Quantisation and Pruning
Overview
Model quantization and pruning are techniques that compress and accelerate deep learning models. Quantization involves reducing the precision of the weights and activations in a model, typically from 32-bit floating point values to 8-bit integers.
Pruning involves removing unnecessary weights or connections from a model. We can do this during training, fine-tuning, or after training the model.
Introduction
Deep learning models can be resource-intensive, requiring large amounts of memory and computational power to train and use for inference. This can make it difficult to deploy these models on resource-constrained devices such as smartphones, IoT devices, and edge devices with limited computational power and storage. To overcome this limitation, we can use model quantization and pruning to reduce these models' complexity and resource requirements.
Model quantization is a technique that reduces the precision of the model's parameters, typically from a 32-bit floating point to 8-bit integers. This can significantly reduce the memory and computational requirements of the model while still maintaining good performance.
On the other hand, model pruning is a technique that removes unimportant or redundant model parameters. This can also reduce the complexity and resource requirements of the model while still maintaining good performance.
What is Quantization?
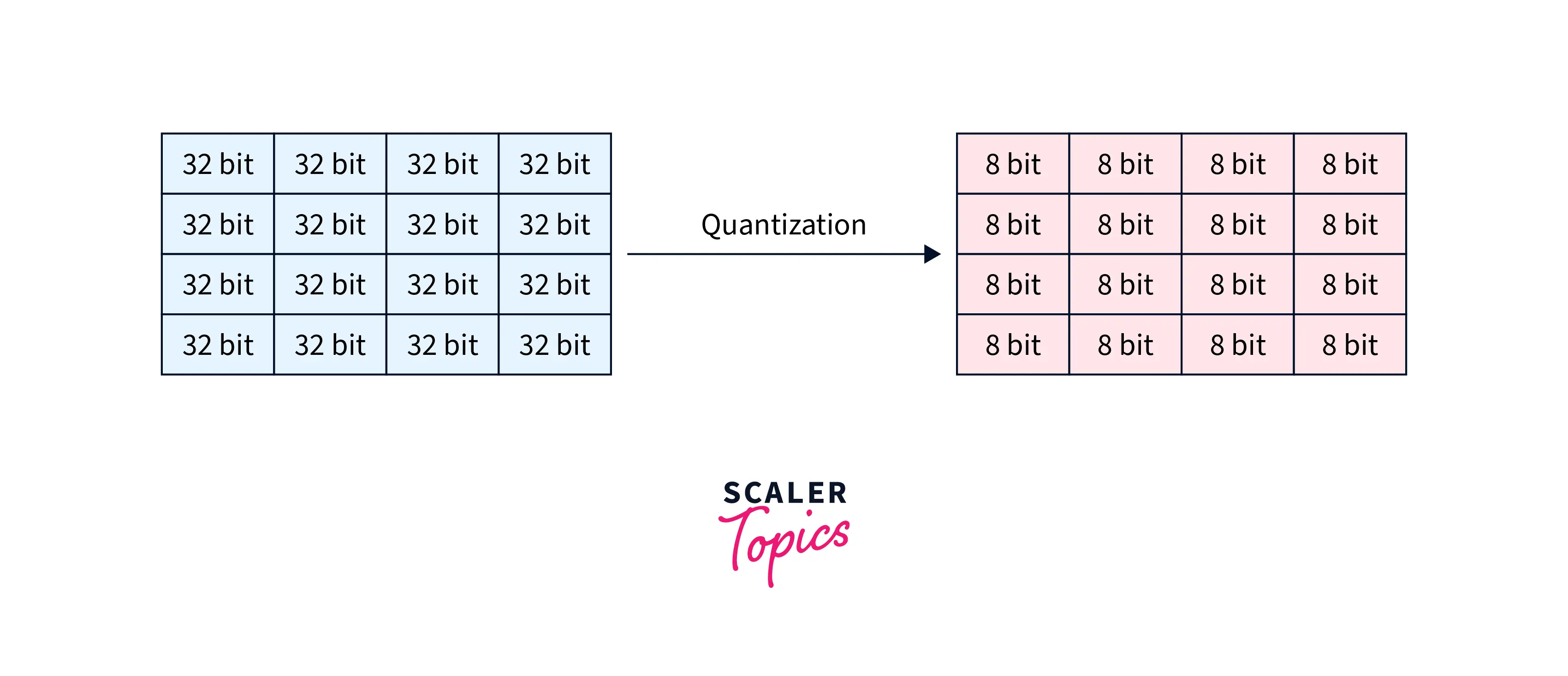
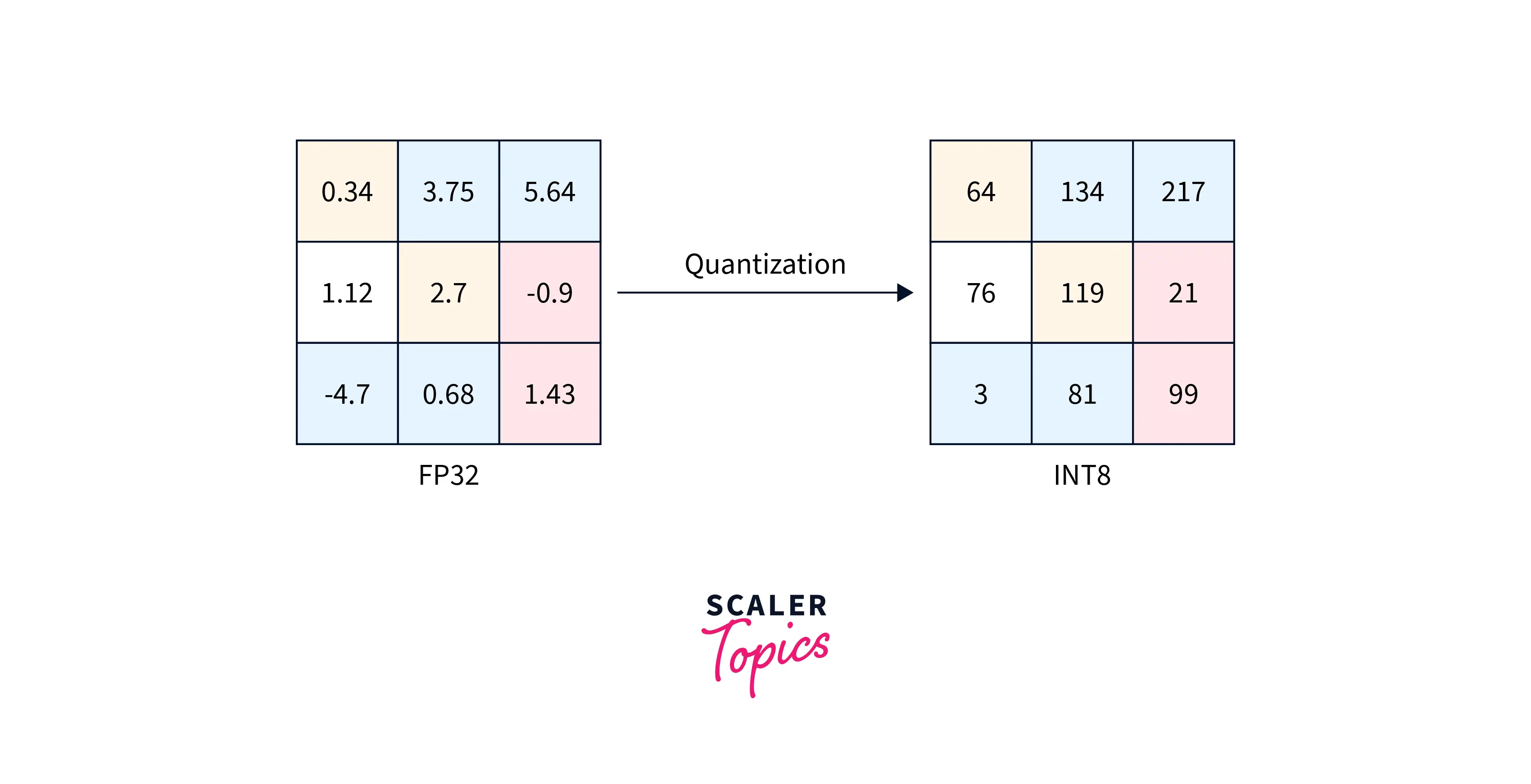
Model quantization is a technique for reducing the precision of the weights and activations of a model to reduce the memory required to store the model and the computational resources required to perform inference with the model. Quantizing a model typically involves converting weights and activations from a higher-precision data type, such as a 32-bit floating point, to a lower-precision data type, such as an 8-bit integer.
This can significantly reduce the size of the model and the amount of memory required to store and use, which can be useful for deploying the model on resource-constrained devices such as smartphones or Internet of Things (IoT) devices.
Model quantization can also improve the speed of model inference by allowing computations to be performed using lower-precision arithmetic, which can be faster than higher-precision arithmetic on some hardware.
Why Quantization?
Model quantization is important because it allows models to be deployed on resource-constrained devices such as smartphones or Internet of Things (IoT) devices. These devices often need more memory and computational resources and may need help to handle the large model sizes and computational requirements of non-quantized models.
By reducing the precision of the model's weights and activations, model quantization can significantly reduce the model size and the amount of memory required to store and use the model, making it possible to deploy the model on these devices.
In addition to enabling model deployment on resource-constrained devices, model quantization can also improve the speed of model inference. By using lower-precision arithmetic, We can perform computations faster on some hardware. This can be particularly useful for real-time applications where the model needs to make predictions quickly.
How to Quantize?
Quantization in deep learning reduce the precision of a model's weights and activations from floating-point to lower bit-width representations, typically 8-bit or lower. The goal is to reduce the memory and computational requirements of the model while retaining its accuracy.
Here are the steps to quantize a deep learning model:
- Train the model with floating-point weights and activations.
- Evaluate the accuracy of the model on a validation dataset.
- Convert the model's weights and activations to lower bit-width representations.
- Fine-tune the quantized model to compensate for the loss of precision.
- Evaluate the accuracy of the quantized model on the validation dataset.
- Repeat steps 3-5 until the desired accuracy is achieved or until there is no further improvement.
It is important to note that quantization may affect the accuracy of the model, and some models are more robust to quantization than others. Fine-tuning the quantized model can help to mitigate these effects.
Post Training Quantization
Post-training quantization is a process of converting a pre-trained floating-point model to a lower-precision integer representation, typically 8-bit or lower, without retraining the model. This can be done by calibrating the quantization range for each layer based on the actual activation values during inference. The quantized model is then fine-tuned to compensate for any loss in accuracy. This method is simpler and faster than quantization-aware training but may result in lower accuracy compared to the original floating-point model.
There are different methods for post-training quantization, including weight quantization, integer quantization, and float 16 quantization.
Weight Quantization:
Weight quantization involves reducing the precision of the model's weights from a higher-precision data type, such as a 32-bit floating point, to a lower-precision data type, such as an 8-bit integer. This can be done by dividing the weights by a scaling factor and rounding them to the nearest integer value.
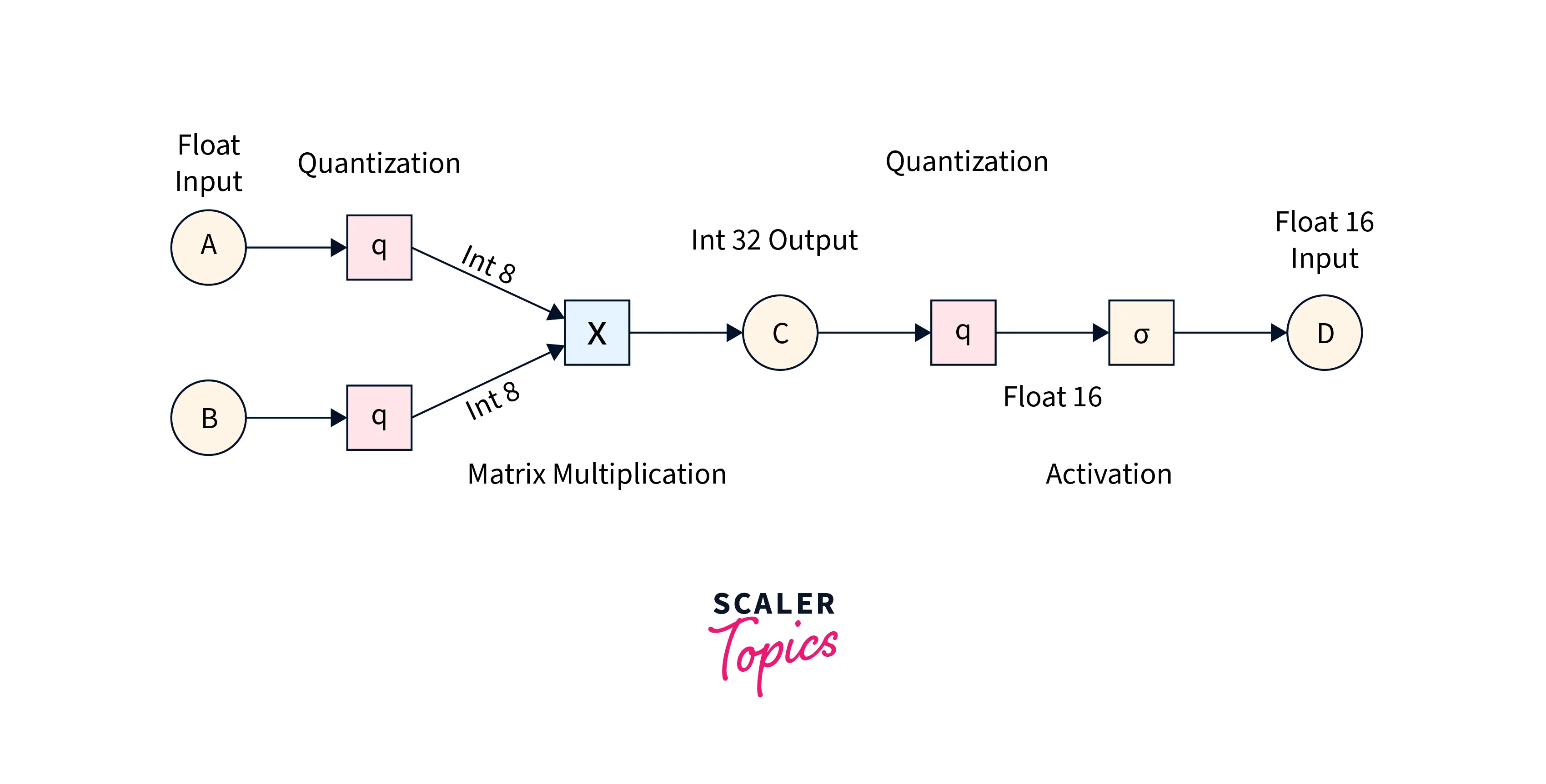
Integer Quantization:
Integer quantization involves converting the model's weights and activations from floating points to integer data types. We can do this by multiplying the weights and activations by a scaling factor and rounding them to the nearest integer value.
Float 16 Quantization:
Float 16 quantization involves reducing the precision of the model's weights and activations from a 32-bit floating point to a 16-bit floating point. We can do this by casting the data to the float16 data type.
Quantization Aware Training
Quantization-aware training is a technique used to improve the performance of a model after quantization. It involves training the model with quantization in mind to be more robust to quantization at inference time. This is done by adding fake model quantization ops during training, which simulate the effects of quantization on the model's weights and activations.
Training the model with these fake quantization ops, the model can learn to produce accurate results despite the quantization. This can help to mitigate the performance loss caused by quantization and improve the model's performance.
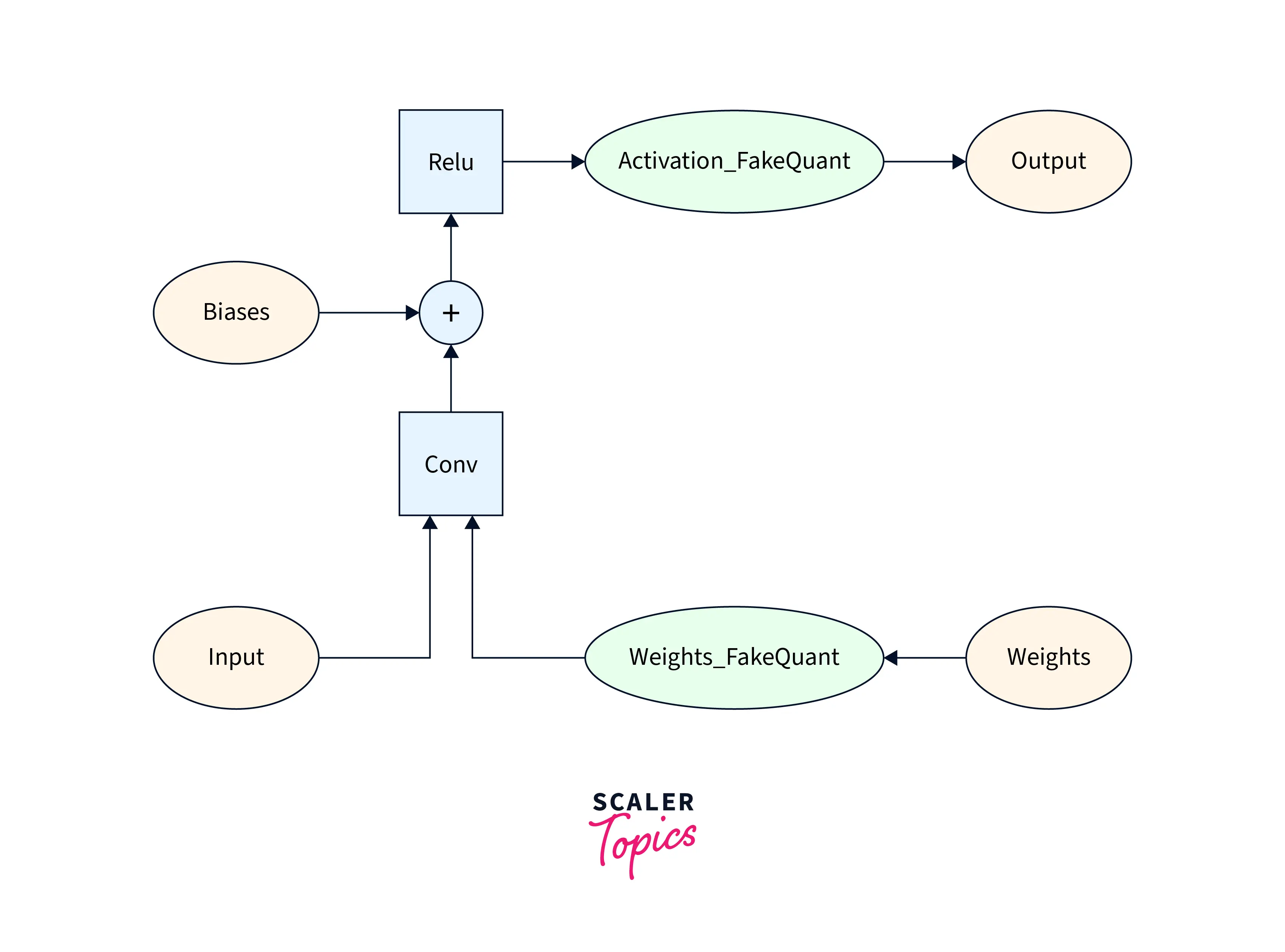
Here is an example of how to perform quantization-aware training in TensorFlow
This code adds fake quantization ops to the model during training, allowing the model to learn to produce accurate results despite the quantization. Once the model is trained, We can convert it to real quantization ops for inference.
What is Pruning?
Model pruning is a technique for reducing the complexity of a machine learning model by removing unnecessary weights or connections from the model. We can use model pruning to reduce a model's size, making it faster to train and use for inference. It can also improve the generalization ability of the model by reducing overfitting.
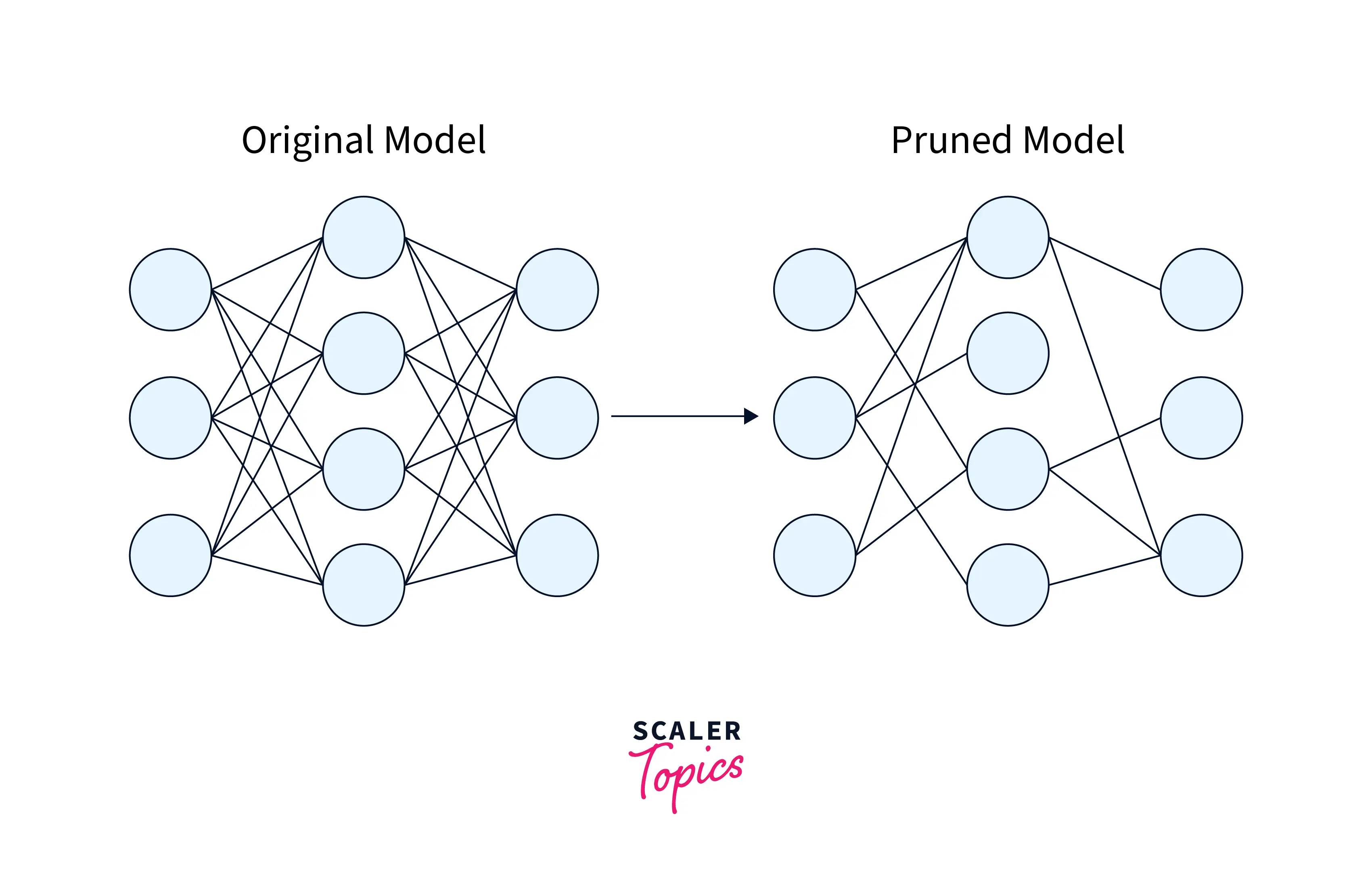
There are several ways to prune a model, including:
- Weight pruning:
Weight pruning involves removing individual weights from the model that are close to zero or are not contributing significantly to the model's output. - Unit pruning:
Unit pruning involves removing entire units (neurons or groups of neurons) from the model if they are not contributing significantly to the model's output. - Structural pruning:
Structural pruning involves removing entire layers or connections from the model if they do not contribute significantly to its output.
Model pruning can be performed during training by setting a threshold for the weights or units to be removed and updating the model to remove them as they fall below the threshold. It can also be performed after training by evaluating the importance of the weights or units and removing those that are less important.
Why Prune Deep Learning Models?
There are several reasons to prune a deep learning model:
- Model size reduction:
Pruning can significantly reduce the size of a deep learning model, making it faster to train and use for inference. This can be especially useful for deploying the model on resource-constrained devices such as smartphones or Internet of Things (IoT) devices, which may have limited memory and computational resources. - Improved speed:
Pruning can also improve the speed of model inference by removing unnecessary weights and connections from the model. This can be particularly useful for real-time applications where the model needs to make predictions quickly. - Improved generalization:
Pruning can also improve the model's generalization ability by reducing overfitting. By removing unnecessary weights and connections, the model is less likely to memorize the training data and is more likely to generalize to unseen data.
Overall, model pruning is a useful technique for improving the efficiency and effectiveness of deep learning models.
Types
There are several types of model pruning, each with its approach to reducing a model's complexity and resource requirements.
There are two main types of model pruning:
Pre-pruning
Pre-pruning involves removing unnecessary weights or connections from the model before training begins. We can do this by setting a threshold for the weights or connections to be removed and removing them before training begins.
Pre-pruning can be useful for reducing the model's complexity before training, making training faster and more efficient. However, it can also limit the model's learning ability and may not result in the most accurate model.
Post-pruning
Post-pruning involves removing unnecessary weights or connections from the model after completing training. We can do this by evaluating the importance of the weights or connections and removing those that are less important.
Post-pruning can be more effective at reducing the complexity of the model while preserving its accuracy. However, it requires training the model to completion before model pruning, which can be more time-consuming.
Conclusion
- Model quantization is a technique for reducing the precision of the weights and activations of a model to reduce the model's size and the computational resources required to perform inference with the model.
- Quantization can enable deploying deep learning models on resource-constrained devices and improve the speed of model inference.
- Model pruning is a technique for reducing the complexity of a deep learning model by removing unnecessary weights or connections from the model.
- Pruning can reduce the size of a model, improve the speed of inference, and improve the model's generalization ability by reducing overfitting.