What is Spark Streaming?
Overview
Spark Streaming is an Apache Spark platform extension allowing for real-time streaming data processing. It enables developers to create fault-tolerant, scalable, high-throughput stream processing applications capable of handling massive amounts of data in real-time. Spark Streaming uses the Spark platform's capabilities to process data in mini-batches, resulting in low latency, high throughput, and the ability to manage complicated data processing workflows. Organizations may get useful insights from real-time data streams using Spark Streaming, allowing them to make educated business decisions and achieve a competitive advantage in their respective industries.
Introduction
Spark Streaming is a real-time data processing extension of the Spark API,, it is open source and is part of the Apache Spark ecosystem. It provides a scalable and fault-tolerant infrastructure for processing streaming data, allowing developers to create robust, high-performance applications capable of handling massive amounts of real-time data.
The Discretized Stream, or DStream, is the essential idea of Spark Streaming and depicts a succession of data arriving in real time. DStreams can be integrated with batch data processing utilizing Spark's core processing engine and processed using high-level operators such as map, filter, and reduce. Developers can use this to create complicated data processing processes that blend real-time and batch processing.
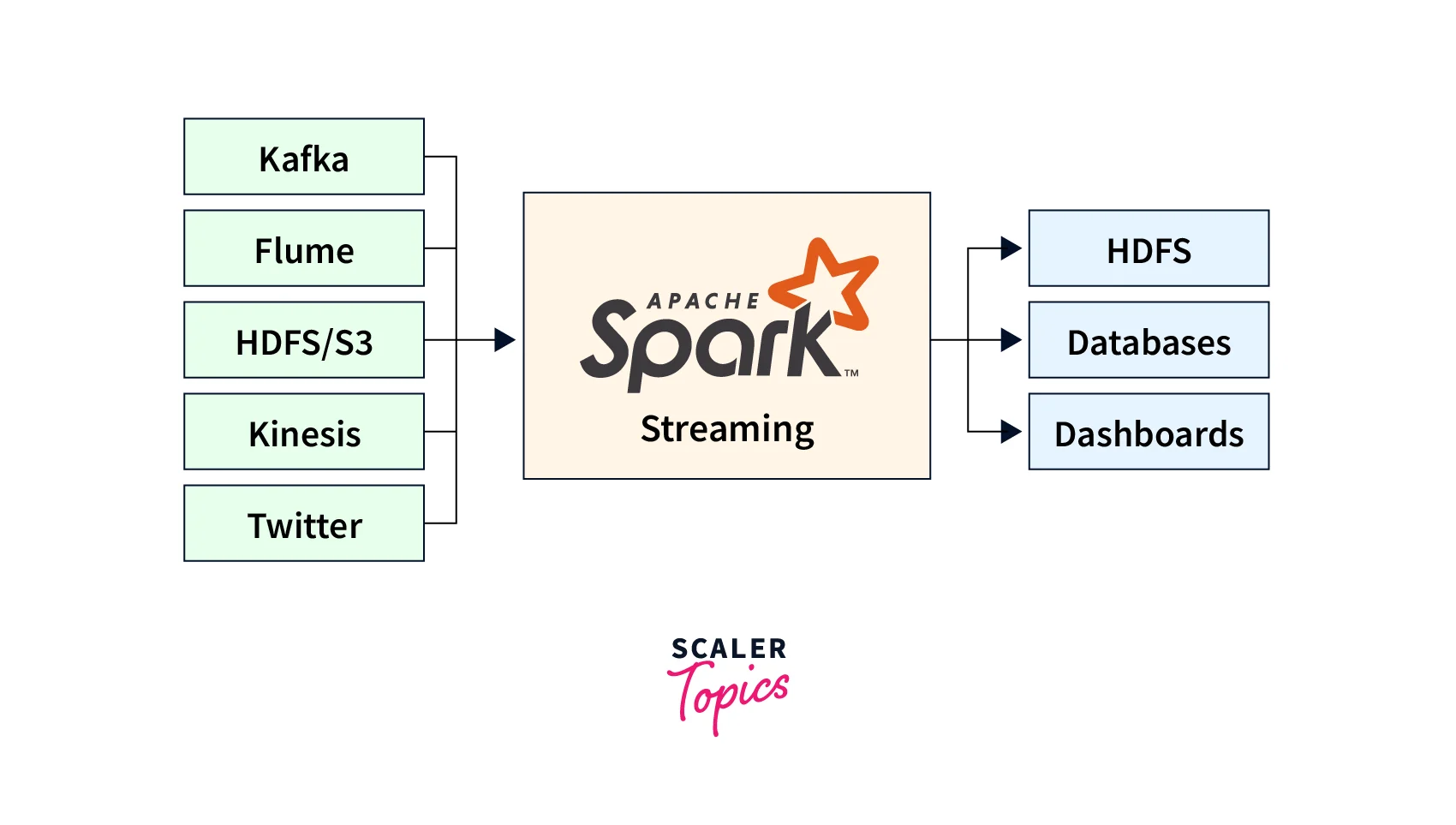
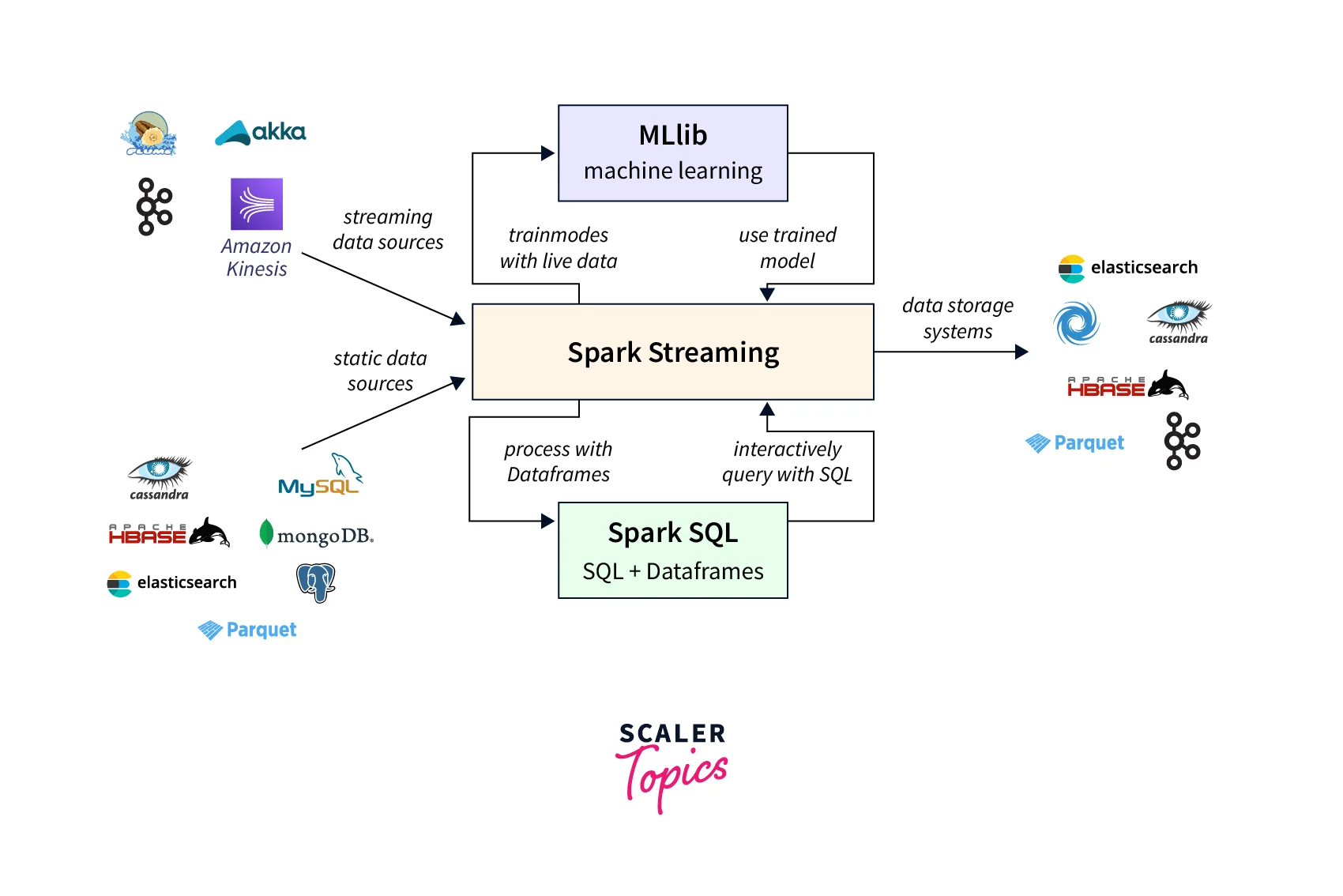
Spark Streaming accepts input from various sources, including Kafka, Flume, and HDFS, as well as bespoke sources via a flexible API. It also works with other Spark components like SQL and MLlib to provide a unified real-time and batch data processing platform.
One of the primary benefits of Spark Streaming is its scalability, which allows enterprises to handle massive volumes of data easily. It also provides fault tolerance and fast throughput, ensuring data processing is not hampered by system breakdowns.
Overall, Spark Streaming is a strong real-time data processing solution widely utilized in industries like finance, healthcare, and advertising, where real-time insights can provide a major competitive edge.
What is Spark Streaming?
Spark Streaming is a strong and adaptable framework for real-time data processing in the Apache Spark environment. It offers a unified framework for constructing complicated data processing processes, including real-time and batch processing.

In the financial services industry, the ability to collect and analyze huge volumes of real-time data can provide a competitive advantage. A financial services firm, for example, may need to monitor stock prices in real-time and make swift choices based on market patterns. Therefore, the organization may utilize Spark Streaming to ingest and process enormous amounts of stock price data in real time and use machine learning algorithms to spot trends and patterns.
Another application of Spark Streaming is in the sphere of healthcare. Hospitals and healthcare professionals create massive volumes of data in real-time, from patient records to medical gadgets. Healthcare professionals can use Spark Streaming to evaluate this data in real-time, detecting patterns and trends that might improve patient outcomes. Doctors, for example, can monitor patient vital signs in real-time and utilize machine learning algorithms to identify potential health hazards before they become urgent.
In addition to these examples, Spark Streaming is used in various industries, from advertising to manufacturing. This is because it provides a scalable, fault-tolerant framework for processing massive amounts of real-time data. Furthermore, it integrates seamlessly with other Spark components like SQL and MLlib.
Overall, Spark Streaming is a powerful tool for processing real-time data, and it is critical for organizations that need to make quick decisions based on current data. Because of its scalability and versatility, it is a popular choice for companies where real-time insights can provide a major competitive edge.
Need for Spark Streaming
In today's world, data is being generated at an unprecedented rate, and companies are trying to keep up with this data's volume, diversity, and velocity. Conventional batch processing techniques are no longer adequate for real-time data processing, and companies are looking for innovative ways to handle and analyze data in real-time. Spark Streaming comes into play here. Let us look at the various scenarios where Spark Streaming can be helpful.
- It provides a strong foundation for processing real-time data streams, allowing businesses to obtain insights from their data as it is generated. In addition, spark Streaming enables real-time data processing, ensuring that the insights obtained from the data are as current and relevant as possible.
- One of the key reasons for the need for Spark Streaming is the increasing volume of data created in real time. Data is being generated at an unprecedented rate in today's world, and organizations are seeking methods to harness this data to acquire insights that will help them make better decisions. Conventional batch processing approaches, designed to handle data in batches rather than in real time, could be better for processing real-time data.
- Furthermore, with the rise of the Internet of Things, the requirement for real-time data processing has become even more crucial in recent years (IoT). With IoT devices producing massive amounts of data in real-time, organizations want a method to manage and analyze this data as it is produced.
- Ultimately, the need for Spark Streaming stems from enterprises' increased need to process and analyze real-time data streams to get insights to help them make better decisions. Organizations can use Spark Streaming to process data in real-time, ensuring that the insights from the data are as current and relevant as possible.
Major Aspects of Spark Streaming
When working with this technology, it is critical to understand several fundamental characteristics of Spark Streaming. Let us look at the various characteristics of Spark Streaming:
- Spark Streaming employs a micro-batch processing approach, which means data is processed in small, discrete batches rather than as a continuous stream. This allows Spark to process massive amounts of data in real-time without overwhelming the machine.
- Second, Spark Streaming has built-in fault tolerance and scalability. As a result, it can recover from failures automatically and scale up or down to meet changing demands.
- Third, Spark Streaming supports various input sources, including Kafka, Flume, and Twitter. As a result, it can readily integrate with a wide range of data sources.
- Fourth, Spark Streaming contains several built-in operations for real-time data processing, such as map, filter, reduce, and join. Once data is processed, these processes can be utilized to change and manipulate it.
- Finally, Spark Streaming features machine learning and graph processing capability, making it an effective tool for studying and visualizing real-time data.
Understanding the fundamentals of Spark Streaming is critical for anyone working with real-time large data applications. Organizations can process and analyze enormous volumes of data in real time by utilizing the power of Spark Streaming, allowing for faster decision-making and more accurate insights.
Dstreams vs Structured Streaming
DStreams and Structured Streaming are both Spark stream processing frameworks, although they use different approaches to stream processing. DStreams are best suited for low-latency applications with small to medium loads, whereas Structured Streaming is better suited for high-latency applications with big loads.
Structured Streaming provides high-level APIs for ease of use, whereas DStreams enable additional control over processing logic. Both frameworks have advantages and disadvantages, and the unique requirements of the use case ultimately determine the choice between them.
Here are the main differences between DStreams and Structured Streaming in tabular format:
| Aspect | DStreams | Structured Streaming |
|---|---|---|
| Programming Model | Micro-batch processing model | Continuous processing model |
| Abstraction | RDDs (Resilient Distributed Datasets) | DataFrames and Datasets |
| Data Sources | Only supports basic input sources such as Kafka and sockets | Supports various input sources including Kafka, sockets, and more |
| Output Operations | Limited output operations such as print and saveAsTextFiles | Supports complex output operations such as aggregations and more |
| Latency | Higher latency due to micro-batch processing | Lower latency due to continuous processing |
| Fault Tolerance | Full fault tolerance through RDD lineage | Fault tolerance through checkpointing |
| APIs | Low-level APIs with more control over processing logic | High-level APIs for ease of use |
| Performance | Suitable for low-latency use cases with small to medium loads | Suitable for high-latency use cases with large loads |
Stream Processing Model in Spark
The processing of data streams is becoming increasingly crucial in the age of big data. As a result, the capacity to process data in real time has become a requirement for firms that want to stay ahead of the competition. Spark Streaming is a strong tool for real-time data processing, making it a popular choice for stream processing. Spark's stream processing model is built on the concept of micro-batch processing. The incoming data stream is separated into distinct batches in this paradigm and handled individually. Spark can process data in real-time because these batches are processed continuously.
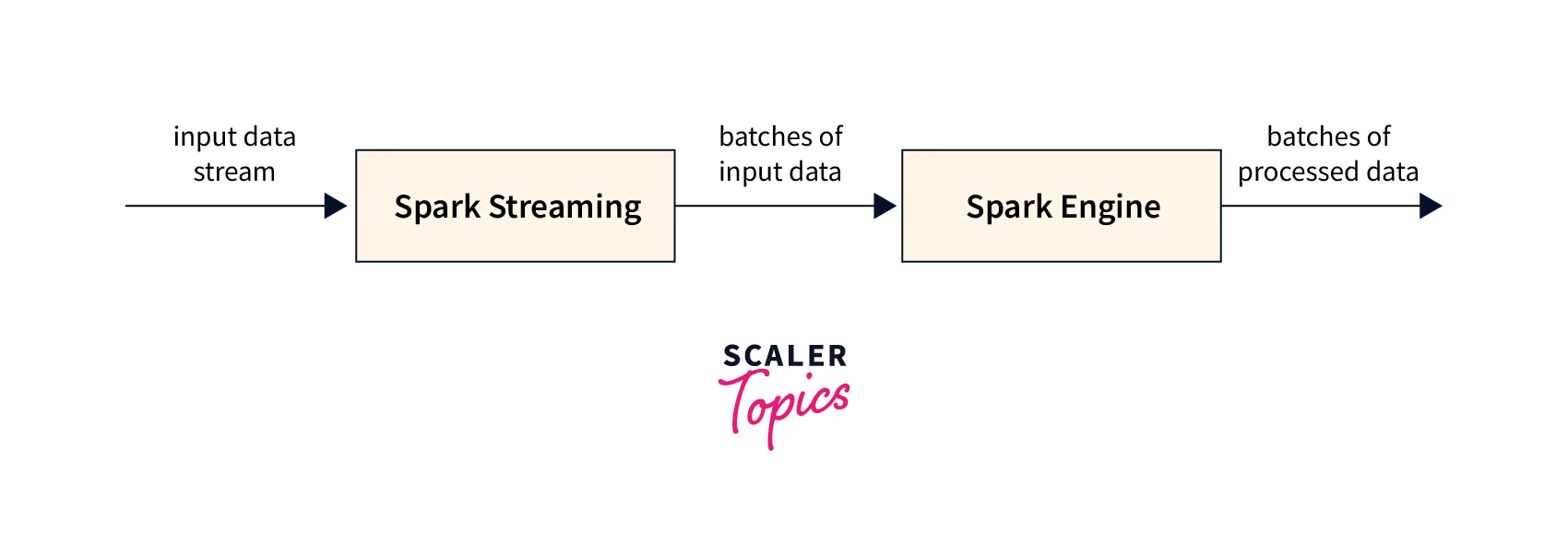
The micro-batch processing paradigm has several advantages over conventional stream processing approaches. Some of them are:
- One of the most important advantages is fault tolerance. If a batch fails to process correctly, Spark will retry the batch to ensure that all data is handled correctly.
- Another advantage of the micro-batch processing paradigm is its easy integration with batch processing. For example, data processed in real time can be saved in a batch processing system for later analysis.
- Ultimately, Spark's stream processing approach is a valuable tool for businesses that allows them to process data in real time. Its advantages over other stream processing approaches include fault tolerance and ease of interface with batch processing systems.
Source, Sink, and Output Modes
Spark Streaming is a frequently used stream processing platform in large data analytics. One of its primary strengths is its capacity to deal with diverse data sources, sinks, and output modes.
The input data streams that Spark Streaming processes are referred to as sources. Spark Streaming accepts data from various sources, including Kafka, Flume, HDFS, and socket streams. These sources capture real-time data for processing and can be linked to Spark Streaming.
On the other hand, Sinks are the destinations where Spark Streaming writes the processed data. Data can be written to various destinations, including HDFS, databases such as Cassandra, and external systems such as Kafka.
Spark Streaming output modes govern how to output data is written to sinks. In Spark Streaming, three output modalities are available:
- Complete mode: The complete updated result set is written to the sink in this manner. When the whole result set is required, this mode is handy.
- Update mode: The updated data is written to the sink in this mode. This mode is useful when changes to the result set are necessary.
- Append mode: Only new data is written to the sink in this mode. This mode is useful when new data is required, and current data should not be altered.
Retry and Fault Tolerance Semantics
Spark Streaming is a fault-tolerant stream processing solution allowing real-time data stream analytics. In streaming data processing, fault tolerance and retry techniques are critical. These techniques ensure that data processing continues even when there are errors.
- Spark Streaming enables fault tolerance via a micro-batch processing method. Each micro-batch is processed independently, which implies that if a fault happens during one batch's processing, it does not affect the processing of subsequent batches.
- Furthermore, through its RDD pedigree, Spark Streaming enables fault tolerance. In the event of a failure, the RDD lineage enables Spark Streaming to recompute missing data.
- In streaming data processing, retry techniques are also crucial. In the event of a job failure, Spark Streaming provides automatic retries. By configuring Spark Streaming correctly, failed batches can be re-executed automatically.
- Spark Streaming offers a variety of fault-tolerance semantics in addition to automated retries. At least once, at-most-once and exactly-once semantics are examples of these.
- At least once semantics ensure that each record is treated at least once, even if this means that some records are processed many times.
- In addition, although at-most-once semantics ensure that each record is only processed once, some records may be lost if a fault occurs.
- Finally, exactly-once semantics ensure each record is handled only once, preventing duplication or loss.
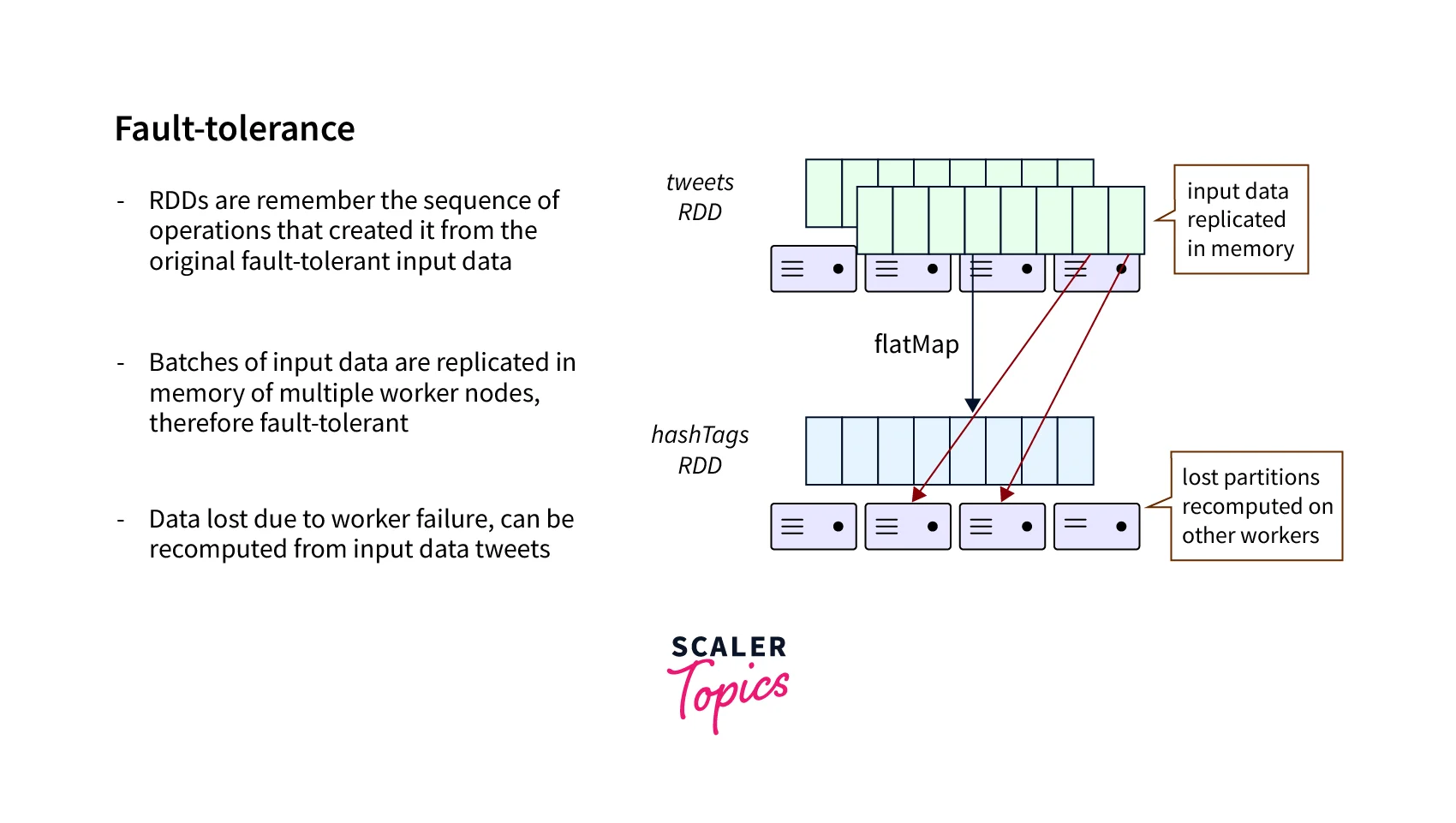
Overall, fault tolerance and retry mechanisms are critical components of the Spark Streaming processing architecture, guaranteeing that data processing is dependable and robust even when faults occur.
Window and Aggregate
Stream processing is an important part of Big Data analytics and is commonly used to handle massive amounts of data. This section will review two crucial Spark Streaming concepts: Window and Aggregate.
1. Stateful and Stateless Transforms
Transforms are functions that operate on input data to generate output data. Stateful transforms rely on past data states, whereas stateless transforms do not. The updateStateByKey() is an example of a stateful transform that can keep track of the state over many batches. On the other hand, a stateless transform is map(), which executes a simple transformation on each record independently.
2. Event Time and Windowing
Spark Streaming supports both sliding and tumbling windows.
a. Sliding Window
We can set the window size and the sliding interval using the sliding Window. For example, a sliding window of 10 seconds with a sliding interval of 5 seconds would compute the aggregate for every 5 seconds of data within the previous 10 seconds. On the other hand, the tumbling Window collects data in fixed, non-overlapping windows of a specific size.
b. Tumbling Window
Records in event time processing are given a timestamp that indicates when they occurred. Spark Streaming processes data by default based on the processing time when the record was processed. Yet, event time processing allows us to manage out-of-order and late data.
3. Watermarking your Windows
A watermark is a time delay that sets the maximum time that records can be evaluated for a window. The watermark is used to handle late data and verify the accuracy of the results. For example, if the watermark is set to 10 minutes, any records received more than 10 minutes after the Window's expiration are ignored. This ensures that the aggregates are accurate and not affected by late data.
Performance Tuning
As with any distributed computing system, performance is important to consider to achieve the best outcomes. This section will review the top three strategies to optimize Spark Streaming performance in Big Data.
1. Reducing the Batch Processing Times
- The time it takes to process each batch is one of the most important factors in Spark Streaming performance. You can enhance the frequency with which data is processed and evaluated by minimizing batch processing time. This is accomplished by optimizing the code and reducing how much data must be handled. Avoiding needless transformations, adopting efficient data structures, and parallelizing computations are some techniques for lowering batch processing time.
2. Setting the Right Batch Interval
- The batch interval specifies how long Spark Streaming waits before processing the next batch of data. Choosing the proper batch interval is crucial for achieving peak performance. A shorter batch interval results in more frequent data processing but may also result in more overhead and lower throughput. A larger batch interval, on the other hand, may minimize overhead but result in the delayed data processing. The ideal batch interval is determined by the use case and the amount of data being processed.
3. Memory Tuning
- Memory is another crucial aspect of Spark Streaming speed. Optimizing memory utilization can reduce overhead while increasing data processing speed and throughput. Some memory optimization tips are increasing the driver and executor RAM, configuring the garbage collector, and tuning the serialization and deserialization settings.
In summary, performance optimization in Spark Streaming includes minimizing batch processing times, determining the optimal batch interval, and optimizing memory. Addressing these factors, you can achieve faster and more efficient processing of real-time data streams.
Examples of Spark Streaming
Spark Streaming is a sophisticated technology that allows for real-time data stream processing. These are some instances of how Spark Streaming can be applied in different industries:
1. Social Media Analytics: Real-time data generated by social media sites such as Twitter. Businesses can use Spark Streaming to evaluate this data and acquire insights into the current customer trends and sentiments. Companies, for example, can monitor tweets about their brand or products and evaluate the tweet's mood to understand customer opinions better.
2. Fraud Detection: Spark Streaming can be used to detect fraud in financial transactions in real-time. It can process many transaction data in real-time and detect anomalies or suspicious transactions. This can assist financial organizations in preventing fraud and protecting their consumers.
3. Internet of Things (IoT) Applications: The Internet of Things (IoT) generates vast amounts of data in real-time. This data can be processed using Spark Streaming to gain real-time insights. In the industrial business, for example, sensors can monitor equipment and detect faults in real-time, allowing maintenance crews to handle issues before they become critical.
4. Traffic Management: Spark Streaming can also be used to manage traffic in real-time. It can assess traffic trends and deliver real-time insights to city planners by processing data from numerous sources, such as traffic sensors, GPS devices, and social media platforms. This can assist them in making an educated judgment about traffic management and reducing road congestion.
Finally, Spark Streaming can be applied in various industries to process and analyze data in real-time. Because of its ability to manage enormous volumes of data in real-time, it is a useful tool for organizations seeking real-time insights and making educated decisions.
Advantages and Disadvantages of Spark Streaming
Spark Streaming is a real-time data processing framework that processes and analyses huge amounts of streaming data. It does, however, have its own set of benefits and drawbacks, which are mentioned below:
Advantages of Spark Streaming:
- High-Speed Processing: Spark Streaming processes data in real-time and returns results in seconds. It can handle high-speed data streams and scale up or down in response to demand.
- Fault-Tolerant: Spark Streaming is a fault-tolerant framework capable of recovering from faults without losing data. It also allows you to create checkpoints and recover from errors.
- Integration with Apache Spark: Because Spark Streaming is built on top of Apache Spark, it can take advantage of all of Apache Spark's features and benefits.
- Variability: Spark Streaming may interact with various data sources, including Kafka, Flume, HDFS, and others. This makes it a versatile platform for real-time data processing.
- Scalability: Spark Streaming can scale horizontally and vertically depending on the requirements. It can handle massive amounts of data and run on a cluster of devices.
Disadvantages of Spark Streaming:
- Complexity: Spark Streaming is a sophisticated framework that necessitates a thorough understanding of the underlying concepts and technology. It also necessitates extensive knowledge of programming languages such as Scala or Python.
- Resource-Intensive: To handle massive volumes of data, Spark Streaming can be resource-intensive, requiring a lot of memory and computing power.
- Latency: Because Spark Streaming involves latency, processing and analyzing the data may take a few seconds or minutes.
- Overhead: Some overheads are associated with Spark Streaming, such as the requirement to manage numerous threads, manage state, and schedule activities.
- Data Streaming Limitations: Spark Streaming is ideally suited for real-time data processing. You may need to utilize a different tool or framework to process historical or batch data.
Conclusion
- Spark Streaming is a powerful technology for large data analytics that allows for real-time data processing. Its capacity to manage continuous streams of data and its connection with other Spark components allows enterprises to extract insights and make informed decisions in real-time.
- One of the primary advantages of Spark Streaming is its low latency, which enables near real-time data processing. This is crucial for use cases like fraud detection, market trading, and IoT data processing, where even minor delays can have serious effects.
- This is crucial for use cases like fraud detection, market trading, and IoT data processing, where even minor delays can have serious effects.
- Furthermore, the fault-tolerance properties of Spark Streaming ensure that node failures or network issues do not hamper data processing.
- Spark Streaming's compatibility with other Spark components increases its utility as a large data analytics tool. Organizations can use Spark SQL, Spark MLlib, and other Spark components to perform additional analysis on data produced by Spark Streaming.
- It should be noted that Spark Streaming may only be the optimal choice for some real-time data processing applications. Its micro-batch processing technique may result in greater overhead costs and may not be suitable for use cases that require extremely low latencies.