RabbitMQ vs Kafka: What’s the Difference?
The RabbitMQ is defined as an open-source distributed message broker. With RabbitMQ, efficient delivery of data records is achieved for complex routing scenarios. It was built around the known AMQP protocol. It works best with the existing technologies, along with collaborating its ts capabilities via plug-ins that could easily be enabled on the server. During any network or server failure conditions, RabbitMQ brokers could be easily distributed and configured.
Apache Kafka can be defined as an open-source distributed event streaming platform. Kafka is known for it is flexible routing, as well as its ability to facilitate raw throughput. Kafka is the concept around distributed append-only log messaging where the data records are pushed in the log. This log persists to disk, where clients can select from where they want to start reading the log. Kafka clusters are distributed as well as could be clustered over various servers for offering high availability.
What is Kafka?
When it comes to log messaging systems, you might have heard of Apache Kafka. We describe it as an open-source distributed and event-streaming platform. Kafka was developed by LinkedIn to solve their issue of tracking website activity. For building real-time data pipelines as well as streaming applications, Kafka was built. Kafka is considered as often considered the dominant real-time streaming as well as queuing technology for organizations working with large-scale, real-time, event-driven applications.
Some widely popular characteristics offered by Kafka:
- Scalability For offering prominent horizontal scalability, Kafka has a distributed architecture.
- Flexibility: With its spontaneous and useful APIs, Kafka offers flexibility which is creatively designed to interface with multiple systems.
- Community: Kafka has built a strong community around its production which is not only contributing to it but has a rich ecosystem.
- Performance: Provides competitive high performance by its ability to process millions of data records per second with its limited resources.
- Strong reputation: Implemented in prominent organizations like Netflix, Twitter, Spotify, Pinterest, Airbnb, and Uber, Kafka holds a strong reputation as well.
- Availability: Offers high availability via its data replication and load balancing features.
The below illustration shows how Kafka could be used across industries.
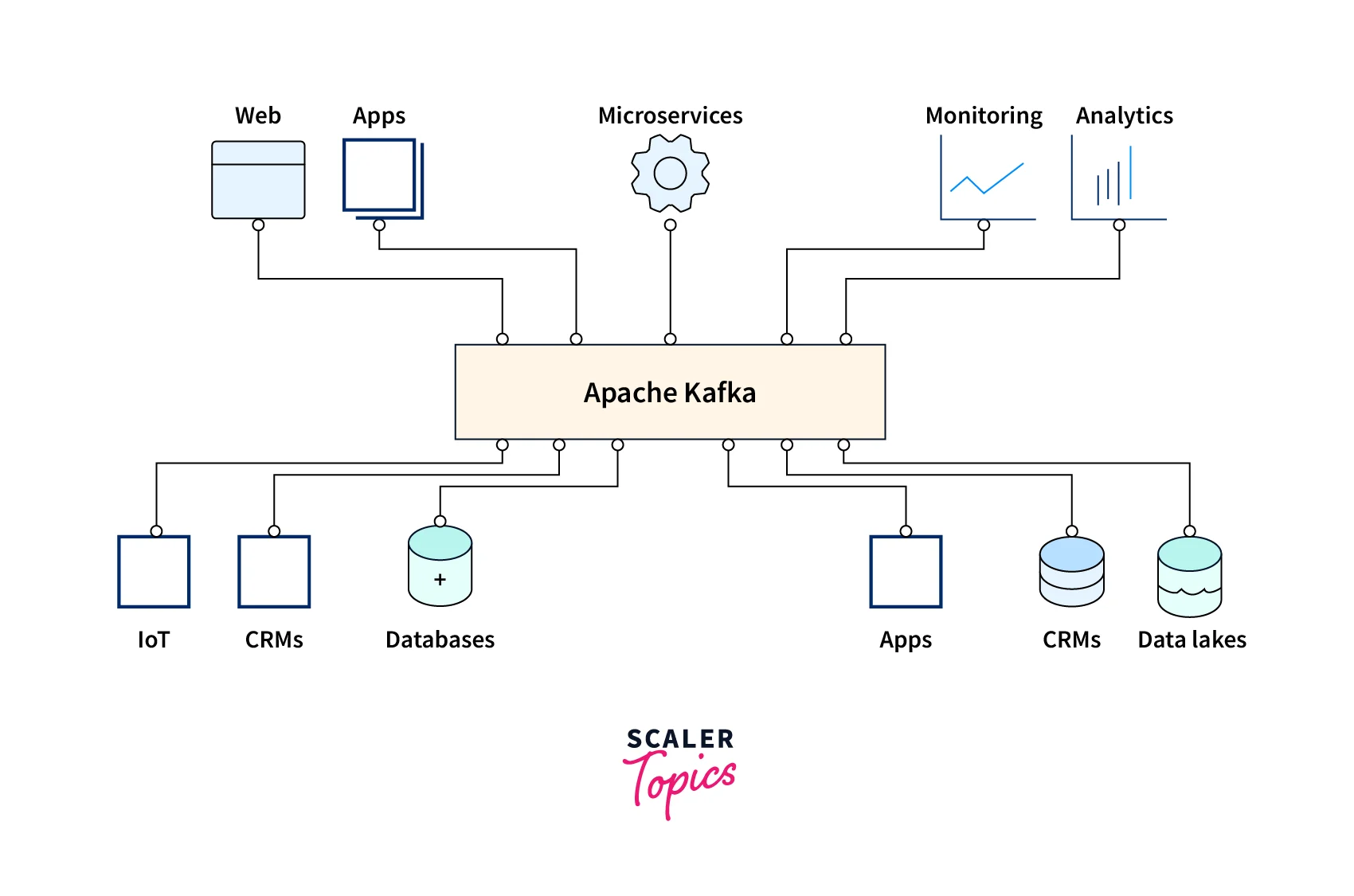
Scenarios where Apache Kafka could be implemented:
- For systems where multi-stage data pipelines are created for the event stream, along with generating real-time graphs of data offering real-time monitoring of traffic in the data pipelines.
- When there is a bug or overloading scenario or even if the consumer is not ready to consume the data records, Users can use Kafka to directly replay the data records. All the messages are in place until the consumer is in a ready state, you can replay the data records.
- If you are looking for faster consumption of messages, Kafka could be utilized as the go-to event-handling platform.
- Application that processes huge amounts of data records needs messaging offering High throughput(100K/sec events or more, then Kafka could be implemented.
What is RabbitMQ?
Released in 2007, RabbitMQ can be defined as an open-source distributed message broker. Widely popular as a “mature” platform, it is often linked with various “conventional” messaging platforms, like IBM MQ and Microsoft Message Queue. RabbitMQ is popular among developers for its flexibility. It effortlessly handles any complicated routing scenarios it backing various messaging protocols, such as STOMP, AMQP, and MQTT. RabbitMQ offers high availability as well as high scalability for its users where they can deploy the RabbitMQ with a distributed configuration.
Many developers are using RabbitMQ where they can simply find potential clients, plug-ins, guides, etc. Organizations such as T-Mobile, Trivago, Accenture, Alibaba Travel, and Robinhood, are all using RabbitMQ.
The below representation shows how RabbitMQ works.
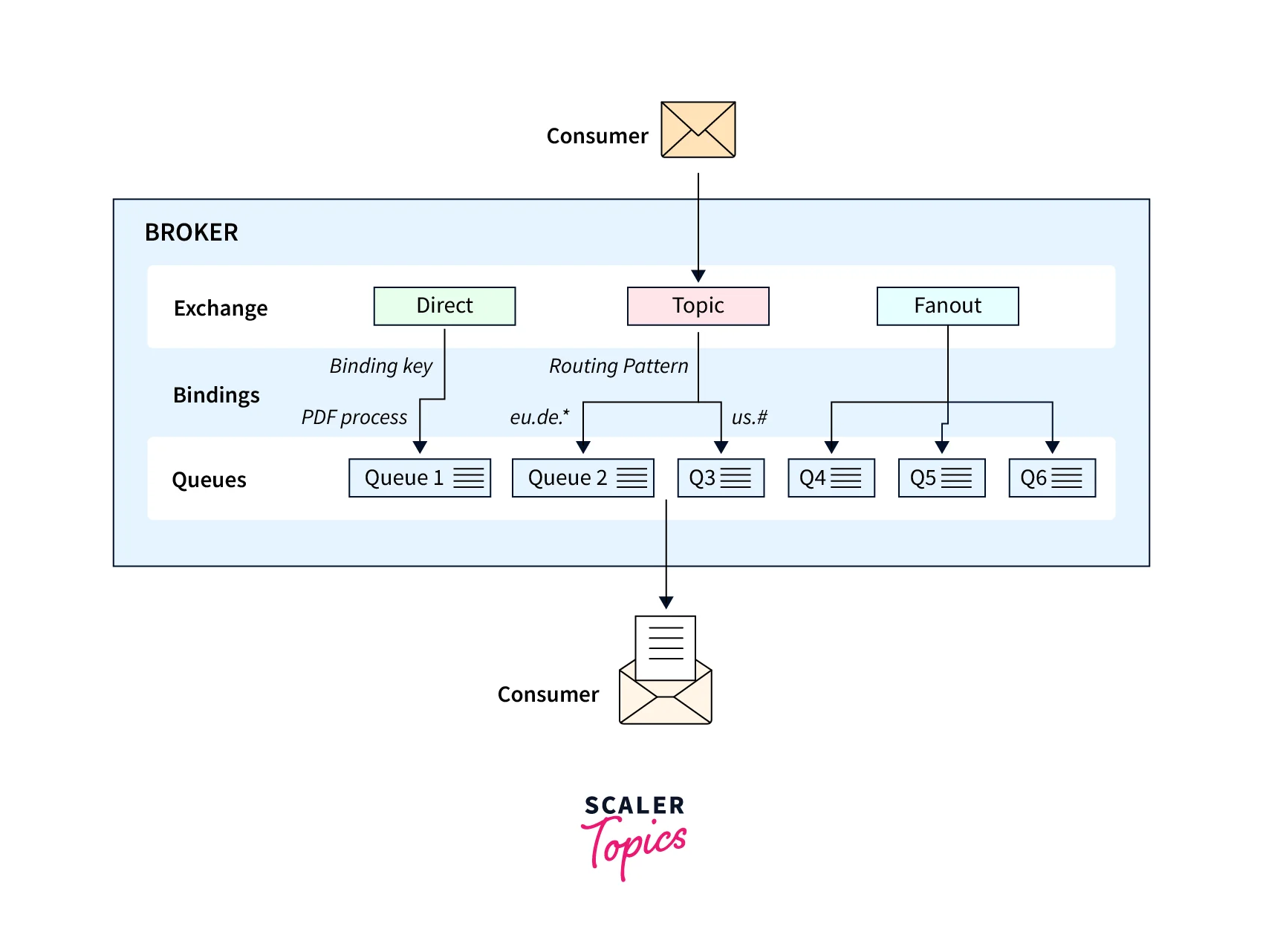
Scenarios where RabbitMQ could be implemented:
- With RabbitMQ, users cannot replay the data records on a topic. The sent messages could be stored, hence allowing the utilize the producer to replay the message.
- As compared RabbitMQ is flexible and holds the capability to cope with any modification in structure via its flexible routing abilities.
- No change is required in the publisher while dynamically adding the consumers.
- If your use case revolves around consistent behavior for each data record, then RabbitMQ could be utilized for the same.
- When you need a system that interacts point-to-point (requests and response) between microservices then RabbitMQ is a better choice.
Difference between RabbitMQ and Kafka
You now might be wondering which of RabbitMQ vs Kafka is the better messaging option. We know both the service RabbitMQ vs Kafka offer features that might be useful but we must also take into consideration the skills required for operating the versatile developer and services communities.
Below is a tabular format where we have distinguished between RabbitMQ vs Kafka
| Key metrics | RabbitMQ | Kafka |
|---|---|---|
| Performance | Process upto 10K data records per second | Process up to 1 million messages per second |
| Data Type | Offers transactional data type | Offers operational data type |
| Synchronicity of messages | Work both as synchronous or asynchronous | Offers durability of storing the data records which can be replayed later. |
| Topology | Based on exchange type topology such as Direct, Fan out, Topic, Header-based | Based on publish/subscribe messaging system. |
| Payload Size | No constraints are observed. | Works at the default 1MB limit |
| Usage Cases | Implemented for simple use cases | Implemented for massive data and cases involving high throughput. |
| Data Flow | Distinct data packets are transferred as data records or messages | The data flow is not bounded and works as continuous data that are in the key-value format. |
| Data Unit | Data unit is referred to as message | referred to as continuous stream of messages. |
| Data Tracking | The Broker/Publisher is validating and keeping track of the status of messages and whether those are read or not. | The Broker/Publisher keeps track of only the unread messages. the already sent message is not retained. |
| Routing messages | Depending upon the event type, complex routing is possible. | Usesr can consume individual topics but complex routing is not possible. |
| Message delivery system | Data records are pushed to defined queues | Based on Pull-based model. Here the message pulls are mandatory for the consumer's end. |
| Message management | Messages are Prioritized | Messages can be Order and retained |
| Message Retention | Acknowledgment s provided once a message is consumed by the consumer based | Based on the retention period chosen the message stays up until then. |
| Event storage structure | Queue-based storage structure. | Logs-based storage structure. |
| Consumer Queues | Decoupling of the consumer queues | Coupled consumer partition. |
Kafka vs RabbitMQ – Differences in Architecture
Let us discuss the critical differences in Architecture between Kafka vs RabbitMQ.
Kafka Architecture is shown below:
The messages are pushed and consumed in Kafka via the Producers and consumers respectively. Messages are pushed to the architecture where they are queued in the Kafka topics, and various can simply pull the messages from the subscribers to the same topic.
The architectural features of Kafka are:
- High volume of publish-consumer messages It is fast, reliable, durable, and scalable.
- Data Record store With the log commit partition system, Kafka keeps the streams of records in topics.
- Data Records are nothing but key-value, along with timestamps.
- Message resides in the queue until the retention period.
- Apache Zookeeper manages the coordination between brokers.
RabbitMQ Architecture is shown below:
RabbitMQ receives the data records from the applications which push the message in it widely popular as publishers. Within the architecture, these messages are received which are then routed to the storage buffers popularly known as the queues. Systems that consume these data records are the consumers where these data records are sent via its push-based approach.
The architectural features of RabbitMQ are:
- General purpose message broker: Variations of request/reply, point-to-point, and pub-sub communication patterns is implemented.
- Smart broker consumer model: Messages are consistently pushed to consumers, at the same speed while the broker monitors the state of the consumer.
- Communication: It can either be synchronous or asynchronous.
- Deployment scenarios: Offers distributed deployment scenarios.
Pull vs Push Approach – Kafka and RabbitMQ Compared
While talking about the difference between RabbitMQ vs Kafka, talking the Pull vs Push Approach plays a crucial role. While Kafka works on a pull-based messaging model, RabbitMQ is working on a push-based messaging system. As said, the consumer asks for data from the Kafka brokers through its pull-based approach, and when a consumer is late in doing so, it can still catch up when it's ready. While in the push-based models, the data records are instantly pushed to the already decided subscribed consumer. Hence, both RabbitMQ vs Kafka behave quite differently and one should take their requirements into the picture while selecting one of them, where this Pull vs Push Approach could be a game-changer for them.
Pull vs Push Approach is depicted below:
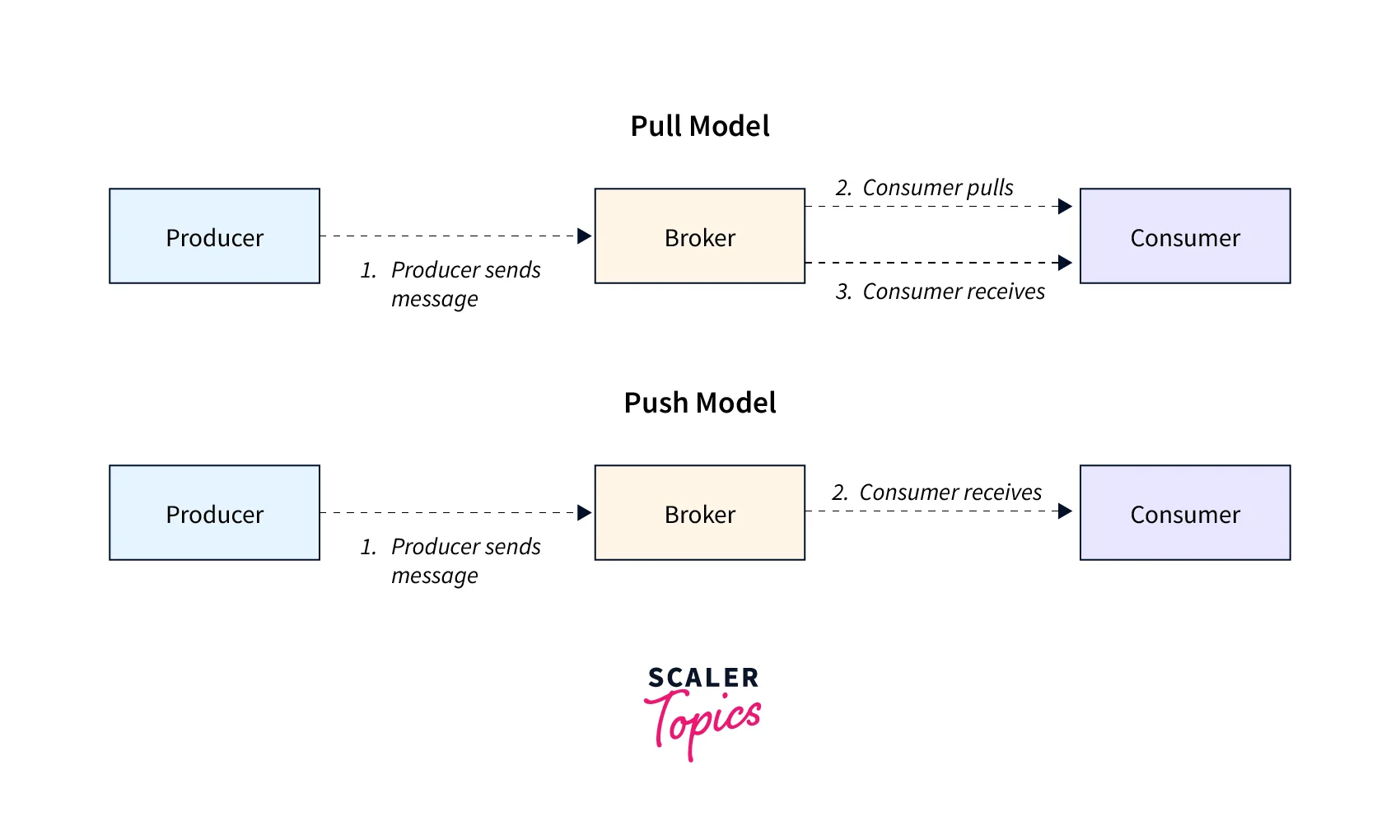
Apache Kafka: Pull-based approach As understood Kafka is utilizing the Pull based approach where the consumer needs to ask for data from the Kafka broker. Here, the subscriber requests certain specific data records from a defined offset. As Kafka has a partitioned log commit model, this pull-based approach works perfectly for it. As Kafka offers the message in the specified order over a partition allowing the users to leverage this batch of data records. This enables efficient message delivery to consumers as well as offers higher throughput. When there is no alienated subscriber for the data records Kafka preserves the data records over a single partition which enables the pull-based approach for message consumption.
RabbitMQ: Push-based approach
On the contrary side, RabbitMQ offers a push-based approach to its customers. This help to stop overwhelming the subscriber via the limit specified by the subscriber. This is a highly accepted messaging system for low-latency messaging.
The push model aims to distribute messages individually and quickly, to ensure that work is complemented in an even structure. This way the data records are seamlessly processed in the order they were pushed into the queue. But this also causes problems when more than one consumer has ‘failed’ or is no longer receiving any data records. As the limit is already defined over the producer to prevent from overwhelming the subscriber while it is pushing the data records. The advantage one can implement with the push-based model is that it could effectively parallelize the workload over various subscribers by evenly distributing the data records. The order in which the data record arrive is approximate and not always exact as sometimes few data records might be processed faster.
RabbitMQ vs Kafka – How do They Handle Messaging?
When it comes to handling the messaging of the data records between RabbitMQ vs Kafka, it depends on the use case a user defines based on which it can understand which between the two must be chosen.
Let us discuss how RabbitMQ vs Kafka behaves concerning topics like
- Message Deletion
- Message Consumption
- Message Priority
Message Deletion: While talking about RabbitMQ, when a message is delivered an acknowledgment is provided by the subscriber. When this acknowledgment is positive it means the message has reached the consumer else the message is returned to the queue.
While for Kafka, within the defined retention time, the data records or any messages are retained depending upon the period. And once the period passes, the message is removed from the queue itself.
Message Consumption: When it comes to consuming the data records delivered to the subscriber by any one of RabbitMQ's brokers, it is then these data records that are transferred in batches.
When a Kafka consumer consumes a data record from the Kafka broker, the offset is increased. It is so as it also maintains the queue counter offset trackable.
Message Priority: In RabbitMQ, the priority is assigned to the data record via the help of a priority queue. While for Kafka, the data records share the same priority. It's also noted that no modification in the priority is allowed.
Below is the tabular format representing how the messaging is handled between RabbitMQ vs Kafka:
| Tool | RabbitMQ | Apache Kafka |
|---|---|---|
| Ordering in messages | Not supported. | With partitioning, users can order their message in the way it wants to receive it from the customer. With the help of the message key, the data records are sent to the topics. |
| Message retention | RabbitMQ is a queue messaging system, which means that as soon as the messages are consumed they vanish. Acknowledgment of the message being read is provided. | As Kafka is a log messaging system, and hence it retains the data records by default. This can be defined with the help of the retention policy. |
| Guarantee of the Delivery | No atomicity is guaranteed. No guarantee of the delivery is defined even if single queue transactions are viewed. | The order of the message is retailed inside the partition. Apache Kafka guarantees that the entire set of messages in a partition either fails or passes. |
| Priorities in the Message | The message priorities can be defined explicitly in the RabbitMQ. The messages with high priority can be consumed first. | Not supported. |
Kafka vs RabbitMQ Performance
Let us discuss which RabbitMQ vs Kafka performs better. Although it is quite tough to measure performance where multiple variables are taken in the picture such as configuration of the service, code interaction with the service, along with the hardware. These can severally impact service performance. Its recommended to configure as per your requirement for max efficiency for your to check what is better between RabbitMQ and Kafka model. Metrics such as the speed of the disk, network, also memory could contribute to the performance.
While we talk about RabbitMQ it is advised to set the benchmark and size of the cluster, check for performance optimization techniques for your code to offer better efficiency, know how to handle the queue connection and sizes along with learning about how the consumers are consuming the data records. For a use case where the processing of millions of data records requires more resources up to 32 nodes is the key, one must opt-in for RabbitMQ along with the combination of tools such as Apache Cassandra.
Whereas when Kafka is being checked for efficiency and optimizing its performance, one should know how they can configure the Kafka cluster. users must also look into metrics associated with running Kafaka over JVM and more like it. We know that with Kafka the performance is significantly higher than with RabbitMQ vs Kafka utilizes the sequential disk I/O which contributes to its sealess queues and hence boosts performance. One key advantage of Kafka is that it requires limited resources when it comes to processing millions of requests per second for organizations dealing with big data.
Conclusion
- Kafka was developed by LinkedIn to solve their issue of tracking website activity. Kafka was built for building real-time data pipelines as well as streaming applications.
- While Kafka works on a pull-based messaging model, RabbitMQ is working on a push-based messaging system.
- With RabbitMQ, users cannot replay the data records on a topic. The sent messages could be stored, hence allowing the utilize the producer to replay the message.
- As compared RabbitMQ is flexible and holds the capability to cope with any modification in structure via its flexible routing abilities.
- In RabbitMQ when a message is delivered an acknowledgment is provided by the subscriber. When this acknowledgment is positive it means the message has reached the consumer else the message is returned to the queue.
- For Kafka, within the defined retention time, the data records or any messages are retained depending upon the period. And once the period passes, the message is removed from the queue itself.
- Application that processes huge amounts of data records needs messaging offering High throughput(100K/sec events or more, then Kafka could be implemented.