Service Level Authorization Guide with Apache Hadoop
Overview
Service Level Authorization with Apache Hadoop entails putting in place a security mechanism that ensures authorized access to different Hadoop services. It is a necessary component of the Hadoop ecosystem, allowing administrators to configure authorization policies for various Hadoop services based on user roles and permissions. Hadoop administrators can create access control policies for specific users, groups, or roles using Service Level Authorization, limiting unauthorized access to critical data and protecting data privacy. This security paradigm assists enterprises in maintaining regulatory compliance while also providing a safe platform for Big Data processing.
Prerequisites
Service Level Authorization (SLA) is a method that helps safeguard Hadoop Distributed File System (HDFS) data by authorizing fine-grained data access. However, some criteria must be met before adopting SLA.
- First and foremost, the Hadoop cluster must be Kerberos-secured. All users accessing the cluster must have valid Kerberos tickets, as user authentication is necessary. Furthermore, access control techniques cannot be enforced successfully without Kerberos authentication.
- Second, a security policy for the Hadoop cluster must be defined. This policy should identify the categories of individuals and groups who have access to the data and the amount of access permitted to each user or group. The policy should also outline the cluster's auditing needs, such as which actions must be logged and which users can examine the logs.
- Third, the Hadoop cluster must have sufficient hardware resources to manage the increased strain imposed by access control measures. This includes sufficient memory and processing capability to manage the increased overhead associated with SLA enforcement and sufficient disc space to record the additional metadata associated with SLA.
- Furthermore, having a solid grasp of the data in the Hadoop cluster is critical. This includes comprehending the data's sensitivity and importance and the regulatory requirements related to it. With this insight, effective access control policies that are suited to the individual needs of the data can be defined.
Establishing SLA in Hadoop necessitates a Kerberos-secured cluster, a well-defined security policy, sufficient hardware resources, and a thorough understanding of stored data. Organizations can increase the security of their Hadoop clusters and guarantee that access to sensitive data is strictly managed by following these requirements.
Introduction
Service Level Authorization (SLA) is important to Hadoop cluster security management. It allows you to enforce access control regulations and ensure that users can only execute actions they can undertake. SLA is intended to function in tandem with other Hadoop security techniques such as Kerberos authentication and HDFS encryption.
The requirement for SLA in Hadoop arises because Hadoop is a multi-user system in which numerous users can access and process data at the same time. In such a case, it is critical to verify that users only have access to data they are permitted to see. Furthermore, SLA aids in achieving compliance standards by ensuring that sensitive data is only accessible by authorized individuals. Access to certain files or directories to specific users or groups is an example of SLA in Hadoop. This can be accomplished using HDFS ACLs or POSIX permissions to set appropriate permissions on the file or directory. For example, a file containing sensitive material can be set up so that only users from a specific group can access or write to it.
SLAs can also be used to impose resource quotas on individuals or groups. For example, suppose a specific user can only access a certain amount of storage or processing resources. In that case, SLA can be used to verify that the user does not exceed these limits.
To implement SLA in Hadoop, it is necessary to first understand the various security mechanisms available in Hadoop, such as Kerberos authentication, HDFS encryption, and HDFS ACLs. Furthermore, it is critical to understand the many components of the Hadoop ecosystem, including HDFS, YARN, and MapReduce, and how they interact.
Finally, SLA is important for controlling security in a Hadoop cluster. It allows you to enforce access control regulations and ensure that users can only execute actions they can undertake. Using SLA, organizations may ensure that sensitive data is protected and compliance needs are satisfied.
Here's a rough diagram that shows how service level authorization works with Apache Hadoop:
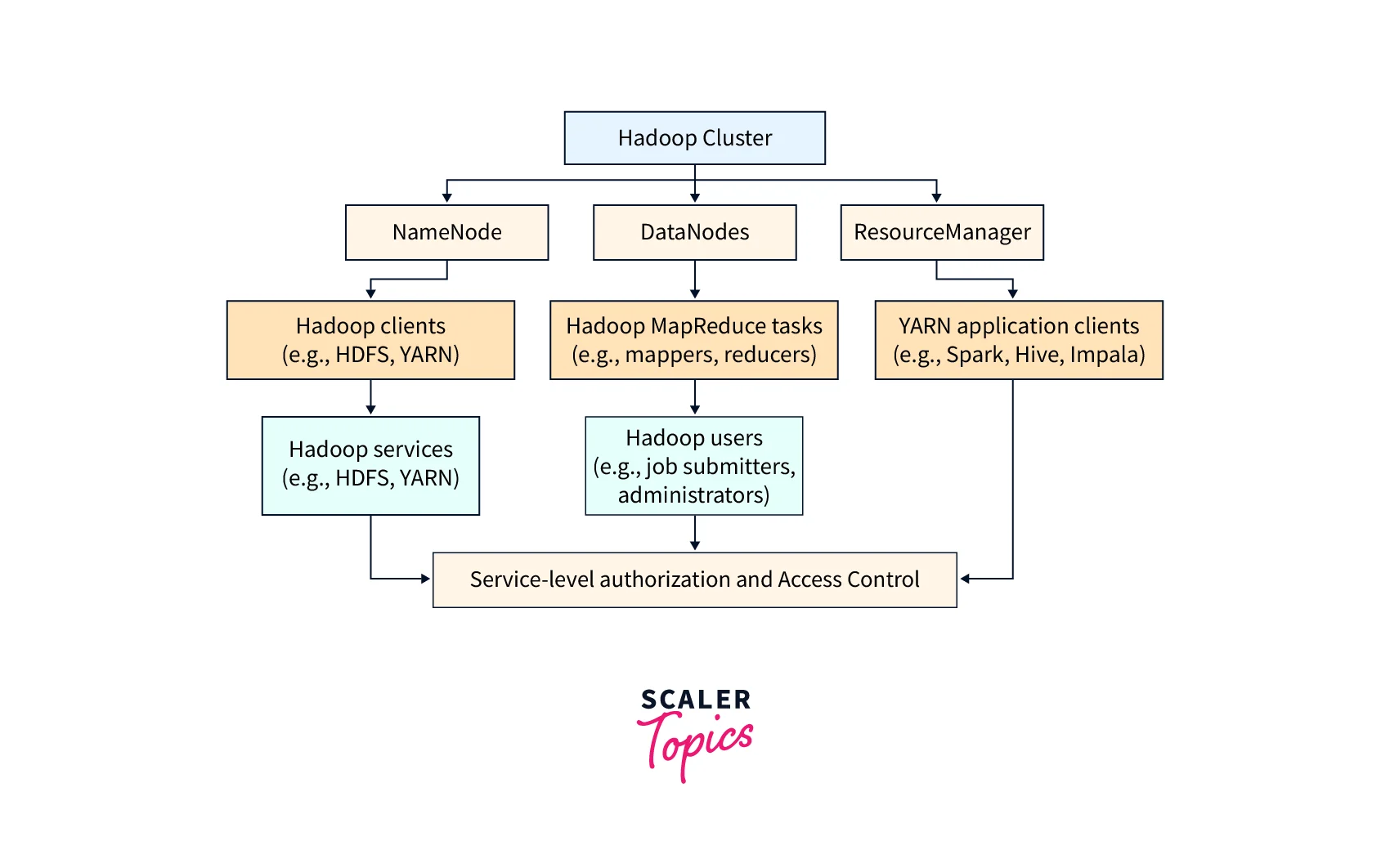
What is Apache Hadoop?
Apache Hadoop is an open-source software platform for storing and processing huge amounts of data. It is a distributed storage and processing system capable of handling enormous volumes of data across a network of commodity hardware nodes. Hadoop is built on the MapReduce programming methodology, which enables the concurrent processing of massive data sets over many cluster nodes. Some of its advantages are:
- One of Hadoop's primary advantages is its ability to manage both structured and unstructured data, such as text, photos, audio, and video.
- It also offers fault tolerance by replicating data across several cluster nodes, guaranteeing that data is not lost in the event of hardware or software failures.

Hadoop comprises two parts: Hadoop Distributed File System (HDFS) and MapReduce.
- HDFS is a distributed file system that delivers massive datasets with scalable and reliable storage.
- Hadoop MapReduce is a programming methodology allowing the concurrent processing of big datasets across numerous cluster nodes.
Hadoop is widely utilized in various industries, including finance, healthcare, telecommunications, and e-commerce. In addition, because of its capacity to analyze massive datasets fast and cheaply, it is a popular choice for big data analytics.
Furthermore, Apache Hadoop includes a wide ecosystem of tools and frameworks that operate in unison to increase Hadoop's capabilities. Apache Spark, Apache Hive, Apache Pig, and Apache HBase are some of the most popular technologies in the Hadoop ecosystem. These tools add to the functionality for processing and analyzing Hadoop data.
Purpose of Service Level Authorization
In Big Data, Service Level Authorization (SLA) is critical to data security. It is a framework meant to ensure that users and programs attempting to access Hadoop resources have the necessary permissions and access controls. The fundamental goal of SLA is to enable secure access to data and services based on the user's role, function, or other criteria.
SLAs are designed to allow data administrators to handle data and resource access control in a centralized and granular manner. They can ensure that sensitive data is kept private and confidential while other data is available to the appropriate persons at the appropriate time.
SLA also ensures that system resources are distributed evenly, with no single user or program consuming excessive processing power, memory, or disc space. This guarantees that the system as a whole is reliable, performs properly, and satisfies the demands of all users.
Furthermore, SLA allows enterprises to monitor and audit data access, assisting them in meeting regulatory compliance obligations. SLA assists companies in demonstrating that they have taken necessary measures to protect sensitive information by giving a thorough record of who accessed what data and when.
In summation, the fundamental goal of SLA is to ensure that the right individuals have access to the correct information at the right time by providing secure, centralized, and granular access to data and resources. It assists enterprises in maintaining a stable and efficient system and meeting regulatory standards while keeping sensitive data safe and secure.
Configuration
Configuring Service Level Authorization with Apache Hadoop entails establishing policies, rules, and permissions to limit access to resources within the Hadoop ecosystem. This ensures that only authorized users and processes can access and manipulate Hadoop data. Configuring Service Level Authorization is an important step in assuring the security of the Hadoop environment and safeguarding the sensitive data stored within it.
Enable Service Level Authorization
Certain configuration steps are required to implement Service Level Authorization with Apache Hadoop. First, in the core-site.xml file, set the field value hadoop.security.authorization to true. This step enables Hadoop cluster authorization.
Following that, you must set access control policies for your users and groups. This is possible with the Hadoop Access Control List (ACL) method. You can set permissions for each user and group on certain Hadoop resources, such as folders and files.
After defining the ACLs, restart the Hadoop services to apply the modifications. Testing the authorization settings by accessing Hadoop resources with different user and group credentials is also advisable.
Implementing Service Level Authorization helps secure your Hadoop cluster by ensuring that only authorized users can access Hadoop resources. It also provides a better control method for managing the cluster's access control policies.
Hadoop Services and Configuration Properties
It is critical to properly set up the Hadoop services and their associated configuration parameters when implementing Service Level Authorization (SLA) in Apache Hadoop.
Here is a rough diagram showing the major Hadoop services and their configuration properties:
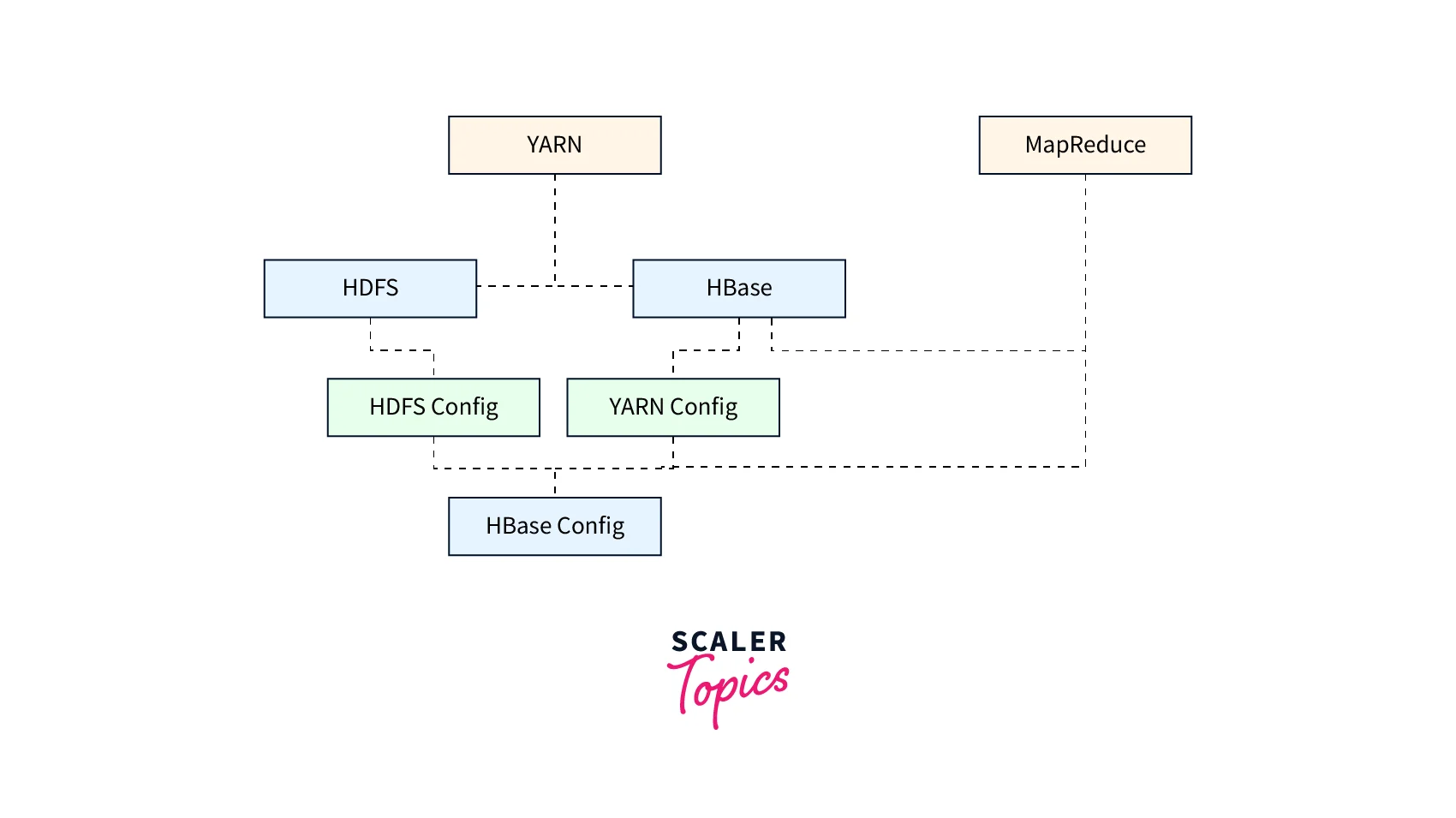
The important services and characteristics that must be configured for SLA are as follows:
-
HDFS (Hadoop Distributed File System): The Hadoop core component stores and handles massive data sets across numerous cluster nodes. Therefore, HDFS must be configured with suitable rights and access controls using properties to support SLA such as dfs.permissions.enabled and dfs.namenode.acls.enabled.
-
YARN (Yet Another Resource Negotiator): The Hadoop resource manager controls resources like CPU, memory, and disc across different applications running in a cluster. YARN must be configured to enable SLA with appropriate access controls and security settings, such as yarn.acl.enable and yarn.admin.acl.
-
MapReduce: A Hadoop processing framework for batch processing huge datasets. MapReduce must be set up with appropriate job-level permissions and access controls using properties to enable SLA use mapreduce.job.acl-view-job and mapreduce.job.acl-modify-job.
-
HBase: A NoSQL database that runs on top of Hadoop provides real-time access to large datasets. To enable SLA, HBase must be configured with proper permissions and access controls using properties such as hbase.security.authorization and hbase.security.access.
SLA can be implemented securely and regulated by appropriately setting these important Hadoop services and their associated characteristics, ensuring that only authorized users and applications have access to the data and resources they require.
Access Control Lists
Access Control Lists (ACLs) are a component of Apache Hadoop service-level authorization that allows fine-grained access control to users and groups. Administrators can use ACLs to set access policies for individual files and directories based on the organization's needs.
Permissions assigned to users and groups are used to define ACLs in Hadoop. These permissions can be changed or removed based on the company's needs. Hadoop supports three sorts of permissions by default: read, write, and execute.
When an ACL is enabled for a file or directory, the setfacl command can be used to set permissions for specified users or groups. For example, to grant read and write access to a user named user1 for the directory data, the following command shall be used:
Similarly, to give execute permission to a group named group1 for a file named file1, the following command can be used:
ACLs can also be removed or modified using the setfacl command. The following command can be used to remove all ACLs for a file or directory:
As a result, Hadoop's Access Control Lists give an extra layer of protection and authorization to files and folders. In addition, it allows administrators to apply permissions to individual users and groups, giving them fine-grained control over data access.
Refreshing Service Level Authorization Configuration
When the Service Level Authorization (SLA) configuration in Apache Hadoop is changed, the configuration must be refreshed to guarantee the new changes take effect. Reloading the changes into the ongoing processes are required to guarantee that the new policies are enforced throughout the configuration refresh process.
To renew the SLA configuration, use the refresh command from the command line interface or send a POST request to the REST API endpoint in Apache Hadoop. Changes can also be made directly to the configuration files, and the changes will take effect when the Hadoop services are restarted.
It is crucial to remember that when the permission policies are changed, it is necessary to update the SLA configuration. Therefore, please update the configuration to avoid changes not being applied, resulting in security issues and unauthorized data access. As a result, it is strongly advised to follow the right approach for updating the SLA configuration to ensure the security and integrity of the Hadoop cluster system.
Examples of Service Level Authorization with Apache Hadoop
Service Level Authorization (SLA) is an essential component of Apache Hadoop since it ensures that the data stored in the Hadoop cluster is secure and only available to authorized employees.

Here are some SLA examples with Apache Hadoop:
- Hadoop Distributed File System (HDFS) File Access Control: The Hadoop Distributed File System (HDFS) is the core storage component of Hadoop, and it stores data in a distributed fashion. With SLA, access to HDFS files can be controlled to specified users or groups. In addition, individual files, folders, or the entire file system can have access control lists (ACLs) and permissions specified.
- MapReduce Job Access Control: MapReduce is the processing framework used in Hadoop for large-scale data processing. SLA can also be used to control access to MapReduce jobs. For example, jobs can be assigned to certain users or groups, and permissions can be assigned based on the type of access required, such as read, write, or execute.
- Control of Hive Table Access: Apache Hive is a data warehouse application that provides a SQL-like interface for querying Hadoop data. SLA can be used to control access to Hive tables. Individual tables, columns, or the entire database can have permissions configured, and access can be restricted to specified users or groups.
- Impala Query Access Control: Impala is a SQL-like interface for querying Hadoop data. SLA can be used to regulate access to Impala queries. For example, queries can be restricted to specific users or groups, and permissions can be adjusted according to the type of access required, such as read, write, or execute.
- Kerberos Authentication: Kerberos is a network authentication protocol that allows clients and servers in a network to communicate securely. It may be linked with Hadoop to enable SLA-based secure authentication and authorization. Kerberos authentication ensures that only authorized users have access to the Hadoop cluster and that unauthorized access or data breaches are prevented.
Finally, Service Level Authorization with Apache Hadoop is essential to data security and access management. SLA provides a strong and adaptable framework for managing access to Hadoop components, including HDFS, MapReduce, Hive, and Impala. It ensures that only authorized individuals have access to the data and protects against data breaches and unauthorized access to the Hadoop cluster.
Conclusion
- Service Level Authorization is an important part of Hadoop cluster security because it assures only authorized users can access the resources.
- It provides fine-grained access control to various Hadoop components and services based on user roles, groups, and permissions.
- Service Level Authentication improves overall Hadoop ecosystem security by prohibiting unauthorized access and lowering the risk of data breaches and theft.
- Organizations may maintain regulatory compliance, secure sensitive data and intellectual property, and reduce the risk of legal penalties by employing Service Level Authorization.
- Apache Ranger is a well-known Service Level Authorization tool that works well with Hadoop and offers centralized policy management, audit logging, and access control enforcement.
- Besides Apache Ranger, alternative technologies for Service Level Authorization in Hadoop clusters include Apache Sentry, Knox, and LDAP.
- It is critical to evaluate and update Service Level Authorization rules on a regular basis to ensure that they align with evolving business demands and conform to regulatory compliance criteria.
- Service Level Authorization should be viewed as an essential component of the overall Hadoop security strategy and applied with other security measures such as encryption, data masking, and firewall protection.