Introduction to Apache Spark with Scala
Overview
Apache Spark is an open-source, distributed computing platform that offers a rapid and versatile cluster-computing framework designed for the processing of large-scale data. It's designed to handle a wide range of data processing tasks, from simple data transformations to complex machine learning and graph processing.
Spark — An All-Encompassing Data Processing Platform
In today's data-driven world, the ability to process and analyze large volumes of data efficiently is paramount. Apache Spark, coupled with the expressive programming language Scala, provides a powerful solution to this challenge.
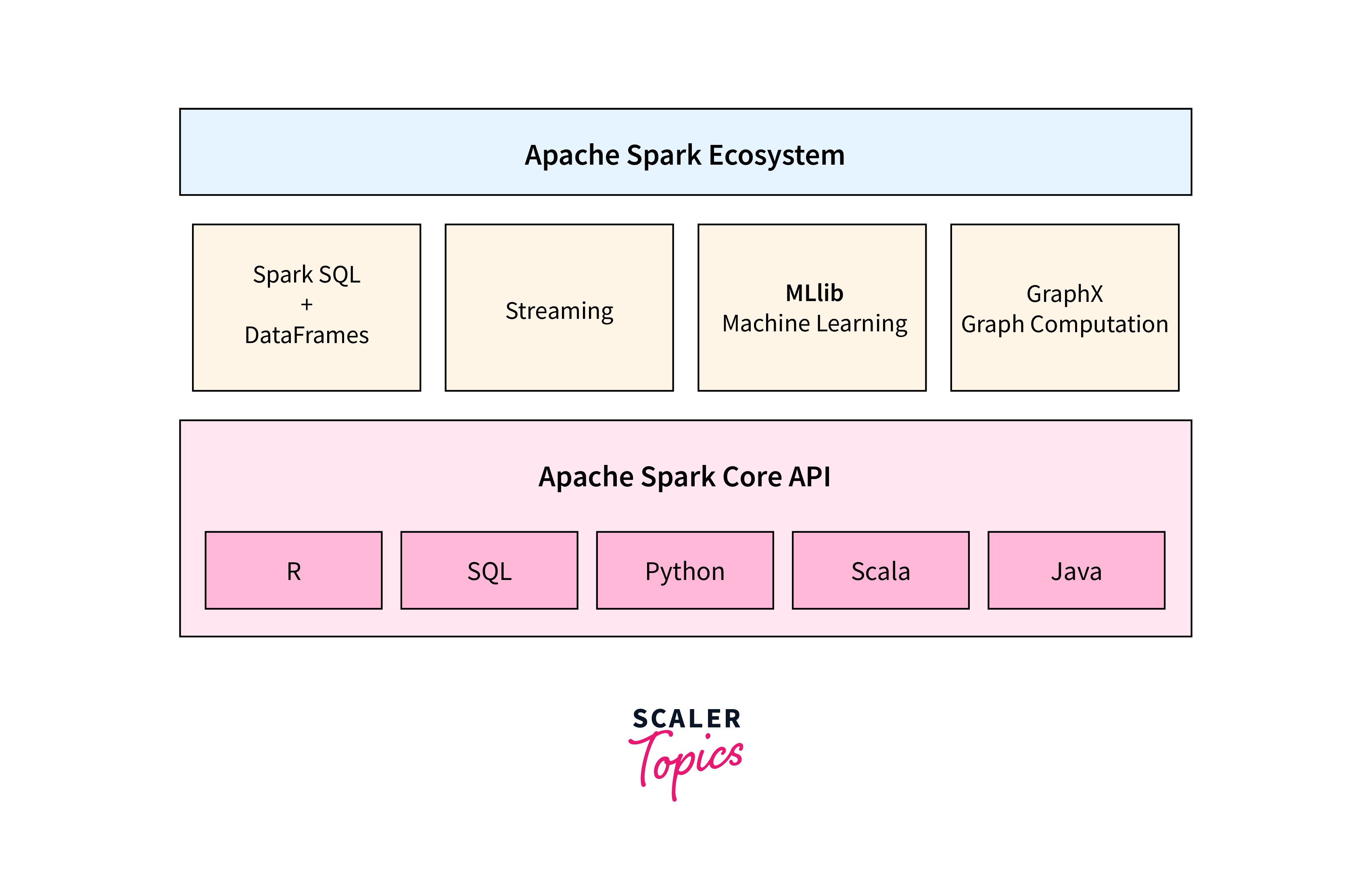
Apache Spark has revolutionized the way we handle big data. It's an open-source, distributed computing system designed for speed, ease of use, and advanced analytics. Spark's ability to process data in memory greatly accelerates data processing tasks compared to traditional disk-based systems. The core abstraction in Spark Scala is the Resilient Distributed Dataset (RDD), a fault-tolerant collection of elements that can be processed in parallel.
Apache Spark vs Other Data Processing Technologies
Hadoop MapReduce:
- MapReduce is suitable for processing vast datasets in batch mode. It provides fault tolerance through data replication and supports data locality.
- Hadoop MapReduce is best for large-scale batch processing of structured or semi-structured data, such as ETL jobs, log analysis, and historical data analysis.
Apache Flink:
- Flink offers low-latency, event-driven processing for real-time applications. Its powerful stream processing capabilities are complemented by support for batch processing.
- Flink is favoured for real-time stream processing, event-driven applications, and cases requiring low-latency data transformations.
Apache Spark on the other hand comes with greater speed, versatility, ease of use, machine learning compatibility and unified approach.
Use Cases for Spark:
- Iterative Algorithms: Spark's in-memory processing suits iterative algorithms like PageRank or machine learning tasks.
- Real-Time Analytics: Spark Streaming is apt for real-time data processing and analytics from sources like sensors or social media.
- Batch Processing: Spark can handle large-scale batch processing while accommodating other workloads in the same cluster.
- Complex ETL: Spark's capabilities make it suitable for intricate ETL transformations on diverse data sources.
- Graph Processing: Spark's GraphX is effective for analyzing and processing graph-structured data.
Advantages of Apache Spark
At its core, Spark scala offers a set of programming libraries and APIs that enable developers to process data in a distributed and parallelized manner, leveraging clusters of computers to achieve high-speed performance.
- Speed and Performance: Spark's in-memory processing accelerates speed by reducing data read/write operations.
- Flexibility: Spark supports Scala, Java, Python, and R, enabling comfortable language choices.
- Batch and Stream Processing: Spark handles historical analysis and real-time streaming in one platform.
- Advanced Analytics: Spark offers MLlib, GraphX, and Spark SQL for machine learning, graph processing, and SQL-based queries.
- Ease of Use: Spark's high-level APIs abstract distributed computing complexities.
- Fault Tolerance: Spark's fault tolerance ensures reliable processing despite node failures.

Spark Data Processing Capabilities.
Apache Spark's expertise lies in its ability to cater to a broad spectrum of data processing needs. Let us have a closer look at its standout capabilities.
Structured SQL for Complex Analytics with Basic SQL
Spark SQL is a powerful component of Apache Spark that allows us to seamlessly integrate SQL queries with our Spark applications. It enables developers and data analysts to leverage their familiarity with SQL for complex data analytics. This capability is particularly valuable when dealing with structured data in a distributed computing environment.
With Spark SQL, we can:
- Execute SQL Queries: Write SQL queries against our structured data, making it easier to perform data exploration, filtering, aggregation, and joins.
- DataFrame Abstraction: Spark SQL introduces DataFrames as distributed, structured collections with named columns, offering a higher-level abstraction and seamless integration with SQL queries compared to RDDs.
- Optimization: Spark SQL optimizes SQL queries by applying predicate pushdown, column pruning, and other techniques. This leads to improved query performance and efficient data processing.
- Data Source Integration: Spark SQL supports reading and writing data from various data sources, including Parquet, Avro, JSON, CSV, Hive, and more. This facilitates data interchange between different systems.
Spark Streaming for Real-time Analytics
Spark Streaming is a module of Apache Spark that extends its capabilities to process real-time data streams. It enables organizations to handle data as it arrives, making it suitable for applications that require rapid insights from streaming data sources.
Visualization tools like Grafana, Kibana, Tableau, and Power BI enable real-time monitoring and visual representation of insights from Spark Streaming data.
With Spark Streaming, we can:
- Ingest Streaming Data: Receive and process data in micro-batches, which are small time intervals in which data is collected and processed.
- Complex Event Processing: Apply complex event processing techniques to analyze and aggregate data in real time. This is useful for monitoring applications, fraud detection, social media sentiment analysis, and more.
- Windowed Operations: Perform windowed operations that allow us to analyze data within specific time windows, providing insights into trends and patterns over time.
- Integration with Batch Processing: Spark Streaming seamlessly integrates with batch processing, enabling us to combine real-time insights with historical analysis for a comprehensive view of our data.
MLLib/ML Machine Learning for Predictive Modeling
Apache Spark's MLlib (Machine Learning library) and ML (Spark ML) libraries provide tools and algorithms for building and training machine learning models at scale. This empowers data scientists and analysts to create predictive models and extract valuable insights from their data.
With MLLib/ML, we can:
- Choose Algorithms: Access a wide range of machine learning algorithms for classification, regression, clustering, recommendation, and more.
- Feature Engineering: Perform feature extraction, transformation, and selection to prepare our data for modelling.
- Model Training: Train machine learning models on distributed data using parallelized algorithms, making the training process faster and more efficient.
- Model Evaluation: Evaluate the performance of our models using various metrics to ensure they generalize well to new data.
- Pipeline Construction: Create machine learning pipelines that combine data preprocessing, feature engineering, and model training in a streamlined manner.
GraphX Graph Processing Engine.
GraphX is a component of Apache Spark that extends its capabilities to handle graph-structured data. It provides a powerful framework for graph processing, allowing organizations to analyze and traverse complex relationships within their data.
With GraphX, we can:
- Graph Creation: Construct graphs with vertices and edges to represent relationships between entities.
- Graph Algorithms: Apply various graph algorithms like PageRank, connected components, and triangle counting to gain insights into the structure of our data.
- Property Graphs: Attach properties to vertices and edges, enabling more sophisticated analysis and visualization.
- Graph Computation: Utilize efficient distributed graph computation techniques to process large-scale graphs.
- Integration with Other Spark Components: Integrate graph processing seamlessly with other Spark components, allowing us to combine graph analysis with batch processing and machine learning.
Initializing Spark
Various strategies exist for initializing a Spark scala application, contingent upon the specific use case. Depending on whether the application utilizes RDDs, Spark Streaming, or Structured SQL with Datasets or DataFrames, the initialization process can differ significantly. Hence, grasping the initialization of these diverse Spark scala instances is vital.
RDD with Spark Context:
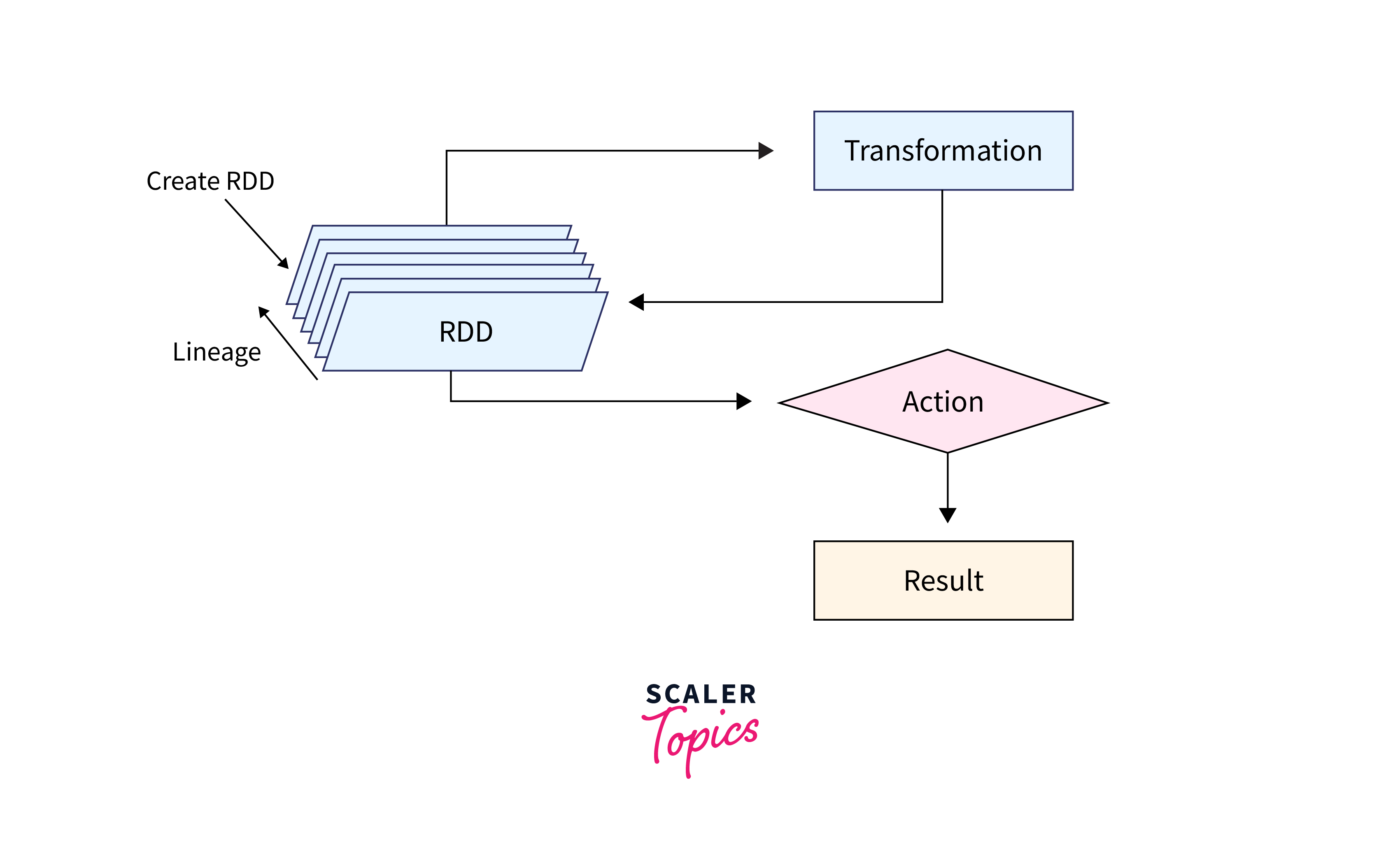
Resilient Distributed Datasets (RDDs) are the fundamental data structures in Spark, representing distributed collections of data that can be processed in parallel. The initiation of Spark begins with the creation of a SparkContext, which serves as the entry point to the Spark ecosystem.
Example:
Steps:
- Creating a SparkConf: A SparkConf object is used to configure various parameters for our Spark application, such as the application name and execution mode.
- Creating a SparkContext: The SparkContext is created using the SparkConf. It serves as the entry point for Spark's core functionalities.
- Working with RDDs: With the SparkContext in place, we can create RDDs and perform various transformations and actions on them.
- Terminating Spark Context: Once our RDD operations are complete, remember to stop the SparkContext to release resources.
DataFrame/Dataset with Spark Session:
DataFrames and Datasets provide a structured and efficient way to work with structured data. Initializing Spark now involves creating a SparkSession, which encapsulates both the SparkContext and SQLContext.
Example:
Steps:
- Creating a SparkSession: A SparkSession is the entry point to Spark's higher-level functionalities, combining the functionalities of SparkContext and SQLContext.
- Loading Data: Use the SparkSession to read data from various sources and create DataFrames or Datasets.
- Performing Operations: Leverage DataFrames and Datasets to perform SQL-like operations on structured data.
- Stopping Spark Session: After working with DataFrames/Datasets, stop the SparkSession.
DStream with Spark Streaming:
Spark Streaming revolutionizes real-time data processing, enabling the analysis of data streams. Initializing Spark Streaming requires the creation of a SparkConf and a StreamingContext.
Example:
Steps:
- Creating a SparkConf: Similar to previous examples, set up a SparkConf to configure our application.
- Creating a StreamingContext: The StreamingContext is created using the SparkConf and represents the entry point to Spark Streaming.
- Working with DStreams: DStreams are created using input sources like Kafka, Flume, or HDFS. Perform operations on DStreams to process real-time data.
- Starting and Terminating: Initiate the streaming context, process data, and wait for the streaming to finish.
Operations on RDD, Datasets and DataFrame
Apache Spark Scala, with its versatile abstractions like RDDs, Datasets, and DataFrames, offers a rich toolkit for data manipulation. Whether we're performing transformations, aggregations, or filtering, Spark's operations empower us to process vast datasets efficiently. Let us delve into the essential operations we can perform on RDDs, Datasets, and DataFrames in Spark Scala.
RDD
RDDs provide a flexible and powerful way to process data in a distributed manner. Here are some fundamental operations we can perform on RDDs:
Transformation Operations:
- map: Apply a function to each element in the RDD, creating a new RDD.
- filter: Retain elements that satisfy a given condition.
- flatMap: Apply a function that returns an iterator for each element and flatten the results.
- distinct: Remove duplicate elements.
- groupByKey: Group elements by a key.
- reduceByKey: Aggregate values by key using a specified reduction function.
- sortByKey: Sort elements by a key.
Action Operations:
- collect: Return all elements from the RDD to the driver program.
- count: Count the number of elements in the RDD.
- reduce: Combine elements using a specified function.
- foreach: Apply a function to each element in the RDD.
DataSet/DataFram
Datasets and DataFrames provide higher-level abstractions that optimize Spark's performance by leveraging Catalyst query optimization and the Tungsten execution engine.
Catalyst optimizes query plans by choosing the most efficient execution path, reducing unnecessary computations and improving data locality. Tungsten accelerates operations by minimizing CPU and memory overhead, utilizing CPU registers efficiently, and facilitating memory management through off-heap storage.
Here's a glimpse of operations we can perform on Datasets and DataFrames:
Transformation Operations:
- select: Choose specific columns.
- filter: Apply filtering conditions.
- groupBy: Group data based on specified columns.
- orderBy: Sort data based on specified columns.
- join: Perform inner, outer, left, or right join with another DataFrame.
- agg: Perform aggregate operations like sum, average, etc.
Action Operations:
- show: Display the content of the DataFrame in a tabular format.
- count: Count the number of rows in the DataFrame.
- collect: Retrieve all rows from the DataFrame.
- first: Retrieve the first row.
- foreach: Apply a function to each row in the DataFrame.
Error Handling and Debugging in Spark
Common Errors:
- NullPointerException: Accessing a null object or variable can lead to this error. Verify your data and operations.
- ClassNotFoundError: If a required class is missing in the classpath, this error occurs. Ensure all dependencies are correctly included.
- OutOfMemoryError: Running out of memory due to inefficient memory management can trigger this error. Optimize memory usage and consider caching.
- UnsupportedOperationException: Attempting an unsupported operation on an RDD or DataFrame can cause this issue. Check if the operation is appropriate.
- Task Failures: Tasks failing due to resource constraints or data skew can impact job execution. Address resource allocation and data distribution.
Debugging Strategies:
- Logging: Utilize Spark's logging framework to output information, warnings, and errors. Check logs to identify issues.
- Interactive Sessions: Use Spark's interactive shells (e.g., spark-shell, pyspark) to experiment and test code snippets before implementing them in applications.
- Checkpoints: Introduce checkpoints in long workflows to recover from failures without rerunning the entire job.
- Test Locally: Develop and test code on a smaller dataset or locally before deploying on a large cluster.
- Resource Monitoring: Use monitoring tools to track resource usage, detect bottlenecks, and ensure optimal resource allocation.
Conclusion
- Apache Spark is an open-source, high-speed data processing framework, that leverages Scala for versatile distributed computation, including batch processing, real-time streaming, and advanced machine learning.
- Spark offers comprehensive data processing capabilities, including batch processing, real-time analytics, machine learning, and graph processing.
- Operations on RDDs, Datasets, and DataFrames encompass transformations and actions that enable efficient data manipulation and analysis in Spark, catering to different data structures and optimization levels.
- Examples of operations on RDDs in Spark Scala include mapping elements, filtering data, and performing aggregations like sum or count.
- Examples of operations on Datasets/DataFrames in Spark Scala include selecting columns, filtering rows, and performing aggregations like average or grouping.