StackGAN
Overview
In image generation, the GAN architecture is one of the best ones. The StackGAN architecture addresses some of the flaws of basic GANs by decomposing the task of generating images into multiple parts. This article will focus on the training paradigm proposed by StackGAN and take an in-depth look at its architecture.
Introduction
Generating novel photorealistic images is a huge part of the computer vision process in many fields, such as photo editing, design, and other graphics-related work. Many attempts to generate high-resolution images have been made in the past, and StackGAN is one of the major ones. Instead of performing the generation task in one go as most existing architectures do, a StackGAN uses two separate GANs. The authors of the StackGAN made this architectural choice to replicate how a human artist paints a picture. They start with a rough sketch and a color blackout, then move on to refining the details of the sketch. They then add more information based on the description of what they want to paint. This article looks at StackGAN and how and why it works. The multi-stage architecture, loss functions, and the need to modify the GAN training paradigm are also explained. Given their descriptions, some of the images generated by StackGAN are shown below.

What is a StackGAN
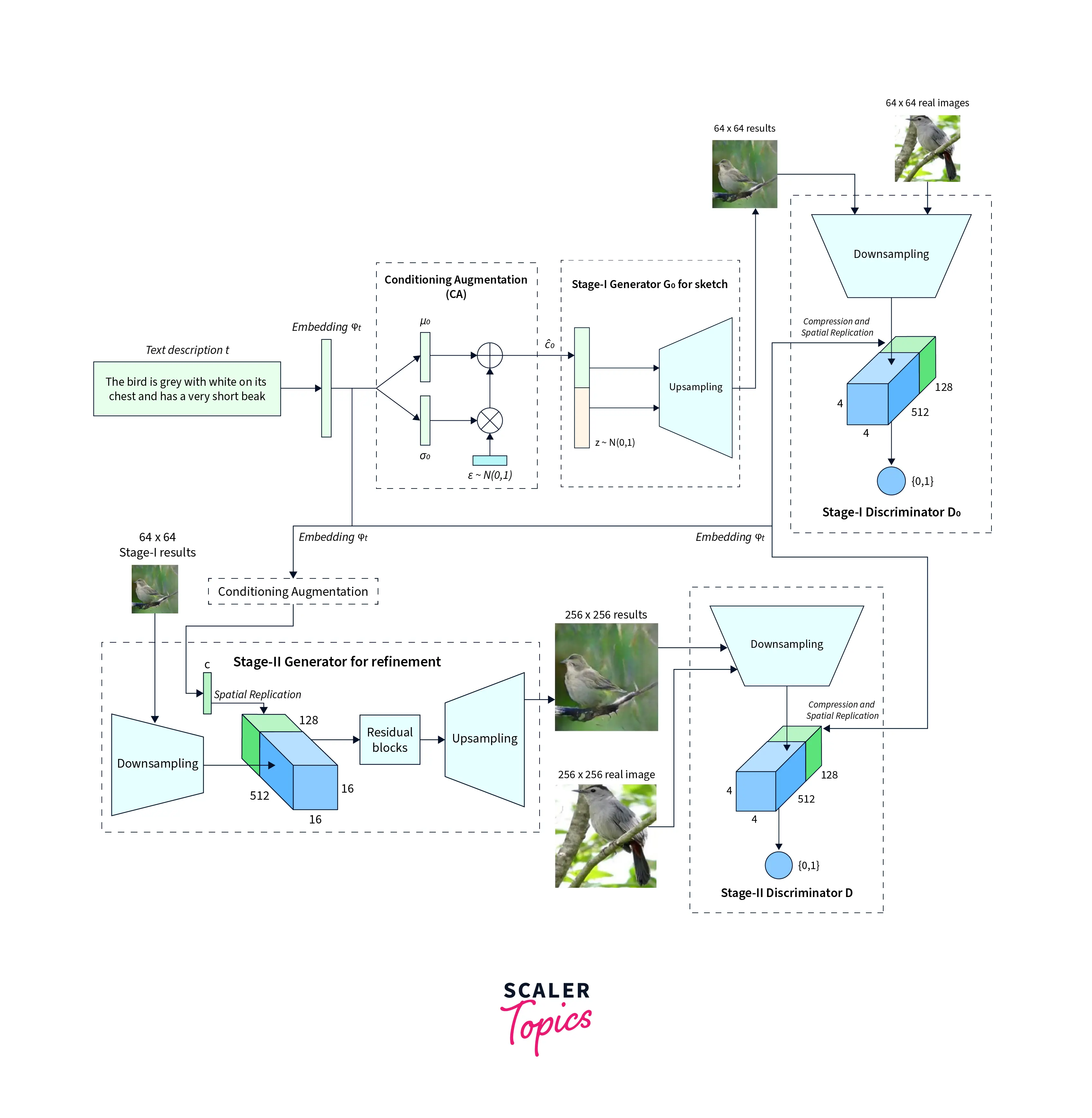
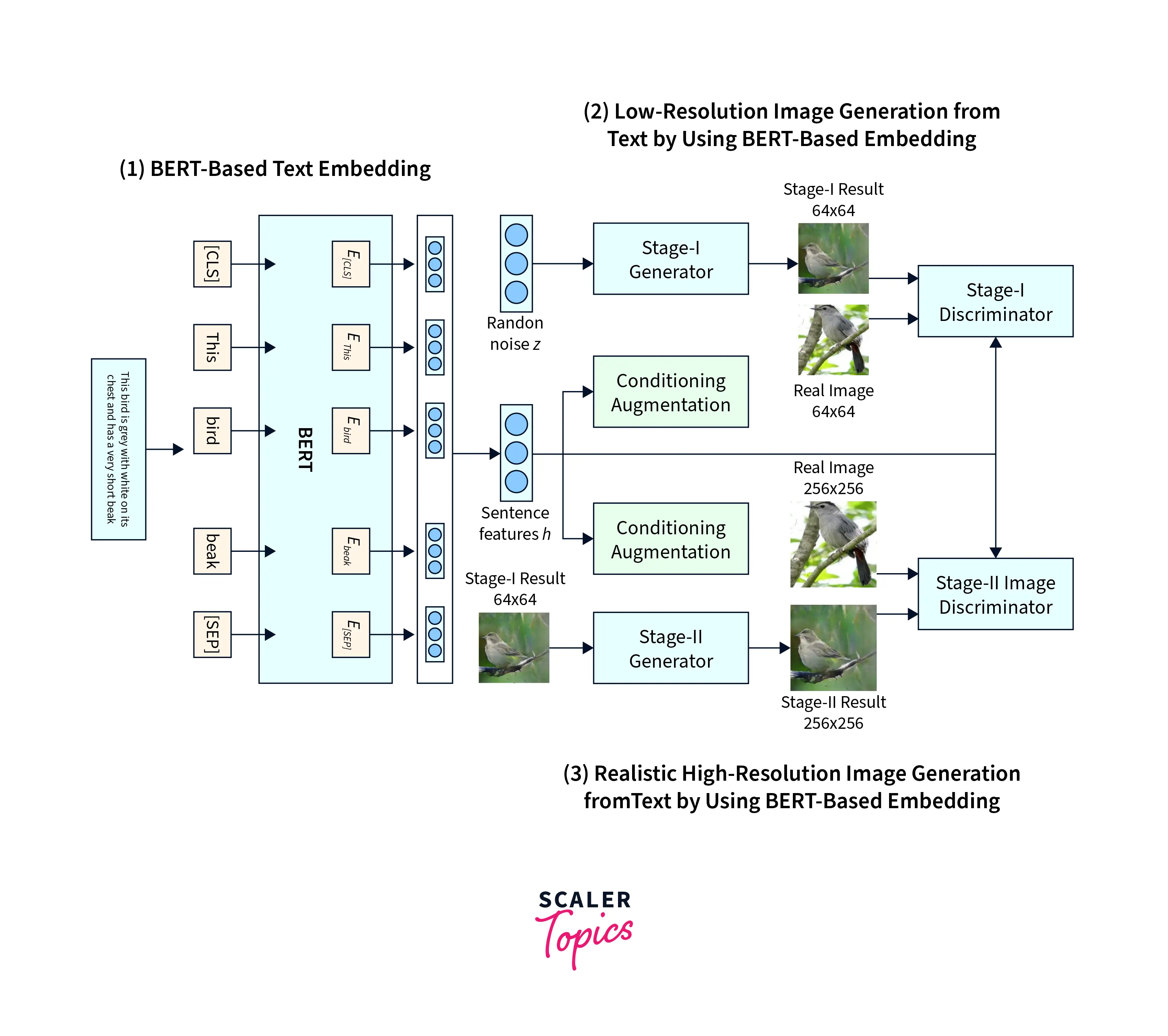
A StackGAN is a multi-modal network Generative Adversarial Network (GAN) designed to generate high-resolution images from text descriptions. It is a modification of the general GAN training paradigm where generating new objects is split into sub-tasks. It consists of two stages: a Stage-I GAN that generates low-resolution images and a Stage-II GAN that takes the low-resolution images generated by Stage-I and refines them to produce high-resolution images.
For example, a StackGAN could be trained to generate images of birds based on text descriptions of different bird species. The Stage-I GAN would generate low-resolution images of birds based on the text descriptions. The Stage-II GAN would take those images and refine them to produce high-resolution images that are more realistic and detailed. The conditioning augmentation technique allows for more variations and diversity in the generated images.
Prerequisites
Before understanding the StackGAN architecture, we need to understand the concept of Conditional GANs (CGANs).
- In a Conditional Generative Adversarial Network (CGAN), the Generator and Discriminator are given additional conditioning variables alongside the input. These variables typically provide additional information that guides the generation process.
- The conditioning variables influence the output of the Generator network. The generator network takes in a noise vector and the conditioning variables , producing an output image . The generated image is influenced by the conditioning variables, allowing the Generator to create images specific to the provided condition.
- Similarly, the Discriminator network takes in an input image and the conditioning variables and produces a probability value indicating whether the input image is real or fake. The Discriminator network is also influenced by the conditioning variables, which allows it to distinguish between real and fake images more specifically.
- Using conditioning variables in CGANs enables the network to generate images specific to a certain condition, such as a specific class, style, or attribute. This approach makes the generated images more realistic and diverse. It allows the network to be used for various applications such as image generation, text-to-image synthesis, and style transfer.
Architecture of StackGAN
The StackGAN comprises two parts - Stage I and Stage II GANs. The first stage generates low-quality images by "sketching" a primitive shape and coloring the image with a simple color block out based on the text description provided. The background is generated from random noise. The second stage corrects defects in the output of the first stage by re-reading the provided description and then completing the details the first phase missed. The output of the second stage is thus a high-resolution image.
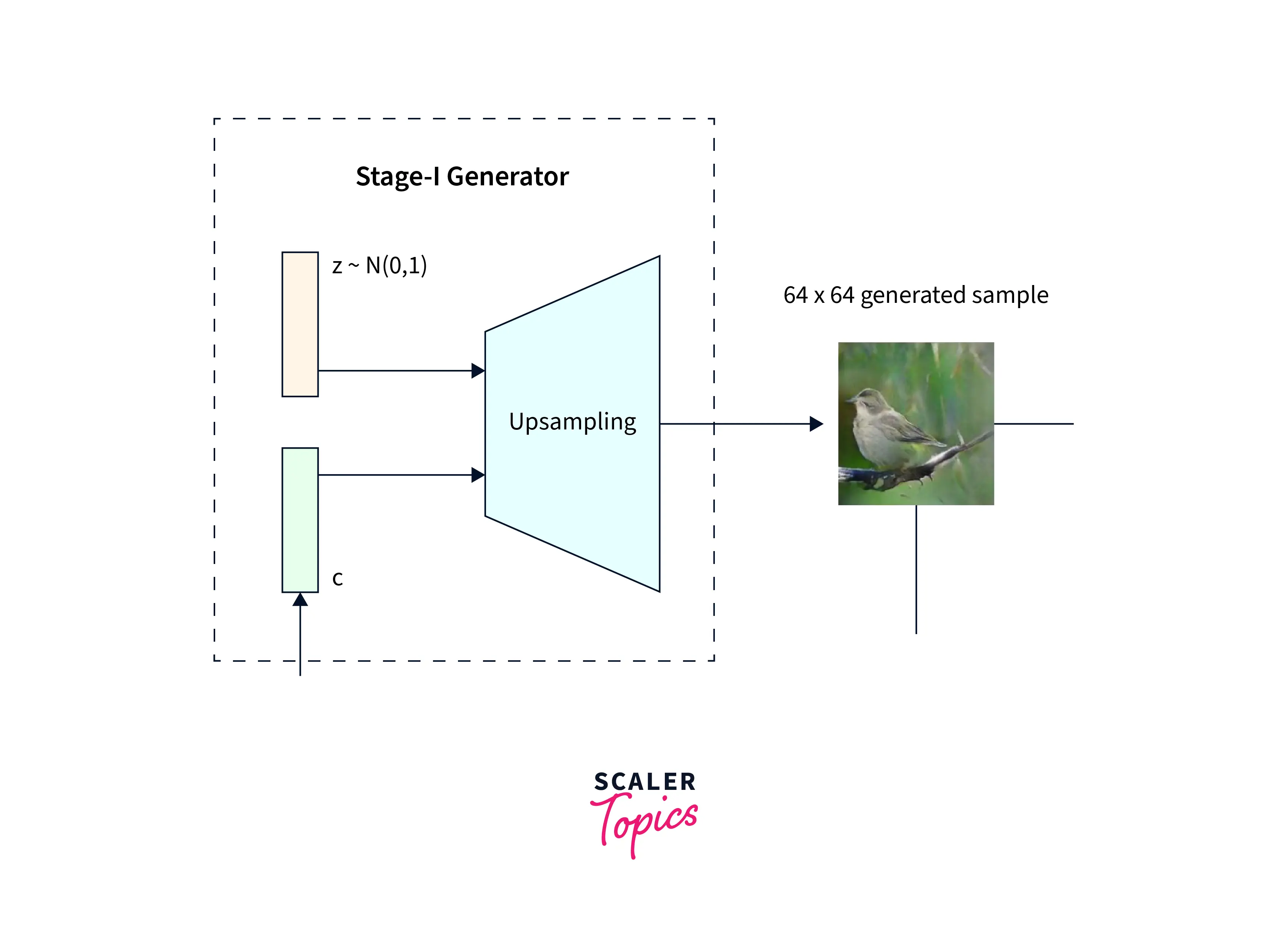
Stage I GAN
Stage I of the GAN is focused on generating a rough sketch with simple colors from the description.
Architecture
It is first fed into a fully connected layer(FC) to understand the embedding. The output of this FC layer is then passed to the Generator, which attempts to learn how to create the image better. The Discriminator compresses the text embeddings to a smaller representation using another FC layer. The image is also passed through a few downsampling blocks until it is a size the network can use. The final down-sampled image is combined with the text embedding and passed through a 1x1 convolutional layer. The final layer is another FC layer that returns the probability of the generated image being real or fake.
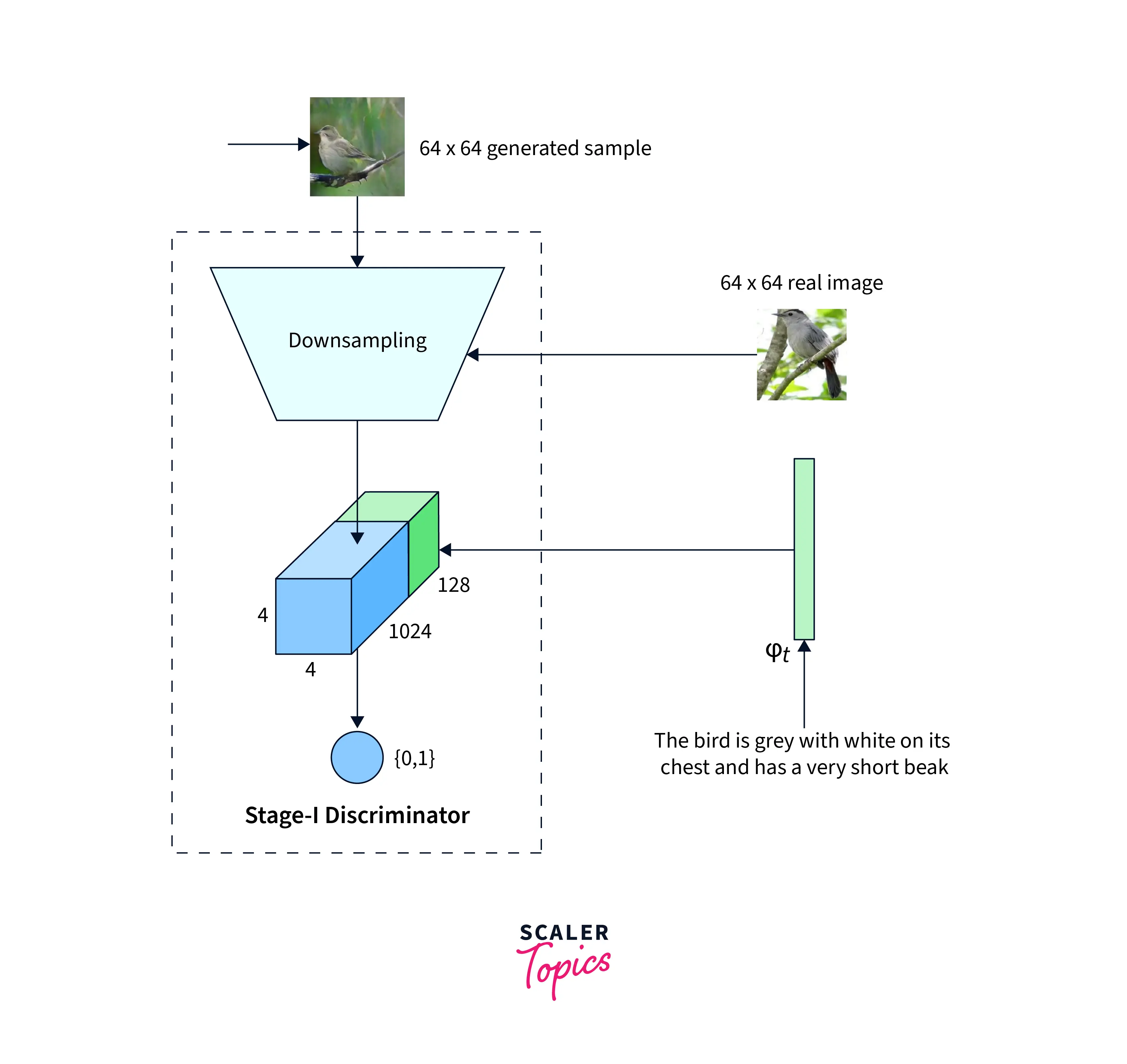
Loss Functions
Consider the text embeddings of the required description as . The meaning of the text embeddings is sampled from the Gaussian conditioning variables . Stage I first trains the Discriminator and then the Generator to alternatively maximize the discriminator and generator losses. The equations for these loss functions are as follows.
is a noise vector randomly sampled from the Gaussian distribution . A regularizing parameter is provided in the variable. The StackGAN research uses a for the paper.
Stage II GAN
The Stage II GAN receives the output of the Stage I GAN and refines it by re-considering the descriptions.
Architecture
The StackGANs Stage II Generator follows an encoder-decoder architecture with residual blocks. Text embedding is used first to create the conditioning variables. The result of Stage I is passed through downsampling layers and then concatenated with the features obtained from the text embedding. The output of these layers is then upsampled to generate high-resolution images. The Discriminator architecture is almost identical to Stage I, except for a few extra down-sampling layers. These down-sampling layers were included as the output of this part of the network is of a higher resolution than Stage I.
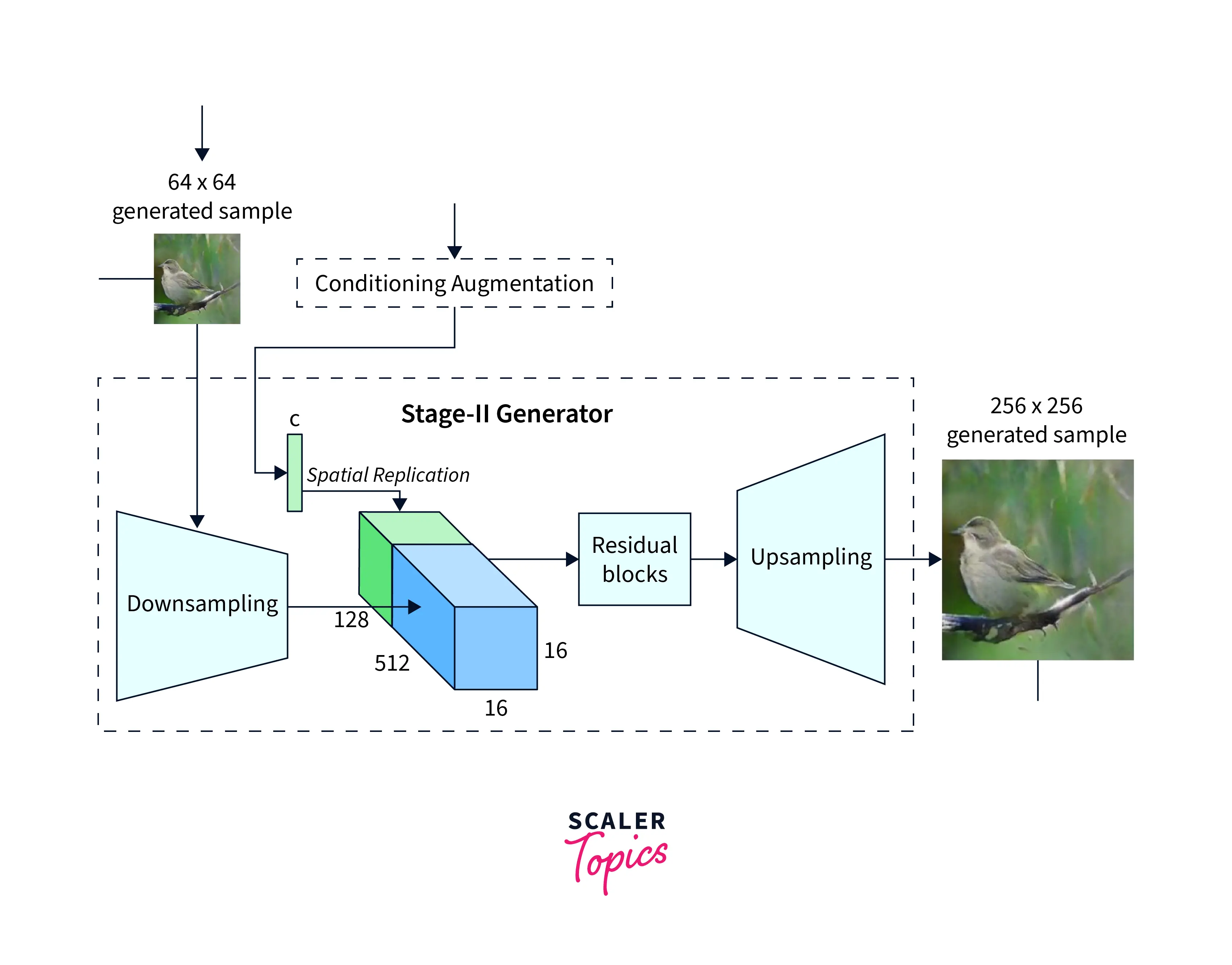
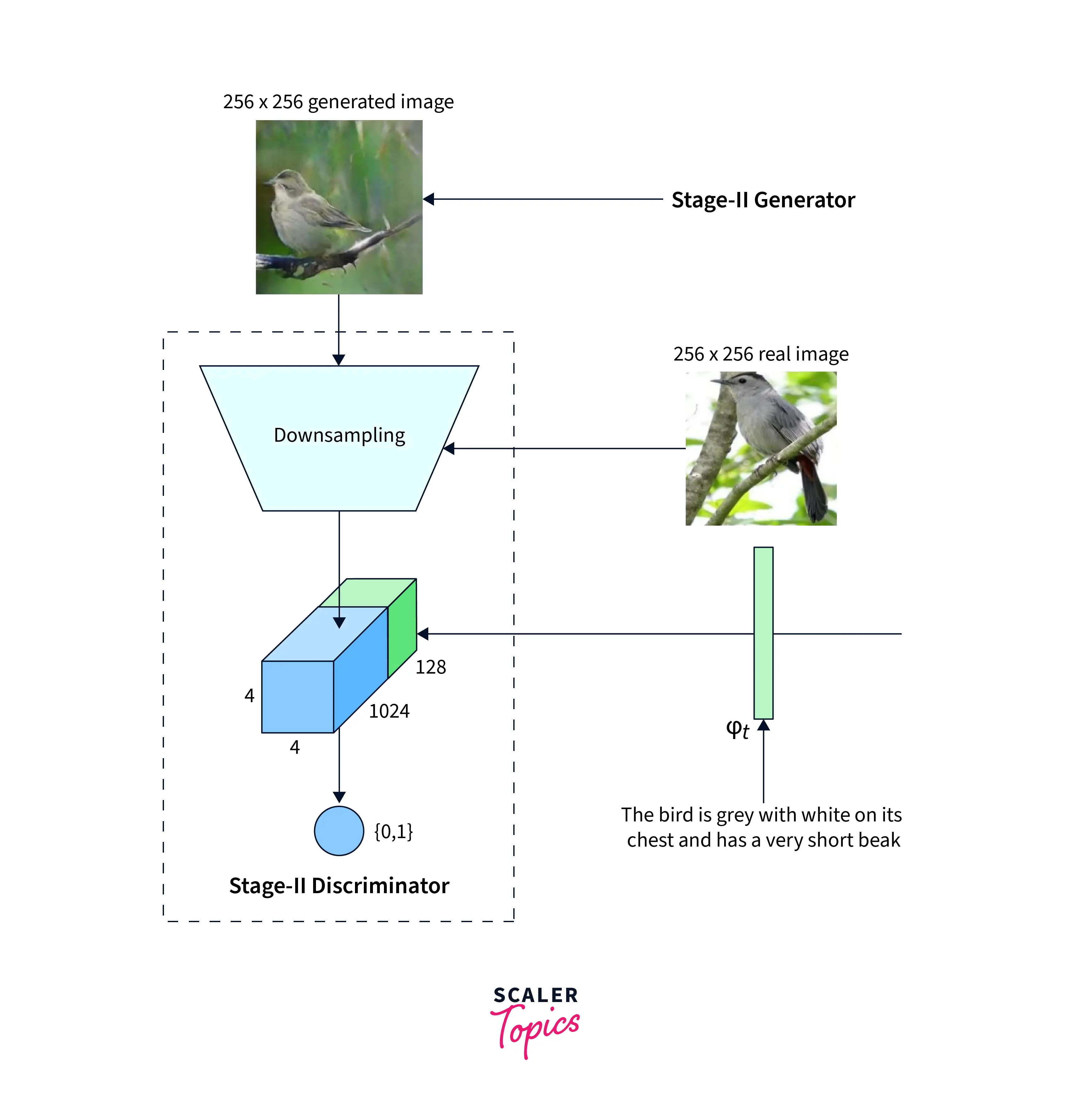
Loss Functions
If the low-resolution image is given by and the Gaussian sampled latent variables are given by , the Discriminator and Generator are trained by alternatively maximizing the value of the Discriminator loss and minimizing the Generator loss. The equations for these loss functions are the same as the Stage I GAN, except the low-resolution image is used instead of the noise . It is also to be noted that the noise is not used in Stage II as the StackGAN is meant to preserve the required randomness with the previous stage. A different FC layer is also used here that generates different statistical outputs compared to Stage I to learn better features.
More Architectural Details
Some architectural details were also mentioned in the StackGAN research. These details apply to both the Generator and the Discriminator.
- The up-sampling blocks are composed of nearest neighbor upsampling and then passed to a 3x3 stride one convolutional layer. Besides the final layer, Batch Normalization and the ReLU activation are applied after every convolution.
- The residual blocks have 3x3 stride one convolution.
- The StackGAN model that generates 256x256 images has four residual blocks, while the one that generates 128x128 images has only two blocks.
- The down-sampling blocks have 4x4 stride two convolutions and LeakyReLU instead of ReLU.
- The first downsampling block does not have a Batch Normalization layer.
Embedding
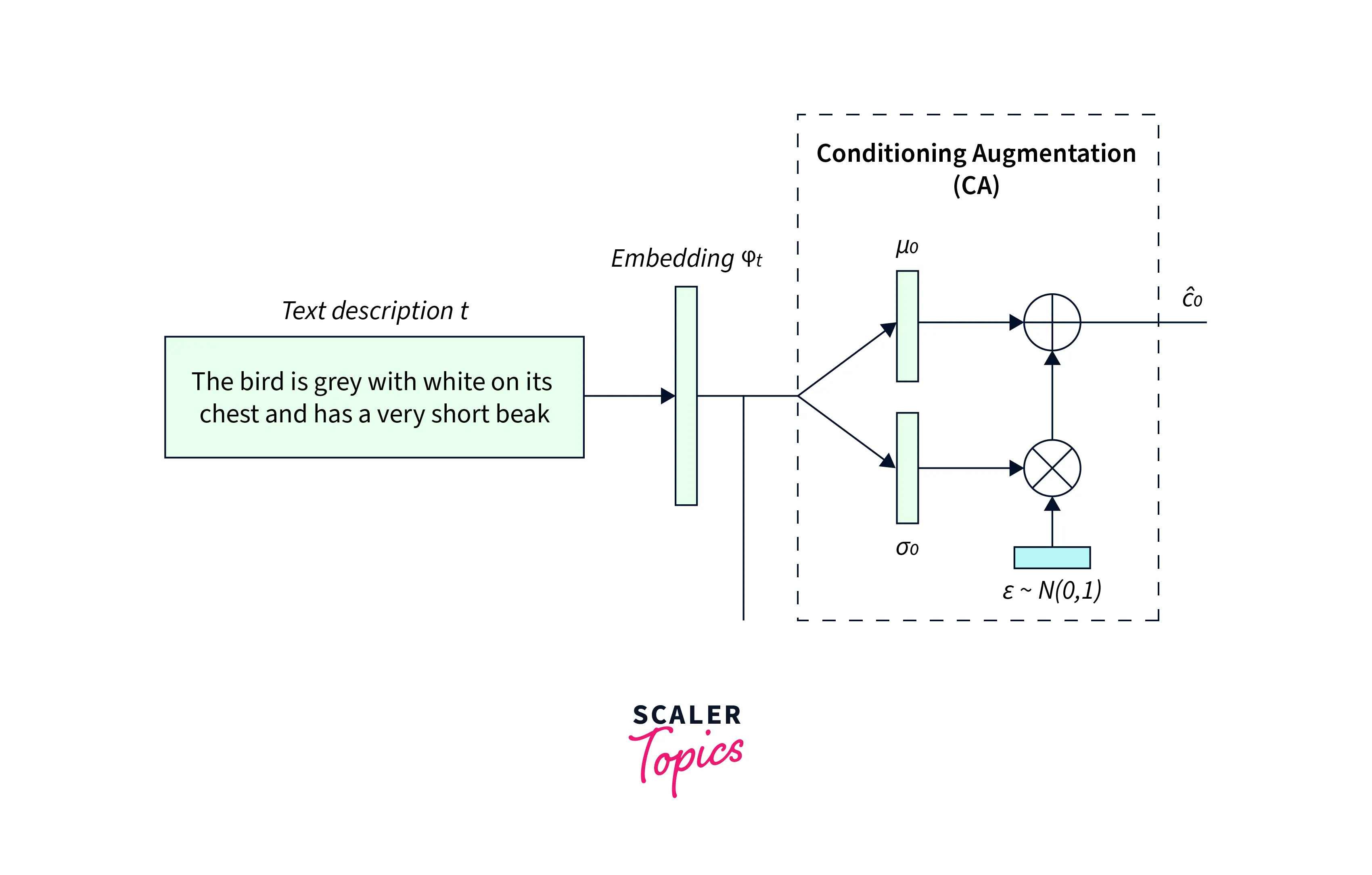
StackGAN uses a unique method for incorporating text embeddings into the image generation process. Instead of traditional methods, such as non-linear techniques, to transform the text embeddings, StackGAN uses Conditioning Augmentation.
Conditioning Augmentation is a method that allows StackGAN to incorporate text embeddings more robustly. The technique involves using additional variables, called conditioning variables, to guide the image generation process. These variables are derived from text embeddings and are used to influence the output of the generator network.
For example, imagine a StackGAN that generates images of birds based on text descriptions. The text descriptions are first converted into text embeddings. These embeddings then generate conditioning variables that guide the image-generation process. The generator network takes in a noise vector and the conditioning variables and produces an output image of a bird.
Using conditioning variables in StackGAN text embeddings results in a more robust image generation process. The network is also less sensitive to minor changes in the data manifold and can work with fewer image data.
Conditioning Augmentation
Conditioning Augmentation is one of the major contributions of the StackGAN research. Given a text description , the StackGAN uses an embedding to convert it to input for the Generator. Under circumstances where the data is limited, the latent space of the embedding is not fully exploited and leads to changes in the data manifold. These changes in the manifold are not desirable and hurt performance.
Conditioning Augmentation uses these to create more training pairs from a small subset of data. Instead of using a fixed conditioning variable, StackGAN samples latent variables from a Gaussian distribution. The mean and covariance matrix is generated for a text embedding .
The secondary objective of Conditioning Augmentation is to encourage reducing changes in the output with small changes in the data manifold. StackGAN uses a regularization term called KL Divergence as part of the Generator. This is given by,
Need For StackGAN
- Generating photorealistic images is easy with a GAN like DCGAN, but higher resolution is a difficult problem.
- Previous approaches have tried stacking more up-sampling layers but have failed to use this approach stably.
- StackGAN uses the decomposition of generation and refinement tasks to generate 256x256 images.
- The StackGAN training paradigm can be used with existing GANs to improve performance.
- StackGANs use a two-stage process, which allows for better control over the image generation process and enables the model to focus on different aspects of the image at different stages.
- StackGANs can be trained on smaller datasets, as the two-stage process allows for more efficient use of data.
Conclusion
In this article, we looked at StackGAN and all its components.
- We understood how to decompose the task of generating novel images using a StackGAN.
- We looked at the architectural details of the StackGAN, its' embeddings, and the respective training stages.
- We also explored Conditional Augmentation and understood why it was proposed.