Streaming Ingestion in Big Data
Overview
Streaming data input is vital to Big Data processing since it allows for real-time data analysis and processing. It entails continuously recording and processing data as it comes in instead of batch processing, which processes data at regular intervals. Because of the growing requirement for real-time analytics in current applications such as IoT and social media, streaming ingestion technology has become prominent. It enables businesses to make quick, informed decisions, improve customer experiences, and increase operational efficiencies. With the rise of Big Data, streaming ingestion technologies will play an important role in data processing for many years to come.
Streaming Ingestion in Big Data
The practice of continuously collecting and processing data in real-time from numerous sources is known as streaming ingestion in big data. It enables firms to make informed decisions based on current data, giving them a competitive advantage.
In contrast to batch processing, which collects data in batches and processes it offline, streaming ingestion processes data as it is generated, allowing organizations to respond swiftly to changing conditions. Data acquired may include social media feeds, online logs, or machine-generated data.
Technologies like Apache Kafka, Apache Flume, and Apache Spark Streaming enable streaming ingestion. These technologies enable real-time data collection and processing while offering the scalability and fault tolerance required to manage enormous amounts of data.
Streaming ingestion and real-time processing provide advantages such as reduced latency, higher accuracy, and improved efficiency. As a result, organizations may respond to key events quickly, making timely decisions that greatly influence their business.
Here's a rough diagram for Streaming Ingestion in Big Data:
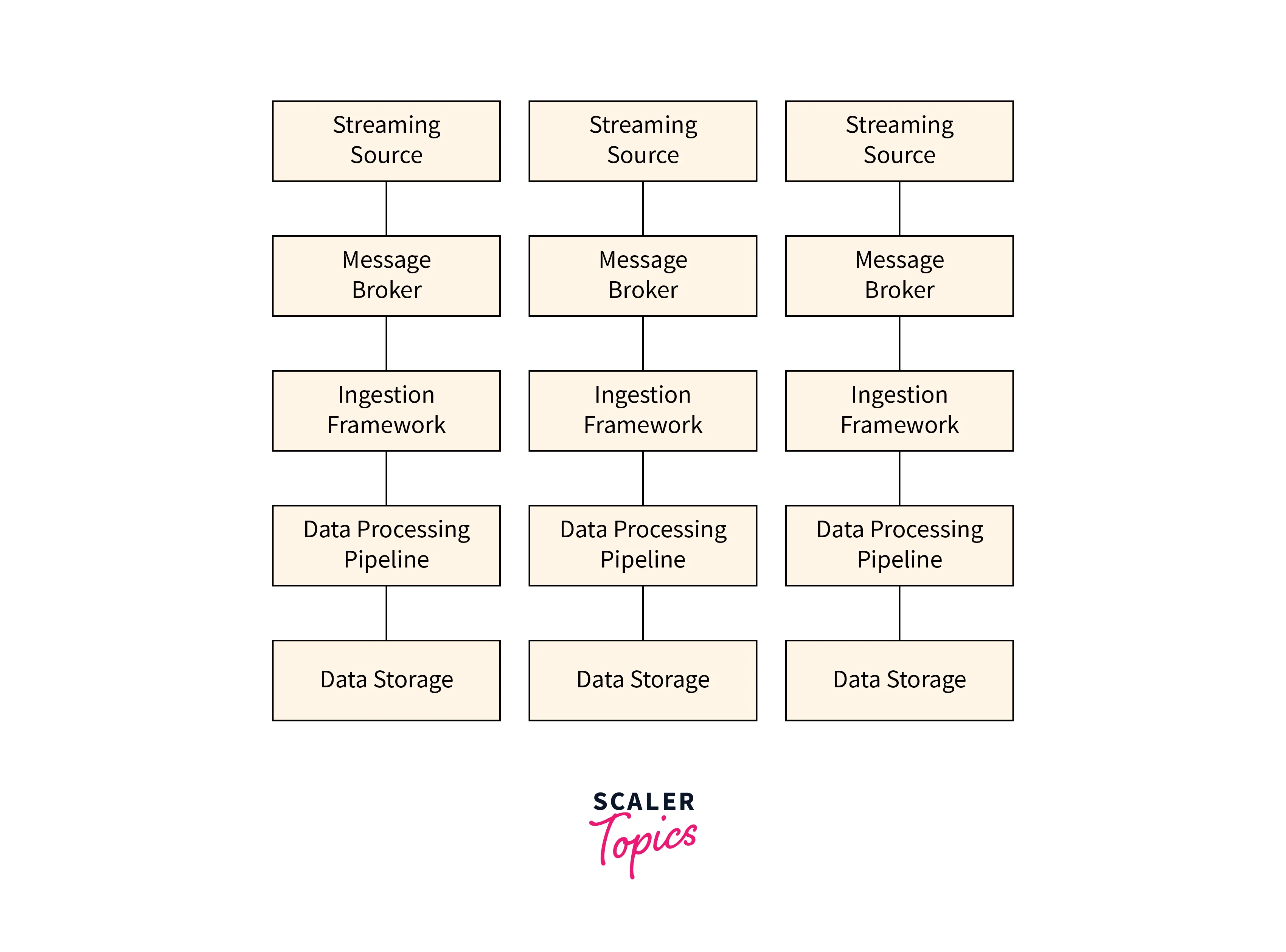
Streaming ingestion is important in big data processing since it allows enterprises to acquire and process data in real-time. In addition, it has considerable advantages over traditional batch processing, such as lower latency, more accuracy, and higher efficiency, making it a vital tool for firms wanting to remain ahead of the competition.
Flume
Big data is a term that refers to large, complex datasets that require specialized tools and techniques to manage and analyze. One such tool is Apache Flume, an open-source software platform designed for efficiently collecting, aggregating, and moving large amounts of data from various sources to the Hadoop Distributed File System (HDFS) for further processing.
Definition and Use Cases
In big data, Flume is a popular data ingestion tool used to collect, aggregate, and transfer large amounts of data from various sources to the Hadoop Distributed File System (HDFS) or other systems. It is an open-source tool that Cloudera initially developed, but now it is maintained by the Apache Software Foundation.
Flume is intended to handle massive amounts of data in real time by offering a dependable and scalable means of moving data between various data sources and destinations. It may consume data from various sources, including web servers, application logs, social media platforms, etc.
Flume's major use case is to collect log data from various sources and send it to HDFS for further analysis. This can assist firms in monitoring their systems and detecting any possible concerns. Before storing data in HDFS, it can also be used for processing and transformation operations like filtering, parsing, and aggregating.
Flume can also collect and transfer data from social media platforms like Twitter, Facebook, and LinkedIn. This allows businesses to monitor their brand's reputation and analyze sentiment in real-time. Flume may also be used for data analytics and warehousing by ingesting data from various sources into warehouses such as Hive, HBase, and Impala.
To summarise, Flume is a critical tool for large data processing widely utilized in banking, healthcare, retail, etc. Furthermore, its ability to gather and send enormous amounts of data in real-time is essential for big data initiatives.
Architecture of Flume
Flume is a distributed, dependable, and available system that collects and aggregates. It moves massive amounts of streaming data from diverse sources to centralized data stores such as HDFS (Hadoop Distributed File System) or HBase (Hadoop Database). Its architecture comprises three major parts: sources, channels, and sinks.
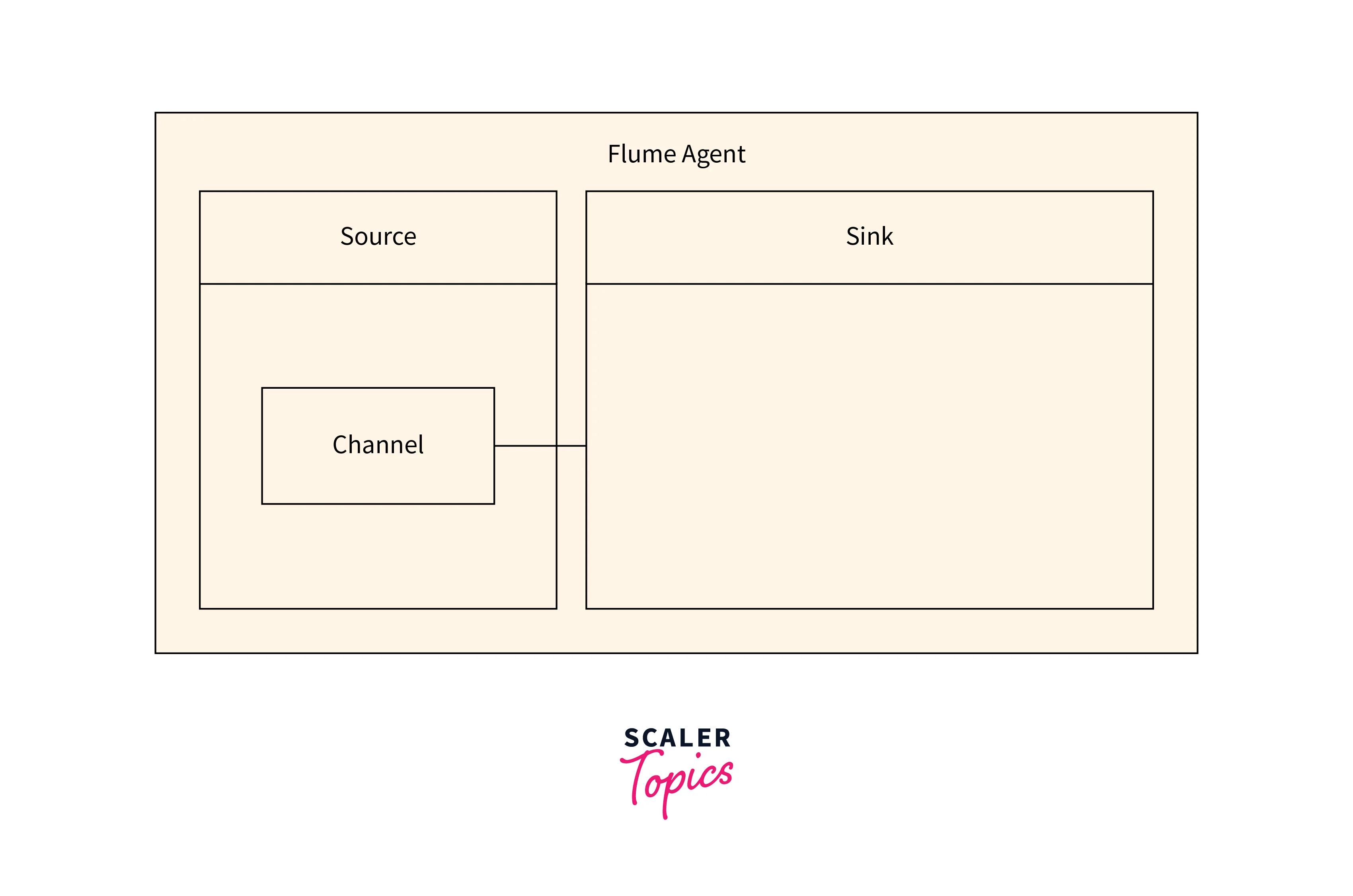
Sources are responsible for consuming data from various data generators, such as log files, social media feeds, or network traffic. Flume supports a range of sources, including Avro, Netcat, and Syslog, to accommodate various use cases.
Channels serve as a buffer between sources and sinks, allowing data to be staged and processed before it is committed to its final destination. Flume supports a variety of channels, including memory, file, and Kafka.
Sinks provide data to the end destination, which could be HDFS, HBase, or Solr. For example, Flume includes HDFS, HBase, and Elasticsearch.
Flume's modular and adaptable architecture allows users to add new sources, channels, and sinks to satisfy specific needs. It also has failover and load-balancing capabilities, allowing for high availability and scalability.
To summarise, Flume's architecture provides a flexible and robust platform for effectively gathering and processing massive amounts of data from various sources, making it a critical tool for big data analytics and real-time processing.
Flume Event
Flume is a distributed, dependable, and available system for efficient gathering, aggregating, and transporting massive amounts of streaming data. The Flume event is the basic data unit handled by the Flume system. It is a data packet including data, headers, and optional metadata.
Various systems, including web servers, sensors, and other data-generating devices, can generate flume events. They are routed to Flume agents, who gather, process, and transmit the events to the destination systems. The target systems may be a Hadoop Distributed File System (HDFS), Apache HBase, or any other system capable of real-time data processing.
Flume events can be configured to incorporate extra metadata such as timestamps, locations, or any other pertinent data. This facilitates the tracking and analysis of data as it flows through the Flume system. In addition, Flume's flexible design enables users to alter and personalize the system to meet their needs.
To summarise, Flume events are the foundation of the Flume system. They provide efficient and dependable real-time data collecting, processing, and transportation, making them a perfect solution for big data processing.
What are Agents in Flume?
Flume is a distributed system that is used to collect, aggregate, and move large amounts of data from various sources to a centralized location. The primary components of Flume are called Agents, which are responsible for moving data from one location to another. There are three types of Agents in Flume: Source, Channel, and Sink.
Let's first look at the rough diagram for Agents in Flume.
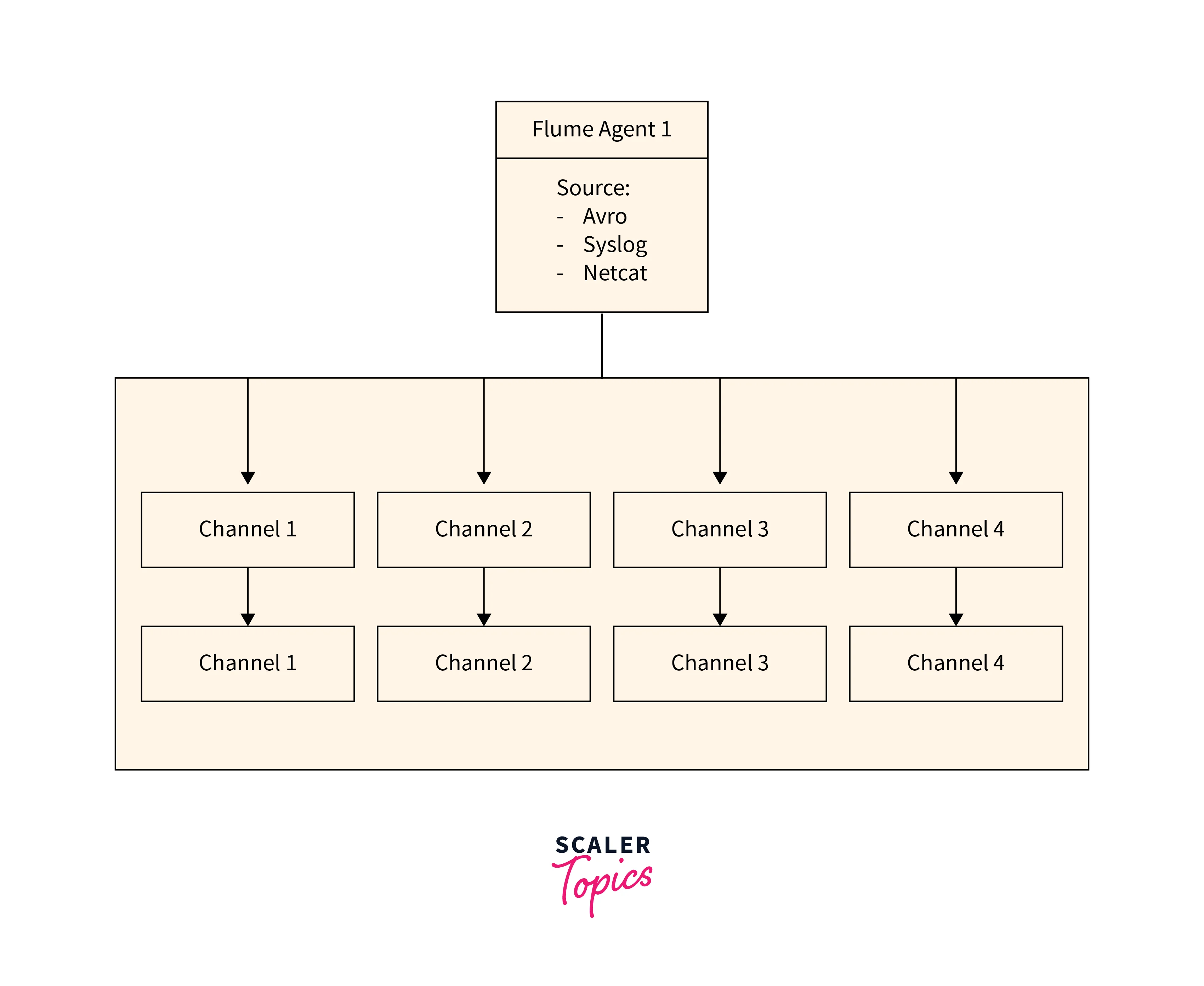
Source
A Source Agent is responsible for receiving data from a source, such as a log file or a message queue, and passing it to the Channel Agent for processing. The Channel Agent then stores the data temporarily in a buffer or queue until it is ready to be sent to the Sink Agent. Finally, the Sink Agent delivers the data to its final destination, such as a Hadoop cluster or a database.
Channel
The Channel Agent is a buffer between the Source and Sink Agents, ensuring that data is handled as efficiently and quickly as possible. The Sink Agent ensures that data is reliably delivered to its destination.
Sink
A sink agent receives data from Flume and writes it to a destination system like HDFS, HBase, or even a bespoke database. In Flume, it serves as the final destination of the data flow.
The sink agent can be set to provide fault tolerance, ensuring that data is not lost during system or network failures. It can also be configured to batch data writes, which improves the overall throughput of the data intake process.
Overall, Flume sink agents provide a dependable and quick method of ingesting data into Hadoop, making it a desirable tool for large data processing.
Data Flow Patterns of Flume
Flume has three primary data flow patterns: the pull model, the push model, and the hybrid model. The Flume agent pulls data from the source and sends it to the next stage in the pull model. Data is pushed from the source to the Flume agent and subsequently to the next stage in the push mechanism. Depending on the source and destination, the hybrid model employs both push and pull models.
Flume also offers a variety of data storage and processing channels. Memory, file, and JDBC channels are examples of these. The channel that is used is determined by the use case and the performance requirements.
To summarise, Flume provides several data flow patterns and channel options for efficiently moving massive amounts of data in big data contexts. Because of its simple and adaptable architecture, it is a popular choice for data input and transfer.
Fault Tolerance and Recovery in Flume
Flume is a free and open-source distributed data ingestion solution that makes it simple to collect, consolidate, and transport huge amounts of data from disparate sources to a centralized storage or processing system. Unfortunately, data importation is only sometimes simple, and errors might occur. Therefore, fault tolerance and recovery come into play here.
Flume includes fault tolerance and recovery tools to prevent data loss in the event of a failure. Flume can, for example, cache events in memory or on storage, repeat failed transactions, and recover from system crashes or network outages. Flume can also be set up with many channels, sinks, and sources, allowing redundancy and failover.
Flume delivers a strong and dependable data import system that can manage massive volumes of data with minimal data loss by exploiting these fault tolerance and recovery characteristics.
Retry in Flume
Having reliable data transfer systems in place is critical when dealing with huge data processing. Flume is a distributed, dependable, and available system for collecting, aggregating, and moving massive amounts of log data.
However, data transfer errors might occur due to network difficulties, server downtime, or other circumstances. Flume's retry feature comes in helpful in such instances.
Flume's retry mechanism automatically retries unsuccessful transactions, allowing uninterrupted data flow. Flume retries unsuccessful transactions using retry strategies like exponential backoff or constant latency.
Flume's retry feature, in general, increases the robustness and dependability of your data transfer process, lowering the chance of data loss and decreasing downtime.
Create an Application for Flume Demo
Create a basic Flume demo application to demonstrate Flume's capabilities.
To get started, you should have a basic understanding of Flume's architecture and configuration options. Once you have that, you can design a Flume agent that will take data from a source, change it (if necessary), and transmit it to a destination.
For example, you could develop an agent that listens for Twitter streams and writes the data to HDFS. Create a Twitter source that connects to the Twitter API and listens for tweets with certain keywords. Configure an HDFS sink to write the data to a specified HDFS directory.
Lastly, launch the Flume agent and watch it collect and store real-time tweets. The data can then be queried using Hadoop tools such as Hive or Pig.
By constructing a Flume demo application, you can demonstrate Flume's strength and flexibility in managing real-world data circumstances. It's a great approach to show how Flume can simplify and streamline data ingestion, ultimately allowing businesses to make better decisions based on data insights.
What is a Messaging System in Big Data?
A messaging system in Big Data is a framework that allows communication between multiple software components in a distributed system. It enables multiple programs to communicate and share data, allowing more efficient processing and analysis of enormous amounts of data.
With Big Data, there are two main types of messaging systems: point-to-point messaging and pub-sub messaging.
Point-to-Point Messaging
As the name implies, point-to-point messaging requires communication between two endpoints or systems. Messages are transmitted from a sender to a specific receiver in this communication. This approach is useful when there is an instant and direct requirement to convey a message from one program to another.
Pub-Sub Communication
Pub-Sub messaging, also known as publish-subscribe messaging, entails communication between several endpoints. In this mechanism, a publisher delivers a message to a topic, and the topic sends the message to numerous subscribers. This approach is suitable when numerous programs require the same message or when multiple subscribers require the same data to be processed.
Overall, messaging systems are critical in Big Data because they allow for efficient communication between applications, reduce the burden on individual systems, and ensure reliable data flow between systems. Selecting the appropriate messaging system for a given use case is critical for maximizing data processing and analysis in a distributed computing environment.
Introduction to Kafka
Kafka is a distributed messaging system that can manage massive volumes of data in real-time. LinkedIn created it, and the Apache Software Foundation now maintains it. Kafka, like a message queue or business messaging system, allows you to publish and subscribe to streams of records, but with many significant distinctions that make it well-suited for modern data-driven applications. It is extremely scalable and capable of handling millions of messages per second, making it a popular choice for log aggregation, stream processing, and real-time analytics. You may use Kafka to create strong, dependable, and scalable systems that can manage the demands of modern data-driven applications.
Kafka Storage Architecture
Kafka is a distributed streaming platform that allows you to process and store real-time data streams in a highly scalable and fault-tolerant manner. A log, a sequence of entries appended over time, is central to Kafka's storage architecture. Consumers can read the log in order since a unique offset recognizes each record.
Kafka's storage is intended to be extremely accessible and long-lasting. Data in a cluster is replicated among many brokers, ensuring that data is not lost in the case of a broker failure. Furthermore, Kafka has customizable retention periods, allowing data to be held for a set amount or until a certain size threshold is achieved.
Kafka's storage architecture is designed to handle high-throughput, real-time data streams, making it a perfect platform for event sourcing, log aggregation, and real-time analytics.
Kafka Topics and Partitions - Replication
Apache Kafka is one of the most popular technologies for processing large amounts of data. It is intended to be a distributed, fault-tolerant system capable of handling massive amounts of data in real-time. The capacity to divide data into topics and partitions is a major feature of Kafka.
A topic is a logical category into which data is organized, whereas a partition is a physically distinct block of data within a topic. For redundancy, each partition is replicated over numerous brokers, guaranteeing that data is never lost in the case of a breakdown.
Replication is an important component of Kafka that provides data availability and durability. Kafka can continue to function even if one or more brokers fail by duplicating data across many brokers. As a result, Kafka is an excellent solution for mission-critical applications where downtime is not an option.
Kafka Cluster Architecture
The Kafka cluster design comprises several critical components that work together to build a fault-tolerant and robust system. This article will examine the components of Kafka's cluster architecture and how they work.
Here is a rough diagram for a Kafka cluster architecture:
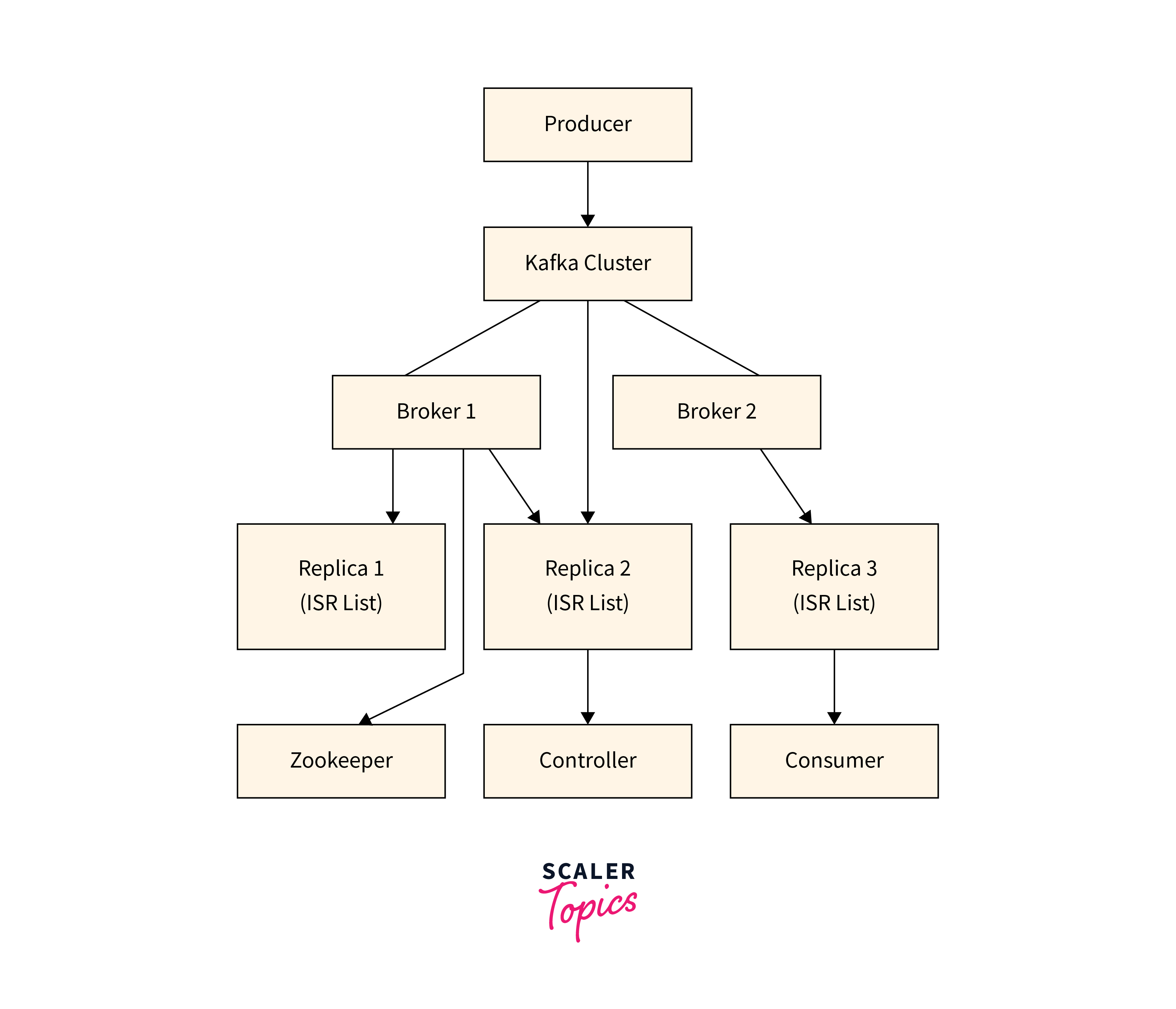
Zookeeper
Zookeeper is the first critical component in Kafka's cluster design. Zookeeper is a distributed coordination service that controls the Kafka brokers' configuration and state. It maintains track of which brokers are currently available and handles topic and partition distribution among them. It also keeps track of the health of the Kafka brokers and guarantees that the system runs smoothly.
Controller
The Controller is the second component of Kafka's cluster design. The Controller controls the brokers' states, including selecting which broker the leader is for each partition. It also handles partition reassignment when a broker fails, assuring the system's fault tolerance.
Partitioning - Fault Tolerance, Partition Leader vs. Partition Follower
Partitioning is a fundamental component of Kafka's cluster architecture. Each topic in Kafka is separated into numerous partitions, then disseminated over the available brokers. Whenever a broker fails, the Controller will transfer the partitions to other brokers to ensure the system continues operational.
ISR List
Each partition has a selected leader and several followers. The leader is the one who handles all the read requests and writes requests for that partition. On the other hand, the followers are responsible for replicating the leader's data to offer fault tolerance. The followers track which brokers have a complete copy of the data by maintaining an in-sync replica (ISR) list. If followers fall behind the leader, they will be removed from the ISR list and barred from voting for future leaders until it catches up.
Transactions Committed vs. Uncommitted
Finally, Kafka ensures data integrity by employing the concept of committed and uncommitted transactions. Uncommitted transactions are not guaranteed to be stored to disc and are not regarded as final, whereas committed transactions can still be rolled back in case of an error or failure.
Finally, the cluster architecture of Kafka is a sophisticated system that needs numerous critical components to provide fault tolerance and real-time processing capabilities. We can better appreciate Kafka's power and flexibility as a streaming platform by knowing how Zookeeper, the Controller, partition allocation, the ISR list, and transaction management interact.
Conclusion
- Streaming ingestion enables enterprises to make educated decisions faster than ever by processing data in real-time as it is generated.
- Unlike typical batch processing, which requires data to be gathered and stored before analysis, streaming ingestion enables continuous analysis, reducing latency and providing a more accurate data perspective.
- Streaming ingestion has several advantages, including the capacity to manage enormous amounts of data, support for numerous data formats, and simple connection with other big data technologies.
- However, because streaming ingestion involves specific expertise and infrastructure, organizations must carefully assess their requirements and use cases before implementing it.
- Depending on their needs, organizations can select from several streaming ingestion solutions, including Apache Kafka, Apache Flink, and Apache Storm.