Speech Recognition in AI
Overview
Speech recognition is one technique that has advanced significantly in the field of artificial intelligence (AI) over the past few years. AI-based speech recognition has made it possible for computers to understand and recognize human speech, enabling frictionless interaction between humans and machines. Several sectors have been transformed by this technology, which also has the potential to have a big impact in the future.
Introduction
One of the most basic forms of human communication is speech. It serves as our main form of thought, emotion, and idea expression. The capacity of machines to analyze and comprehend human speech has grown in significance as technology develops. AI research in the area of speech recognition aims to make it possible for machines to understand and recognize human speech, enabling more efficient and natural communication.
Today, speech recognition in AI has numerous applications across various industries, from healthcare to telecommunications to media and marketing. The ability to recognize and interpret human speech has opened up new possibilities for machine-human interaction, enabling machines to perform tasks that were previously only possible through manual input. As technology continues to advance, we can expect to see even more exciting applications in the future.
What is Speech Recognition in AI?
Speech recognition is the process of identifying a human voice. Typically, businesses create these programs and integrate them into various hardware devices to identify speech. When the program hears your voice or receives your order, it will respond appropriately.
Numerous businesses create software that recognizes speech using cutting-edge technologies like artificial intelligence, machine learning, and neural networks. The way individuals utilize hardware and electrical devices has been changed by technologies like Siri, Amazon, Google Assistant, and Cortana. They include smartphones, devices for home security, cars, etc.
Remember that voice recognition and speech recognition are not the same. Speech recognition takes an audio file of a speaker, recognizes the words in the audio, and converts the words into text. Voice recognition, in contrast, only recognizes voice instructions that have been pre-programmed. The conversion of voice into text is the only similarity between these two methods.
How does Speech Recognition in AI Work?
- Recording: The voice recorder that is built into the gadget is used to carry out the first stage. The user's voice is kept as an audio signal after being recorded.
- Sampling: As you are aware, computers and other electronic gadgets use data in their discrete form. By basic physics, it is known that a sound wave is continuous. Therefore, for the system to understand and process it, it is converted to discrete values. This conversion from continuous to discrete is done at a particular frequency.
- Transforming to Frequency Domain: The audio signal's time domain is changed to its frequency domain in this stage. This stage is very important because the frequency domain may be used to examine a lot of audio information. Time domain refers to the analysis of mathematical functions, physical signals, or time series of economic or environmental data, concerning time. Similarly, the frequency domain refers to the analysis of mathematical functions or signals concerning frequency, rather than time.
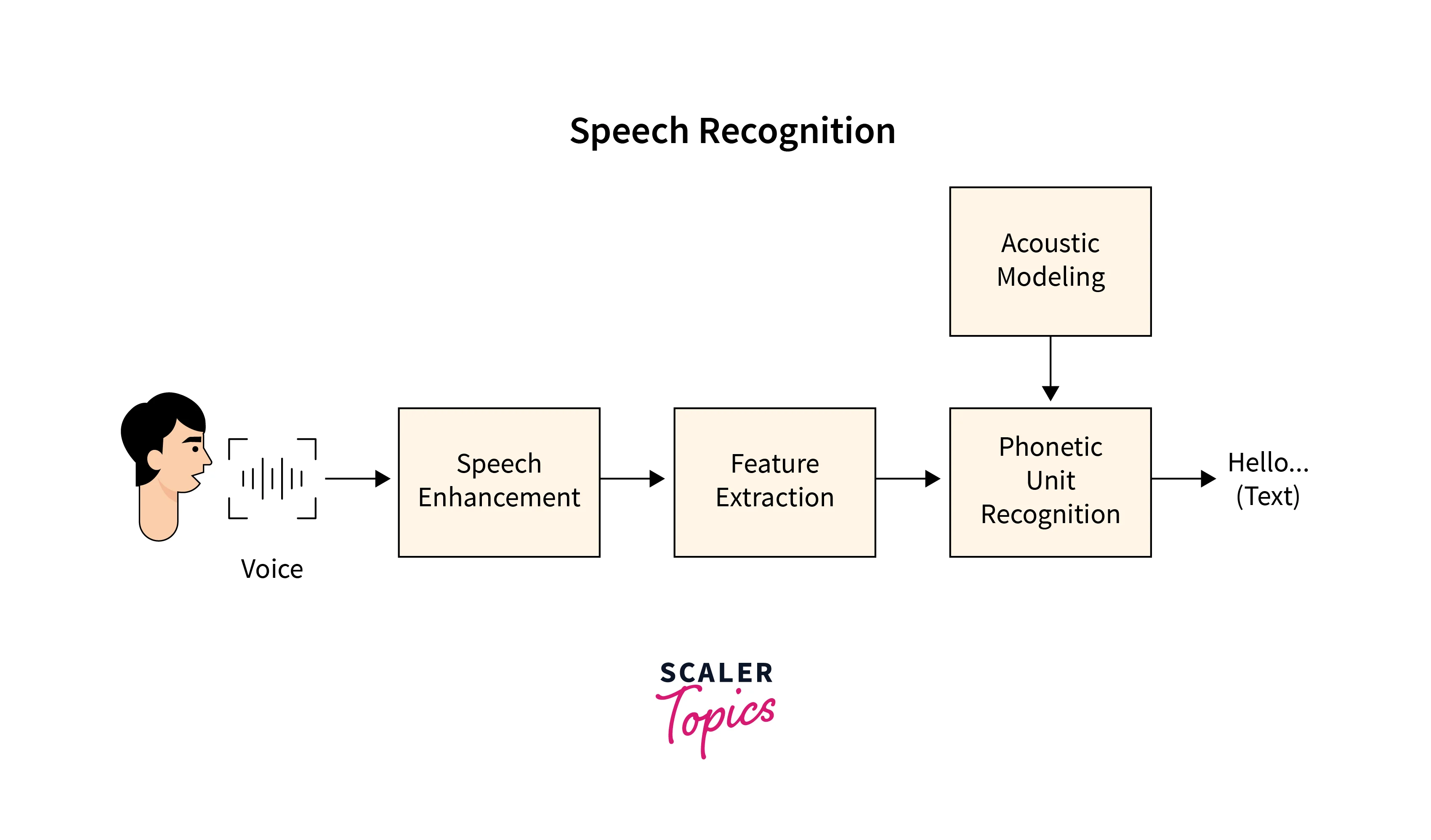
-
Information Extraction from Audio: Each voice recognition system's foundation is at this stage. At this phase, the audio is transformed into a vector format that may be used. For this conversion, many extraction methods, including PLP, MFCC, etc., are applied.
-
Recognition of Extracted Information: The idea of pattern matching is applied in this step. Recognition is performed by taking the extracted data and comparing it to some pre-defined data. Pattern matching is used to accomplish this comparing and matching. One of the most popular pieces of software for this is Google Speech API.
Speech Recognition AI and Natural Language Processing
Speech recognition AI and natural language processing (NLP) are two closely related fields that have enabled machines to understand and interpret human language. While speech recognition AI focuses on the conversion of spoken words into digital text or commands, NLP encompasses a broader range of applications, including language translation, sentiment analysis, and text summarization.
One of the primary goals of NLP is to enable machines to understand and interpret human language in a way that is similar to how humans understand language. This involves not only recognizing individual words but also understanding the context and meaning behind those words. For example, the phrase "I saw a bat" could be interpreted in different ways depending on the context. It could refer to the animal, or it could refer to a piece of sporting equipment.
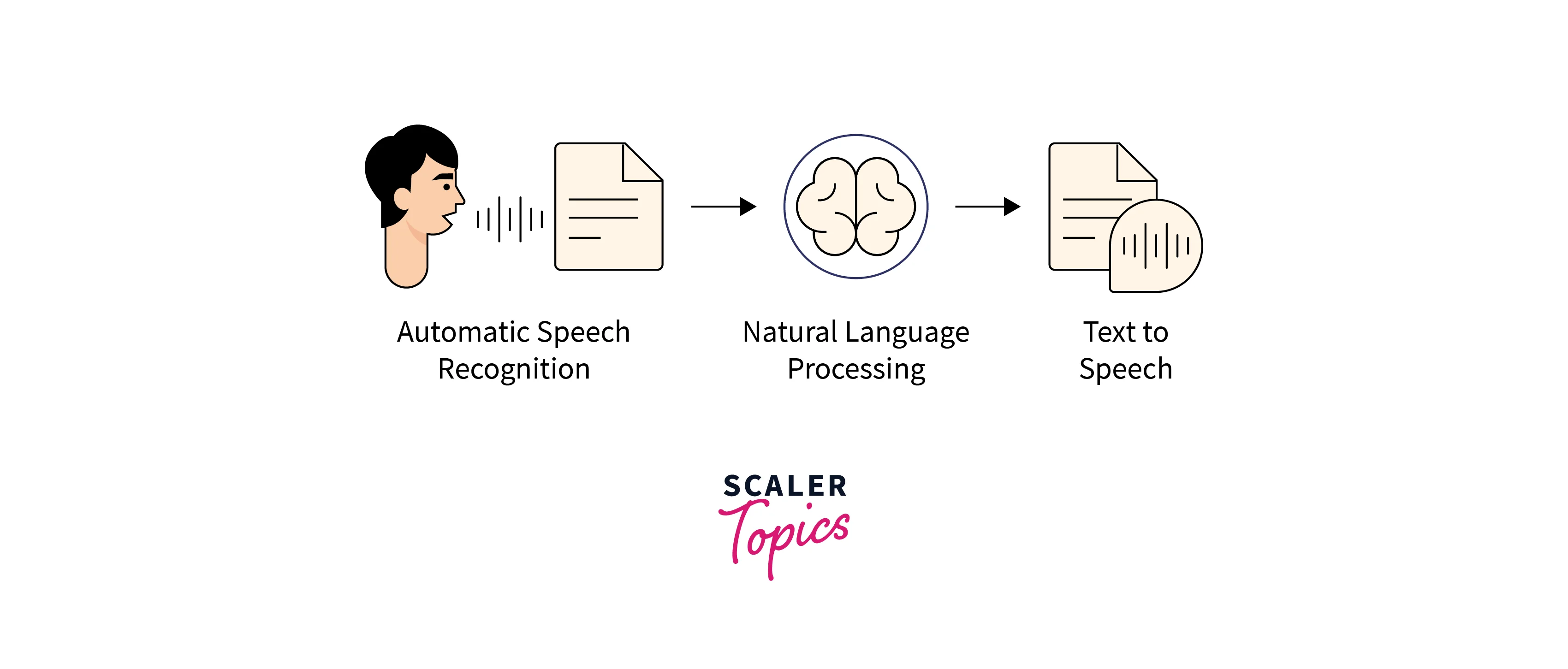
Speech recognition AI is a subset of NLP that focuses specifically on the conversion of spoken words into digital text or commands. To accomplish this, speech recognition AI systems use complex algorithms to analyze and interpret speech patterns, mapping them to phonetic units and creating statistical models of speech sounds.
Some of the techniques used in AI for speech recognition are:
- Hidden Markov Models (HMMs): HMMs are statistical models that are widely used in speech recognition AI. HMMs work by modelling the probability distribution of speech sounds, and then using these models to match input speech to the most likely sequence of sounds.
- Deep Neural Networks (DNNs): DNNs are a type of machine learning model that is used extensively in speech recognition AI. DNNs work by using a hierarchy of layers to model complex relationships between the input speech and the corresponding text output.
- Convolutional Neural Networks (CNNs): CNNs are a type of machine learning model that is commonly used in image recognition, but have also been applied to speech recognition AI. CNNs work by applying filters to input speech signals to identify relevant features.
Some recent advancements in speech recognition AI include:
- Transformer-based models: Transformer-based models, such as BERT and GPT, have been highly successful in natural language processing tasks, and are now being applied to speech recognition AI.
- End-to-end models: End-to-end models are designed to directly map speech signals to text, without the need for intermediate steps. These models have shown promise in improving the accuracy and efficiency of speech recognition AI.
- Multimodal models: Multimodal models combine speech recognition AI with other modalities, such as vision or touch, to enable more natural and intuitive interactions between humans and machines.
- Data augmentation: Data augmentation techniques, such as adding background noise or changing the speaking rate, can be used to generate more training data for speech recognition AI models, improving their accuracy and robustness.
Use Cases of Speech Recognition AI
Speech recognition across a wide range of fields and applications, artificial intelligence is employed as a commercial solution. AI is enabling more natural user interactions with technology and software, with higher data transcription accuracy than ever before, in everything from ATMs to call centres and voice-activated audio content assistants.
- Call centres: One of the most common applications of speech AI in call centres is speech recognition. Using cloud models, this technology enables you to hear what customers are saying and respond properly. The use of voice patterns as identification or permission for access solutions or services without relying on passwords or other conventional techniques or models like fingerprints or eye scans is also possible with speech recognition technology. By doing this, business problems like lost passwords or compromised security codes can be resolved.
- Banking: Speech AI applications are being used by banking and financial institutions to assist consumers with their business inquiries. If you want to know your account balance or the current interest rate on your savings account, for instance, you can ask a bank. As a result, customer support agents may respond to inquiries more quickly and provide better service because they no longer need to conduct extensive research or consult cloud data.
- Telecommunications: Models for speech recognition technology provide more effective call analysis and management. Providing better customer service enables agents to concentrate on their most valuable activities. Consumers may now communicate with businesses in real-time, around-the-clock, via text messaging or voice transcription services, which improves their overall experience and helps them feel more connected to the firm.
- Healthcare: Speech-enabled In the telecommunications sector, AI is a technology that is growing in popularity. Models for speech recognition technology provide more effective call analysis and management. Providing better customer service enables agents to concentrate on their most valuable activities.
- Media and marketing: Speech recognition and AI are used in tools like dictation software to enable users to type or write more in a shorter amount of time. In general, copywriters and content writers may transcribe up to 3000–4000 words in as little as 30 minutes. Yet accuracy is a consideration. These tools cannot ensure 100% error-free transcription. Yet, they are quite helpful in assisting media and marketing professionals in creating their initial draughts.
Challenges in Working with Speech Recognition AI
Working with speech AI presents various difficulties.
Accuracy
Today, accuracy includes more than just word output precision. The degree of accuracy varies from case to case, depending on various factors. These elements—which are frequently tailored to a use case or a specific business need—include:
- Background noise
- Punctuation placement
- Capitalization
- Correct formatting
- Timing of words
- Domain-specific terminology
- Speaker identification
Data Security and Privacy
Concerns regarding data security and privacy have significantly increased over the past year, rising from 5% to 42%. That might be the outcome of more daily interactions occurring online after the coronavirus pandemic caused a surge in remote work.
Deployment
Voice technology, or any software for that matter, needs to be easy to deploy and integrate. Integration must be simple to perform and secure, regardless of whether a business needs deployment on-premises, in the cloud, or embedded. The process of integrating software can be time-consuming and expensive without the proper assistance or instructions. To circumvent this adoption hurdle, technology vendors must make installations and integrations as simple as feasible.
Language Coverage
There are gaps in the language coverage of several of the top voice technology companies. English is covered by the majority of providers, but when organizations wish to employ speech technology, the absence of language support creates a hurdle to adoption.
Even when a provider does offer more languages, accuracy problems with accent or dialect identification frequently persist. What occurs, for instance, when an American and a British person are speaking? Which accent type is being used? The issue is resolved by universal language packs, which include a variety of accents.
Conclusion
- For commercial solutions, speech recognition enables computers, programs, and software to understand and convert spoken word input into text.
- The speech recognition model works by analysing your voice and language using artificial intelligence (AI), understanding the words you are speaking, and then accurately reproducing those words as model content or text data on a screen.
- Speech recognition in AI works by converting spoken words into digital signals that can be analyzed and interpreted by machines.
- This process involves several steps, including signal processing, feature extraction, acoustic modeling, language modeling, and decoding.
- Speech recognition AI is closely related to natural language processing (NLP). NLP involves the ability of machines to understand and interpret human language, enabling them to perform tasks such as text summarization, sentiment analysis, and language translation.
- Speech recognition AI is a subset of NLP that focuses on the conversion of spoken words into digital text or commands.
- Working with speech AI presents various difficulties. As an illustration, both technology and the cloud are recent and evolving quickly. As a result, it can be difficult to anticipate with any degree of accuracy how long it will take a company to develop a speech-enabled device.
- Speech recognition AI has the potential to transform the way we communicate with machines and has numerous applications across various industries.
FAQs
Q. How does speech recognition work?
A. Speech recognition works by using algorithms to analyze and interpret the acoustic signal produced by human speech, and then convert it into text or other forms of output. Here is a general overview of the process:
- Pre-processing: The incoming audio signal is first processed to remove noise and enhance the signal quality. This may involve filtering out unwanted frequencies, adjusting the volume levels, or normalizing the audio to a standard format.
- Feature Extraction: The processed audio signal is then broken down into smaller, more manageable pieces called "features." These features represent the frequency content and other characteristics of the speech.
- Acoustic Modeling: In this step, a statistical model of the speech signal is created using machine learning techniques. This model takes the feature vectors as input and produces a set of probabilities over a predefined set of linguistic units (phonemes, words, or sentences).
- Language Modeling: Once the acoustic model has been created, a language model is built. This model uses statistical analysis of language to predict the probability of a particular word or sentence based on its context within a larger body of text.
- Decoding: In this step, the acoustic and language models are combined to determine the most likely sequence of words or sentences that match the input audio signal. This process is called decoding.
- Post-processing: Finally, the output of the speech recognition system is post-processed to correct errors and improve the quality of the output. This may involve applying language-specific rules to correct grammar, punctuation, or spelling errors.
Q. What is the purpose of speech recognition AI?
A. The purpose of speech recognition AI is to enable computers and other devices to understand and process human speech. This has a wide range of potential applications, including:
- Voice commands: Speech recognition can be used to enable the hands-free operation of devices, such as smartphones, smart home devices, and virtual assistants. This allows users to control these devices with their voice, which can be particularly useful in situations where they cannot physically interact with the device.
- Transcription: Speech recognition can be used to automatically transcribe audio recordings into text. This can be particularly useful in industries such as healthcare, legal, and finance, where accurate transcription of audio recordings is necessary for documentation and record-keeping.
- Accessibility: Speech recognition can be used to enable people with disabilities, such as those who are visually impaired or have mobility issues, to interact with computers and other devices more easily.
- Translation: Speech recognition can be used to automatically translate spoken language from one language to another. This can be particularly useful in situations where language barriers exist, such as in international business or travel.
- Customer service: Speech recognition can be used to automate customer service interactions, such as phone-based support or chatbots. This can help reduce wait times and improve the overall customer experience.
Q. What is speech communication in AI?
A. Speech communication in AI refers to the ability of machines to communicate with humans using spoken language. This involves the use of speech recognition, natural language processing (NLP), and speech synthesis technologies to enable machines to understand and produce human language.
Speech communication in AI has become increasingly important in recent years, as more and more devices and applications are being designed to support voice-based interaction. Some examples of speech communication in AI include:
- Virtual assistants: Virtual assistants like Siri, Alexa, and Google Assistant use speech recognition and NLP to understand user commands and queries, and speech synthesis to respond.
- Smart home devices: Devices like smart speakers, thermostats, and lights can be controlled using voice commands, enabling hands-free operation.
- Call centers: Many call centers now use speech recognition and NLP to automate customer service interactions, such as automated phone trees or chatbots.
- Language translation: Speech recognition and NLP can be used to automatically translate spoken language from one language to another, enabling communication across language barriers.
- Transcription: Speech recognition can be used to transcribe audio recordings into text, making it easier to search and analyze spoken language.
Speech communication in AI is still a developing field, and many challenges must be overcome, such as dealing with accents, dialects, and variations in speech patterns.
Q. Which type of AI is used in speech recognition?
A. There are different types of AI techniques used in speech recognition, but the most commonly used approach is Deep Learning.
Deep Learning is a type of machine learning that uses artificial neural networks to model and solve complex problems. In speech recognition, the neural network is trained on large datasets of human speech, which allows it to learn patterns and relationships between speech sounds and language.
The specific type of neural network used in speech recognition is often a type of Recurrent Neural Network (RNN) called a Long Short-Term Memory (LSTM) network. LSTMs can model long-term dependencies in sequences of data, making them well-suited for processing speech, which is a sequence of sounds over time.
Other AI techniques used in speech recognition include Hidden Markov Models (HMMs), Support Vector Machines (SVMs), and Gaussian Mixture Models (GMMs).
Q. What are the difficulties in voice recognition AI in artificial intelligence?
A. Despite advances in speech recognition technology, there are still several challenges that must be addressed to improve the accuracy and effectiveness of voice recognition AI. Here are some of the key difficulties in voice recognition AI:
- Background noise: One of the biggest challenges in speech recognition is dealing with background noise. Ambient noise, such as music, traffic, or other people talking, can interfere with the accuracy of the system, making it difficult to distinguish between speech and noise.
- Variations in speech: People speak in different accents, and dialects, and with varying levels of clarity. This can make it difficult for speech recognition systems to accurately transcribe spoken language, especially for individuals with non-standard speech patterns.
- Speaker diarization: In situations where multiple people are speaking, it can be difficult for the system to identify and distinguish between different speakers. This can result in errors in transcription or the misattribution of words to the wrong speaker.
- Contextual understanding: Speech recognition systems often struggle to understand the context of the spoken language. This can result in errors in transcription or misinterpretation of the intended meaning of the speech.
- Limited training data: Building accurate speech recognition models requires large amounts of high-quality training data. However, collecting and labeling speech data can be time-consuming and expensive, especially for languages or dialects with limited resources.
- Privacy concerns: Voice recognition systems often rely on collecting and storing user voice data, which can raise concerns about privacy and security.
Overall, these difficulties demonstrate that speech recognition technology is still a developing field, and there is a need for ongoing research and development to address these challenges and improve the accuracy and effectiveness of voice recognition AI.