What is Sequential File Organization in DBMS?

Types of File Organizations in DBMS
A collection of similar records stored in secondary storage, such as magnetic tapes or optical disks, is called a File. File organization means storing these files so they can be accessed quickly, are easy to update, and are memory efficient. It is a logical relationship between the various records (refers to a single row in RDBMS) of the files by some means of identification and access to the specific record.
Various file organizations are given below:
- Sequential file organization
- B+ Tree file organization
- Heap file organization
- Clustered file organization
- Hash file organization
What is Sequential File Organisation in DBMS?
Sequential File organization is the easiest type of file organization in which the files are sequentially stored one after the other; rather than storing the various records of the files in rows and column format(tabular form), it stores the records in a single row.
You cannot shorten, lengthen, or delete a record after it has been placed in a sequential file. However, if the length of the record does not change, you can update it. At the end of the file, new records are added.
What are the Various Methods of Sequential File Organization in DBMS?
Two methods can implement sequential file organization
- Pile File method
- Sorted File method
Pile File method
It is the easiest sequential file organization method in which the records are stored on a first come basis, meaning whichever records come first would be stored first in the sequence. There is no fixed sequence. In this method, the order in which the records come decides the order in which they will be stored.
In case of an update, we first have to find the previous record and then update that record by the new value of the record without changing the order of the sequence.

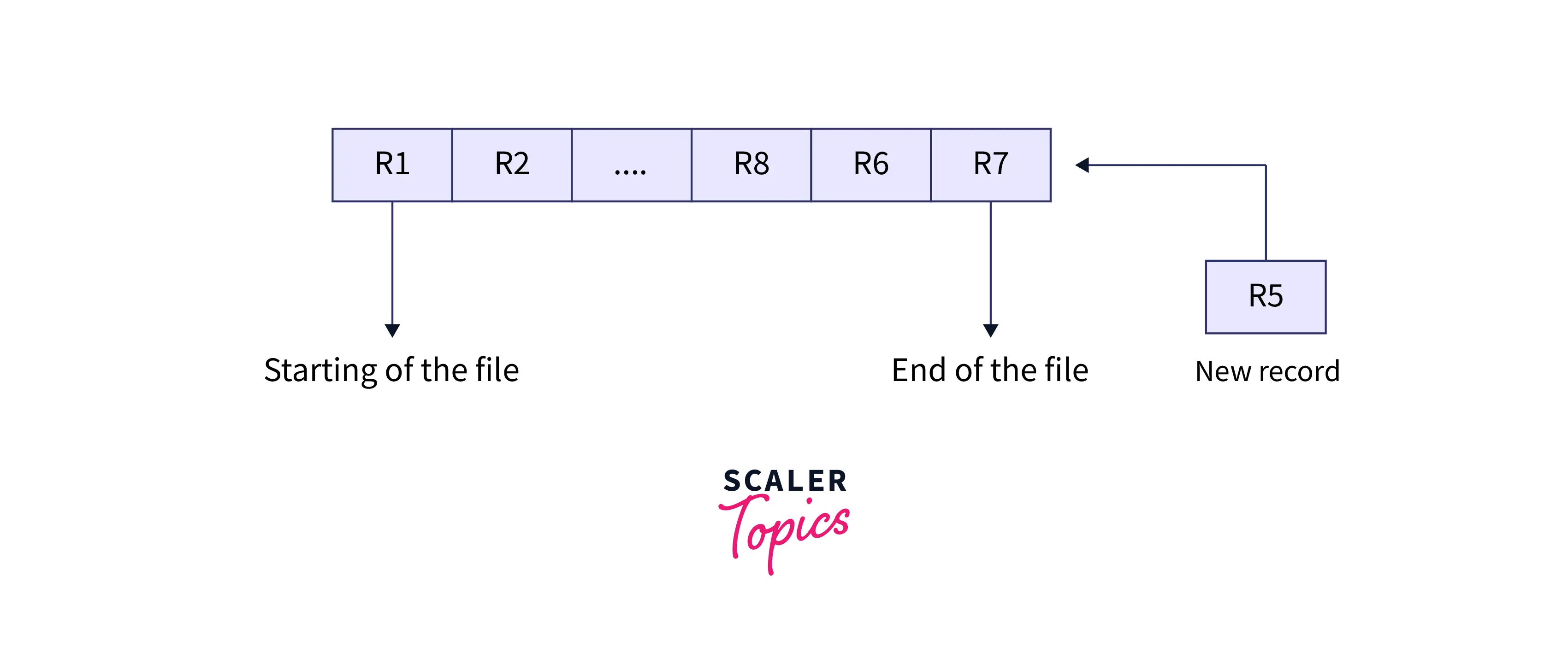
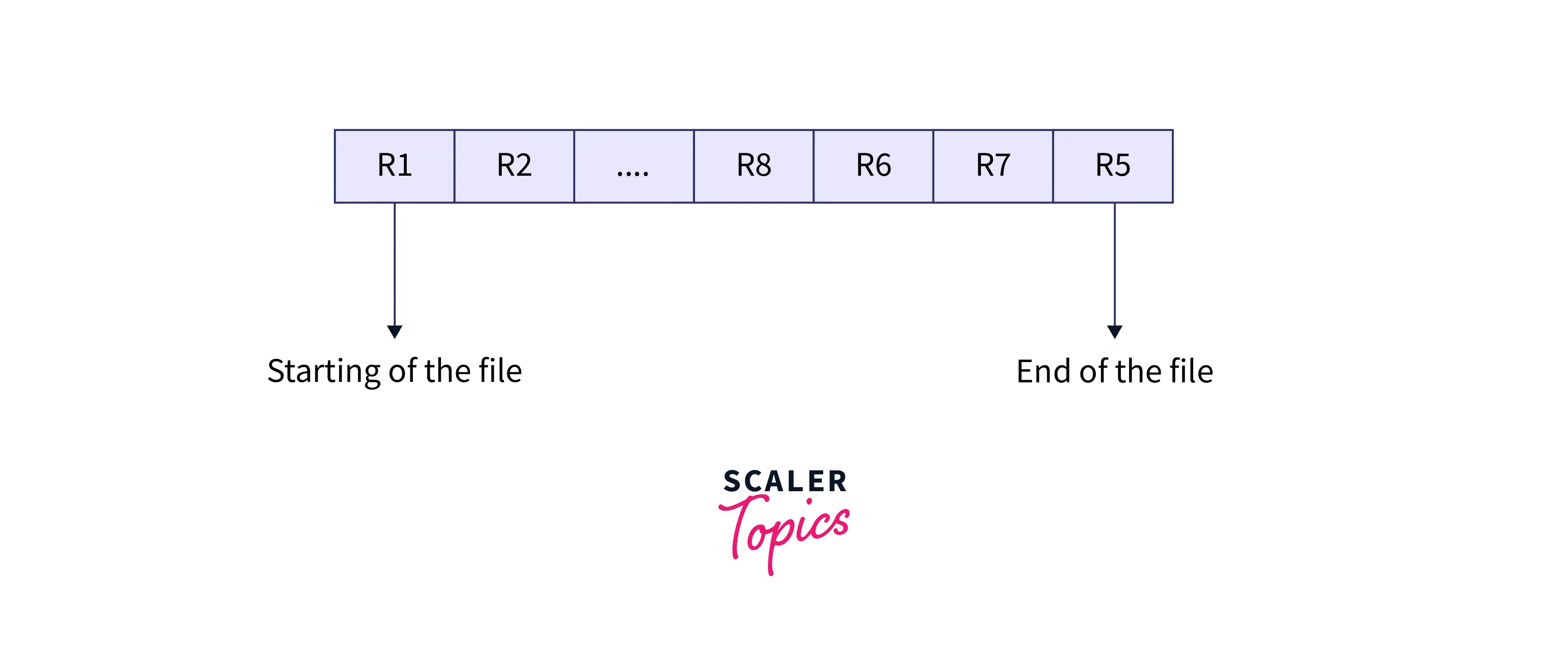
- Insertion of the New Record: It is a one-step process. Whenever a new record is added to the file organization system it would append itself to the end of the existing file in a sequential manner. Let R1, R2, R8, R6, and R7 be the five records previously stored in the file. Suppose a new record R5 comes; then the record will be added to the end of the file, i.e., after record R7.
Sorted File Method
As the name suggests in the method, files are stored in some sorted format( ascending or descending). The order in which the records come has no impact on the final sequence because we always get a sorted sequence. Order can be defined by a primary key or any other key/attribute.
In case of an update, we first have to find the previous record and update its value just like the pile file method, and then we have to sort the file according to the new record value. Searching the previous record takes less time in the case of the sorted file method.
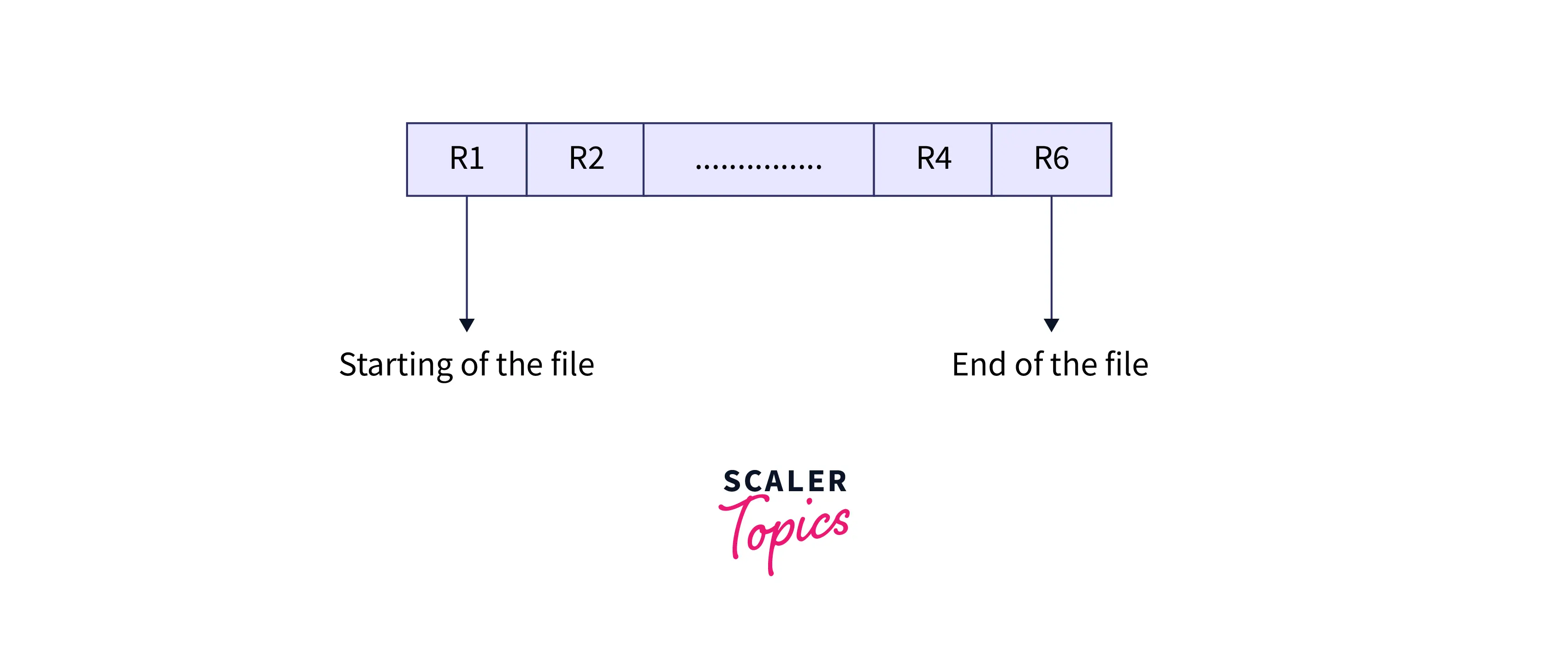
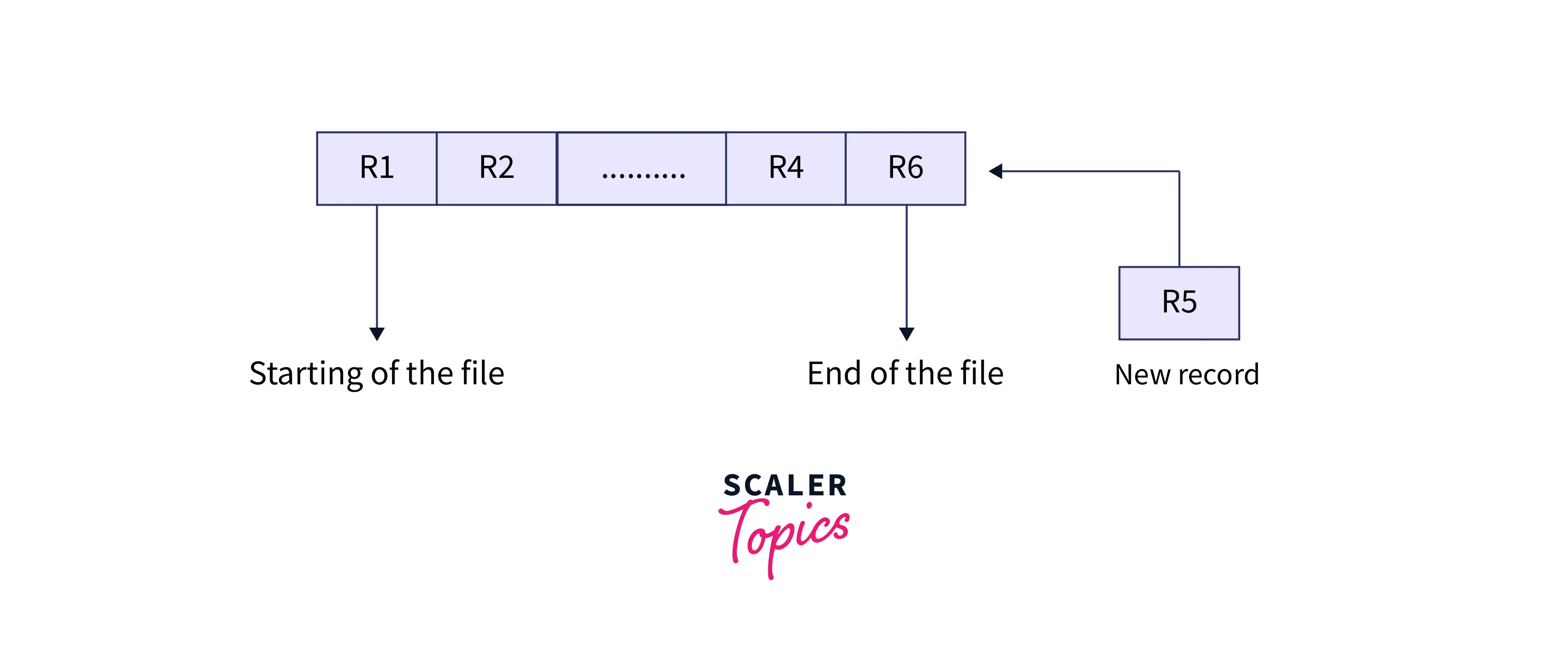
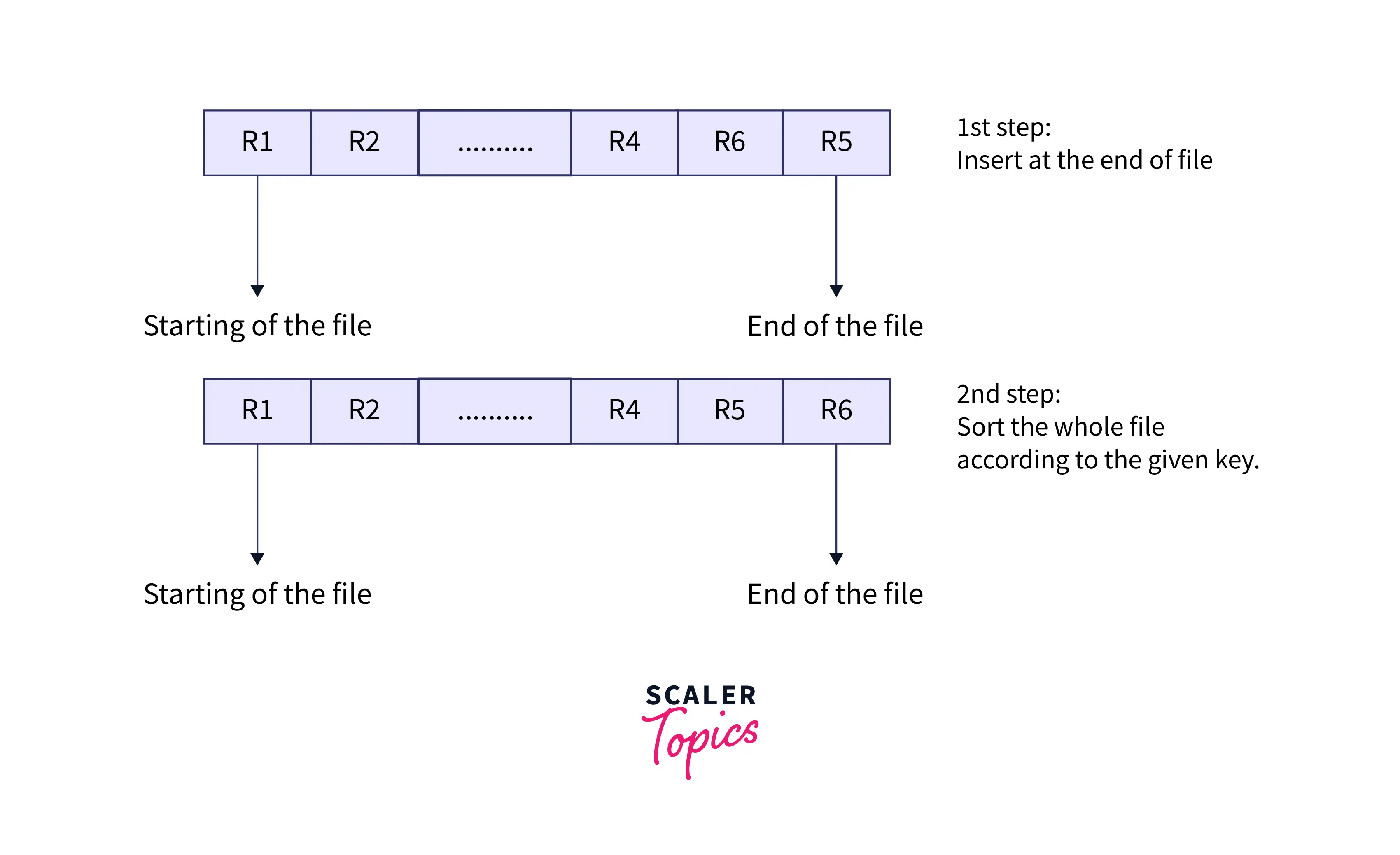
- Insertion of the New Record: It is a two-step process. Whenever a new record comes, it is first added to the end of the file, just like the pile file method, and then it will change its position according to the sorted order. Let R1, R2, R4, and R6 be the four previous records in the file sorted based on primary key reference. Suppose a new record R5 comes; then the record will firstly add it at the end of the file, i.e., after R6, and then change its position next to R4, according to sorted format.
What are the Pros and Cons of Sequential File Organization in DBMS?
As everything in the world has pros and cons, this sequential file organization also has both pros and cons.
Pros
- Comparatively speaking to other file groups, the design is simple. The process of storing the data does not need much work.
- When there are significant amounts of data, this method is extremely quick and effective. This approach is useful when it's necessary to access the majority of the information, like when computing a student's grade or creating pay stubs, for example, where we use every record to make our calculations.
- In the case of report generation or statistical calculations, this strategy is appropriate.
Cons
- In the case of the pile file approach, we cannot immediately hop onto the particular record. It takes a lot of time to always travel through it sequentially from left to right.
- Whenever we have to delete a record from a certain position the record at that particular position is deleted and all the other records will remain at their respective positions which results to create an unused memory space in the file hence it is an inefficient memory method to delete a record.
- The record must always be sorted when using the sorted file approach. The file is sorted after each insert, update, and delete operation. Therefore, repeatedly sorting them after finding the record, adding it, updating it, or deleting it takes time and could cause the system to slow down.
Learn More
File organization techniques other than the sequential file organization are explained below
1. Hash File organization - In this technique, we used a hashing technique to uniquely identify the specific record in O(1) time complexity, and hashing must be done on the column having a unique value.
2. Heap File Organization - The data block is chosen at random, and the next data block is not required for mapping the record. There is no ordering of data in this method.
3. Clustered File Organization - Clustering entails joining based on a cluster key, which is the common column in tables. This method is used when several tables are frequently joined to produce a combined result.
4. B+ File Organization - Records are kept in a tree-like structure where the leaf nodes store records and the intermediary nodes serve as pointers to those nodes.
Conclusion
- File organization stores the various files in the secondary storage so that it is easy to update, delete, and insert a new record into it.
- Sequential file organization is the easiest way to organize files for large volumes of data storage and processing systems. Files are stored in sequential order.
- Various methods to implement sequential file organization
- Pile file method - Add the new record to the end of the file on a first come basis.
- Sorted file method - First add the record to the end of the file and then sort the records according to some key.
- The advantage is that it is a simple and easy method to implement file organization. The disadvantage is the time wastage in traversing the whole file sequentially to find a single record.