Import and Export Command in Sqoop
Overview
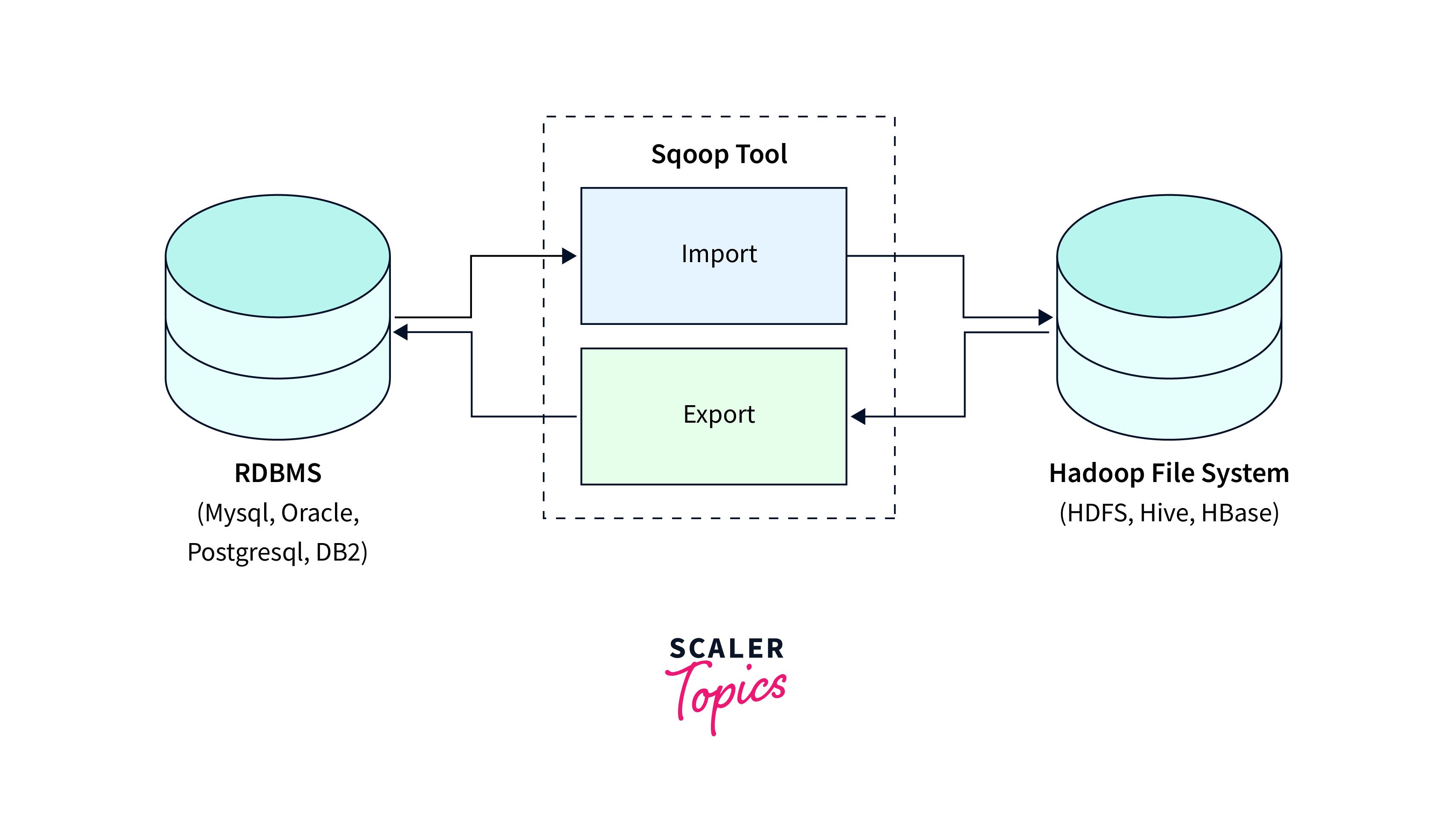
In Big Data and data analytics, the efficient migration of data between different systems is crucial for the success of any data-driven project. This is where Sqoop, a powerful tool in the Hadoop ecosystem, simplifies the process of importing and exporting data between Hadoop and relational databases, allowing organizations to handle data seamlessly.
Syntax:
- TOOL_NAME: Specific Sqoop tool being used, such as import or export.
- TOOL_OPTIONS: Options specific to the chosen tool, specifying details about the import/export process.
- GENERIC_OPTIONS: These options are common across all sqoop import and export tools and control general behaviors.
- TOOL_ARGUMENTS: Additional arguments or parameters required by the tool.
:::
Sqoop Import Command
The Sqoop import command is a part of sqoop import and export tool in the Hadoop ecosystem that is used to transfer data from relational databases to the Hadoop Distributed File System (HDFS).
Syntax
Options:
- --connect: Specifies the JDBC connection URL for the source database. Example: --connect jdbc:mysql://localhost/mydb
- --username: Specifies the username for connecting to the source database.
- --password: The password for the source database user.
- --target-dir: The HDFS directory where imported data will be stored.
- --verbose: Provides detailed debugging information during the sqoop import and export process.
- --table: Name of the source database table from which data will be imported.
- --columns: A comma-separated list of columns to be imported from the source table.
- --split-by: The column used for data splitting in parallel import tasks.
Working:
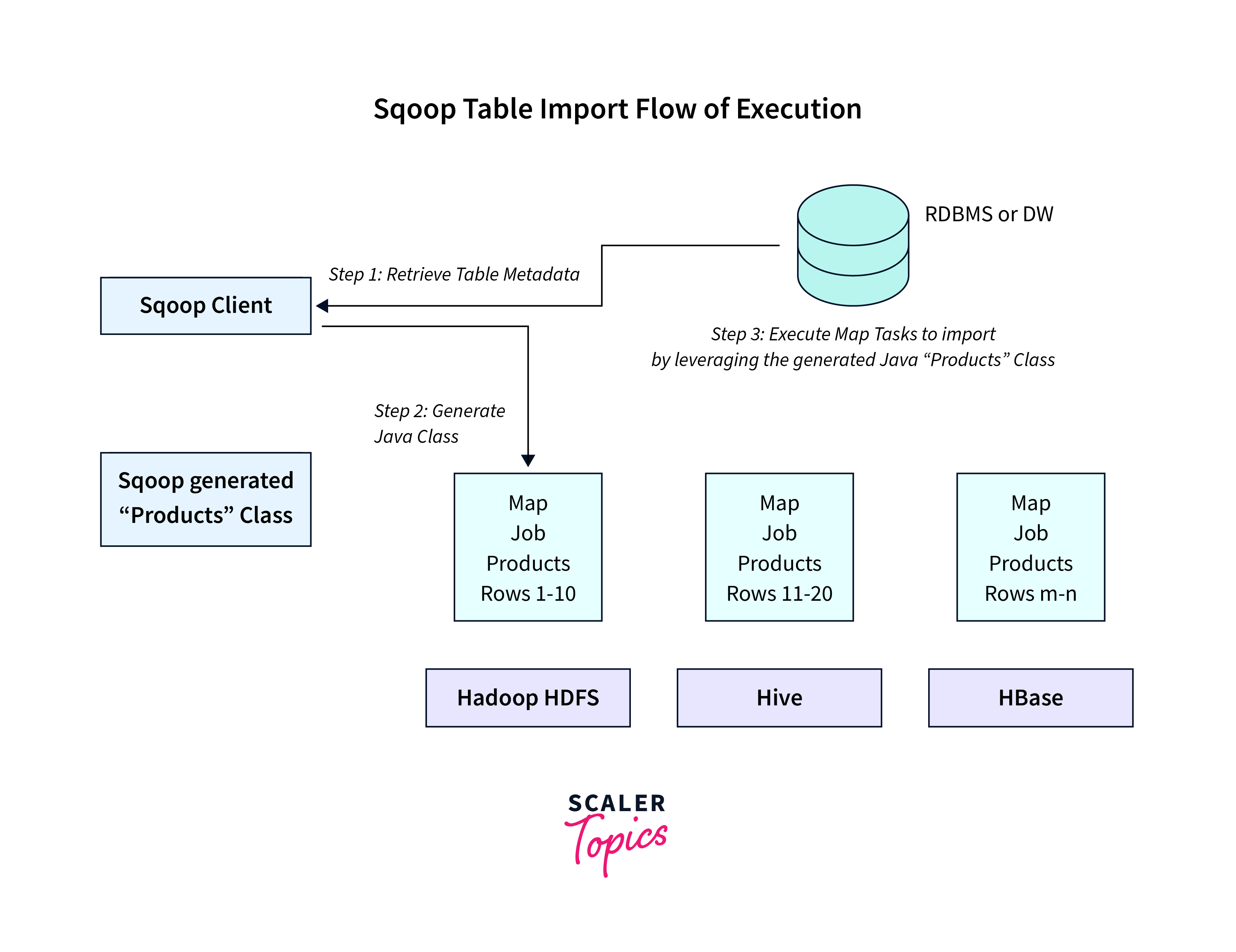
- The Sqoop import command begins by establishing a connection to the source relational database using the provided connection URL, username, and password.
- Once the connection is established, Sqoop extracts data from the specified source database table. It retrieves the data in small chunks to optimize performance and memory usage.
- During the extraction process, Sqoop converts the extracted data into Hadoop's internal format.
- The transformed data is ingested into the specified target directory within the HDFS.
Examples:
Importing Specific Columns and Filtering Data:
Get only the order_id, order_date, and product_name of the products which have been ordered on or after 2023-01-01 from the orders table.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Supported Data Formats
sqoop import and export tools offers support for various data formats when importing data from relational databases into Hadoop's Distributed File System (HDFS). The supported formats are:
- Avro
- Parquet
- SequenceFile
- Text
Syntax:
Options:
The format in the --as-<format> option should be specified to specify the required data format such as:
- The text data format is the default data format which is widely supported for storing unstructured or semi-structured data.
- --as-avrodatafile: Avro data format which is a compact, schema-based data serialization format.
- --as-parquetfile: Parquet data format which is a columnar storage format optimized for analytics workloads
- --as-sequencefile: SequenceFile data format, a binary file format optimized for storing large amounts of key-value pairs
- --compression-codec: Used to specify the compression codec for the specified format.
Example:
To store the imported data from the transactions table in sequence file format in the /user/hadoop/data file in HDFS:
Importing Incremental Data
Importing incremental data is part of sqoop import and export and is useful in scenarios where only the newly added or modified records need to be transferred from a source database to the Hadoop ecosystem.
Working:
- Sqoop compares the specified column (usually a timestamp or an incrementing key) between the source and target datasets.
- Sqoop then imports only the records that have a higher value in the specified column than the maximum value present in the target dataset.
- Now, only the new or modified records are transferred, significantly reducing the amount of data transferred and improving overall efficiency.
Syntax:
Options:
- --incremental: Import mode for incremental data such as:
- append: Appends new data to the existing dataset without any modifications. Useful for databases with incrementing primary keys.
- lastmodified: Imports data based on the timestamp of the last modification. Useful for databases with timestamp columns.
- --last-value: The last value is seen in the check column for incremental import.
- --check-column: The column on which the values of the incremental import will be.
Examples:
To get data from the transactions table for records with transaction_date that have been added or modified since 2023-01-01 into the HDFS target directory.
Importing Data with Hive Integration
Importing data into Hive, a powerful data warehousing solution in the Hadoop ecosystem, is a common requirement for organizations seeking to perform efficient data analysis and querying. sqoop import and export performs this integration by allowing the import of data directly into Hive tables, eliminating the need for manual data loading.
Working:
- When importing data with Hive integration, Sqoop directly populates Hive tables with the imported data.
- Sqoop import and export optimizes Hive's metadata and data management capabilities.
- The imported data is immediately available for analysis and querying using Hive's SQL-like language, HiveQL.
Syntax:
Options:
- --hive-import: Instructs Sqoop to import data into Hive.
- --hive-table: Name of the Hive table where data will be imported.
- --hive-overwrite: The current data in hive table willl be replaced.
- --create-hive-table: Automatically creates the target Hive table if it doesn't already exist.
- --hive-partition-key: Column used for Hive partitioning.
- --hive-partition-value: Value for the Hive partition key.
Example:
To update an existing Hive table named hive_products with the latest data from the source database's products table.
Sqoop's --hive-overwrite option ensures that the data in the Hive table is refreshed with the latest data from the source.
Turn Learning into Career Growth
Sqoop Export Command
The Sqoop export command allows transfer of data from Hadoop to external relational databases.
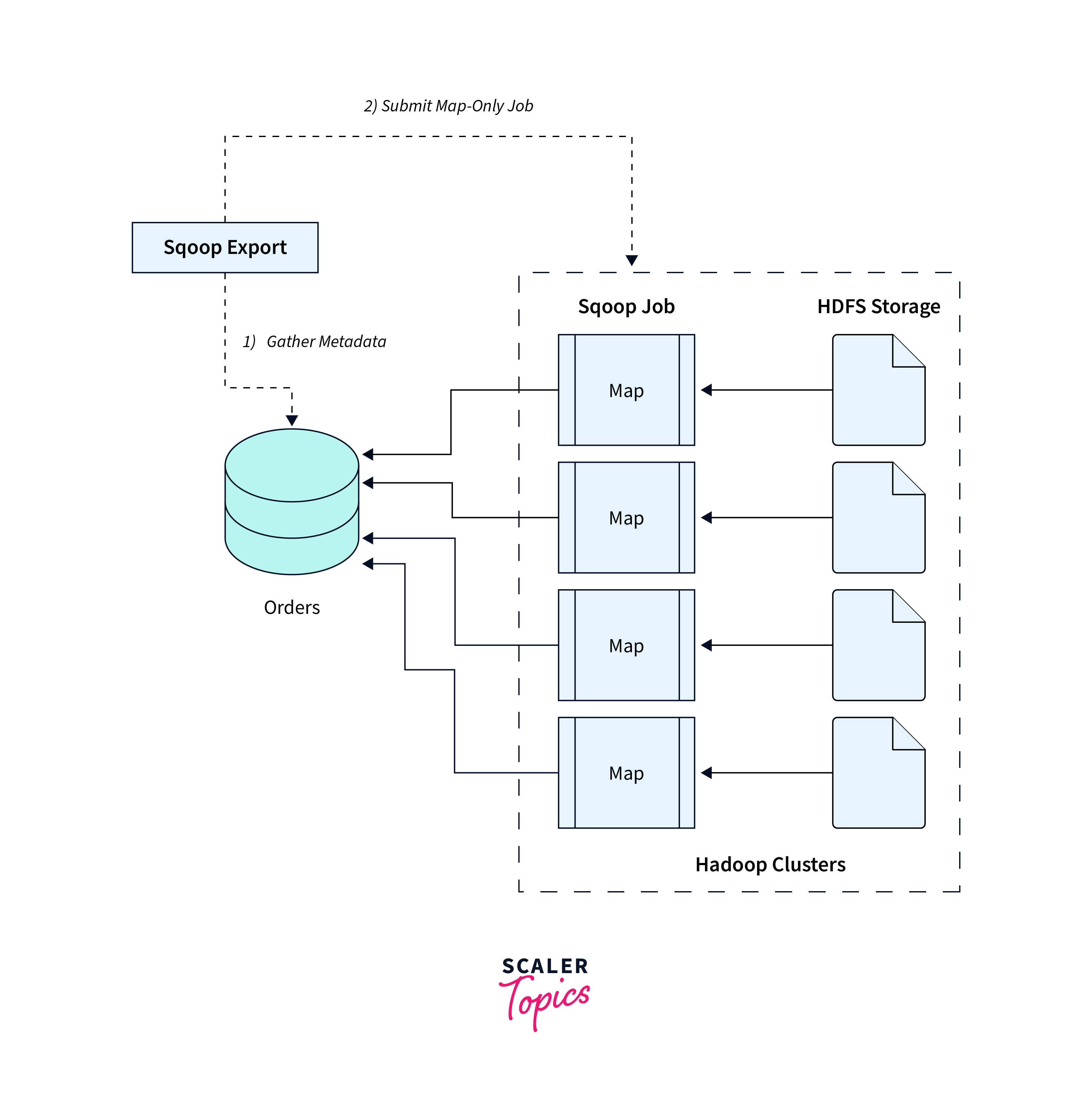
Working:
- The Sqoop export command transfers data from Hadoop to external databases through JDBC connections.
- It allows users to customize the distributed processing capabilities of Hadoop for preparing and transforming data before exporting it to relational databases.
Syntax:
Options:
- --export-dir: The HDFS directory containing the data to be exported.
- --update-key: Primary key columns used to identify rows for updates.
- --update-mode: Update mode. It can be set to one of the following values:
- updateonly: Only updates existing records.
- allowinsert: Allows both updates and inserts.
- allowinsertfailupdate: Tries to insert new records and updates existing ones if a primary key constraint violation occurs.
- --batch: Enables batch mode, reducing the number of MapReduce tasks when exporting data.
Example:
Export data from the user/hadoop/data to the results table in MySQL database.
Explanation:
- Suppose the results table in the MySQL database already contains data with unique id values.
- When we run the command, Sqoop will compare the id values of the exported data with the existing data in the results table.
- If there is a match based on the id values, the corresponding rows in the results table will be updated with the new data from the HDFS directory.
- If no match is found, new rows will not be inserted.
Sqoop Integration with Hadoop
sqoop import and export integration with Hadoop allows usage of distributed computing capabilities for processing and analyzing structured data from various external sources.
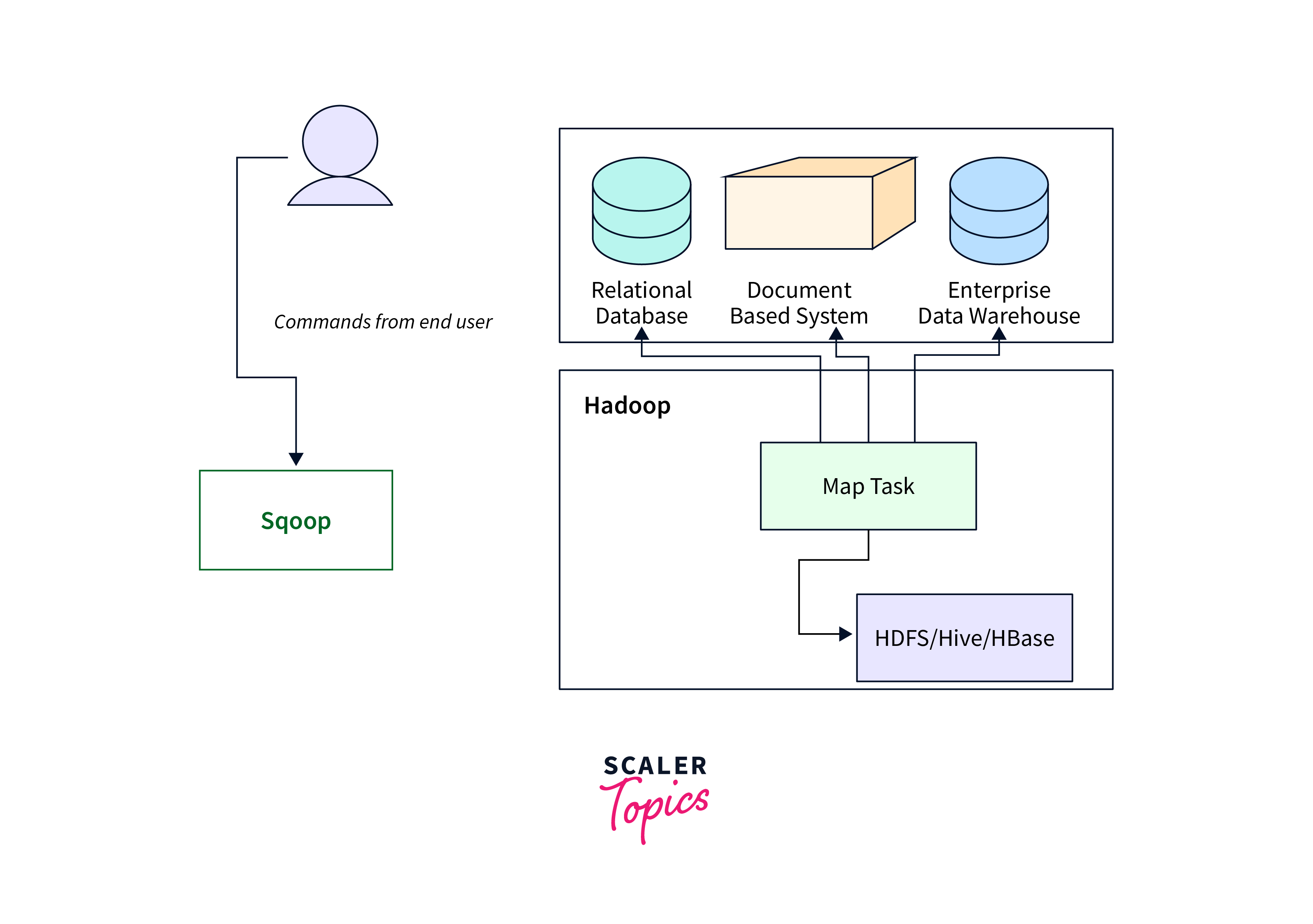
Working:
- Sqoop integrates with Hadoop by utilizing Hadoop's underlying MapReduce framework to efficiently move data between Hadoop's distributed file system (HDFS) and external relational databases.
- Sqoop utilizes Hadoop's parallel processing capabilities to divide data transfer tasks into smaller, manageable chunks, which are then distributed across the Hadoop cluster for faster and more efficient data movement.
Syntax
The [generic-args] are the common arguments that apply to all Sqoop commands, [tool-name] refers to the specific Sqoop tool being used (e.g., import, export, eval), and [tool-args] are the options and arguments specific to the chosen Sqoop import and export tool.
Example:
The Sqoop eval tool provides a way to evaluate SQL queries on a specified database server and display the results without importing or exporting data. This tool is used for testing and shows the integration with Hadoop.
Explanation:
The query calculates and displays the count of employees whose salary exceeds 50000. The result of the evaluation is then displayed in the terminal. This is helpful to test the output of a SQL query.
Exporting Data to Specific Tables
Exporting data from Hadoop to specific tables is used to efficiently transfer data from Hadoop's distributed file system (HDFS) to tables in external databases.
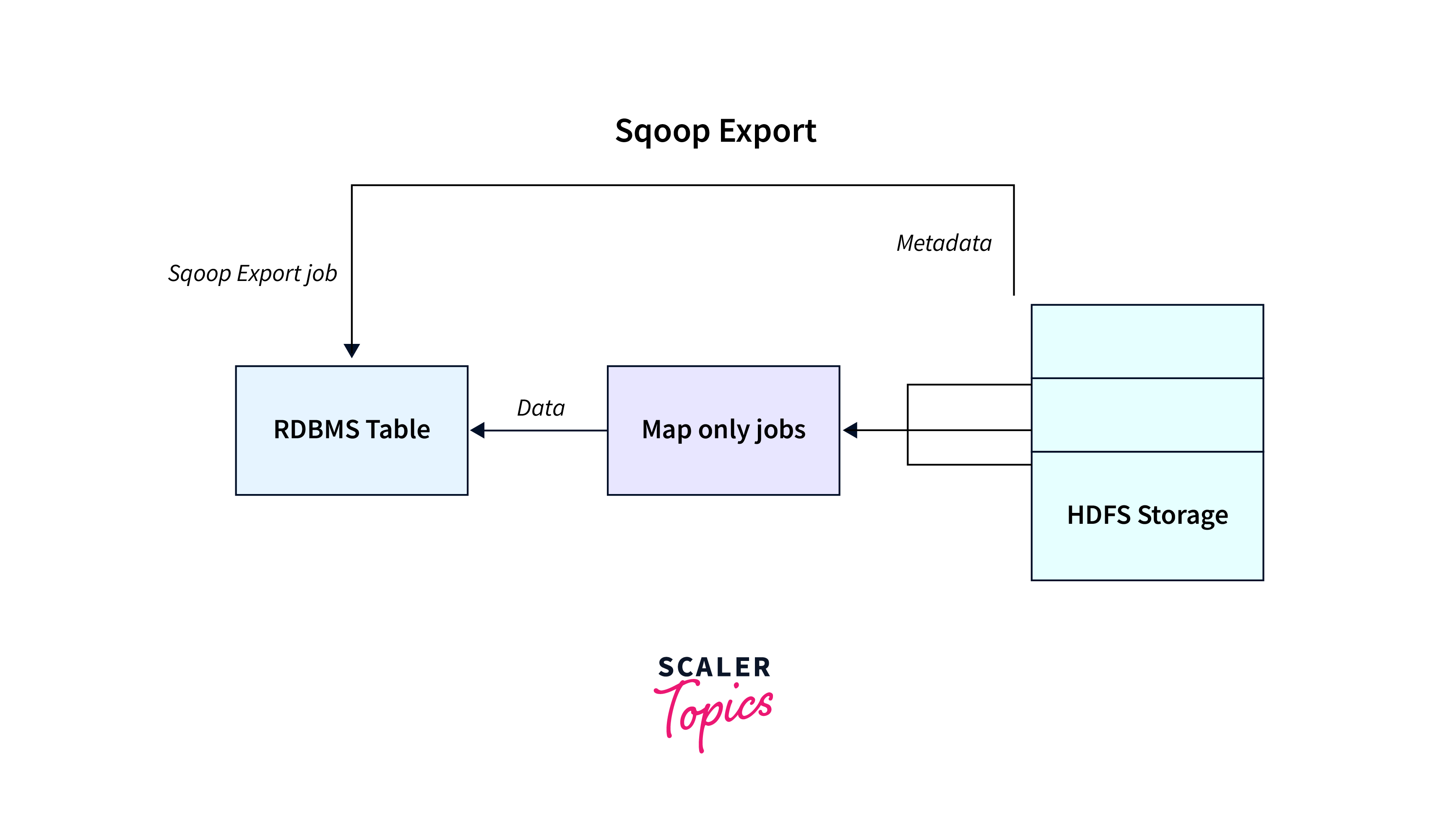
Working:
- The process of exporting data to specific tables involves transferring data from HDFS to external databases using sqoop import and export.
- Sqoop maps the columns in HDFS to the columns in the target database table and efficiently inserts or updates the data based on the specified criteria.
Syntax:
Options:
- --input-fields-terminated-by: Field delimiter for input data in HDFS.
- --input-lines-terminated-by: The Line delimiter for input data in HDFS.
- --input-null-string and --input-null-non-string: The strings representing null values for string and non-string columns, respectively.
- --batch: Batch mode, reducing the number of MapReduce tasks during data transfer.
Example:
Explanation:
Extract data from /user/hadoop/data and transform it according to the column mapping. For each row of data in HDFS, Sqoop will match the designated columns (emp_id, emp_name, and salary) and insert the corresponding values into the employees table.
Exporting Data with Hive Integration
Exporting data from Hive to external relational databases is used to transfer processed or analyzed data from Hive tables to specific tables in external databases.
Working:
- Exporting data with Hive integration involves transferring data from Hive tables to external databases using Sqoop.
- Sqoop interacts with the Hive metastore to understand the structure of the Hive table, including column names, data types, and partitioning information.
- It then maps the Hive table's columns to the columns in the target database table and efficiently inserts or updates the data based on the specified criteria.
Syntax:
Options:
- --table: Specifies the target database table where data will be exported.
- --hcatalog-table: Name of the Hive table from which data will be exported.
Example:
To export data from the Hive table named hive_employees to an external MySQL database table named employees.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- Sqoop import and export serves as a tool for transferring data between Hadoop and relational databases.
- The Sqoop import command is used to transfer data from external databases to Hadoop's HDFS.
- Sqoop supports diverse data formats like CSV, Avro, and Parquet, allowing integration with various data sources.
- Sqoop's export command facilitates data movement from Hadoop to external databases.
- We can also export data directly from Hive tables to external databases via Sqoop.