How to Use Regular Expression in Linux?
Overview
Regular expressions in Linux, commonly referred to as RegEx, are powerful tools used for pattern matching and text manipulation in Linux and other programming languages. Regular expressions allow users to define patterns that can match specific strings of characters or patterns within larger strings of text. They are widely used in Linux terminal commands for tasks such as searching for files, modifying text, and filtering data.
This article will provide an in-depth understanding of regular expressions in Linux, covering their basic concepts, metacharacters, and various examples of how they can be used in practical applications we will also focus on different versions of regular expressions and their compatibility in different Linux environments.
What is RegEx?
A regular expression in Linux is a sequence of characters that forms a search pattern. It is a text string that describes a set of strings with a common structure. Regular expressions are used to match and manipulate text based on predefined patterns. In Linux, regular expressions are supported by many command-line utilities, such as grep, sed, awk, and others, making them an essential tool for text-processing tasks.
How to Use RegEx in Linux Terminal?
The regular expression in Linux can be used in Linux terminal commands to perform various operations, such as searching for files, filtering data, replacing text, and more. The most commonly used commands that support regular expressions are grep, sed, and awk.
grep: The grep command is used to search for patterns in text files. The basic syntax of the grep command with regular expression in Linux is:
As an example, to search for the words having the letter “d” in a file named flowers.txt, the command would be:
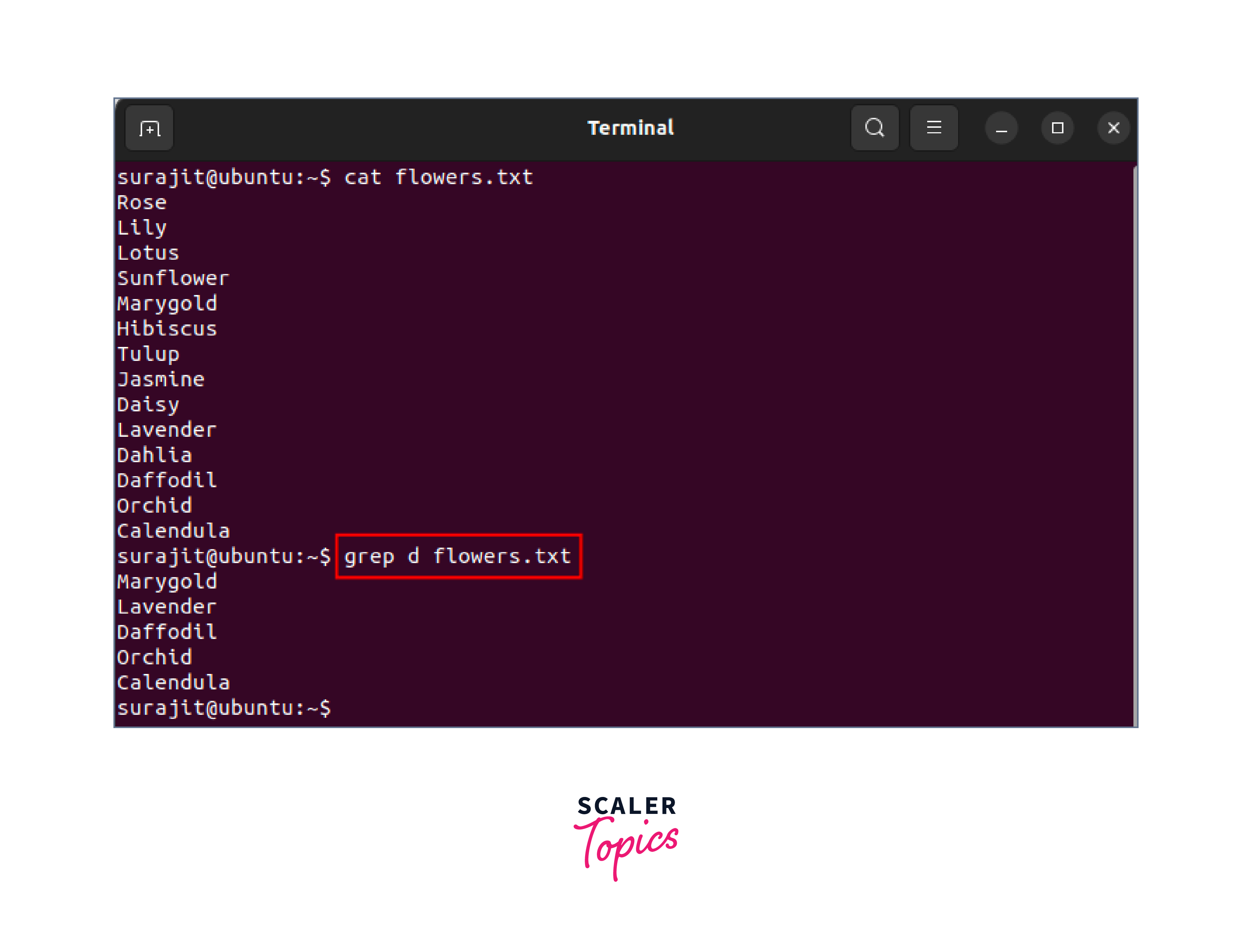
sed: The sed command is used to edit text files by performing operations on an input file line by line. The regular expression in Linux can be used in sed commands to specify patterns to match and manipulate the text. The basic syntax of the sed command with regular expressions in Linux is:
As an example, to replace all occurrences of the word "Tulup" with "Tulip" in a file called flowers.txt, the command would be:
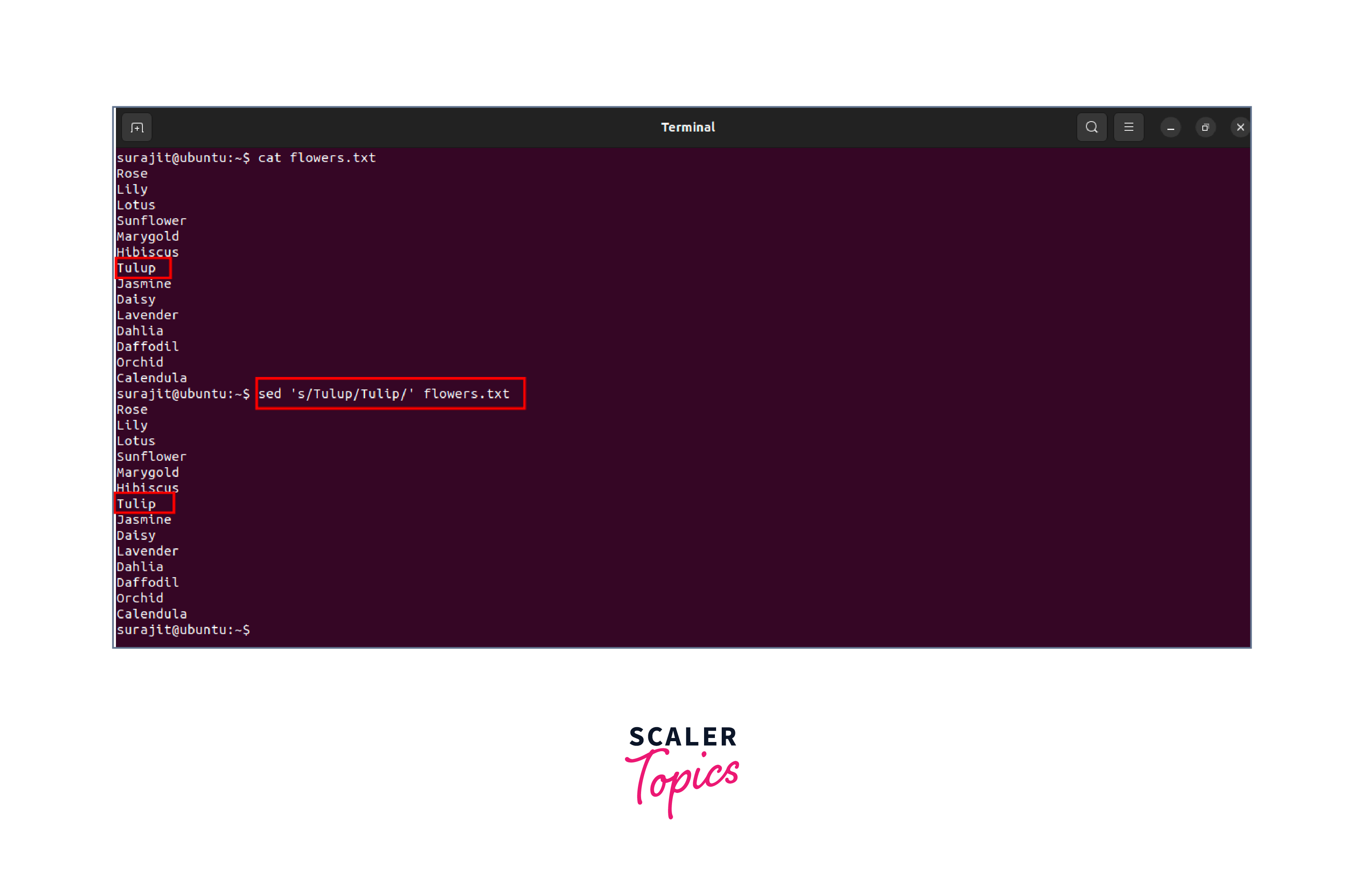
awk: The awk command is a powerful text processing tool that can be used to search for patterns and perform operations on text files. Regular expressions in Linux are used in awk commands to specify patterns and manipulate text. The basic syntax of the awk command with regular expression in Linux is:
As an example, to print all lines that contain the word "fruits" in a file called file.txt, the command would be:
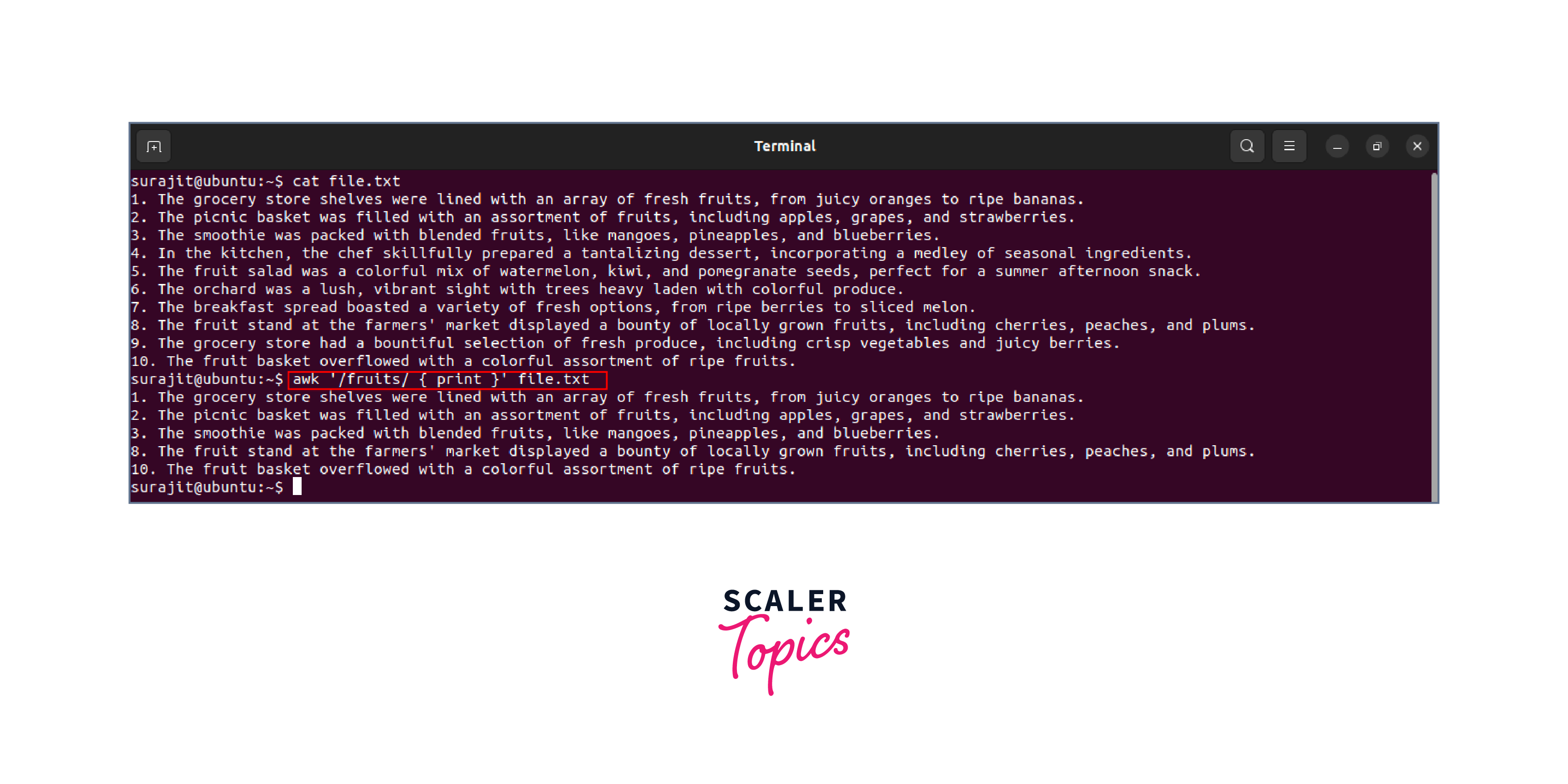
Regular Expression Metacharacters
Regular expressions metacharacters are special characters that have a specific meaning when used in a regular expressions pattern. They are used to define the rules for pattern matching and searching in text using regular expressions. The regular expression in Linux, metacharacters are used by various commands such as grep, sed, awk, and others to perform advanced text processing tasks.
Here are some commonly used regular expressions metacharacters and their definitions:
| Metacharacters | Definitions |
|---|---|
| . | Matches any single character, except for a newline character. |
| ^ | Matches the beginning of a line or string. |
| $ | Matches the end of a line or string. |
| * | Matches zero or more occurrences of the preceding character or group. |
| + | Matches one or more occurrences of the preceding character or group. |
| ? | Matches zero or one occurrence of the preceding character or group. |
| [] | Defines a character class, matching any single character that appears within the brackets. |
| [^] | Defines a negated character class, matching any single character that does not appear within the brackets. |
| {} | Specifies the exact number of occurrences of the preceding character or group. |
| () | Creates a group that allows you to apply quantifiers, such as "*", "+", or "{}", to a set of characters. |
| \ | Used to escape special characters and give them their literal meaning. |
| PIPE | Represents an OR operator, allowing you to specify multiple alternatives. |
Regex Versions
There are three main versions of regular expression in Linux:
-
Basic Regular Expressions (BRE)
-
Extended Regular Expressions (ERE)
-
Perl Regular Expressions (PERL)
ERE is a powerful type of regular expression used in Linux tools like grep, sed, and awk, allowing for advanced pattern matching using features like alternation, quantifiers, and capturing groups.
BRE is a common type of regular expression used in tools like grep and sed. BRE uses a simpler syntax making it suitable for basic pattern-matching tasks such as simple string matching and character classes.
PRCE expressions are widely used in tools like grep, sed, and awk for advanced pattern matching and text processing tasks making it a versatile tool for searching, replacing, and modifying text data.
Examples of Regular Expression in Linux
Using . (Dot): The dot metacharacter matches any character except a newline. For example, the command grep 'c.t' file.txt would match lines containing "cat", "cot", "cut", and so on in the file.txt.
Using ^ (Caret): The caret metacharacter is used to match the beginning of a line. For example, the command grep '^hello' file.txt would match lines that start with the word "hello" in the file.txt.
Using $ (Dollar sign): The dollar sign metacharacter is used to match the end of a line. For example, the command grep 'world$' file.txt would match lines that end with the word "world" in the file.txt.
Using * (Asterisk): The asterisk metacharacter is used to match zero or more occurrences of the preceding character or group. For example, the command grep 'ab' file.txt would match lines containing "a", "ab", "abb", "abbb", and so on in the file.txt.
Using \ (Backslash): The backslash metacharacter is used to escape special characters and give them their literal meaning. For example, the command grep '\*.txt' file.txt would search for lines containing the string "*.txt" in the file.txt.
Using () (Braces): The parentheses are used to group characters or subexpressions together. For example, the command grep '(ab)\*' file.txt would match lines containing zero or more occurrences of "ab" in the file.txt.
Using ? (Question mark): The question mark metacharacter is used to match zero or one occurrence of the preceding character or group. For example, the command grep 'colou?r' file.txt would match lines containing both "color" and "colour" in the file.txt.
Using + (Plus sign): The plus sign metacharacter is used to match one or more occurrences of the preceding character or group. For example, the command grep 'a+b' file.txt would match lines containing "ab", "aab", "aaab", and so on in the file.txt.
Conclusion
-
regular expressions in Linux are used in terminal commands for pattern matching and searching in text files.
-
regular expressions in Linux are case-sensitive by default, but can be made case-insensitive using options or flags.
-
Basic Regular Expressions (BRE) and Extended Regular Expressions (ERE) are the two main versions used in Linux, with ERE providing more advanced features.
-
Metacharacters such as ., *, ^, $, ? and others are used to define patterns and match characters in regular expressions.
-
Practice and experimentation with regular expressions in Linux will improve your proficiency in using this powerful tool.