How to set up Integration of Spark Streaming with Kafka?
About Spark Streaming
Apache Spark offers Spark Streaming with Kafka as its extension with the central application API. Data could be extracted from various sources like Kinesis, Kafka, and TCP sockets. With the help of complex algorithms, the data could be processed via high-level functions including join, map, reduce, as well as window. For an amplified level of data abstraction, Spark streaming implements the usage of discretized data stream popular as DStream extending a continuous data stream.
Spark Streaming is a high-throughput, scalable, and fault-tolerant streaming data processing system that could support both streaming and batching workloads. For real-time data processing, Spark offers this Spark streaming with Kafka extension of the core Spark API from various sources like Flume, Amazon Kinesis, Kafka, etc. Data is processed and pushed to systems such as Kafka, live dashboards, databases, etc.
The live data stream is input in Spark Streaming which is split into batches. Then with the Spark engine, these batches of data are processed for producing the final batch result stream. This offers versatile data integrations through various data sources with Spark Streaming with Kafka.
The below illustration represents this in a more detailed format:
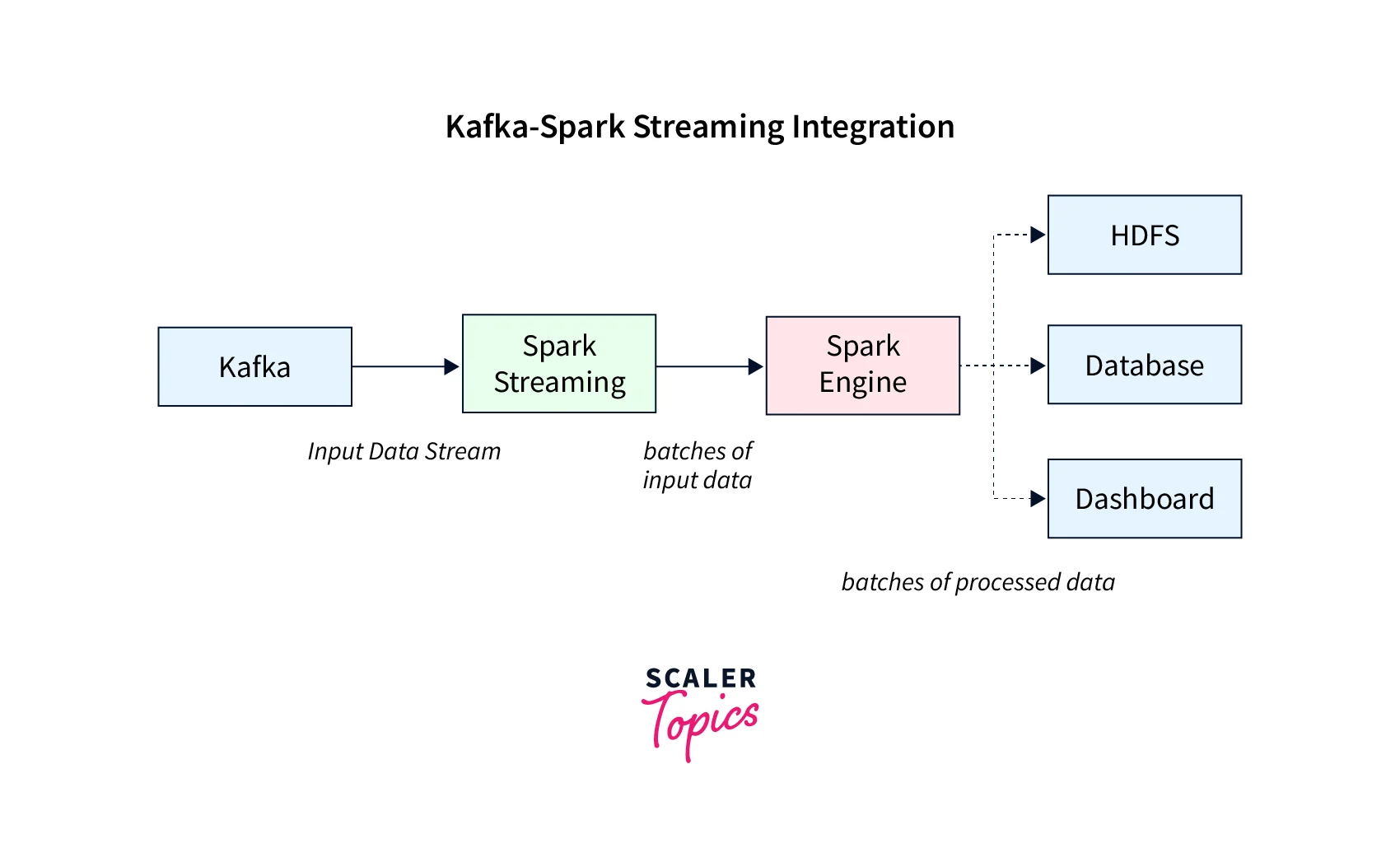
Why are Spark Streaming and Kafka Integration Important?
We have been talking about Spark Streaming with Kafka and how it is a high-throughput, scalable, and fault-tolerant streaming data processing system which could support both streaming and batching workloads.
The below representation depicts how Spark Streaming with Kafka Integration works as a data pipeline as shown:
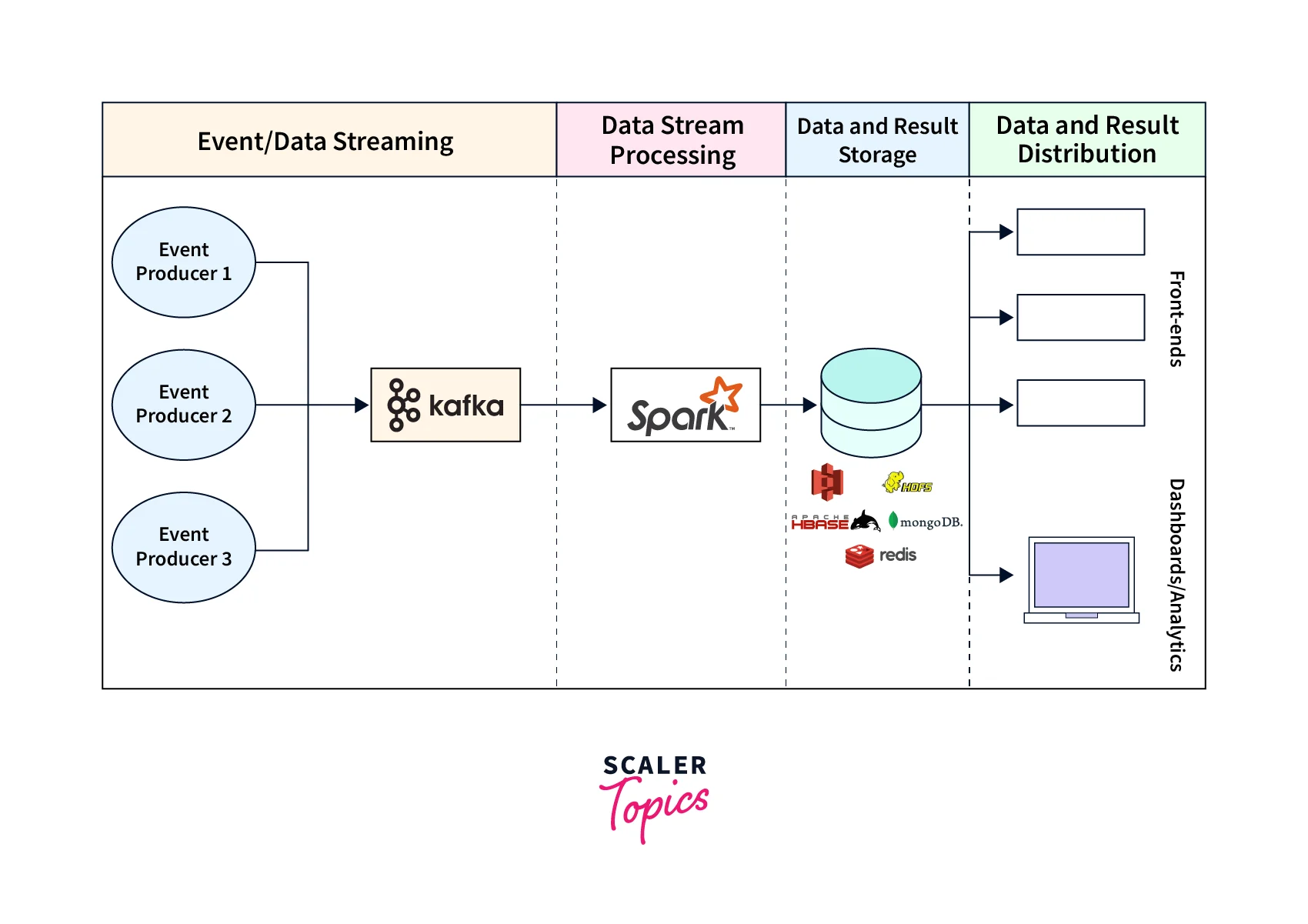
Various benefits are offered when it comes to implementing Spark Streaming with Kafka Integration:
- Capability that users get to read the data records from both single or multiple Kafka topics.
- With this integration between Spark Streaming with Kafka Integration, users ensure minimum data loss from Spark Streaming.
- Data received from Kafka is synchronously saved for an easy recovery.
- Users experience high throughput, flexibility, high scalability, and fault tolerance.
Integration with Spark
Apache Kafka can be defined as a potential messaging and integration tool offering spark streaming. Kafka is like a central hub where the real-time data streams are processed via the complex algorithms in Spark Streaming. This processed data is then published into another Kafka topic, dashboards, databases, or HDFS as the Spark streaming is tuned for after the data is processed.
The berepresentationtion shows how conceptually the integraton with spark works:
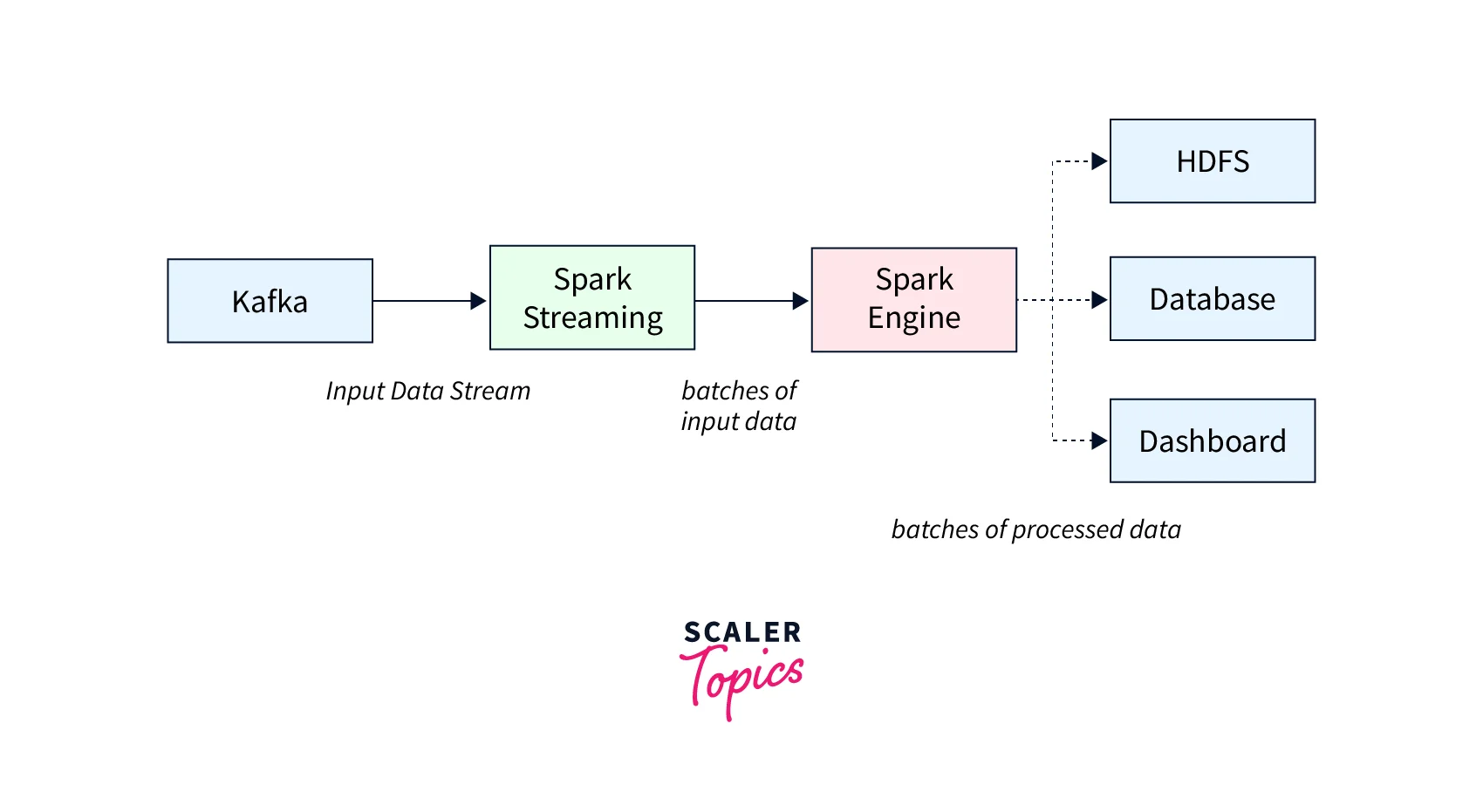
Kafka-Spark APIs
We shall now be discussing the three Kafka-Spark APIs which are essential for setting up Apache Spark Streaming with Kafka Integration:
- StreamingContext API
- SparkConf API
- KafkaUtils API
SparkConf API
The SparkConf API helps users to learn about the Spark application's configuration. The Spark parameters can be set as the key-value pairs that usually takes the priority over other system properties. A SparkConf object could also be created via the new SparkConf(). This helps you to load values from any of the spark.* Java system properties available in your system or application.
The SparkConf class offers the below-given methods −
-
setAppName: The method is of string name format. With this method, users can set the application name as per the users' application.
-
get: The method is of string key format. With this method, users can get the key.
-
set: The method is of string key and string value format. With this method, users can set the configuration variable.
-
remove: The method is of string format. With this method, users can remove the key from the configuration.
StreamingContext API
The StreamingContext API is the crucial entry point for establishing the Spark Streaming functionality. DStreams could be created from multiple data sources via the methods offered by this API.
This StreamingContext API could be built via
- either offering an Apache Spark master URL along with an appName,
- or with the help of the org.apache.spark.SparkConf configuration,
- or via an existing org.apache.spark.SparkContext.
- You can access the associated SparkContext via context.sparkContext.
Once the DStreams have been built and transformed, the spark streaming computation is ready to be started or stopped as per the use case. This could be done via the context. start() or context. stop() methods for starting and stopping the computation respectively.
Allowing the current thread to wait for use can implement the context.awaitTermination() for terminating the context by either stop() or an exception.
KafkaUtils API
Users can connect the Kafka clusters to the Apache Spark streaming via the KafkaUtils API. With the KafkaUtils API, you can easily set the Spark Streaming with Kafka Integration. You also get a crucial method widely popular as createStream. With the createStream method, an input stream can be easily created which helps to pull the messages from the Kafka broker.
Another known method, offered by the KafkaUtils API is the createDirectStream. With the createDirectStream method, users can create an input stream where the messages could easily be fetched directly from the Kafka broker without having to implement a receiver. This way the stream guarantees, that each message from Kafka participates only once in the conversion.
The following parameters are found in the KafkaUtils API:
-
ssc: Used for defining the StreamingContext object.
-
zkQuorum: Could be implemented for mentioning the Zookeeper Quorum.
-
groupId: Resonates as the Group ID for a particular consumer.
-
Topic: Users can return the topic map for usage.
-
storage level: For storing the received objects, this parameter could be implemented.
Spark Streaming with Kafka Integration Steps
Let us quickly jump into understanding how we can do Spark Streaming with Kafka having Integration. There are two ways in which you can configure and set up Spark Streaming for receiving the data from Apache Kafka Integration.
- Through the implementation of Receivers along with Apache Kafka’s high-level API.
- Without implementing the Receivers. There are different programming models for both the approaches, such as performance characteristics and semantics guarantees.
Let's quickly throw light into each approach and see which suits our requirements.
Through the implementation of Receivers along with Apache Kafka’s high-level API
In this approach, users need to implement the Receiver to start receiving the data. This could easily be done via the Apache Kafka high-level consumer API. In addition, the Spark executor is where the data is stored. After jobs could be launched and executed to start the data processing by the Apache Kafka and Spark Streaming process.
- It has also been seen that the receiver-based approach could also lead to data loss during failures under the configuration set as default.
- To combat this failure, its recommended to ensure write-ahead logs additionally in Kafka and Spark Streaming. This makes sure that no data is lost.
- The data gets saved into write-ahead logs in Kafka synchronously over a distributed file system. Hence, if needed the data could also be recovered.
- In addition, let us see how we could implement the Receiver-Based Approach in the Kafka and Spark Streaming systems.
Step 1: Linking
Users can start by linking the Kafka Spark streaming system with the below-mentioned artifact. It is recommended to use SBT/Maven project definitions for Scala or Java-based applications.
For Python applications, users can add the above-mentioned libraries as well as the dependencies while deploying their Python systems.
Step 2: Programming
Now, users can start creating the input DStream in the Spark streaming application program by importing the KafkaUtils.
Variations of createStream from the KafkaUtils API cud be implemented to define the key and value classes with their complementary decoder classes.
Step 3: Deployment
As we know, the spark-submit command is used for launching any application for any Spark application. While there is a slight difference in how the same is being done for Scala or Java systems as well as Python applications.
For projects that lack the SBT/Maven project management, users can implement the –packages spark-streaming-Kafka-0-8_2.11 along with the interlinked dependencies. This could directly be added to the spark-submit command for the Python applications.
The JAR for the Maven artifact could also be downloaded as the spark-streaming-Kafka-0-8-assembly via the Maven repository. Lastly, the same could be added as -jars in the spark-submit command.
Without implementing the Receivers based Approach:
In this Receiver-Less Approach, also widely popular as the "Direct" approach, the end-to-end is strongly guaranteed. Kafka is periodically queried for the latest offsets for each topic as well as the partition. This approach is different as no receiver is getting utilized for receiving the data. The offset range is also defined for each batch. To read the specific offset ranges from Kafka, an easy consumer API could be utilized, once the data processing jobs are launched. This acts similarly to how the files are read from a file system.
Let us deep dive into learning how this Direct approach is implemented in the Kafka and Spark streaming approach.
Step 1: Linking This approach is only supported for the Scala or Java application, where users could link the SBT/Maven project with the below-given artifacts:
Step 2: Programming
Users can create the input DStream via importing the KafkaUtils API as shown in the below-mentioned spark streaming application program:
Users must explicitly define either the metadata.broker.list or bootstrap.servers in the Kafka parameters. By default, it considers the latest offset for consumption. But users can configure for consuming the smallest offset by setting it via the configuration auto.offset.reset in Kafka parameters. Users can read from the arbitrary offset when it uses other variations of KafkaUtils.createDirectStream. Users can opt for updating the Zookeeper on its own. By this, the Zookeeper-based Kafka monitoring tools could be utilized for showing the progress of the Spark streaming application.
For accessing the Kafka offsets, users can implement the following program, for offsets to be consumed for each batch.
Step 3: Deployment
The deployment process is the same as the above-studied Receiver-Based Approach.
Manual Spark Streaming with Kafka Integration Limitations
So far we studied how users can easily set up Spark Streaming with Kafka Integration. The structured methodology with an easy-to-implement step-by-step guide helps users to integrate both Spark Streaming and Kafka Integration quite seamlessly.
But we do need to understand certain limitations offered if users are relying on a manual approach for Spark Streaming and Kafka Integration process:
- One needs to monitor the commands executed during the manual Spark Streaming with Kafka Integration. There still could be chances of inconsistencies while the script is getting executed.
- You need people with strong technical knowledge so that they can understand as well as implement the basic commands for manually setting up the Spark Streaming with Kafka Integration.
- The spark inter-node communications need to be manually taken care of, even after the entire Spark Streaming and Kafka Integration is simply established via executing a script.
- There is a big question regarding the scalability and effective specification of datasets with the data being exponentially growing.
As seen above, these limitations due to the manual Spark Streaming with Kafka Integration could be effectively resolved via automation strategies.
Conclusion
- Spark Streaming is a high-throughput, scalable, and fault-tolerant streaming data processing system which could support both streaming and batching workloads. For real-time data processing, Spark offers this Spark streaming extension of the core Spark API from various sources like Flume, Amazon Kinesis, Kafka, etc.
- With the createStream method, an input stream can be easily created which helps to pull the messages from the Kafka broker.
- With the KafkaUtils API, you can easily set the Spark Streaming with Kafka Integration. You also get a crucial method widely popular as createStream.
- The SparkConf API helps users to learn about the Spark application's configuration. The Spark parameters can be set as the key-value pairs that usually takes priority over other system properties.