Integrating Hadoop with R
Overview
Integrating Hadoop with R involves merging the power of Hadoop's distributed data processing capabilities with R's advanced analytics and data manipulation functions. This synergy allows data scientists and analysts to efficiently analyze vast datasets stored in Hadoop's distributed file system (HDFS) using R's familiar interface. By leveraging packages like "rhipe" or "rhdfs," users can seamlessly access and process big data in R, making it easier to perform complex data analytics, machine learning, and statistical modeling on large-scale datasets. This integration enhances the scalability and versatility of data analysis workflows, making it a valuable tool for handling big data challenges.
What is Hadoop?
Hadoop is a powerful open-source framework designed for distributed storage and processing of vast amounts of data. Originally developed by Apache Software Foundation, it has become a cornerstone of big data technology. Hadoop consists of two core components: Hadoop Distributed File System (HDFS) and the Hadoop MapReduce programming model. HDFS is responsible for storing data across a cluster of commodity hardware, breaking it into smaller blocks and replicating them for fault tolerance. This distributed storage system allows Hadoop to handle data at a massive scale.
What is R?
RR is a powerful and open-source programming language and environment widely used for statistical computing, data analysis, and graphics. Developed in the early 1990s, R has since gained immense popularity among statisticians, data scientists, and analysts due to its versatility and extensive library of packages.R offers an array of statistical and graphical techniques, making it a go-to tool for tasks ranging from data manipulation and visualization to complex statistical modeling and machine learning. Users can perform data cleansing, transformation, and exploratory data analysis with ease. R's graphical capabilities allow for the creation of high-quality plots, charts, and graphs, facilitating data visualization and presentation.
Why Integrate R with Hadoop?
Integrating R with Hadoop offers several advantages, primarily because it allows data scientists and analysts to harness the combined power of R's advanced analytics and Hadoop's distributed data processing capabilities. Here are some reasons why integrating R with Hadoop is beneficial:
- Scalability: Hadoop is designed to handle massive volumes of data across distributed clusters. By integrating R with Hadoop, you can leverage the scalability of Hadoop's distributed file system (HDFS) to process and analyze large datasets efficiently. R alone may struggle with big data, but Hadoop can manage it effectively.
- Parallel Processing: Hadoop's MapReduce framework enables parallel processing of data across multiple nodes. Integrating R with Hadoop allows you to distribute R computations across these nodes, significantly speeding up data analysis tasks. This parallelization is especially critical for big data analytics.
- Data Variety: Hadoop can store and manage structured and unstructured data from various sources, such as log files, social media, and sensor data. Integrating R with Hadoop enables you to analyze and extract insights from diverse data types using R's powerful analytics tools.
- Cost-Efficiency: Hadoop is known for its cost-effective storage and processing of large datasets. By utilizing Hadoop's distributed storage and computational resources, organizations can reduce infrastructure costs while benefiting from R's analytics capabilities.
R Hadoop
The rmr package The "rmr" package, short for "R MapReduce," is a set of R packages that enable the integration of R with the Hadoop MapReduce framework. This package is part of the "RHIPE" (R and Hadoop Integrated Programming Environment) project and provides a bridge between R and Hadoop, allowing data scientists and analysts to perform distributed data processing and analysis using R.
Here are some key features and components of the "rmr" package:
- MapReduce Framework: The "rmr" package leverages the MapReduce programming model, which is at the core of Hadoop's distributed data processing capabilities. It allows users to define custom Map and Reduce functions in R to process data in parallel across a Hadoop cluster.
- Data Manipulation: "rmr" provides functions for data manipulation, transformation, and filtering, which can be applied to data stored in Hadoop's distributed file system (HDFS) or other data sources.
- Integration with R: Users can write R code for both the mapping and reducing phases of MapReduce jobs, making it easier to work with complex data analysis and statistical tasks using R's familiar syntax.
The rhbase package This package provides basic connectivity to the HBASE distributed database, using the Thrift server. R programmers can browse, read, write, and modify tables stored in HBASE from within R.
- Connectivity: The "rhbase" package enables R programmers to establish connections to an HBase instance through the Thrift server. This allows R to interact with and manipulate data stored in HBase tables.
- Data Operations: With "rhbase," R users can perform various data operations on HBase tables, including reading data, writing data, modifying records, and browsing table structures.
- Single-Node Installation: The package is typically installed on the node that serves as the R client. This means that you don't need to install it on every node in the Hadoop cluster; you only need it where you intend to run R scripts that interact with HBase.
The rhdfs package The "rhdfs" package is an R package that facilitates the integration of R with the Hadoop Distributed File System (HDFS). HDFS is the primary storage system used in Hadoop clusters, and it's designed to store and manage very large datasets across distributed computing nodes. The "rhdfs" package allows R users to interact with HDFS, read and write data, and perform various file operations within an R environment.
Here are some key features and functionalities of the "rhdfs" package:
- HDFS Connectivity: "rhdfs" provides functions to establish connections to HDFS instances, enabling R to communicate with and access data stored in HDFS.
- File Operations: Users can perform standard file operations like reading, writing, deleting, moving, and listing files and directories within HDFS using R functions provided by the package.
- Data Import/Export: The package facilitates the seamless import and export of data between R and HDFS. This is particularly useful when working with large datasets that are stored in HDFS.

R with Hadoop Streaming
R with Hadoop Streaming is a technique that allows you to integrate the R programming language with the Hadoop ecosystem using Hadoop's streaming API. This approach enables you to leverage the distributed data processing capabilities of Hadoop while writing your data processing logic in R. Here's how it works:
- Hadoop Streaming: Hadoop Streaming is a utility that comes with Hadoop, allowing you to use any executable program as a mapper and reducer in a MapReduce job. Instead of writing Java code, you can use scripts or executable programs in languages like Python, Perl, or R to perform the mapping and reducing tasks.
- R as a Mapper/Reducer: To use R with Hadoop Streaming, you write R scripts that serve as the mapper and/or reducer functions. These scripts read input data from standard input (stdin), process it using R code, and then emit output to standard output (stdout). You can use command-line arguments to pass parameters to your R script.
- Data Distribution: Hadoop takes care of distributing the input data across the cluster and managing the parallel execution of your R scripts on different nodes. Each mapper processes a portion of the data independently and produces intermediate key-value pairs.
- Shuffling and Reducing: The intermediate key-value pairs are sorted and shuffled, and then they are passed to the reducer (if specified) to aggregate or further process the data. You can also use R scripts as reducers in this step.
- Output: The final results are written to HDFS or another storage location, making them available for further analysis or use.
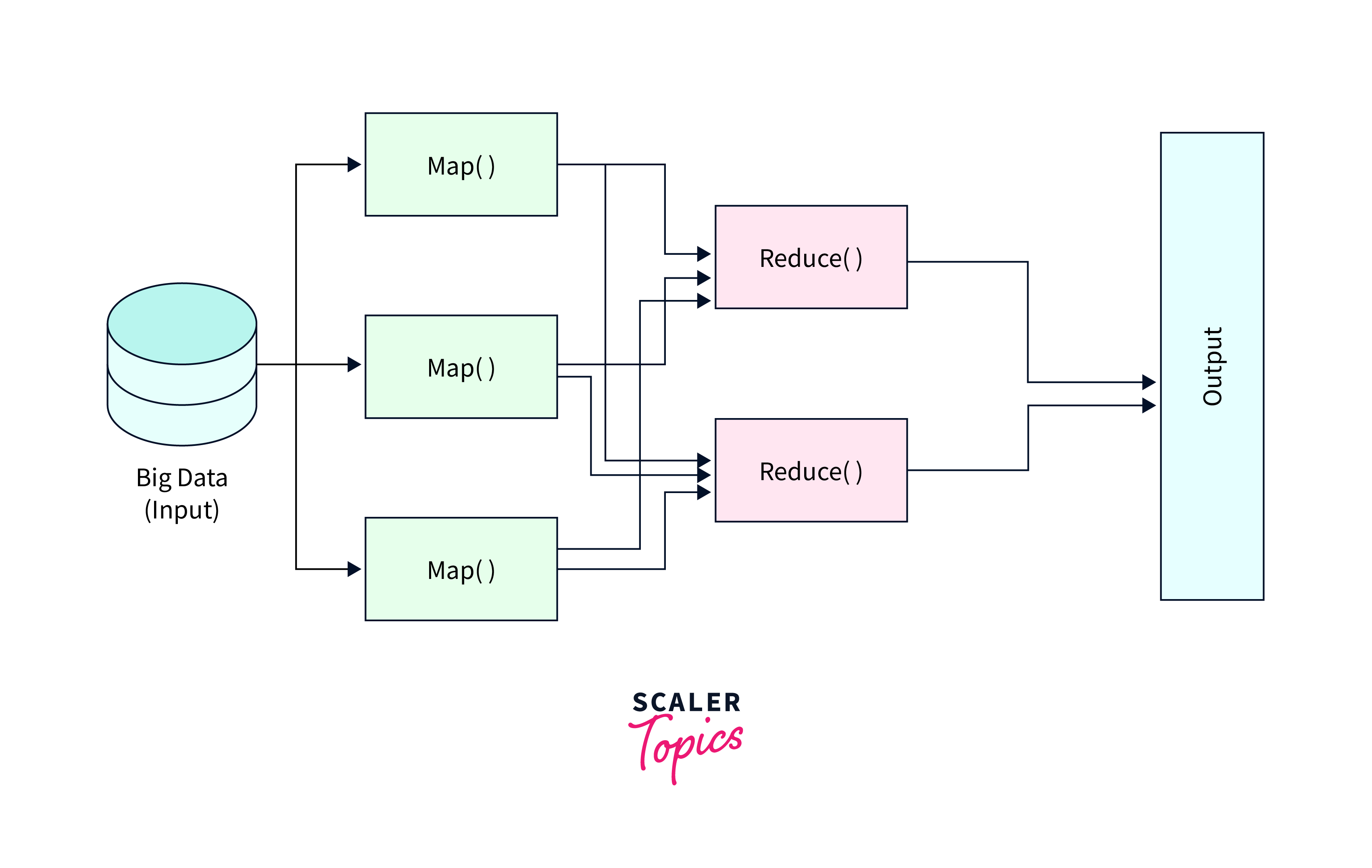
Processing Big Data with MapReduce
Processing big data with MapReduce in R involves leveraging the MapReduce programming model to analyze and manipulate large datasets using the R programming language. MapReduce is a distributed data processing framework commonly associated with Hadoop, but there are R packages and tools available that enable you to apply MapReduce principles within an R environment.
- Install R Packages: To get started, you'll need to install R packages that provide MapReduce functionality. Two popular R packages for this purpose are "rmr2" and "rhipe." "rmr2" is designed for use with Hadoop MapReduce, while "rhipe" works with both Hadoop and Rhipe (R and Hadoop Integrated Programming Environment).
- Set Up Your Hadoop Cluster: Ensure that you have access to a Hadoop cluster or Hadoop distribution. You will need a running Hadoop cluster to execute MapReduce jobs.
- Write Map and Reduce Functions in R: With the R packages installed, you can write your custom Map and Reduce functions in R. These functions define how your data will be processed. In MapReduce, the Map function processes input data and emits key-value pairs, and the Reduce function aggregates and processes these pairs.
RHIVE
Let us read about the properties/ characteristics of rhive in details below:
- Hive Integration: RHIVE connects R with Hive, enabling R users to send HiveQL queries to Hive from within their R scripts. HiveQL is similar to SQL and allows you to query and manipulate data stored in Hive tables.
- Data Analysis: RHIVE is particularly useful for data analysis tasks where you need to work with large datasets stored in Hadoop's distributed file system. You can use R's statistical and visualization packages in combination with Hive's data processing capabilities.
- Query Execution: With RHIVE, you can execute HiveQL queries and retrieve the results directly into R data frames. This allows you to work with the queried data using R's familiar syntax.
- Parallel Processing: Hive itself can perform distributed query processing across a Hadoop cluster. When you use RHIVE, you can leverage Hive's parallelism to process data in parallel, improving performance for large-scale data analysis.
RHIPE
In the era of big data, the integration of data analysis tools with distributed computing frameworks like Hadoop has become essential for handling vast datasets efficiently. One such integration tool is RHIPE (R and Hadoop Integrated Programming Environment), a powerful package that bridges the gap between the R programming language and the Hadoop ecosystem. In this 600-word exploration, we delve into the world of RHIPE, its key features, and how it simplifies the process of conducting data analysis on large-scale distributed data.
RHIPE's Key Features:
RHIPE facilitates this fusion by offering several key features:
- MapReduce Integration: RHIPE allows R users to write MapReduce programs in R, enabling them to leverage the parallel processing capabilities of Hadoop. This integration is particularly valuable when dealing with large-scale data analysis tasks.
- Data Transfer: RHIPE streamlines data transfer between R and Hadoop, making it seamless for users to move data between the two environments. It supports the import and export of data frames and other R objects to and from Hadoop's distributed file system (HDFS).
- High-Level Abstraction: One of RHIPE's strengths is its high-level programming interface. It abstracts many of the complexities of Hadoop MapReduce programming, allowing R users to focus on their data analysis tasks rather than the intricacies of distributed computing.
- Efficient Computation: RHIPE optimizes the execution of R code within Hadoop MapReduce jobs, enhancing the overall efficiency of data processing. This optimization ensures that computations are performed as efficiently as possible across distributed clusters.
ORCH
ORCH, the Hadoop R Connector, is a collection of R packages that offer a range of features for working with data in the Hadoop ecosystem, particularly with Hive and HDFS. ORCH aims to provide seamless integration between R, the Hadoop distributed computing infrastructure, and Oracle database tables. Here's a breakdown of its key features:
- Data Interfaces: ORCH offers various interfaces to interact with data stored in Hive tables. Hive is a data warehousing and SQL-like query language tool in the Hadoop ecosystem. These interfaces allow R users to query, retrieve, and manipulate data in Hive tables directly from their R environment.
- Hadoop Integration: ORCH is designed to work seamlessly with Apache Hadoop, enabling R users to leverage the distributed computing capabilities of Hadoop for data processing tasks. This integration allows you to process large-scale datasets efficiently using Hadoop's parallel processing.
- Local R Environment: ORCH provides a bridge between R and Hadoop, allowing R scripts to be executed as MapReduce jobs on the Hadoop cluster. This means you can write R code to process data in HDFS using Hadoop's distributed computing resources while staying within the familiar R environment.
IBM’s BigR
IBM's BigR is an open-source R package that allows users to analyze and explore big data stored in IBM BigInsights and Apache Spark clusters using the familiar R syntax and paradigm. It provides a number of features, including:
- Ease of use: BigR hides the complexities of the underlying Hadoop/MapReduce framework, making it easy for R users to get started with big data analytics.
- Performance: BigR transparently parallelizes R functions to run on the data, resulting in significant performance improvements for large datasets.
- Flexibility: BigR can be used to run almost any R code, including most packages available on open-source repositories such as CRAN.
Conclusion
- Scalability: Hadoop's distributed architecture allows for the efficient processing of massive datasets, enabling R to analyze and manipulate big data at scale.
- Parallel Processing: Hadoop's parallelism and distributed computing capabilities are leveraged to speed up data analysis and reduce processing times.
- Custom Analytics: R provides a rich set of statistical and analytical packages, allowing for customized data analytics and modeling within Hadoop.