How to Adjust Learning Rate in Pytorch ?
Overview
This article is a guide to PyTorch Learning Rate Scheduler and aims to explain how to Adjust the Learning Rate in PyTorch using the Learning Rate Scheduler. We learn about what an optimal learning rate means and how to find the optimal learning rate for training various model architectures.
Introduction
Learning rate is one of the most important hyperparameters to tune when training deep neural networks. A good learning rate is crucial to find an optimal solution during the training of neural networks.
To manually tune the learning rate by observing metrics like the model's loss curve, would require some amount of bookkeeping and babysitting on the observer's part.
Also, rather than going with a constant learning rate throughout the training routine, it is almost always a better idea to adjust the learning rate and adapt according to some criterion like the number of epochs.
What is the Learning Rate?
-
Learning rate is a hyperparameter that controls the speed at which a neural network learns by updating its parameters.
-
As we know, supervised learning relies on the backpropagation of errors to the model which allows the model parameters to adjust themselves - this is in short what training neural networks mean.
-
Let us understand the concept succinctly, taking gradient descent as an example :
As we know in gradient descent, at each iteration, the parameters are updated to take a step in the negative direction of the steepest gradient.
-
Mathematically,for a set of parameters , each parameter updates by the following equation :
Where delta is the gradient of the loss function with respect to .
What is alpha ?
-
This alpha is exactly what the learning rate is and it controls by what magnitude the network's parameters adjust themselves according to the gradient of the loss.
-
A large value of alpha would cause the parameters to change rapidly, whereas a small value causes slow and steady updates to the parameters.
How to Decide the Right Learning Rate?
Let us now look at the considerations associated with the two cases we defined above: that is, a large value of alpha vs. a small value of alpha.
-
Large alpha:
As is evident from the equation , a large value of alpha or the learning rate causes the network parameters to take big leaps towards updating their values to be able to converge to an optimal solution.-
Pros:
Larger steps toward the optimal solution directly translate to the network training faster without requiring a large number of epochs before the parameter values converge to a solution. A lesser number of epochs also mean a lesser number of iterations, hence a lesser number of passes over mini-batches of data, which leads to lesser consumption of memory. -
Cons:
Larger leaps could also cause the optimizer to skip the minima altogether. This could further cause two issues, one of which is exploding gradients wherein because of larger updates to the parameters with a large learning rate, the parameter values could increase too much and go to infinity: thus the name "exploding".The other phenomenon that could occur as a result of a learning rate that is too large, is oscillating losses, which could further lead to the network converging to a sub-optimal solution.
-
-
Small alpha:
With a very small learning rate, the optimization algorithm takes very slow steps in updating the model parameters.-
Pros:
Slow updates to the parameters as a result of a small learning rate remove the possibility of skipping the minima to a great extent. There is nowhere a possibility of the exploding gradient problem occurring and the network learns steadily. -
Cons:
With a very slow learning rate, the network is faced with the problem of vanishing gradients, which amounts to parameter values practically stagnating as they do not update at all due to a learning rate that is too small. Training is stopped and the network remains at a suboptimal solution.Apart from the vanishing gradient problem, small learning rates require the network to go through a very large number of epochs to be able to learn something from the data and reach an optimal solution. A larger number of epochs is an issue for the obvious reason that they would cause the network to require a large amount of memory before it can learn something useful.
-
With these points considered, how does one decide what the right learning rate is? How large a learning rate isn't too large and how small a learning rate isn't too small?
We will look at it next as we try to find an answer to these questions.
Good Learning Rate, Bad Learning Rate
Ideally, we would want to train our models with a learning rate that causes a steep decrease in the graph of the network's loss function. This is an indication of a good learning rate.
No learning rate is universally optimal and the optimality of the learning rate generally depends on the structure of the loss landscape which in turn depends on the model architecture in use and the dataset the model is being trained on.
While using a "default learning rate" (that is the default set by your deep learning library) may provide decent results, you can often improve the performance or speed up training by searching for an optimal learning rate.
Why Adjust the Learning Rate?
There are two ways one could think of adjusting the learning rate while training neural models :
- Adjusting the learning rate according to how the parameter values change throughout training. Or, adjust the learning rate according to the number of epochs the model trains through.
This amounts to not going for a constant learning rate throughout as the training happens, but for a learning rate that changes over time based on some criterion.
- Adjusting the learning rate according to our model. Essentially, we could choose to not go by the default value provided by our deep learning library even though it is capable of providing decent results, but rather we could choose an optimal learning rate that we deem to be suited to our network.
This amounts to choosing a constant value according to our network.
Turns out that these two ideas are more or less the same and also contain the reason why adjusting the learning rate proves to be efficient. By adjusting the learning rate, we are essentially adapting the hyperparameter according to our model, and also according to the time as a function of the number of epochs.
This often leads to performance speedup and causes the network to train better so that the network can reach a more optimal solution.
What is a Learning Rate Scheduler in PyTorch?
Adjusting the learning rate is formally known as scheduling the learning rate according to some specified rules. There could be many such rules according to which the learning rate adjusts itself throughout training.
"PyTorch Learning Rate Scheduler" provides support for scheduling the learning rate via the API torch.optim.lr_scheduler, which has several schedulers each defined according to some differently specified rules.
We will look at the various schedulers next with code examples demonstrating their use.
Adjusting the Learning Rate in PyTorch :
LambdaLR
LamdaLR scheduler adjusts the learning rate in every epoch according to a lambda function.
In the above example, we defined an optimizer as an instance of the Adam class with an initial learning rate equal to 0.1.
lr_scheduler is a LambdaLR scheduler that changes the learning rate in each epoch according to the function lambda1. For each epoch, the learning rate = initial learning rate * epoch/10.
Hence, the following schedule shall be followed as the number of epochs increases:
| epoch | learning rate |
|---|---|
| 1 | 0.01 |
| 2 | .02 |
| 3 | .03 |
| 4 | .04 |
and so on.
Hence, with this schedule, the learning rate grows as the number of epochs increases.
MultiplicativeLR
The learning rate in each epoch is some factor times the learning rate in the previous epoch.
In the following example, we define a function lambda1 to implement this schedule.
So, the learning rate in each subsequent epoch is 0.9 times the learning rate in the previous epoch.
The schedule over the epochs hence looks like the following :
| Epoch | learning rate |
|---|---|
| 1 | 0.09 |
| 2 | 0.081 |
| 3 | 0.0729 |
Hence the following schedule decays the learning rate as the model trains through the epochs.
StepLR
The step learning rate multiplies the learning rate with a constant gamma after every fixed number of epochs.
In the above example, the initial learning rate is , , and step_size . The step size defines the number of epochs the learning rate is changed after.
Hence so, after every 10 epochs the learning rate changes to lr * step_size.
In this case, the subsequent values taken by the learning rate are hence 0.01, 0.001, and so on.
This is also an example of learning rate decay wherein we start with a large value of the hyperparameter and move to smaller values as the network trains through epochs.
MultiStepLR
Multistep learning rate is like a customized version of the step learning rate as herein we explicitly define the epochs at which the learning rate would change. We do it using milestones.
For the above code, the learning rate through the epochs will be scheduled as follows :
| Epoch | learning rate |
|---|---|
| < 20 | 0.1 |
| > = 20 and < 40 | 0.01 |
| > = 40 | 0.001 |
Here also the learning rate decays as the number of epochs grows in number.
As the model trains during the first 19 epochs, the learning rate will be equal to 0.1, which then decays to 0.01 as the model enters the 20th epoch, and continues to train with a learning rate of 0.01.
Finally, as the model reaches the 40th epoch of training, the learning rate further reduces to 0.001 and continues to be so for as long as the model trains after the 40th epoch.
ExponentialLR
With an exponential learning rate, the value of the hyperparameter decays after every epoch. In other words, the model trains with a different value of the learning rate in every subsequent epoch.
This could also be seen as an aggressive version of the step learning rate with the value of the parameter step_size equal to 1.
For this example, the following schedule is followed by the learning rate as it trains through the different epochs :
| Epoch | learning rate |
|---|---|
| 1 | 0.1 |
| 2 | 0.01 |
| 3 | 0.001 |
and so on.
ReduceLROnPlateau
This scheduler is based on a stronger intuition as compared to the ones we have discussed so far. Till now, we have been scheduling our learning rate "in a naive way" based on the number of epochs and not based on an inherent notion of the performance of the state of the model over the epochs.
On the other hand, ReduceLROnPlateau adjusts the learning rate based on a metric. If the value of this metric doesn't improve for a certain number of epochs, the learning rate is adjusted according to a factor.
Here patience defines the number of epochs after which the learning rate will be reduced if there's no improvement in the metric of our choice.
We will see a working example of this scheduler on the MNIST dataset just next.
Scheduling the Learning Rate on MNIST Dataset
To demonstrate how the PyTorch Learning rate scheduler helps adjust the learning rate as the model trains, we will work through a hands-on example by taking MNIST dataset and building a simple neural net to train it.
We will use the ReduceLROnPlateau scheduler as our Pytorch Learning rate scheduler to adjust the learning rate for model training.
Output:
As can be seen in the above output block, the loss after epoch 2 starts to climb. The scheduler waits for 5 more epochs from epoch 3 through epoch 7 to see if there happens any improvement in the loss, post which, it updates the learning rate from 0.1 to .001 in the 8th epoch.
Finding the Learning Rate Using PyTorch Lightning
PyTorch Lightning, another popular deep learning framework, provides an easy API to find an initial learning rate for training deepb learning models, thus saving us the guesswork required in choosing a good initial learning rate.
This paper describes how a learning rate finder proceeds with a small run and where the learning rate is increased after each batch is done processing.
The corresponding losses from each batch with a different learning rate are logged which results in a learning rate vs. loss plot that can be hence used as a guiding plot to choose an optimal initial learning rate.
To enable an automatic learning rate finder in PyTorch Lightning, all it takes is to set the argument auto_lr_find as True while instantiating the Trainer class, like so :
Now as the trainer.fit method is called, a learning rate range test is performed underneath, and a good initial learning rate is selected using which the model has trained right away.
Hence, all it takes is Trainer(auto_lr_find=True) and the fit method call.
There is also an alternative approach that explicitly allows us to look at the learning rate vs. loss plot that we discussed above, and assesses which value was chosen as the initial learning rate, like the following graph :
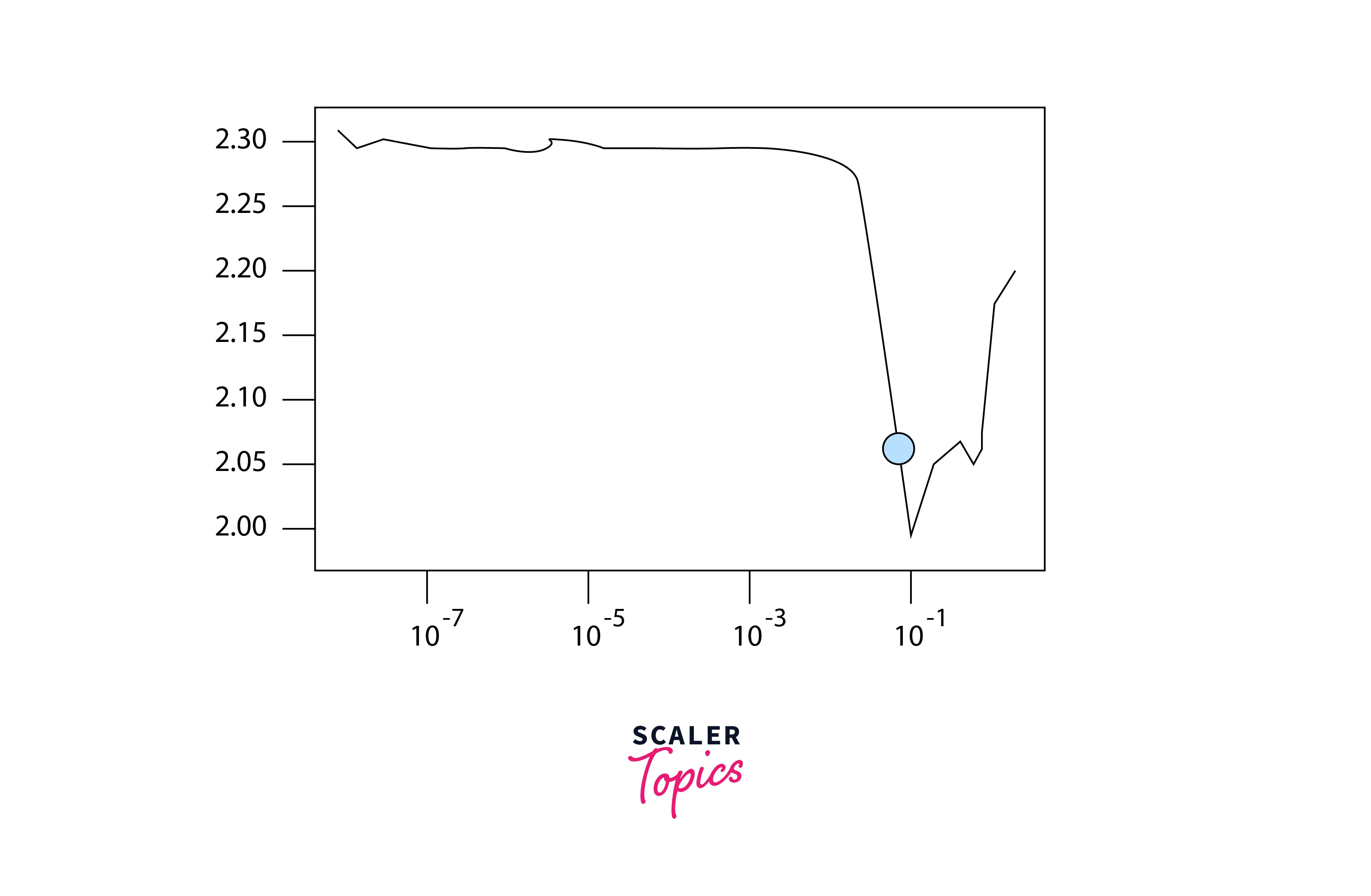
To implement this approach, the Trainer instance is created with the default value of auto_lr_find which is False and the method lr_find is called later manually, like so :
As lr_find is called with the model instance passed as a parameter, the learning rate finder is run. Further, we can plot the learning rate vs. loss plot by calling the plot method on lr_finder.
Finally, the learning rate hyperparameter for the model is set equal to the learning rate suggested by the lr_finder, and the model is trained (fit) with this learning rate.
Conclusion
In this article, we learned about the learning rate which is one of the most important hyperparameters to tune while training deep neural networks. In particular,
- We briefly defined what the learning rate is and where exactly it manifests itself in the model training pipeline.
- We focussed on the importance of learning rate using assessing what a large and a small value of the learning rate imply.
- We then moved our discussion to focus on the concept of adjusting the optimizer's learning rate while focusing on the importance of having scheduled learning rates using the Pytorch Learning rate schedulers.
- After this, we also implemented a full-fledged example using a scheduled learning rate routine leveraging the PyTorch Learning rate scheduler on the MNIST dataset.
- Finally, we also look at how PyTtorch Lighting, a popular deep-learning library, makes it easy and efficient for us to find a good value for the initial learning rate and hence saving us the guesswork involved.