Real-Time Data Pipeline Using Spark Streaming
Overview
Spark Streaming is an extremely effective technique for processing real-time data streams. It allows users to create scalable and fault-tolerant data pipelines capable of handling huge volumes of data. Users can utilize Spark Streaming to ingest data from many sources and execute real-time processing such as filtering, aggregating, and joining. As a result, it's a popular choice for applications like fraud detection, social media analysis, and IoT data processing. Users can process data in parallel and achieve low-latency processing using Spark's distributed computing platform. Spark Streaming provides a stable and adaptable foundation for developing real-time data pipelines.
What are we Building?
Real-time data processing is becoming increasingly vital in the age of big data. Spark Streaming is a useful tool for developers to process real-time data streams at scale. Businesses may make informed decisions based on real-time data by constructing a real-time pipeline with Spark Streaming. In this pipeline, data is ingested from numerous sources, processed and transformed in real-time, and then stored in a database or other system. Organizations can handle massive volumes of data in real time and make smarter decisions faster because of Spark Streaming's fault-tolerant and scalable design.
Prerequisites
The development of real-time data pipelines has become increasingly critical as firms attempt to make data-driven choices. Apache Spark is a well-known open-source big data processing engine that allows for the rapid and efficient processing of enormous amounts of data. In addition, spark Streaming is an Apache Spark component that allows real-time data processing.
-
Real-time data pipeline using Spark Streaming:
The first requirement is a thorough understanding of a real-time data pipeline and how it may assist your company. A real-time data pipeline is a continuous flow processed and evaluated in real-time. Spark Streaming provides a foundation for real-time data processing, allowing businesses to make data-driven decisions based on the most recent facts. -
Spark Streaming Architecture:
The following requirement is a solid understanding of the Spark Streaming architecture. The micro-batch processing architecture underpins Spark Streaming, which separates the real-time data stream into small batches handled in parallel. This architecture provides a fault-tolerant and scalable foundation for real-time data processing. -
Kafka:
Kafka is another crucial prerequisite for building a real-time data pipeline with Spark Streaming. Kafka is a distributed streaming platform that allows you to publish, process, and subscribe to data streams in a dependable and scalable manner. As a result, Kafka is a popular data source for Spark Streaming applications. -
Risk Management Analysis in Banking:
Furthermore, it is critical to understand the precise business requirements for your real-time data flow. For example, risk management analysis is a significant pipeline component in the banking business. Spark Streaming can evaluate massive amounts of data from numerous sources in real time to discover potential dangers.
Overall, the prerequisites for developing a real-time data pipeline using Spark Streaming include a complete understanding of the Spark Streaming architecture, familiarity with Kafka, and a clear awareness of the exact business requirements for your pipeline. By achieving these prerequisites, businesses can establish real-time data pipelines that deliver timely and meaningful insights for making data-driven choices.
How are we Going to Build This?
Creating a real-time data pipeline using Spark Streaming can be difficult, but it is doable with the appropriate strategy and methods. The first step in creating such a pipeline is identifying and connecting the data source to the Spark cluster. After connecting the data source, the following step is to define the data schema and build a data ingestion pipeline capable of handling the data ingestion rate.
The data is then transformed using Spark Streaming operations, including map, filter, and reduce. After that, the altered data can be put in a storage layer like HDFS, Cassandra, or Elasticsearch. Spark Streaming provides multiple output methods for writing data to various storage layers.
The last stage is to create a live data visualization dashboard with tools like Grafana, Kibana, or Tableau. This dashboard allows you to monitor the real-time data pipeline and make data-driven decisions.
To create this real-time data pipeline with Spark Streaming, we will take the following steps:
- Step - 1:
Determine the data source and connect it with the Spark cluster. - Step - 2:
Create a data ingestion pipeline to handle the data ingestion rate and define the data structure. - Step - 3:
Use Spark Streaming operations like map, filter, and reduce to transform the data. - Step - 4:
Using Spark Streaming output operations, save the changed data in a storage layer such as HDFS, Cassandra, or Elasticsearch. - Step - 5:
Configure a real-time data visualization dashboard with tools like Grafana, Kibana, or Tableau to monitor the real-time data pipeline and make real-time data-driven choices.
Following these steps, we can successfully design a real-time data pipeline using Spark Streaming. This pipeline will allow us to process, transform, and store data in real-time for various applications such as fraud detection, real-time recommendation engines, and predictive maintenance.
Final Output
A Spark Streaming data pipeline's final output might take several forms. For example, it could be a processed stream of data sent to a database or file system, a real-time dashboard displaying insights from the data stream, or even an alert or notice triggered when particular conditions in the data are met.
For instance, if the use case is to monitor social media sentiment in real-time, the pipeline's end output could be a stream of sentiment scores for each tweet processed. This sentiment score stream might be saved in a database or utilized to update a real-time dashboard, allowing stakeholders to monitor sentiment changes over time.
Conversely, if the use case is to detect abnormalities in server logs, the end output could be a stream of alerts generated when certain patterns or thresholds are exceeded. These notifications could be delivered to the appropriate parties through email or SMS for further inquiry.
In summary, depending on the exact use case and processing steps applied to the incoming data stream, the ultimate output of a real-time data pipeline with Spark Streaming might take several shapes.
A high-level architecture diagram for a real-time data pipeline using Spark Streaming would look something like this:
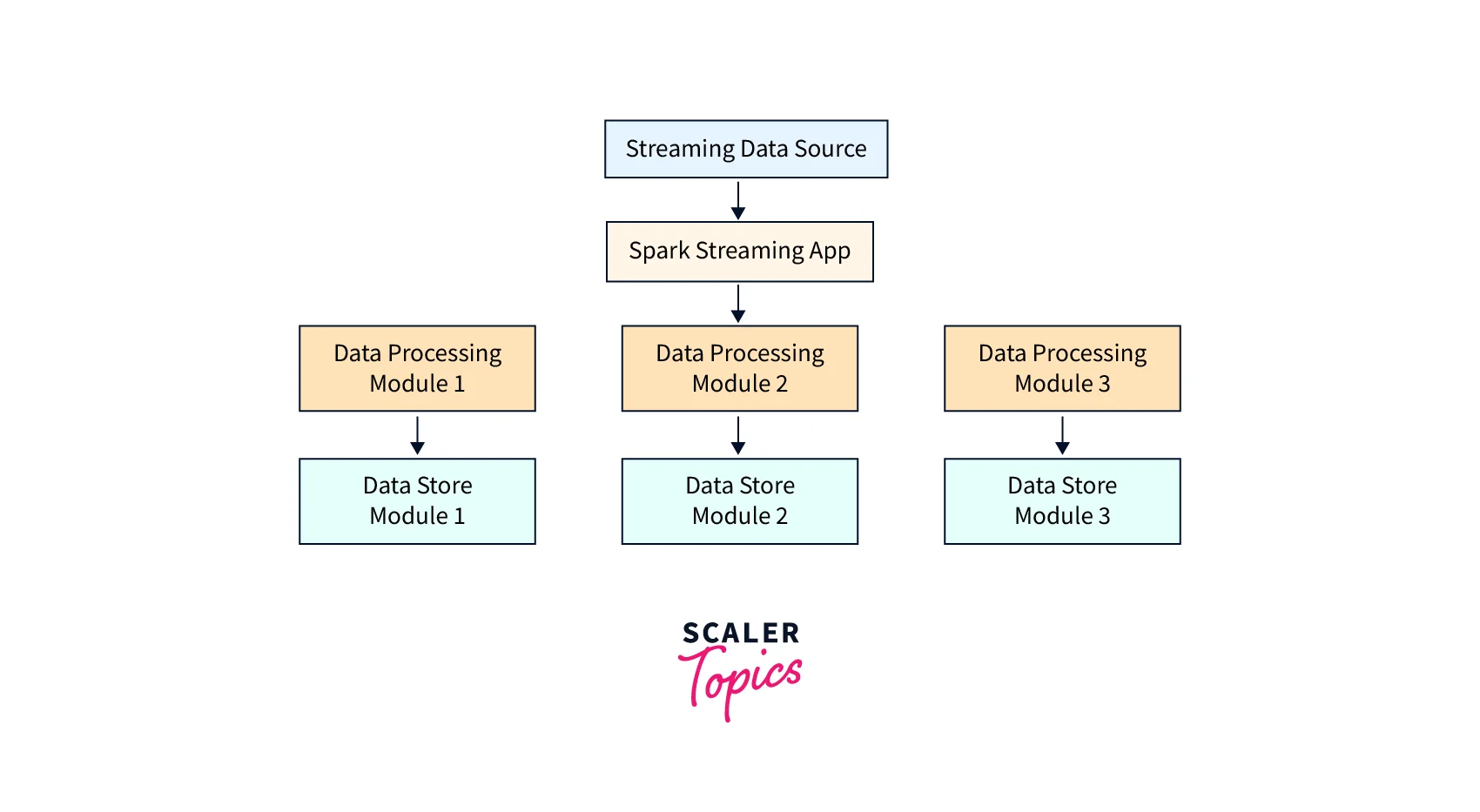
Requirements
To ensure efficient and reliable streaming data processing, a real-time Spark Streaming pipeline must meet a set of libraries, modules, and other requirements. Below is a list of critical components to consider while establishing a real-time data pipeline with Spark Streaming:
- Apache Spark:
An open-source distributed computing platform for processing large-scale data sets. Spark is a scalable and fault-tolerant data processing and analytics technology. - Spark Streaming:
A real-time data stream processing extension to the Apache Spark core API. Spark Streaming is a scalable and fault-tolerant approach for processing large amounts of data. - Kafka:
Kafka is a distributed streaming platform for building real-time data pipelines and streaming applications. It offers a scalable and fault-tolerant method for processing and storing massive data. - Hadoop Distributed File System (HDFS):
A distributed file system with high availability and reliability for storing large-scale data sets. HDFS is critical for storing and managing data in a distributed setting.
In addition to the requirements mentioned earlier, other factors like network connectivity, storage capacity, and processor power should be considered while constructing a real-time data pipeline with Spark Streaming. A real-time data pipeline utilizing Spark Streaming may be created rapidly and precisely with the right mix of libraries, modules, and other prerequisites, offering real-time insights and analytics.
Implementation of Real-Time Data Pipeline Using Spark Streaming
Let us try to implement the real-time data pipeline using Spark Streaming
Imports
Dataset
In this project, we will use a dataset containing information about risk management in banking. The dataset includes parameters such as the type of risk, the degree of the risk, and the risk's impact. This dataset is used to examine the various sorts of hazards that banks encounter and how they manage them.
Data Transformation and Processing
In this step, we can use Spark Streaming to process the real-time data.
Data Ingestion Using Kafka
We will use Kafka as our data ingestion tool. We will define a function to read data from Kafka and create a DStream.
Integration with Amazon S3 for Data Storage
We will use Amazon S3 to store the processed data. We will define a function to save the data to S3.
Data Visualization and Analysis
We can use Tableau to visualize and analyze the processed data.
Tableau is a data visualization and business intelligence tool that allows users to connect, visualize, and share data in a meaningful way. With an intuitive drag-and-drop interface, users can quickly create interactive dashboards, reports, and charts without needing extensive technical skills. Tableau supports a wide range of data sources and formats, including spreadsheets, databases, and cloud services. The tool provides advanced analytics and data blending capabilities to help users gain insights and make data-driven decisions. Tableau also offers a range of deployment options, from on-premises to cloud-based solutions, making it a versatile tool for organizations of all sizes.
Here's a simple diagram that shows the basic components of such an architecture:
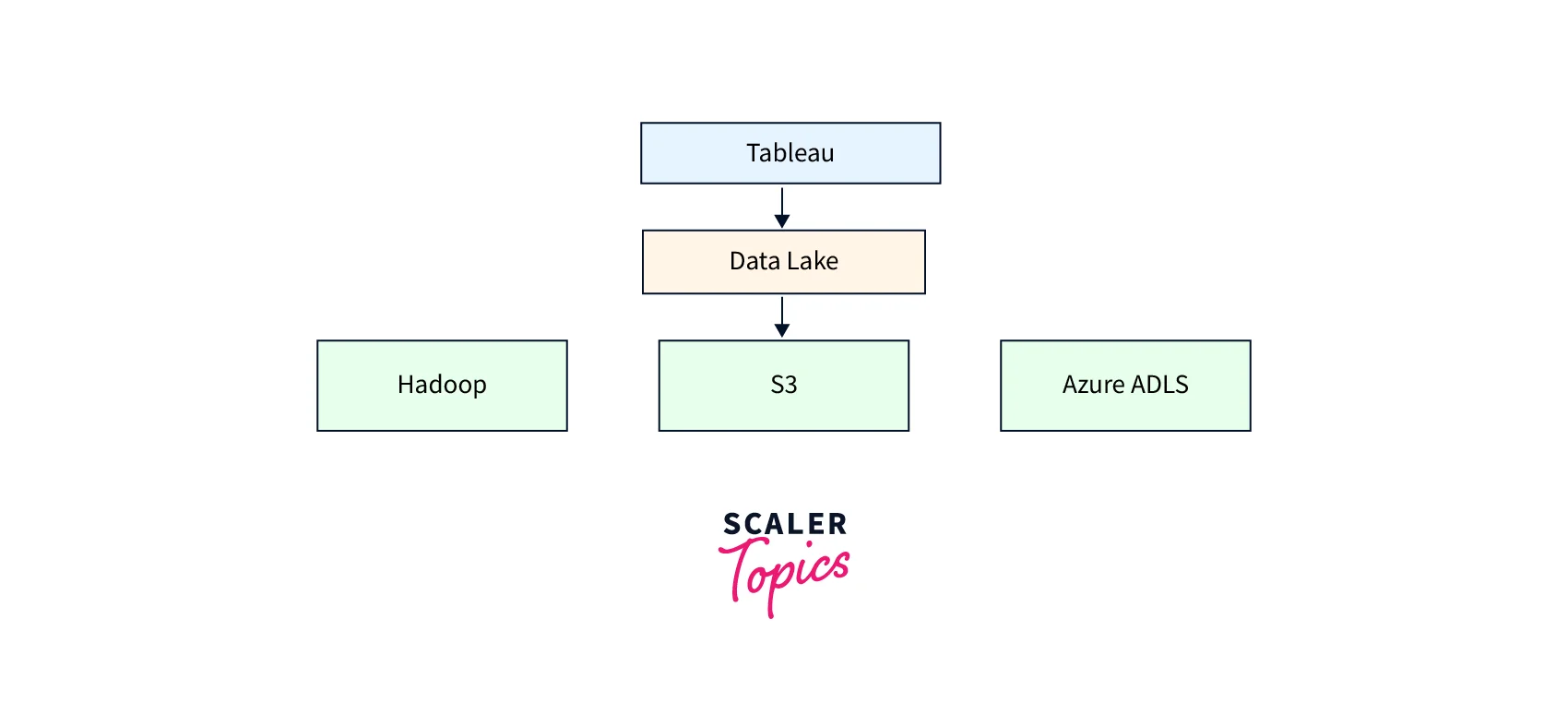
Results and Evaluation
Here's an example of a main function that integrates all the functions described in the implementation plan to create a real-time data pipeline using Spark Streaming, Kafka, and Amazon S3:
This main function sets up the Spark Streaming context with a batch interval of 10 seconds, creates a Kafka stream using the create_kafka_stream function, defines the data processing function process_stream, and processes the Kafka stream using Spark Streaming. The processed data is then saved to Amazon S3 using the save_to_s3 function. Finally, the Spark Streaming context is started and the program waits for it to terminate.
To assess the performance of the real-time data pipeline, we can monitor various metrics such as the number of messages processed per second, the average processing time per message, and the size of the processed data. We can also compare the performance of the real-time data pipeline to a batch processing approach using the same dataset. For example, we can run a batch processing job on the same dataset and compare the processing time and resource utilization with the real-time data pipeline.
In terms of the pipeline's ability to handle real-time data, we can test it by generating a continuous stream of data and measuring the pipeline's ability to process it in real time. We can also simulate various scenarios such as spikes in data volume or network failures to test the pipeline's fault tolerance and scalability.
Overall, assessing the performance and capability of the real-time data pipeline is essential to ensure its reliability and effectiveness in handling real-world data.
Testing
Real-time data pipeline testing with Spark Streaming is critical for assuring the dependability and quality of your data processing systems. Spark Streaming is a popular real-time processing engine that provides a comprehensive foundation for real-time data processing and analysis.
To put a real-time data pipeline through its paces using Spark Streaming, you must set up a test environment that mimics real-world data sources and processing scenarios. This test environment should contain data generators that generate data streams in the same format as the data handled in the production environment. You must also simulate several data processing scenarios to ensure your pipeline can handle various data and processing conditions.
Once your test environment is set up, you can utilize Spark Streaming's built-in testing facilities to check the functioning of your data pipeline. Test StreamingContext, Test DStream, Test InputDStream, and Test OutputDStream are examples of such functionality. These features enable you to test several parts of your data pipeline, such as data processing logic, output correctness, and error and exception management.
You may test your data pipeline using third-party testing frameworks such as JUnit or ScalaTest in addition to the built-in testing features of Spark Streaming. These frameworks extend testing capabilities and can assist you in developing more complete test suites that cover a wider variety of scenarios.
Overall, using Spark Streaming to test real-time data pipelines is an important step in guaranteeing the accuracy and reliability of your data processing systems. You may identify and fix possible issues before they affect your production environment by developing a rigorous test environment and using Spark Streaming's built-in testing facilities.
More on Real-Time Data Pipeline Using Spark Streaming
Real-time data processing is a crucial component of many firms that deal with enormous amounts of data, particularly in banking, telecommunications, and e-commerce. Apache Spark Streaming is one such solution that enables real-time data processing by allowing continuous processing of data streams.
Challenges and Solutions
Nevertheless, creating a real-time data pipeline using Spark Streaming might provide several issues that must be addressed for operations to go smoothly. The following are some of the most prevalent issues that organizations have when installing Spark Streaming-based data pipelines:
-
Scalability issues:
Scalability is one of the most significant issues when working with enormous data. Spark Streaming provides scalability but requires a well-designed cluster architecture to manage massive volumes of data. Scaling up or down, dependent on data load, is also important. -
Latency and throughput challenges:
Another problem is processing real-time data with low latency and high throughput. Spark Streaming achieves low latency and high throughput by employing micro-batch processing, which needs data to be processed in small batches. However, the batch size must be tuned to obtain the optimal balance of delay and throughput. -
Data quality issues:
Another problem in a real-time data pipeline is ensuring data quality. To maintain the quality of the data flowing through the pipeline, it must be cleaned, validated, and transformed in real-time. On the other hand, if the data quality is good, it can lead to accurate results and other problems. -
Solutions to overcome these challenges:
Organizations must employ a variety of strategies to tackle these issues, including:- Cluster Management:
A well-designed cluster architecture with optimum resource allocation can assist firms in scaling up or down dependent on data demand. - Optimizing Batch Size:
Companies may achieve the optimal balance between latency and throughput by optimizing the batch size. - Data Quality Checks:
Including data quality checks in the pipeline can help to assure data quality. Data validation rules and data cleaning strategies can assist in identifying and correcting data quality issues in real-time. - Data Backup and Recovery:
A backup and recovery plan can assure data integrity during a breakdown or downtime.
- Cluster Management:
Creating a real-time data pipeline using Spark Streaming can be difficult. However, by addressing scalability, latency, throughput, and data quality issues, businesses can develop a robust and dependable pipeline capable of handling massive volumes of data in real time.
Importance of Real-time Data Pipeline in Today's World
Real-time data pipelines are becoming increasingly vital in today's environment, as organizations rely significantly on data to make choices and stay competitive. A real-time data pipeline is a system that receives, processes, and sends data in real-time or near real-time, allowing organizations to make faster and more accurate choices.
One of the most significant advantages of a real-time data pipeline is that it allows businesses to respond to changes in real-time. For instance, if a company notices an unexpected rise in demand for a specific product, it can swiftly modify its inventory levels and marketing approach to capitalize on the opportunity. Unfortunately, this level of agility would only be achievable with a real-time data flow, and businesses would be forced to rely on outdated data.
Real-time data pipelines also increase decision-making accuracy by giving up-to-date information. Businesses can make decisions based on the most recent data rather than outdated information when data is processed and given fast. This is especially critical in industries with rapid change, like banking or healthcare.
Another advantage of real-time data pipelines is that they allow businesses to recognize and respond to irregularities swiftly. For example, if a corporation notices a sudden increase in website traffic, it may promptly analyze and find the cause. This can help to avoid downtime and keep the website accessible to clients.
Furthermore, a real-time data pipeline is crucial in today's world, where organizations work in a highly dynamic and competitive environment. It allows firms to adapt to changes rapidly, make more accurate judgments, and spot abnormalities before they become serious problems. As the volume of data businesses generate grows, so will the relevance of real-time data pipelines.
Future Directions for Research in Real-time Data Pipeline with Spark Streaming
In the age of big data, real-time data processing has become increasingly crucial, and Apache Spark Streaming has emerged as a popular framework for developing real-time data pipelines. As the volume, velocity, and variety of data increase, various future research directions in real-time data pipelines with Spark Streaming can help enterprises stay ahead of the curve.
Improving data processing efficiency is one topic of research. As data volumes continue to grow, real-time data processing becomes more difficult. Therefore, researchers can investigate several optimization strategies for Spark Streaming, such as parallelizing data processing, maximizing resource efficiency, and decreasing data shuffling.
Another promising study area is integrating machine learning methods with Spark Streaming. Machine learning is a strong tool for collecting insights from real-time data, and combining it with Spark Streaming can assist enterprises in making better real-time decisions. Researchers can investigate various machine learning algorithms, such as clustering, classification, and regression, that can be combined with Spark Streaming.
Additionally, research can focus on developing more efficient real-time data storage and retrieval systems. Data storage and retrieval systems must be optimized to accommodate the volume and velocity of data handled by Spark Streaming. Several data storage technologies, such as in-memory databases, distributed file systems, and NoSQL databases, might be investigated by researchers.
Finally, research might be directed toward improving the security of real-time data pipelines. Security is a major concern in real-time data processing, and academics can investigate several techniques for securing data pipelines. They can, for example, investigate various encryption and decryption techniques, access control, and data audits.
So, the future of real-time data pipelines with Spark Streaming is bright, and various research avenues can help to improve its capabilities. For example, researchers may assist firms in extracting useful insights from real-time data more effectively and safely by improving data processing, incorporating machine learning, establishing more efficient data storage and retrieval systems, and enhancing security.
Conclusion
- Spark Streaming offers a simple API for processing real-time data streams, making it a popular solution for enterprises working with massive amounts of streaming data.
- Data ingestion is the initial stage in creating a real-time data pipeline with Spark Streaming. Numerous data ingestion sources are available, including Kafka, Flume, and Amazon Kinesis.
- Once the data has been ingested, it is passed through the processing layer, where Spark Streaming offers a variety of transformation and aggregation operations that can be performed on the data.
- The high-performance and fault-tolerant architecture of Spark Streaming makes it an excellent choice for processing large-scale streaming data.
- Integrating Spark Streaming with other components of the Spark ecosystem, such as Spark SQL and MLlib, enables enterprises to design end-to-end data processing pipelines that can handle structured and unstructured data.