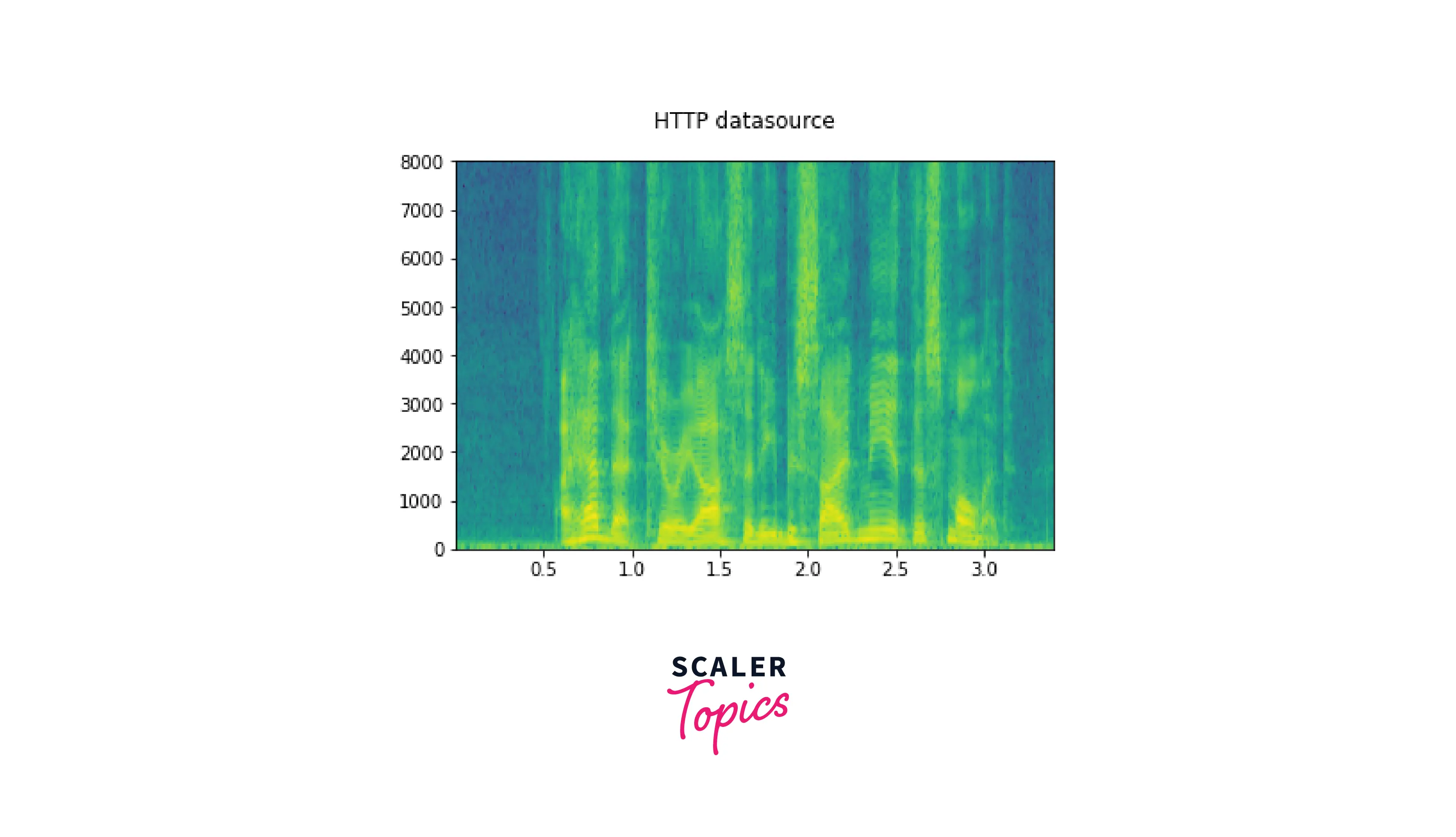
Let us now define a helper function to plot a spectrogram which is the plot of the spectrum of frequencies of a signal as it varies with time.
gives
torchaudio.load can be used in a similar way to load a file like an object which is a result of an HTTP request, like so -
gives
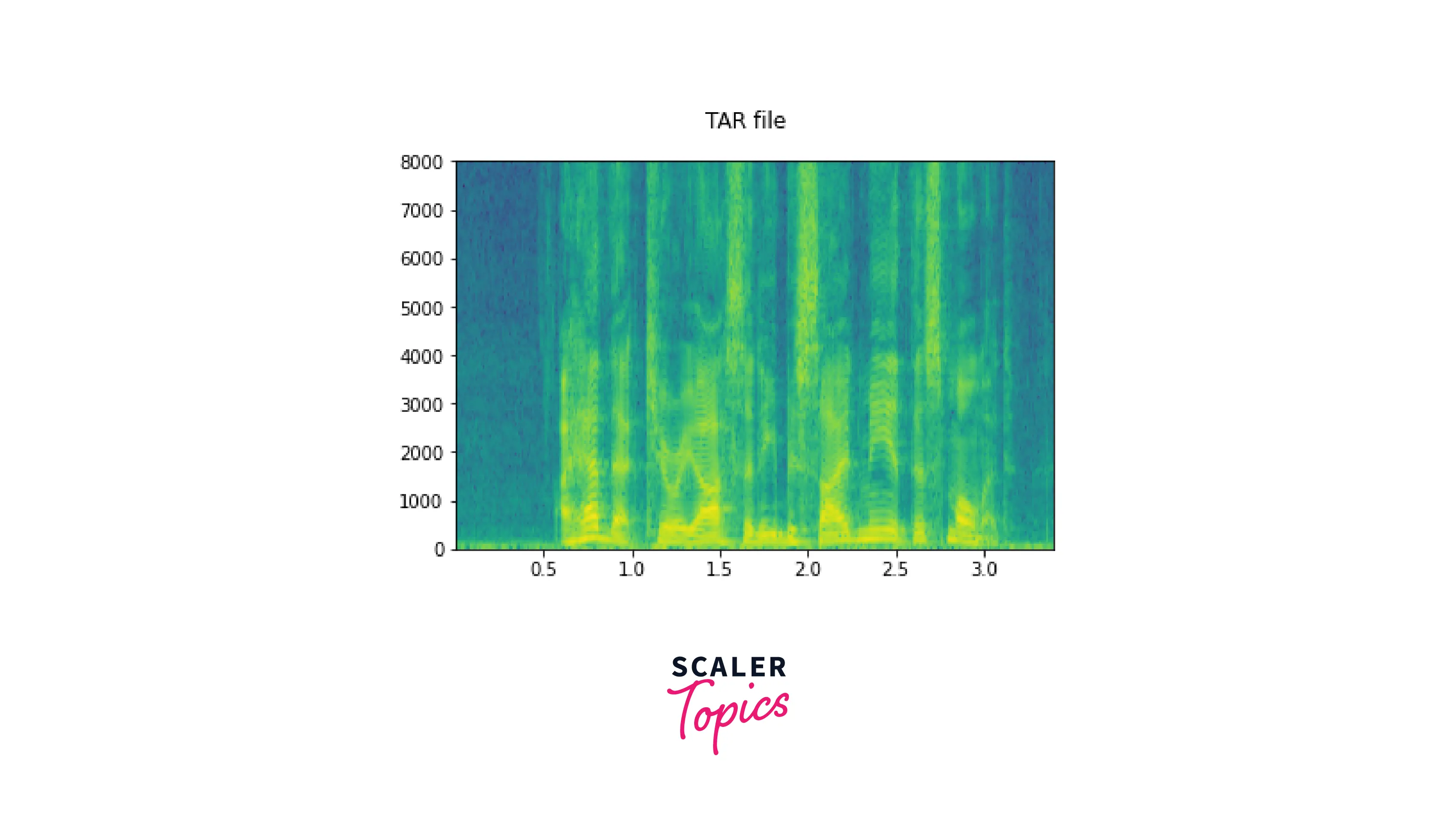
Similarly, we could use torchaudio.load to load from a tar file, like so -
gives
That was it about the basic functionality of TorchAudio.
Conclusion
The following blog introduces audio data, an important data format for building important industry applications. in particular,
- We learned about audio data while throwing light on the use cases in audio, and signal processing becomes useful.
- We learned about the important concepts associated with audio data, like the sample rate, types of file extensions, and so on.
- Finally, we work through TorchAudio and practically demonstrate some of its functionality by implementing it.