Text representation as embeddings in Pytorch
Overview
One of the aspects of Natural Language Processing is Representing text as vectors. As the Results of Deep Learning are directly dependent on the quality and quantity of data, we need ways to represent text data to vectors that can enhance the performance of our model. In this article, let's learn how to use PyTorch for converting text to vectors.
Introduction
Most Machine learning algorithms require text to be converted to numbers to process. The simple approach is assigning a word or letter to a random vector unique to that word/letter. This approach works, but there are better approaches than this one since though two or more text contains similar meaning, the vectors are different and random. The better way is to train a model representing the text/word to get the vector. These kinds of vectors are called embeddings. So, without further ado, Let's dive into details.
What is Embeddings?
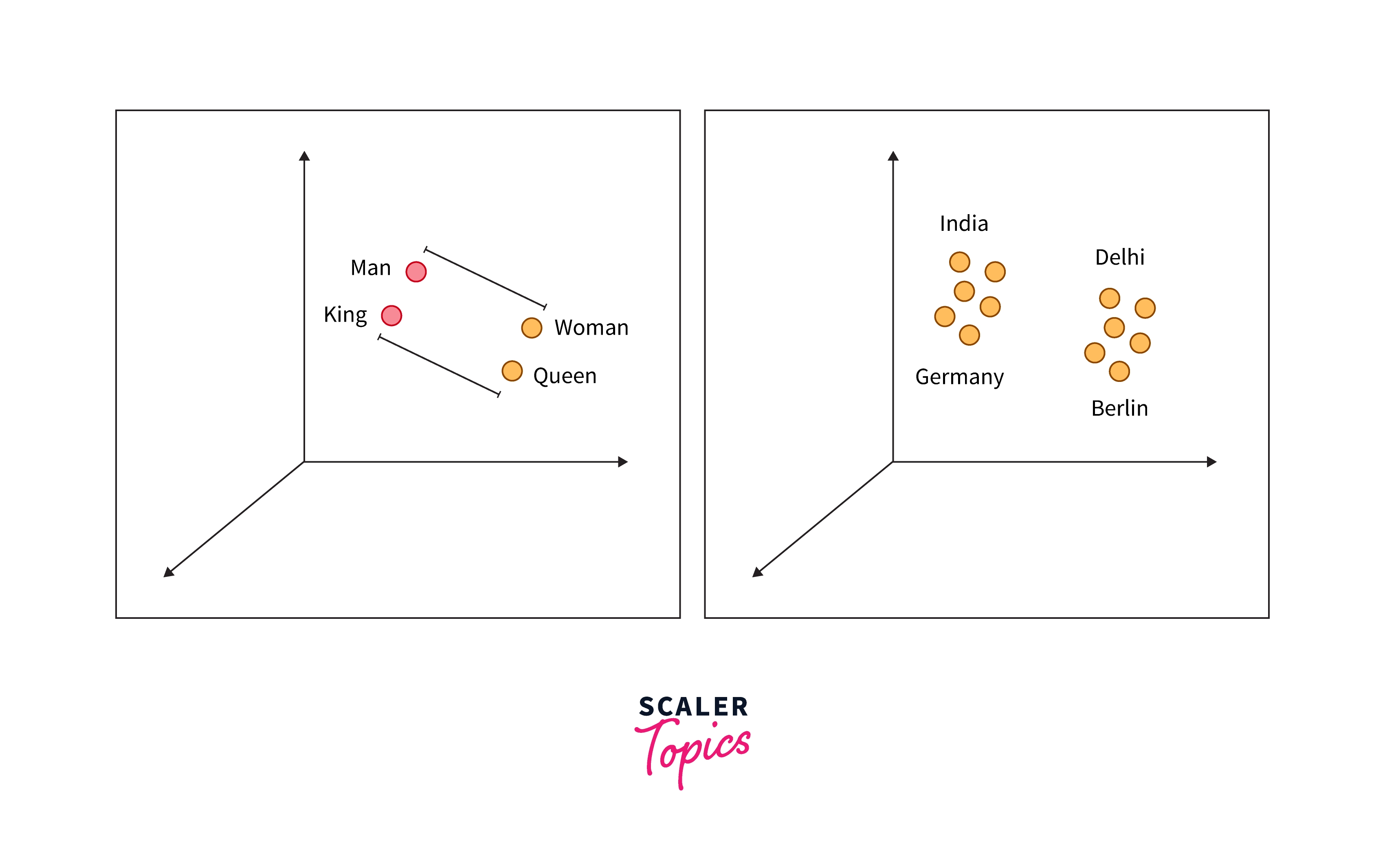
Embeddings are real-valued vectors used to carry the meaning of the text in a vector format such that the closer the two vectors in space, similar it is. An example of embedding is below. Note that the distance between the Man and Woman is almost the same as between the King and Queen. Also, the distances on the right graph have almost equal as they represent their capitals.
Vectors
Embedding vectors are n-dimensional vector that contains dense information about all the words. These vectors can be useful to map each word/sentence to vectors that can be used to train the model for any application.
How to Represent Text as Embeddings in PyTorch?
An embedding layer should be created based on the requirements of the problem statements/model. Next, The embeddings should be trained with data and labels that represent the similarity between texts and can understand the context. Then, the trained embedding weights can be used to generate the vectors for the new text set (Can be understood below figure). Finally, a set of techniques/PyTorch snippets can be used to complete our job. Let's dive in.

Using torch.nn.Embedding
Let's learn how to initialize vectors, load the data, and use the basic version of embedding.
Example: N-gram language modeling
The N-gram is language modeling is used when you have
Using Pre-trained Embeddings
Gensim provides pertained embeddings for the words.
PyTorch Embedding Bag Layer
Computes sums or means of ‘bags’ of embeddings without instantiating the intermediate embeddings.
Word2vec with Pytorch Embedding
Word2vec is a popular embedding model that has revolutionized the nlp. Each word is mapped to a vector.
Conclusion
Here are some takeaways from this article:-
- Text Embeddings are vectors containing dense text information.
- Use pre-trained embedding weights and fine-tune them accordingly to your text data.