What are Recovery Techniques in DBMS?

The database recovery techniques in DBMS are used to recover the data at times of system failure. The recovery techniques in DBMS maintain the properties of atomicity and durability of the database. A system is not called durable if it fails during a transaction and loses all its data and a system is not called atomic, if the data is in a partial state of update during the transaction. The data recovery techniques in DBMS make sure, that the state of data is preserved to protect the atomic property and the data is always recoverable to protect the durability property. The following techniques are used to recover data in a DBMS,
- Log-based recovery in DBMS.
- Recovery through Deferred Update
- Recovery through Immediate Update
What is a Log-Based Recovery?
Any DBMS has its own system logs that have the records for all the activity that has occurred in the system along with timestamps on the time of the activity. Databases handle different log files for activities like errors, queries, and other changes in the database. The log is stored in the files in the following formats,
- The structure [start_transaction, T] denotes the start of execution of transaction T.
- [write_item, T, X, old_value, new_value] shows that the value of the variable, X is changed from old_value to new_value by the transaction T.
- [read_item, T, X] represents that the value of X is read by the transaction T.
- [commit, T] indicates the changes in the data are stored in the database through a commit and can't be further modified by the transaction. There will be no error after a commit has been made to the database.
- [abort, T] is used to show that the transaction, T is aborted.
We can use these logs to see the change in the state of the data during a transaction and can recover the data to the previous state or new state. A undo operation can be used to examine the [write_item, T, X, old_value, new_value] operation and retrieve the state of data to old_data. A redo operation can be done to convert the old state of data to the new state that was lost due to system failure and is only possible if the [commit, T] operation is performed.
Consider multiple transactions named t1,t2,t3, and t4 as shown in the image below. A checkpoint at a time during the first transaction and the system fails during the fourth transaction, but it is possible to recover the data to the state of the checkpoint made during t1.
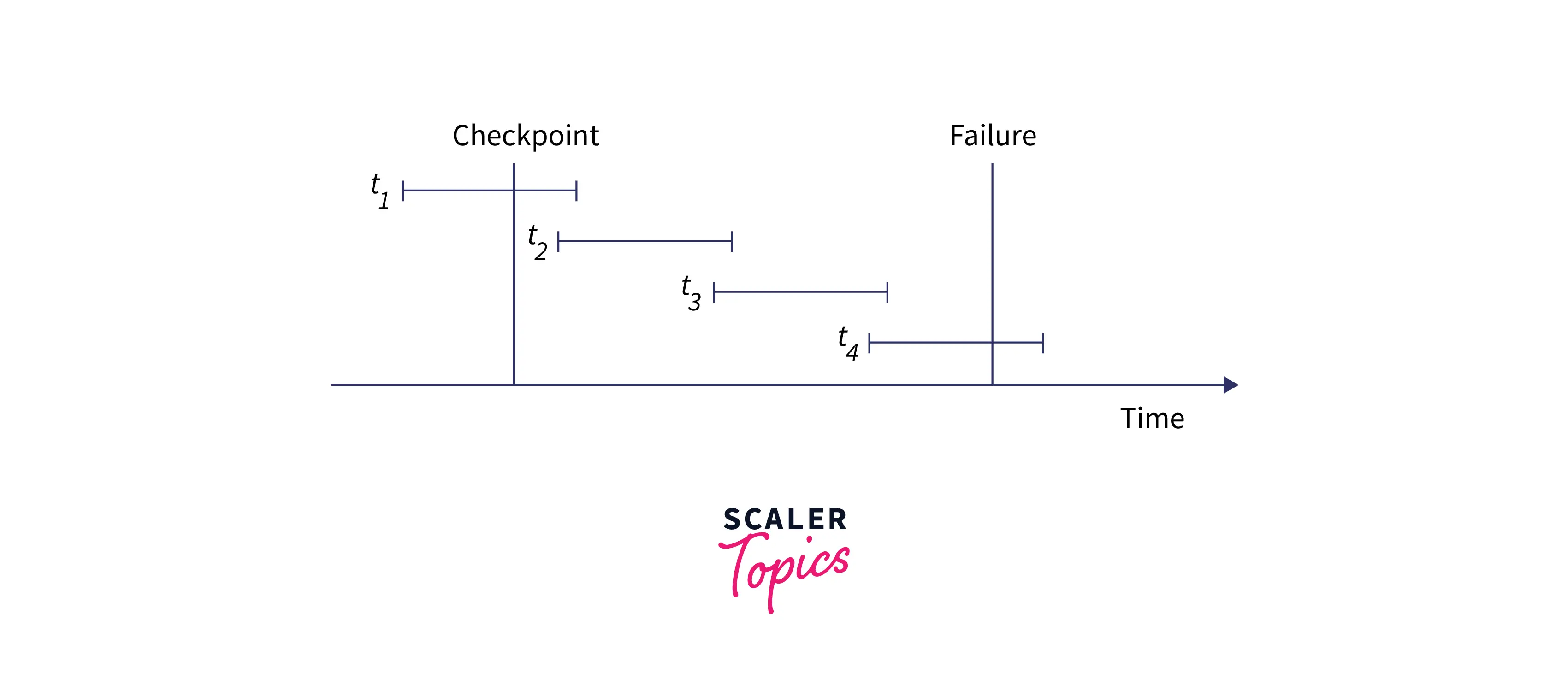
A checkpoint is made after all the records of a transaction are written to logs to transfer all the logs from the local storage to the permanent storage for future use. Read more on Checkpoint in DBMS.
What is the Conceded Update Method?
In the conceded update method, the updates are not made to the data until the transaction reaches the final phase or at the commit operating. After this operation is performed, the data is modified and permanently stored in the main memory. The logs are maintained throughout the operation and are used in case of failure to find the point of failure. This provides us an advantage as even if the system fails before the commit stage, the data in the database will not be modified and the status will be managed. If the system fails after the commit stage, we can redo the changes to the new stage easily compared to the process involved with the undo operation.
Logging is set up automatically in many databases, but we can also configure them manually. The following steps can be executed in the MySQL terminal to set up logging in to a MySQL database,
- Create a variable to store the file path of the log file(.log) to which the logs must be stored.
- Set the log file format.
- The general logging feature of the database should be enabled.
- The system now monitors all the activities in the database and stores them in the general.log file. The configuration for this is maintained in the general_log_file variable and can be checked with the following command,
What is the Quick Update Method?
In the quick update method, the update to the data is made concurrently before the transaction reaches the commit stage. The logs are also recorded as soon as the changes to the data are made. In the case of failure, the data may be in a partial state of the transaction, and undo operations can be performed to restore the data. We can also mark the state of the transaction and recover our data to the marked state using SQL commands. The following commands are used to achieve this,
- The SAVEPOINT command is used to save the current state of data in a transaction. The syntax of this command is,
- The ROLLBACK command is used to restore the state of the data to the save point specified by the command. The syntax of the command is,
What is the Difference Between a Deferred Update and an Immediate Update?
Deferred updates and immediate updates are database recovery techniques in DBMS that are used to maintain the transaction log files of the DBMS.
In the Deferred update, the state of the data in the database is not changed immediately after any transaction is executed, but as soon as the commit has been made, the changes are recorded in the log file, and the state of data is changed.
In the Immediate update, at every transaction, the database is updated directly, and a log file is also maintained containing the old and new values.
| Deferred Update | Immediate Update |
|---|---|
| During a transaction, the changes are not applied immediately to the data | An immediate change is made in the database as soon as the transaction occurs. |
| The log file holds the changes that are going to be applied. | The log file holds the changes along with the new and old values |
| Buffering and Caching are used in this technique | Shadow paging is used in this technique |
| More time is required to recover the data when a system failure occurs | A large number of I/O operations are performed to manage the logs during the transaction |
| If a rollback is made, the log files are destroyed and no change is made to the database | If a rollback is made, the old state of the data is restored with the records in the log file |
What are the Backup Techniques?
A backup is a copy of the current state of the database that is stored in another location. This backup is useful in cases when the system is destroyed by natural disasters or physical damage. These backups can be used to recover the database to the state at which the backup was made. Different methods are being used in backup which is as follows,
- An Immediate backup are copies that are kept in devices like hard disks or any other dives. When a disk crashes or any technical fault occurs we can use these data to recover the data.
- An Archival backup is a copy of the database kept in cloud environments or large storage systems in another region. These are used to recover the data when the system is affected by a natural disaster.
What are Transaction Logs?
The transaction logs are used to keep track of all the transactions that have made an update to the data in the database. The following steps are followed to recover the data using transaction logs,
- The recovery manager searches through all the log files and finds the transactions that have a start_transaction stage and doesn't have the commit stage.
- The transactions that are of the above case are rolled back to the old state with the help of the logs using the rollback command
- The transactions that have a commit command will have made changes to the database and these changes are recorded in the logs. These changes will also be reverted using the undo operation.

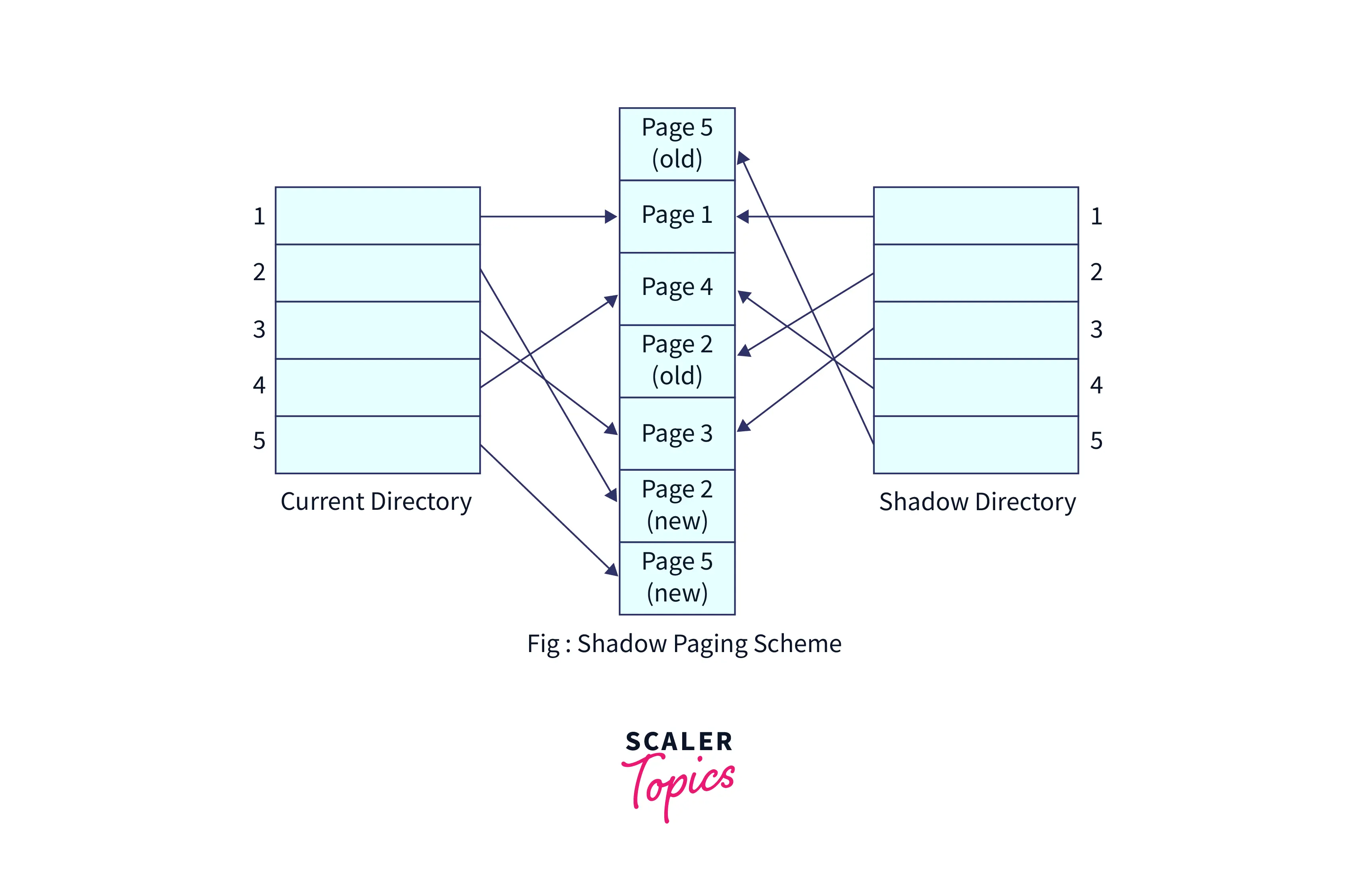
What is Shadow Paging?
- In shadow paging, a database is split into n- multiple pages that represent a fixed-size disk memory.
- Similarly, n shadow pages are also created which are copies of the real database.
- At the beginning of a transaction, the state in the database is copied to the shadow pages.
- The shadow pages will not be modified during the transaction and only the real database will be modified.
- When the transaction reaches the commit stage, the changes are made to the shadow pages. The changes are made in a way that if the i-th part of the hard disk has modifications, then the i-th shadow page is also modified.
- If there is a failure of the system, the real pages of the database are compared with the shadow pages, and recovery operations are performed.
In the Caching/Buffering method, a collection of buffers called DBMS buffers are present in the logical memory. The buffers are used to store all logs during the process and the update to the main log file is made when the transaction reaches the commit stage.
Conclusion
- Failures in a database system may be due to problems in transactions, systems, or disks.
- Recovery techniques in DBMS are used to recover the data when the new state of the data is lost or the entire data in the system is lost.
- Logs are used to keep a record of the actions in a database and these logs are used to recover the data to the database.
- Logs have a general structure and usually start with start_transaction and end with commit.
- The SAVEPOINT command is used to record the state of all data in the database and the ROLLBACK TO command is used to revert the database to the saved point.
- Shadow paging technique uses two copies of the disk memory and compares them to recover the data.