How to SELECT First Row in SQL?

There could be a lot of possibilities to select the first row in SQL. The variations can be many like finding the top scorer from the entire data for the students in a university or likewise, it can be the lowest scorer as well. Clauses like ORDER BY and LIMIT will be more often used in this scenario.
But what if you don't just need to select the first row in SQL but you should do it for each of the respective departments in a university? Well, the first idea that clicks is the use of the GROUP BY clause, isn't it? However, the GROUP BY clause alone might not be able to produce the desired output when we need to select the first row in SQL from each group. Let's look at the use of correlated subqueries and window functions with common table expressions in the upcoming sections.
Data for Finding the First Row in Each Group
We'll begin with creating a table Students for a university where each student record will have a student_id (integer), name (varchar), major (varchar), and GPA (double).
Output:
Now, since the table is still empty, we need to insert some records to perform any operation in the next section.
Output:
SELECT First Row in SQL
We'll be looking at two methods to select first in SQL from each group. However, if you need a precise explanation for correlated subqueries, you can read it here.
Now, we are trying to find the data of the students who have the maximum GPA score in each of the departments, and let us also order these GPA scores (department-wise) from high to low. So, this is what our desired output should look like:
| student_id | name | major | GPA |
|---|---|---|---|
| 9 | Tom | ECE | 9.2 |
| 6 | Damian | IT | 9.1 |
| 7 | Estella | CSE | 9 |
Using Correlated Subqueries
A correlated subquery, also known as a repeating or synchronized query, comprises row-by-row processing where each row from the subquery will be processed once for each row from the parent or outer query.
In our example, we'll show all the records with the student_id, name, major, and GPA. We can provide aliases to the outer and inner queries.
There will be another SELECT statement used in the inner query and both these inner and outer queries will be compared by the WHERE clause. Only the records with the maximum GPA scores will be displayed in the result. MAX() is the aggregate function that will be used to find the department-wise maximum GPA scores.
Also, it is important to group the results of the inner query with the GROUP BY clause.
Output:
However, row-by-row processing means that each row processed by the inner query will be evaluated against the rows from the outer query. Although correlated subqueries can provide us with the output, this is not an efficient approach.
Moreover, in several cases, it might be difficult to write and understand the code properly as it becomes more complex. So, we can try doing the same thing with window functions and common table expressions.
Using Window Functions and Common Table Expressions
Although the use of window functions might look similar to that of aggregate functions, a window function doesn't just group the result into a single row. Instead, it creates windows for a specific set of rows.
The OVER clause in window functions helps us to create different windows (different sets of records) similar to what a GROUP BY clause does. The OVER clause consists of the PARTITION BY and ORDER BY (optional) clauses.
The PARTITION BY clause will create different window frames based on the difference in the set of rows.
The ORDER BY clause can be used to specify the order of the rows in a particular window.
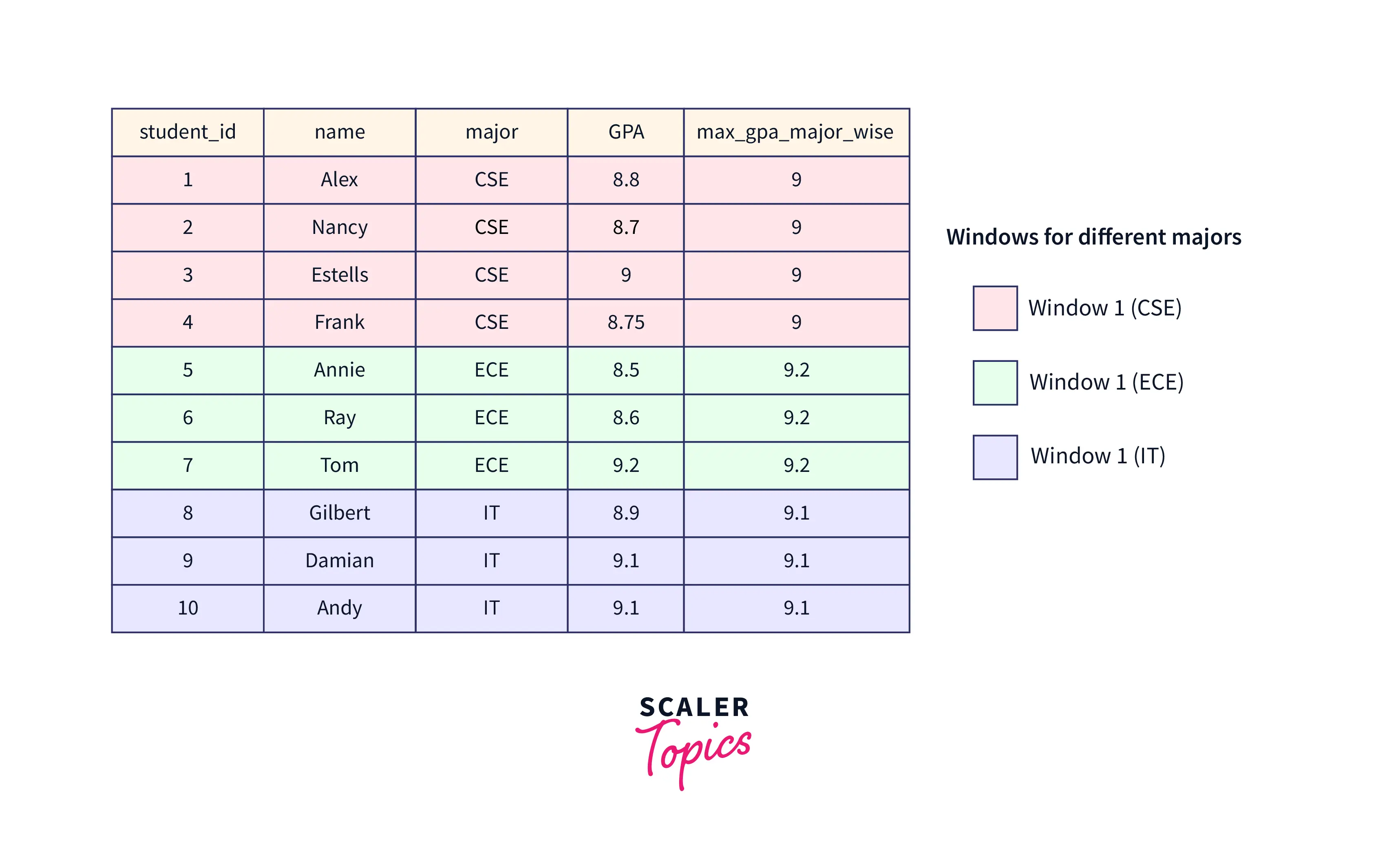
The window function creates an additional column to display the result for each row. Let us create a window function for our example where the maximum GPA scores for each department will be displayed in a separate column.
Output:
As you can see in the table Students, there are different windows for different majors. For instance, CSE has a distinct window with the maximum GPA being 9 and the same applies to ECE as well as IT.
Common table expressions (CTE) are temporary result sets that can be used as a reference in any query or table. Given below is the syntax for the CTE:
Here, in our example, we can put the window function in the CTE and use it as a reference in our main SQL query. By doing this, we can remove the rigmarole of writing the same code multiple times as we have already created a temporary result set to refer from.
So, this is how our temporary result set looks like by using the common table expression:
Now, we can get the records based on the comparison that the GPA of these records is equal to the maximum GPA major-wise or department-wise.
Output:
Learn more
Clauses used in MySQL query statements:
If you want to learn more about the clauses used in our example, you can refer to the pages mentioned below:
Conclusion
- A correlated subquery, also known as a repeating or synchronized query, comprises row-by-row processing where each row from the subquery will be processed once for each row from the parent or outer query.
- While using correlated subqueries, it can be difficult to write and understand the code properly as it becomes more complex. So, we can try doing the same thing with window functions and common table expressions.
- A window function doesn't just group the result into a single row but it also creates windows for a specific set of rows.
- Common table expressions (CTE) are temporary result sets that can be used as a reference in any query or table.