Introduction to Transformers in PyTorch

Overview
Transformer-based language models have been state-of-the-art in natural language processing since they were introduced. Transformers rely completely on the concept of attention (in fact, the paper is called "Attention is all you need"), another breakthrough concept in deep sequential modeling.
To this end, this article discusses transformers and the attention mechanism that backs them along with the PyTorch support for these models, that is, PyTorch transformers along with a PyTorch transformer example to demonstrate the easy implementation support offered by the PyTorch API, which is one of the most popular deep learning libraries.
Introduction
Transformer models are faster and have given much better results than sequential models like RNNs, and LSTMs for modeling text sequences in natural language processing.
And so, before discussing what the attention mechanism and eventually transformer-based models in the field of natural language processing or any field modeling sequential data are, let us first take a step back to revise the concepts of sequence-to-sequence (seq2seq) modeling or deep sequential modeling along with the primary type of deep neural architecture proposed to handle sequential data.
-
Deep sequential modeling deals with data sequences, a stream of data that contains an inherent structure of a sense of order where the notion of order is just as important as the data values itself.
-
to model sequences, we need to do away with the classic multi-layer perceptrons of the feed-forward neural networks and propose some suitable architecture capable of capturing the ordering in sequences. Such networks are called recurrent neural networks (RNNs). Refer to this article for more details on RNNs.
-
Seq2seq or sequence-to-sequence modeling consists of mapping sequential data into sequential data; that is, the input to the model and the output from the model are both sequences. Machine translation, which consists of translating text from one language into another, is an example of se2seq modeling.
-
RNNs or their variants LSTMs have been used to model seq2seq tasks consisting of an encoder side and a decoder side. While these networks have shown decent results in modeling sequences of shorter lengths, they fail to model longer sequences.
Let us elaborate more on the last point to see why that happens. The diagram below shows how RNNs can be used to construct an encoder-decoder structure for seq2seq modeling.
But, the encoder deals with ingesting input sequences and generating hidden representations from every input unit. At the same time, the decoder state ingests the information (specifically, the context) from the encoder side using the hidden state and hence deals with generating the output sequence using the encoder's hidden state.
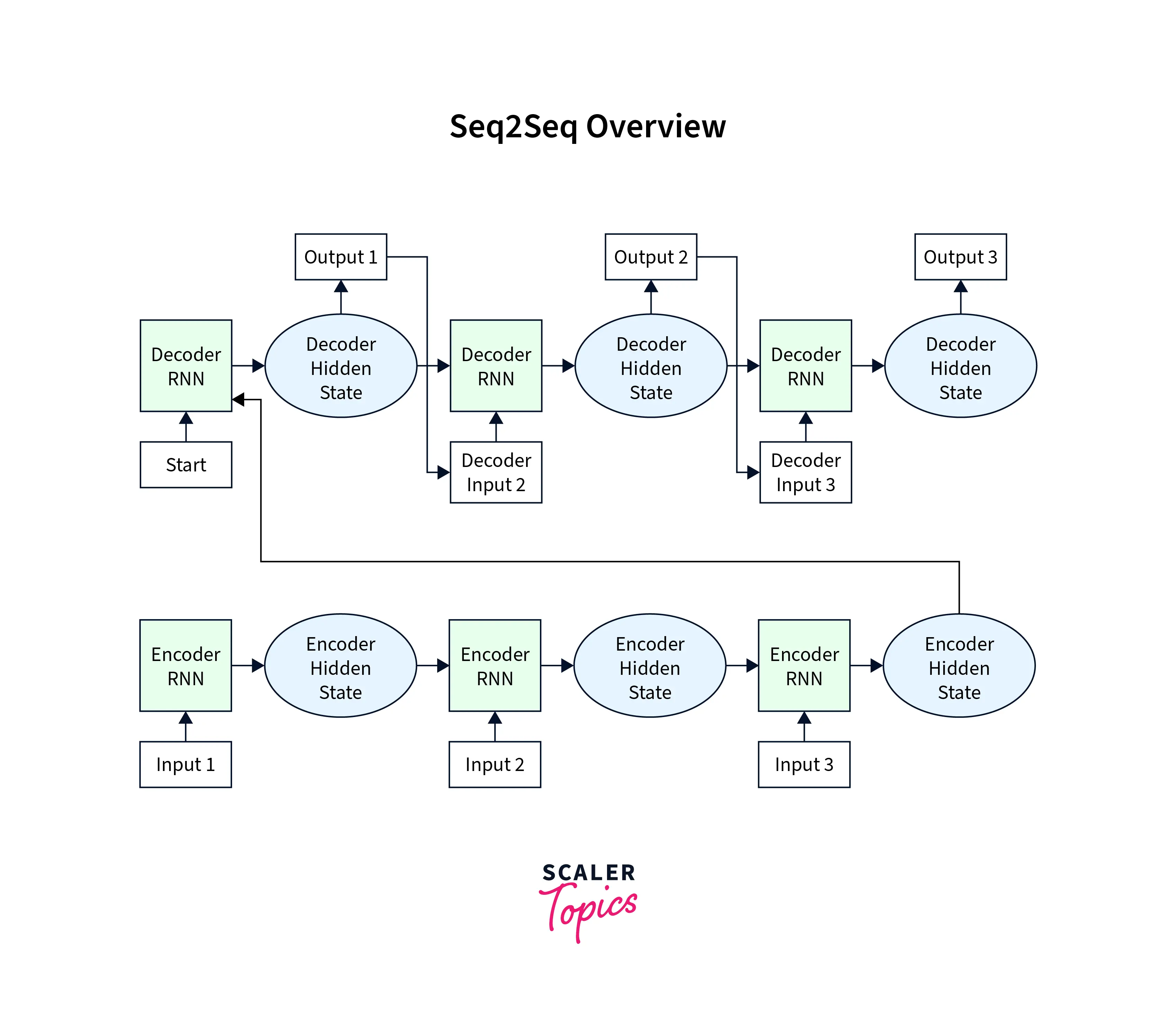
This architecture has one major shortcoming - only the last hidden state of the encoder RNN is used as the context vector for the decoder. While this works fine for shorter sequences, it has been seen that for longer sequences, the encoder's last hidden state is insufficient to capture the context from the whole input sentence.
Apart from this drawback, it is also worthwhile to think that with just the last hidden state, the decoder side cannot decide which part of the sentence to focus on while generating the output at a particular (time) step in the sequence.
With these two shortcomings in mind, let us move on to understand what is called the attention mechanism that directly addresses these shortcomings.
What is Attention Mechanism in Deep Learning?
The attention mechanism is designed in a way that to decode the information processed by the encoder, it is given access to all the encoder hidden states from all time steps.
With access to all the encoder hidden states, the attention mechanism gets to focus on or pay "attention" to specific parts of the sentence by assigning higher weights to them during decoding and thus can generate far more accurate outputs.
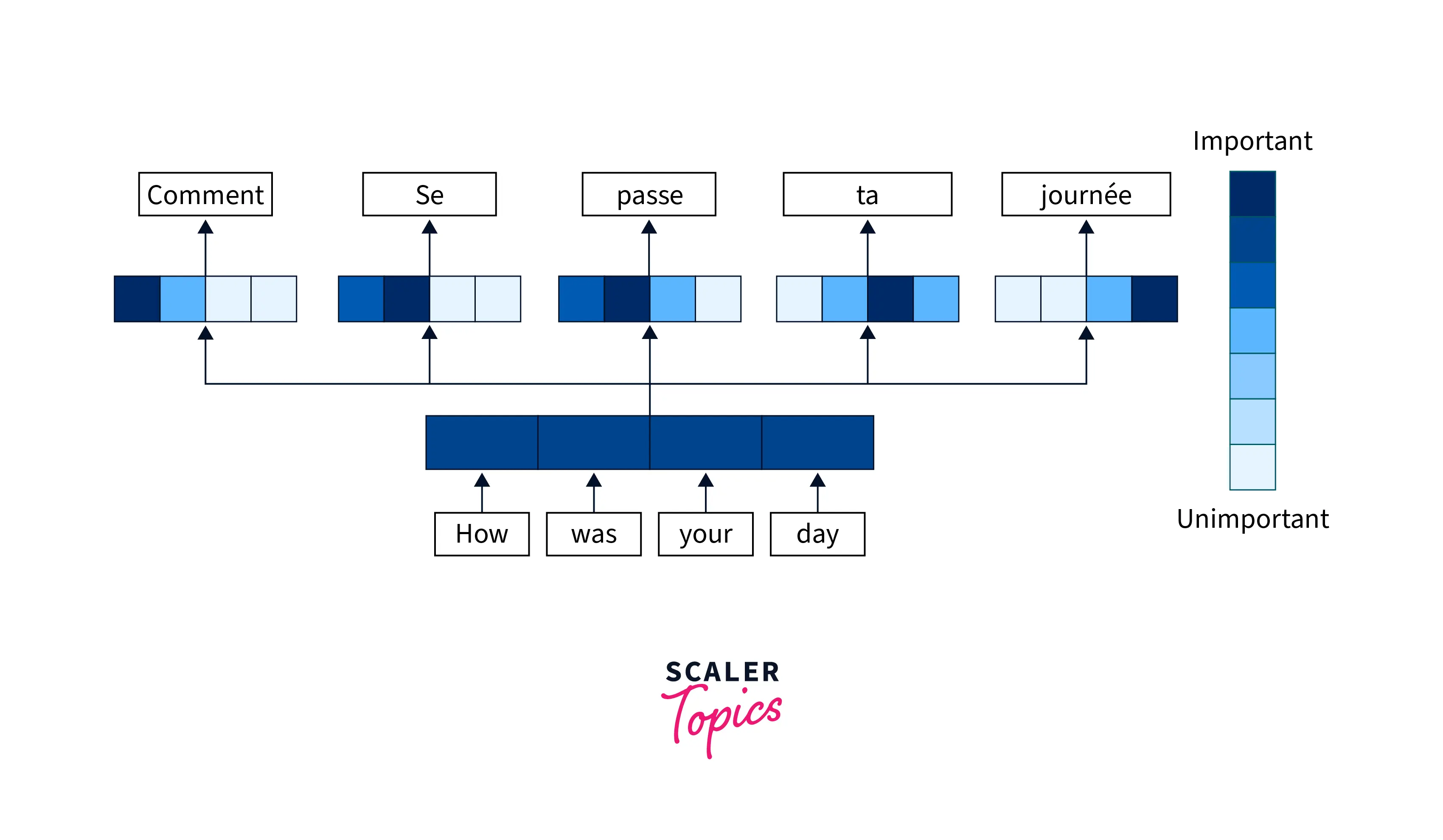
What we have discussed so far is just the intuition behind the attention mechanism.
Before diving into the exact details, we note here that two types of attention constructions differ architecturally but fundamentally work to exploit the general idea of attention that we discussed above.
The first one, called Bahdanau Attention, has the following steps:
-
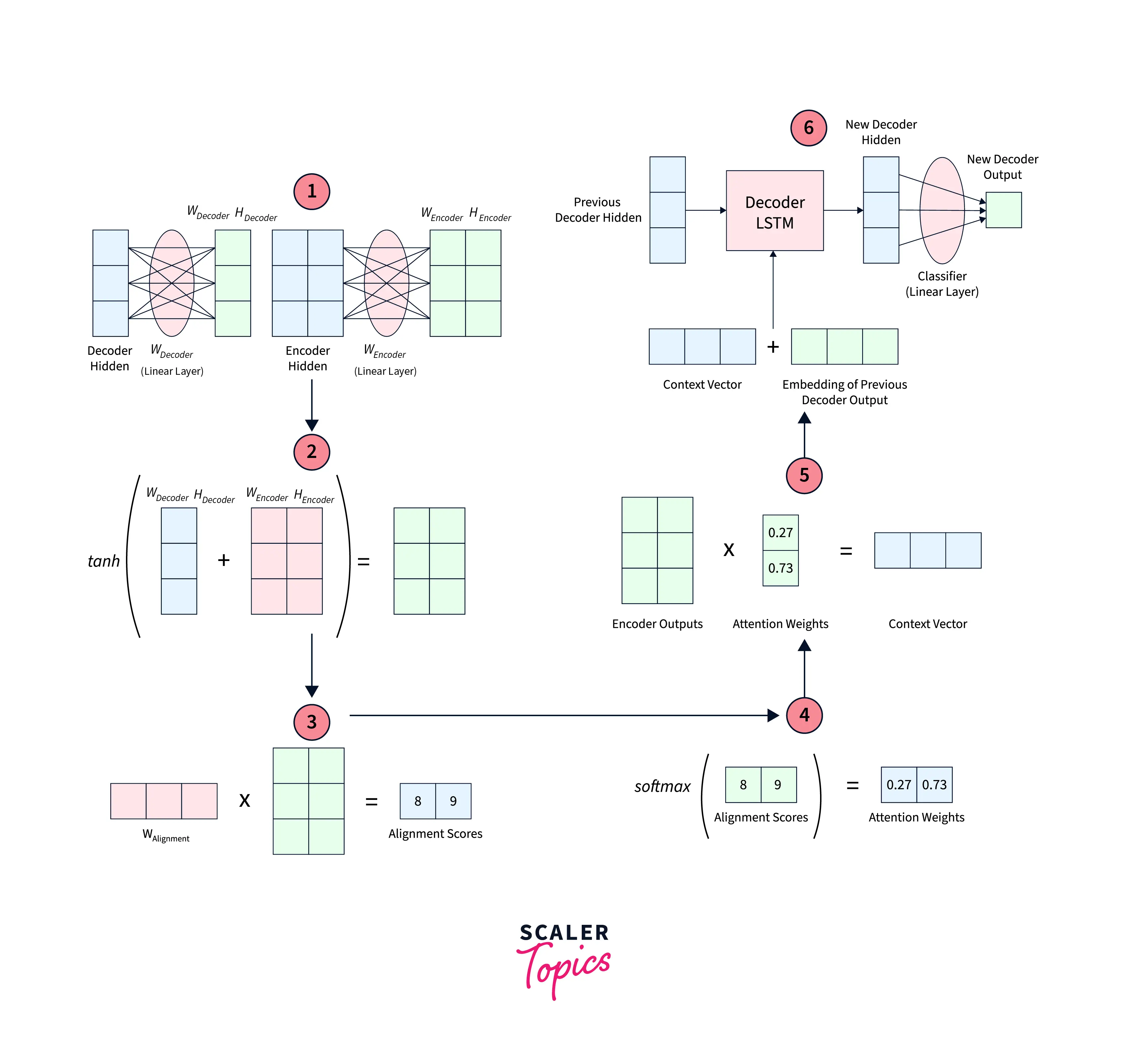
Producing the Encoder Hidden States:
On the Encoder side, the input sequence is ingested to produce hidden states corresponding to each element in the input sequence.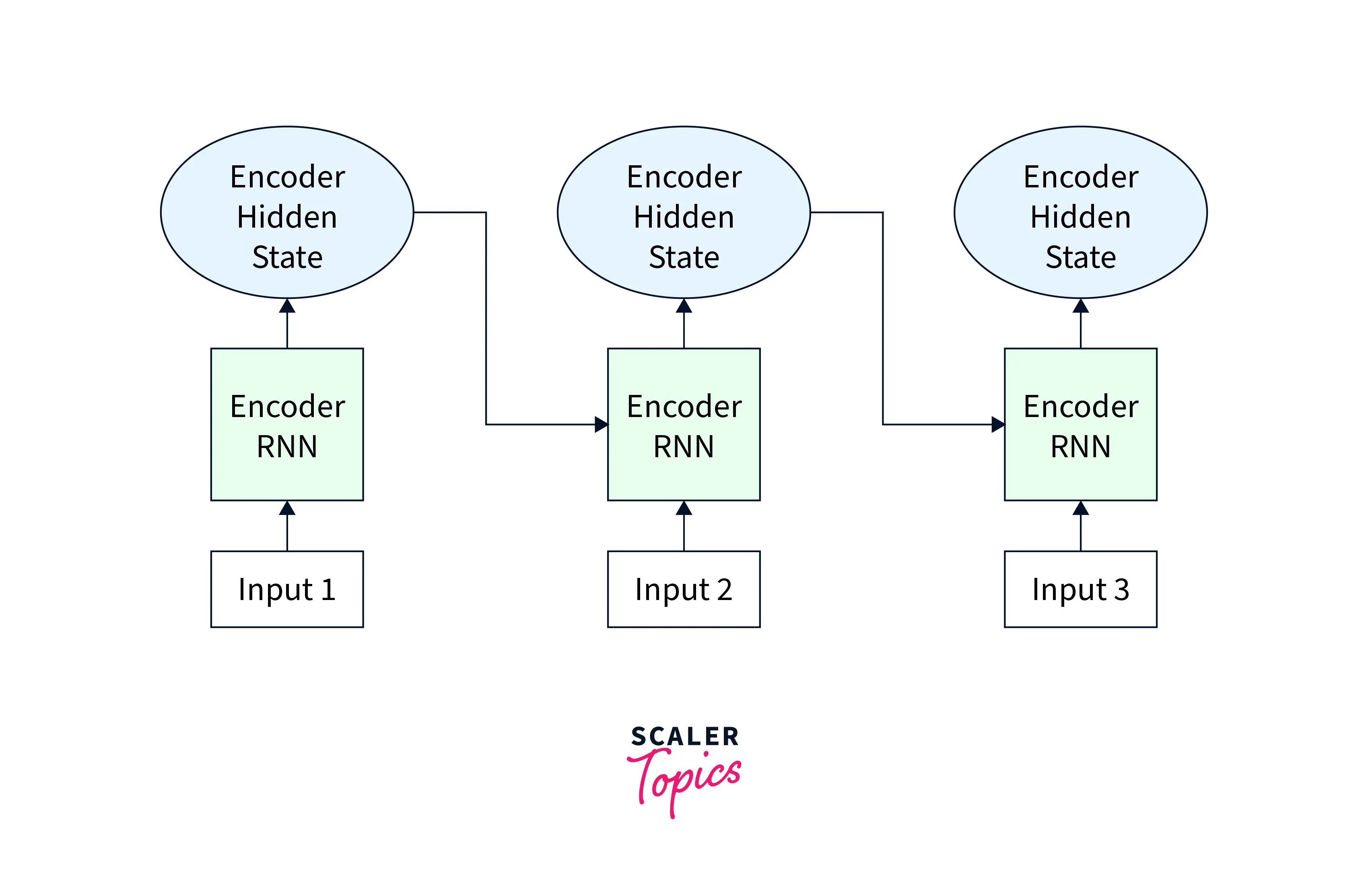
-
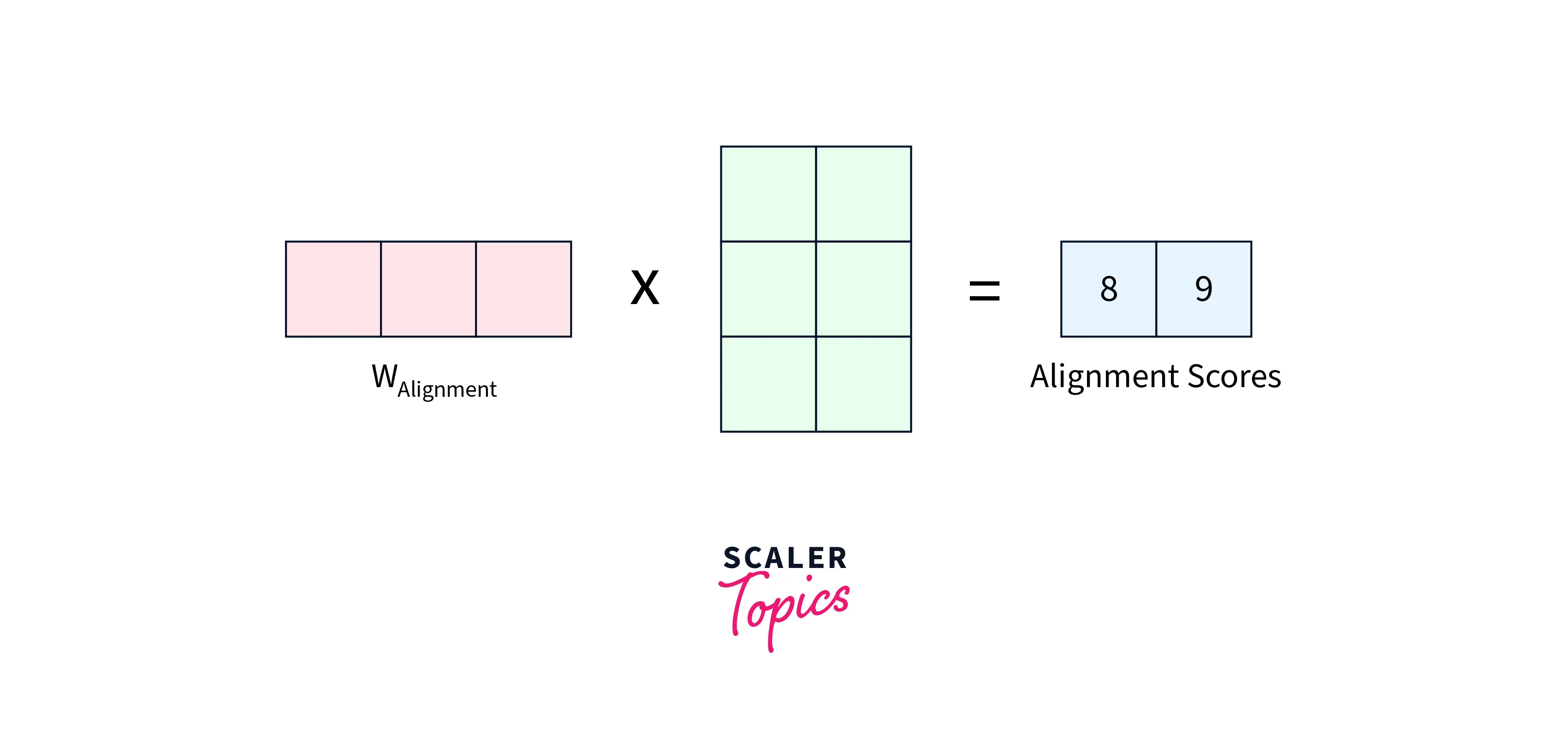
On the decoder side, Alignment Scores are calculated between the previous decoder's hidden state and each of the encoder's hidden states.
For the first time step on the decoder side, the last encoder hidden state can be used as the first hidden state of the decoder
-
Softmaxing the Alignment Scores:
The alignment scores corresponding to each encoder hidden state are concatenated in a single vector, and the softmax function is applied to them to get the softmax scores.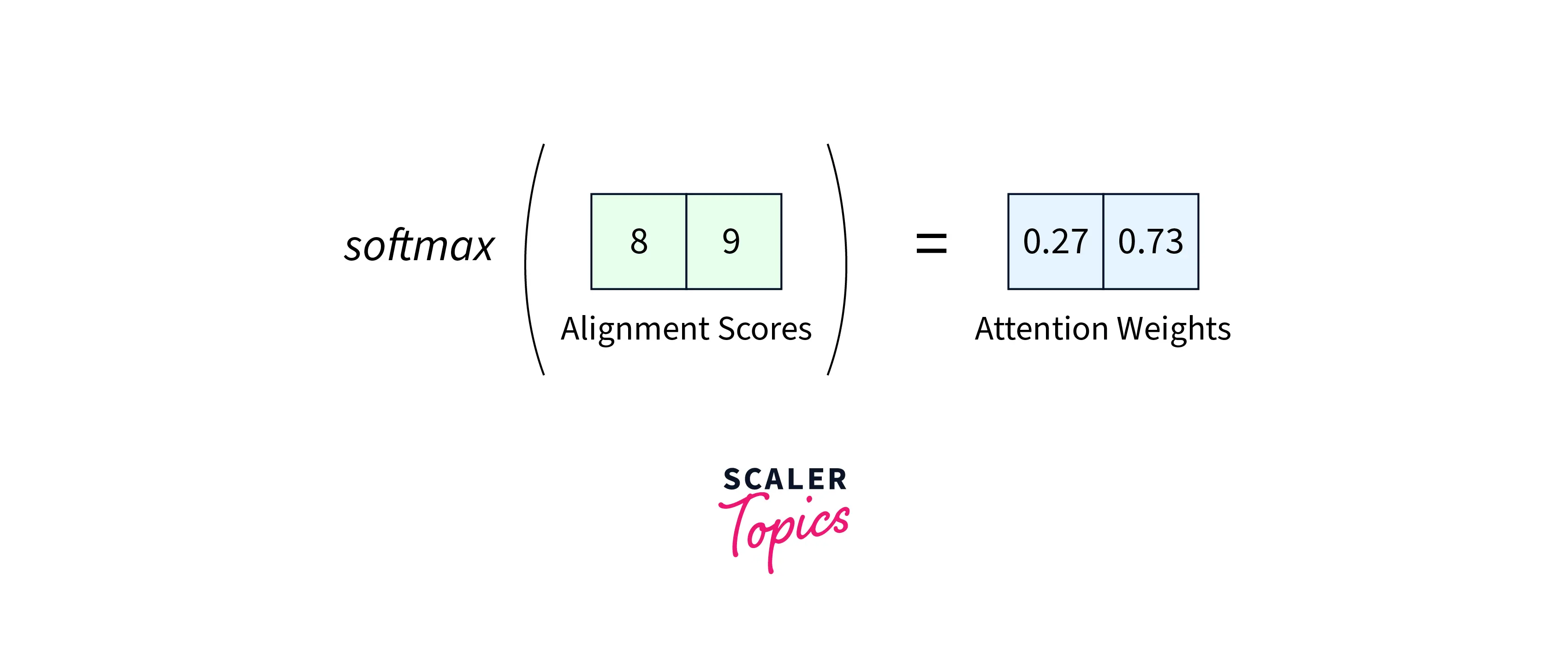
-
Calculating the Context Vector:
The alignment scores from the previous step are multiplied by the encoder's hidden states to construct the context vector.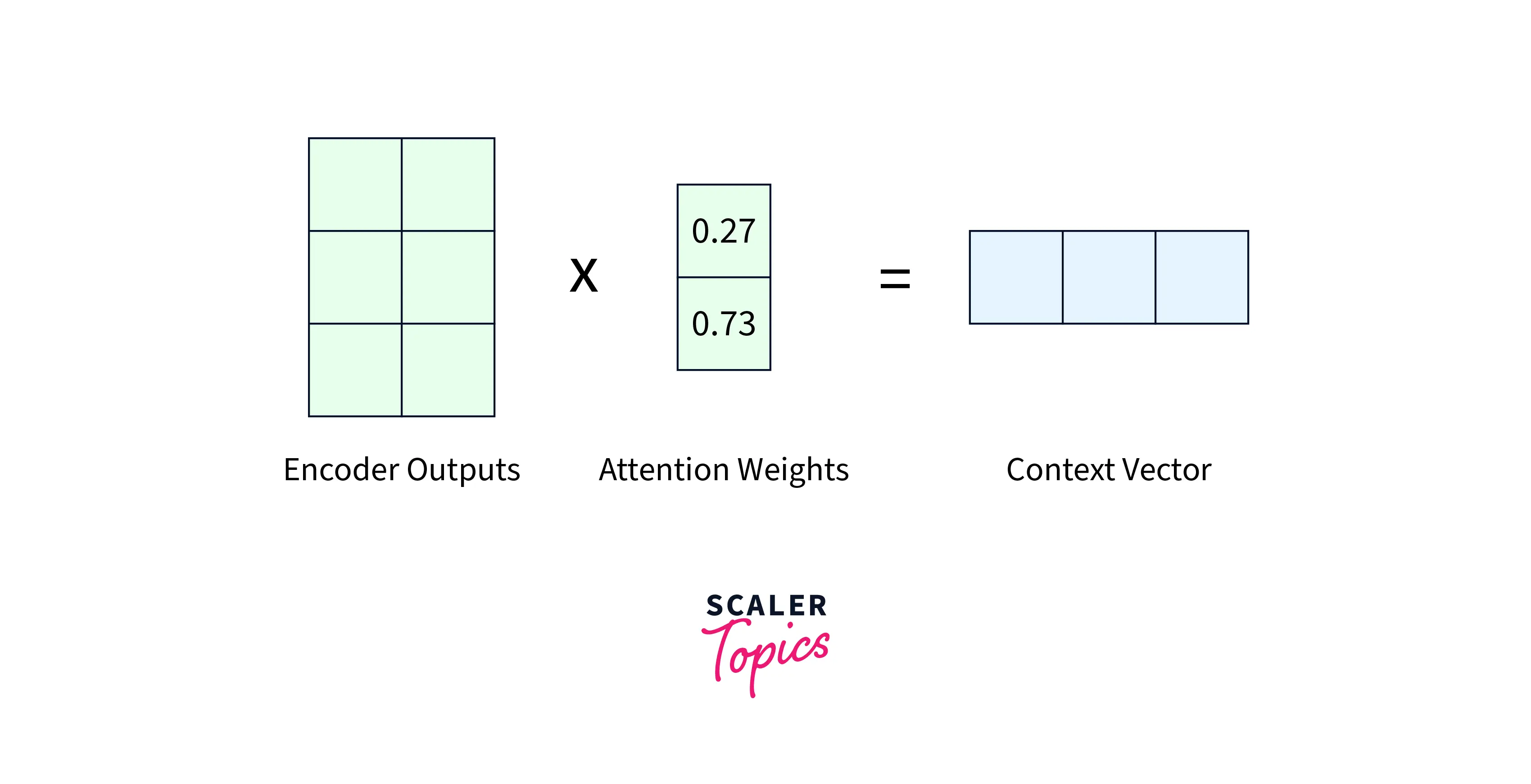
-
Decoding using the context:
The context vector obtained in step 4 is concatenated with the decoder "output" from the previous step - this, along with the previous decoder hidden state, is used as input to the decoder RNN for the current time step to produce the current output.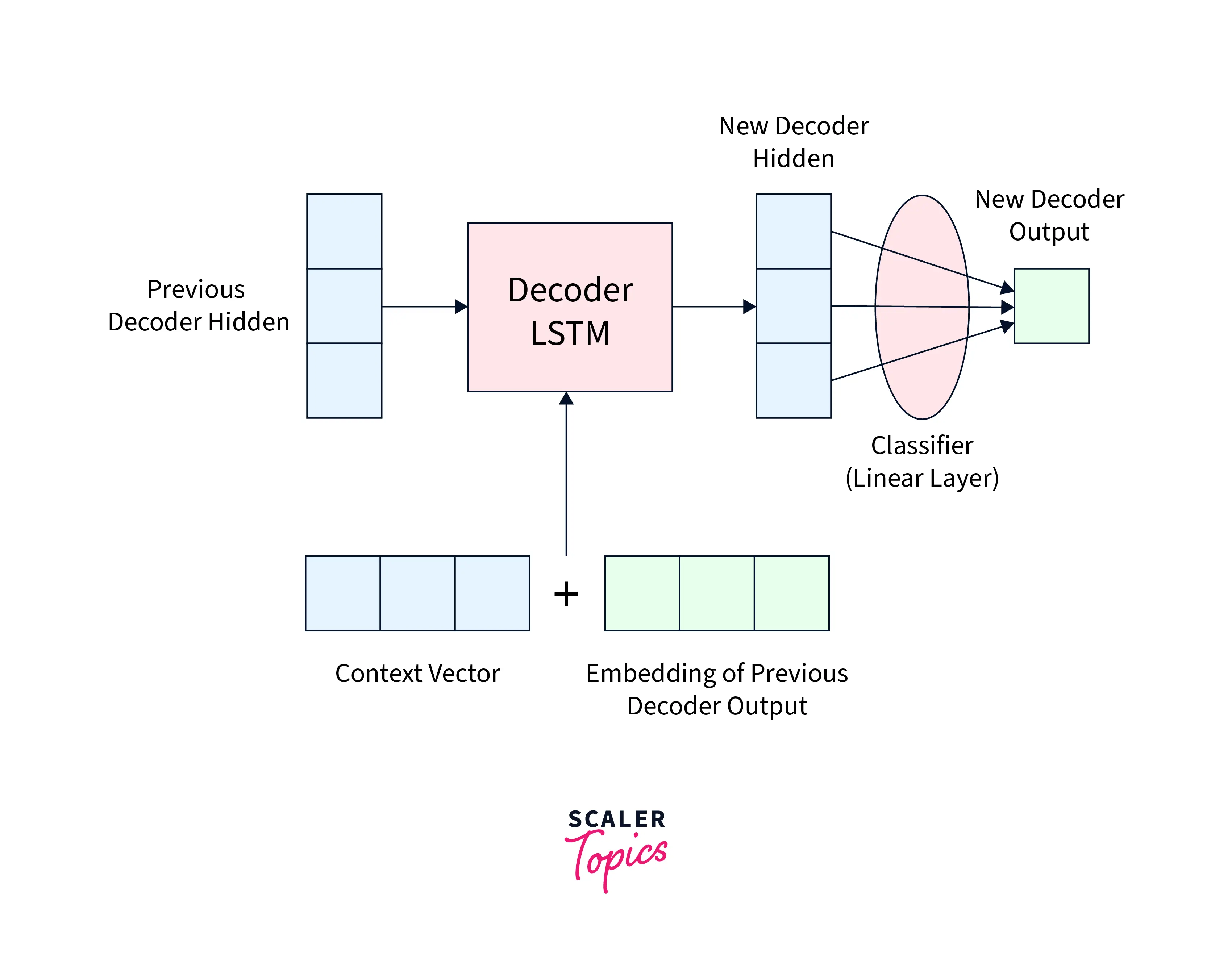
Steps 2 through 5 are iterated for each time step on the decoder side until some stopping criterion is met.
The other type of attention mechanism, called Luong Attention, is discussed below. There are two major differences between Luong Attention and Bahdanau Attention - the calculation of alignment scores and the position of introducing the attention mechanism on the decoder side.
-
Producing the Encoder Hidden States:
Like earlier, hidden states corresponding to each element in the input sequence are calculated on the encoder side. -
Decoder RNN:
On the decoder side, the previous decoder's hidden state and the previous decoder output are passed through the Decoder RNN at the current time step to generate a new hidden state for the current time step. -
Calculating the Alignment Scores:
Alignment scores are calculated between the new decoder hidden state generated in step 2 and all the encoder hidden states. -
Softmaxing the Alignment Scores:
The alignment scores corresponding to each encoder hidden state are concatenated in a single vector subjected to the softmax function. -
The Context Vector:
The context vector is calculated by multiplying the encoder hidden states and their respective alignment scores. -
The Final Output:
The context vector is concatenated with the hidden decoder state at the current time step. This concatenated vector is passed through a fully connected layer to produce the output at the current time step. Steps 2-6 are iterated over at each time step of the decoder until a stopping criterion is met on the decoder side while generating the output sequence.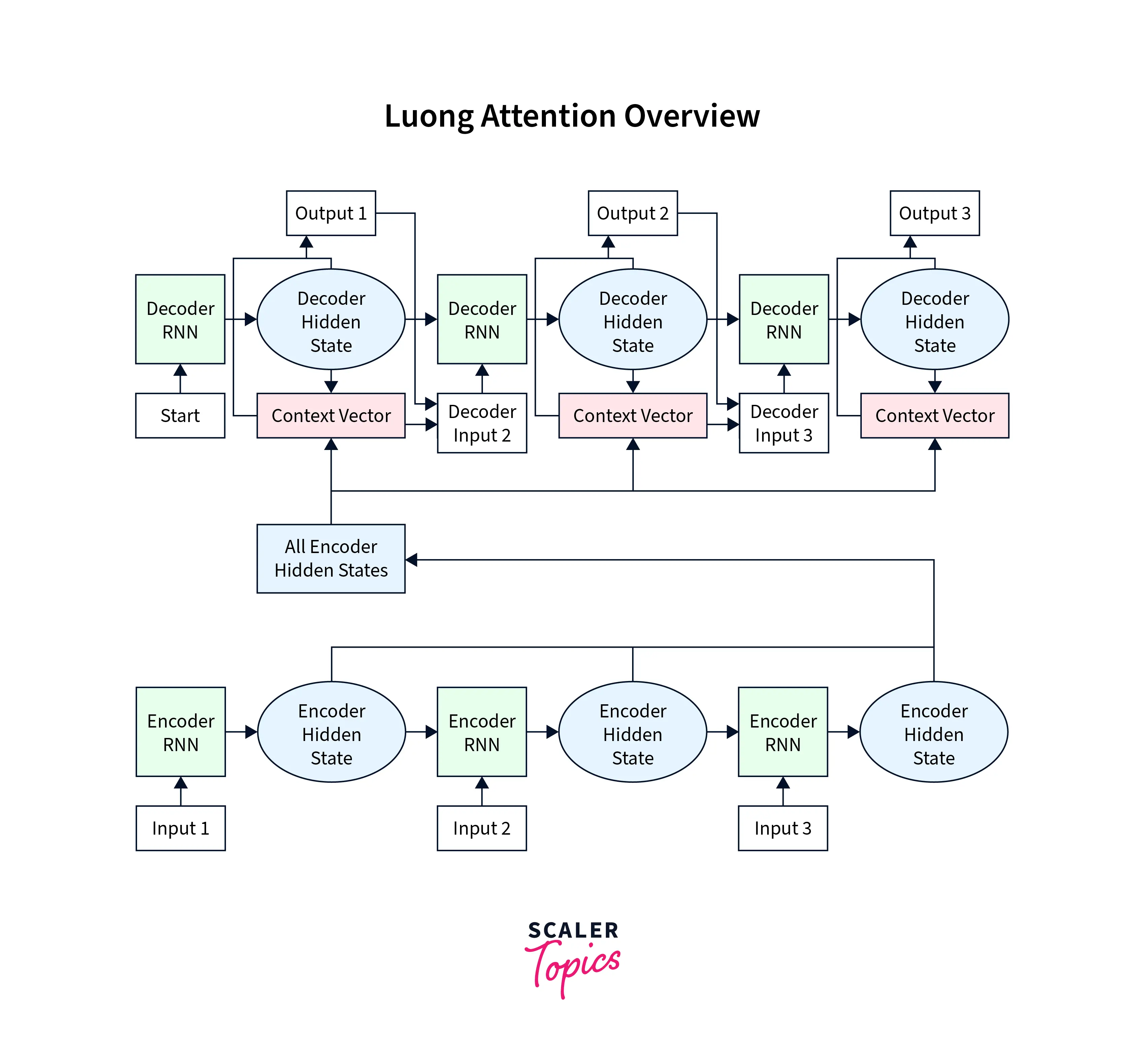
What are Transformers?
Even after introducing attention along with RNNs in seq2seq modeling, there's one caveat that remains - RNNs still sequentially process the data, that is, by taking one unit of the whole input sequence at a time. This sequential process makes training such architectures painfully slow and disallows us from leveraging the benefits of parallel computation.
The transformer architecture does away with the sequential process of the input units in a sequence. Instead, the architecture is so defined that the model can simultaneously ingest the whole input sequence. Instead, transformers rely primarily on attention and specifically work on something called "self-attention".
Self-attention is nothing but attention when it is calculated "among" the input units of a sequence rather than being calculated "between" an input and output sequence.
Overview of the Transformer Model
Let us dive into some architectural details of the transformer model:
Self-attention in transformers is calculated using what is called "Scaled Dot Product Attention". Scaled dot product attention is calculated using three matrices called the query, key, and value matrices denoted by Q, K, and V, respectively.
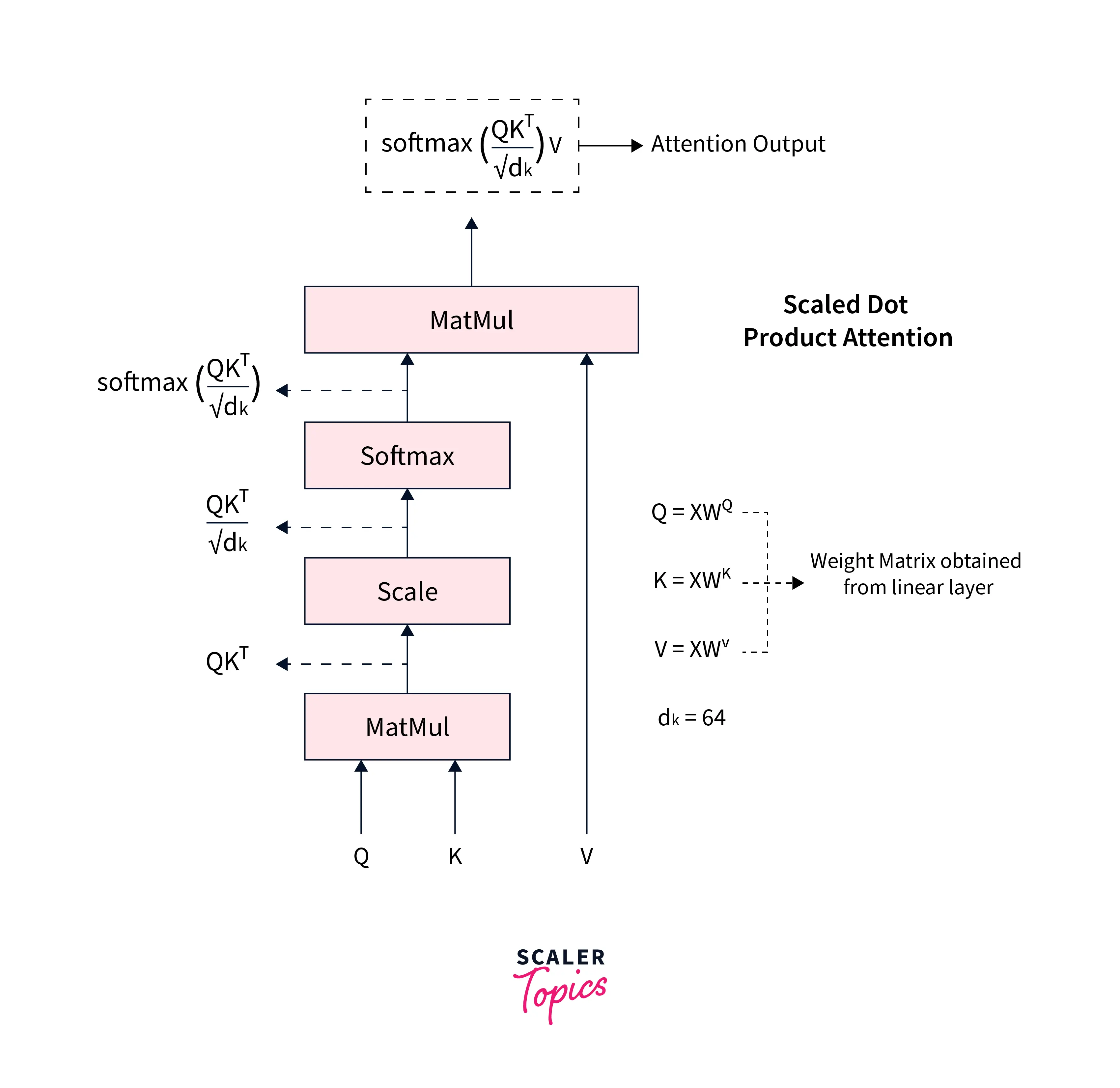
Here's how the attention is calculated:
On the result of the above equation, we multiply the value vector to get the attention as: Finally.
Building upon self-attention, transformers use multi-headed attention. Instead of calculating the attention scores once, they are calculated times with , , dimensioned vectors found after passing each of them from a Linear Layer.
These are now used to calculate the attention values from each attention head, which are then concatenated to produce a resultant vector.
The Multi-Headed Attention output is obtained by passing it through another linear layer.
The Encoder Side
Building upon the multi-headed attention, we will now briefly go over what the encoder side looks like:
It consists of two layers - the linear layer and the attention layer- just the multi-headed attention with 8 heads. The linear layer is a feed-forward neural network with one hidden layer, and the dimensions of the input and the output layer are 2048 and 512, respectively.
This is what the encoder side of the model looks like:
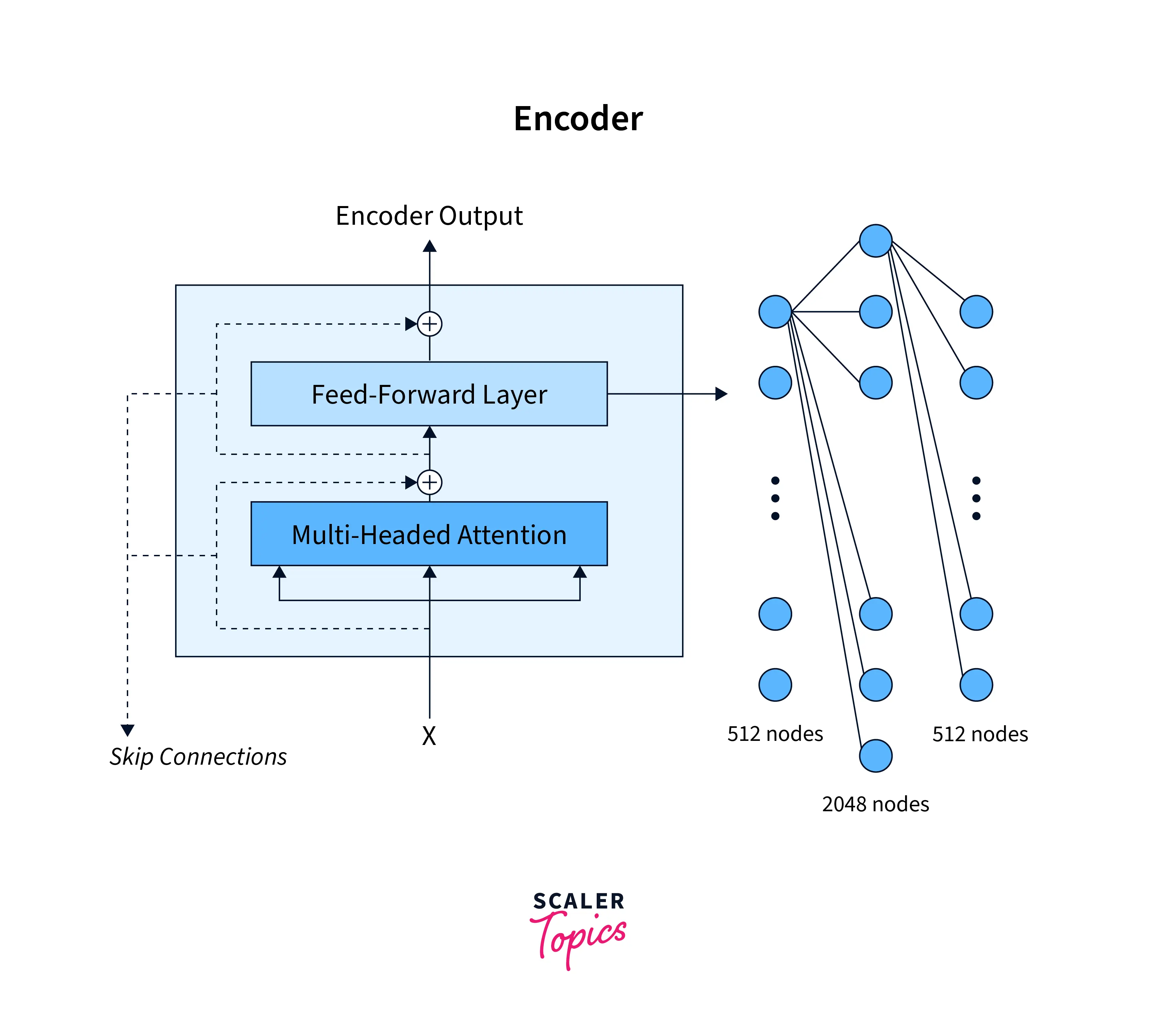
The original paper has a total of 6 such encoder blocks. The output of one encoder block is passed as the input to the next encoder block, and so on.
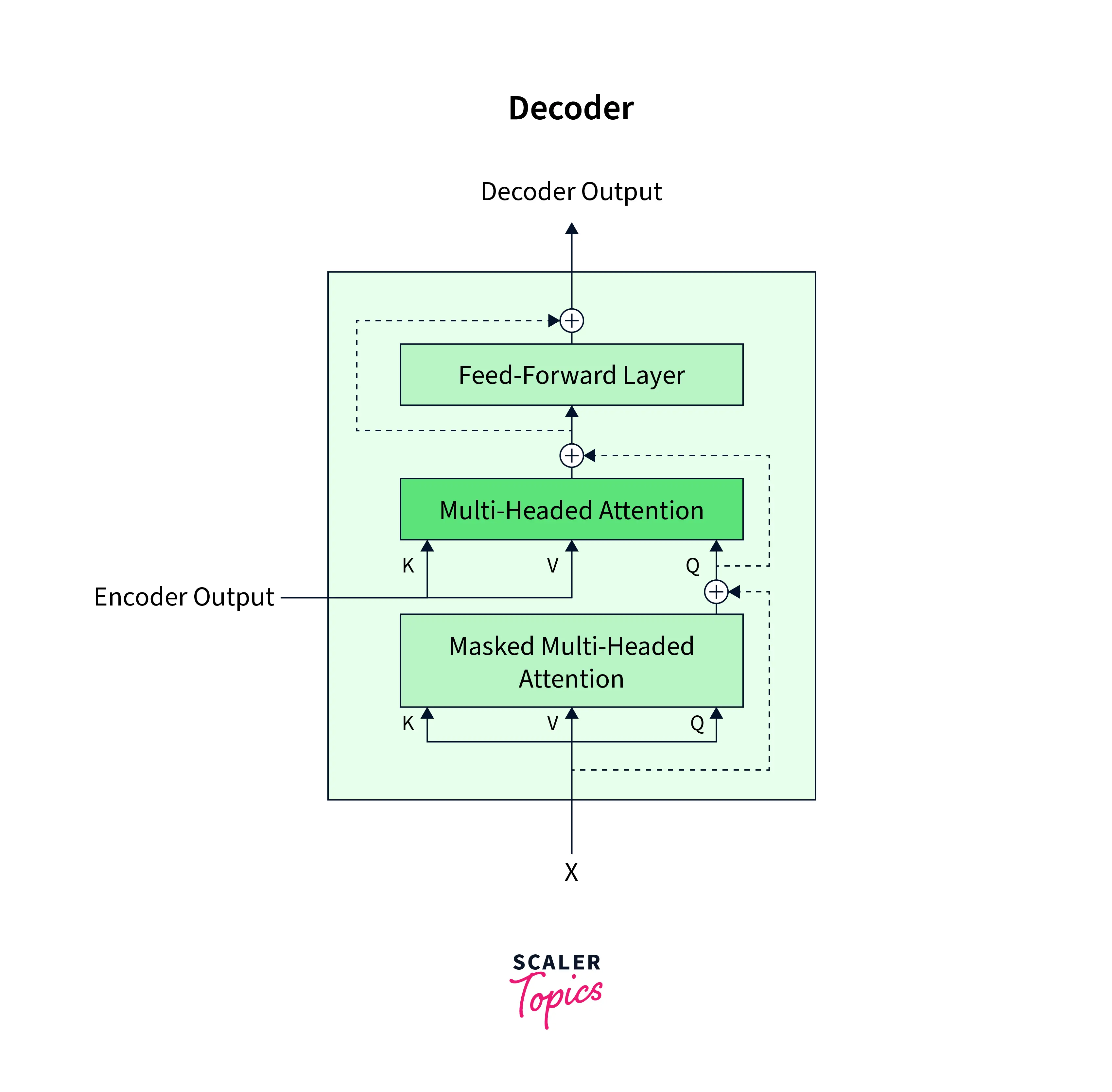
The Decoder Block
The Decoder block is very similar to the encoder block with an additional component called the masked multi-headed attention.
The two inputs that are fed to the decode are as follows:
-
The encoder output is taken as the input for multi-headed attention in the second layer.
-
the embeddings of the target sentence
Introduction to HuggingFace(HF) Transformers API
When talking about transformers and natural language processing in general, we surely cannot afford to miss hugging faces who are the pioneers in making them accessible and useful to a wide range of practitioners. They provide many pre-trained models and datasets for natural language processing with a super simple-to-use API that supports PyTorch, one of the most used Pythonic libraries for deep learning.
We will talk about their transformers API before building our text classification model.
We will use pip to install the hugging face transformers:
To download and use any of the pre-trained models in PyTorch on your given task, all it takes is three lines of code, like so:
Output:
As we can see, the output is produced according to the pre-trained model we used.
For separate tasks, easy-to-use classes are built in the transformers library that we can use in the following code; we use the AutoModelForSequenceClassification API to predict whether a pair of sentences are paraphrases of each other or not. Finally, we use the best base case model fine-tuned on the MRPC dataset, corresponding to our task.
Output:
Similar classes are available for other NLP tasks like question answering, text classification/sentiment analysis, etc.
To know more about their transformers API, refer to the official docs here.
Text Classification with Transformers in PyTorch
In this section, we will implement a PyTorch transformers example; specifically, we will build a text classification model leveraging the pre-trained model checkpoints from the hugging face transformers library.
Text classification is one of the most common NLP tasks in many applications like detecting spam mail, sentiment analysis, etc.
To build our text classification system, we will use three core libraries from the Hugging Face ecosystems: Datasets, Tokenizers, and Transformers.
Let us first pip install all three of them, like so:
Dataset
The datasets library provides various datasets for various tasks - we can download them from the hugging face hub. For our task, we will be using the emotions datasets using the load_dataset function, like so:
Output:
The emotions dataset contains tweets and their corresponding labels defining the emotion conveyed in the tweets.
Our dataset is a DatasetDict object, which behaves similarly to a Python dictionary, with each key corresponding to a different split.
Tokenizing the Data
Transformers provide a convenient AutoTokenizer class that lets us quickly load the tokenizer associated with any pre-trained model. For example, to build our text classification model, we will use the distill-BERT model, a variant of the BERT model. Let us download the pre-trained model checkpoint along with creating the tokenizer instance associated with that model, like so:
We will now use the tokenizer instance to tokenizer our whole dataset, like so:
Output:
As we can now see, the encoded dataset object has additional columns corresponding to the input ids and attention masks of the tweets in the dataset. These two columns are used (and expected) by the distillBERT model to predict the corresponding output.
Getting the Features
We will now use the last hidden state generated by the model when input is fed to it as the features to build a text classification model. This means that we will use the transformer model as a feature extractor. This is also why we will generate the last hidden states in the torch.no_grad mode, as we need the values of the hidden state vector and do not need to update the weights of the transformer model itself. Although we could choose to update the weights of the transformer itself, for now, we will just be building a classifier head on top of it using the hidden state vectors as the features (or inputs) to our classifier model, which will be a simple feed-forward neural network.
Let us first map the emotions_encoded object to get the hidden states as well, like so:
Output:
Creating the Feature Dataset
We will now use the hidden_state column to create our dataset using numpy and pandas, like so:
As we can see, the length of the hidden state vector is 768, and there are a total of 16k examples in the train split and 2k examples in the test split.
Let us create a dataframe out of it using pandas like so:
The Dataset Class
We will now create our custom PyTorch dataset class to load the dataframe objects, like so:
Custom PyTorch Model
After this, let us define a custom PyTorch model class to create a simple feed-forward neural network, like so:
We will also create dataloader objects for parallel batched loading of data examples, along with defining our optimizer and loss function like so:
Train and Test the Model
Let us now take all the components together to define a simple training loop for our model along with a helper function to check the accuracy, like so:
Output:
With this, we are done training a simple feed-forward neural network using the last hidden states extracted from the distillBERT model as feature inputs to our FFNN.
The low accuracy scores here are due to many reasons like the imbalance in the original dataset, using a simple feed-forward neural network, etc.
There are many other ways to leverage the transformers API in PyTorch to build NLP systems, like text classification, question answering, text summarization, etc.
Conclusion
With this, we are done building our text classification model based on state-of-the-art transformer models. Let us conclude with points that we studied in this article:
- We first revised the seq2seq modeling task and the RNN-based encoder-decoder architectures used to model this task.
- To build the ground for learning about the attention mechanism, we discussed the shortcomings of the RNN based seq2seq architectures.
- Then we learned about the attention mechanism and discussed the steps involved in two types of attention - the Luong Attention and Bahdanau Attention.
- After this, we learned about the key concepts of transformer models built primarily on top of the concept of attention, along with looking at the hugging face API for transformers.
- Finally, we learned about the PyTorch transformer and implemented a PyTorch transformer example leveraging the hugging face API to build a text classification system in NLP.