Supervised and Unsupervised Learning

Overview
Supervised Machine Learning is the way in which a model is trained with the help of labeled data, wherein the model learns to map the input to a particular output.
Unsupervised Machine Learning is where a model is presented with unlabeled data, and the model is made to work on it without prior training and thus holds great potential on real-world labelless datasets.
What is Supervised Machine Learning?
Supervised Machine Learning involves training a model with labeled data. By labeled data, we mean that the data should have a clear mapping between the input features (X) and the output variable (Y).
As we train/teach our model with this mapping, it is called 'supervised' learning.
The basic principle of supervised machine learning is to have a model that has learned a set of mappings in a generalized manner such that it can generate correct labels (or outputs) for new data that it has never seen. The model is trained until it makes the minimum possible error.
Some examples of supervised Machine Learning in real-life applications may be:
- Face detection/recognition.
- Weather forecasting.
- Spam Detection.
- Stock price prediction.
Working of Supervised Learning
Let us understand the working of supervised Machine Learning with the help of an example:
Think of it as teaching a toddler about what is a cat or a dog, or maybe what are the different kinds of fruits. What you may want to do is, show the kid pictures and videos of cats and dogs (or show them in person what a cat/dog looks like).
You may tell them about the features and characteristics of it. Such as a cat has whiskers and meows, a dog barks, etc. You may show them what cats and dogs look like.
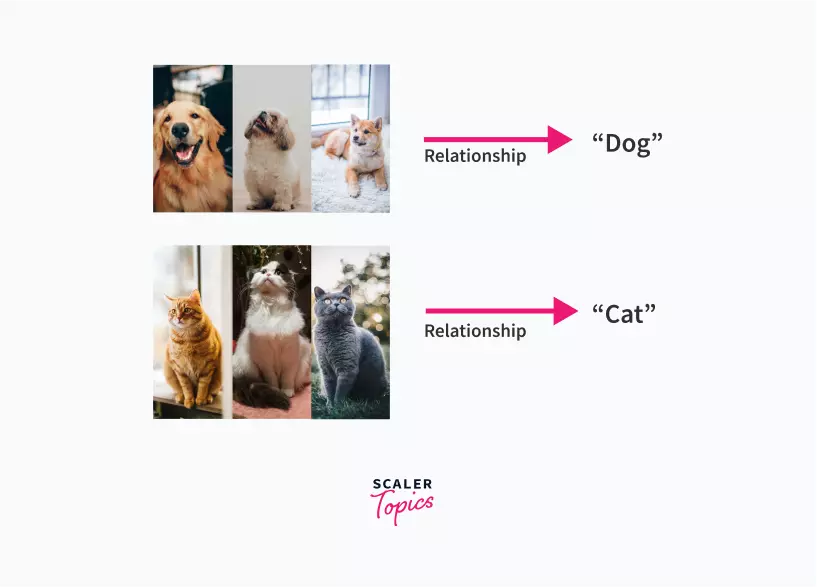
Next time, when you ask them to identify whether the animal is a cat or a dog, and if the kid is able to identify it correctly, this means you successfully taught them!
If not, you'll help them identify it correctly by showing more examples, and eventually, they will learn what a cat/dog looks like.
This is the same way supervised learning works. Following is the way in which formally Supervised Learning works:
A Supervised Learning model is trained with labeled data and is allowed to learn the underlying relationship between the input features and output variable.
Once the training is complete, we test the performance of our model with test data, which is new for the model, i.e., the data is unseen. Test data is usually part of the training set, which we keep separately for testing our model. We perform the testing using different loss functions and other metrics. It keeps adjusting its parameters until good accuracy is achieved, and the model starts giving satisfactory results even on unseen data.
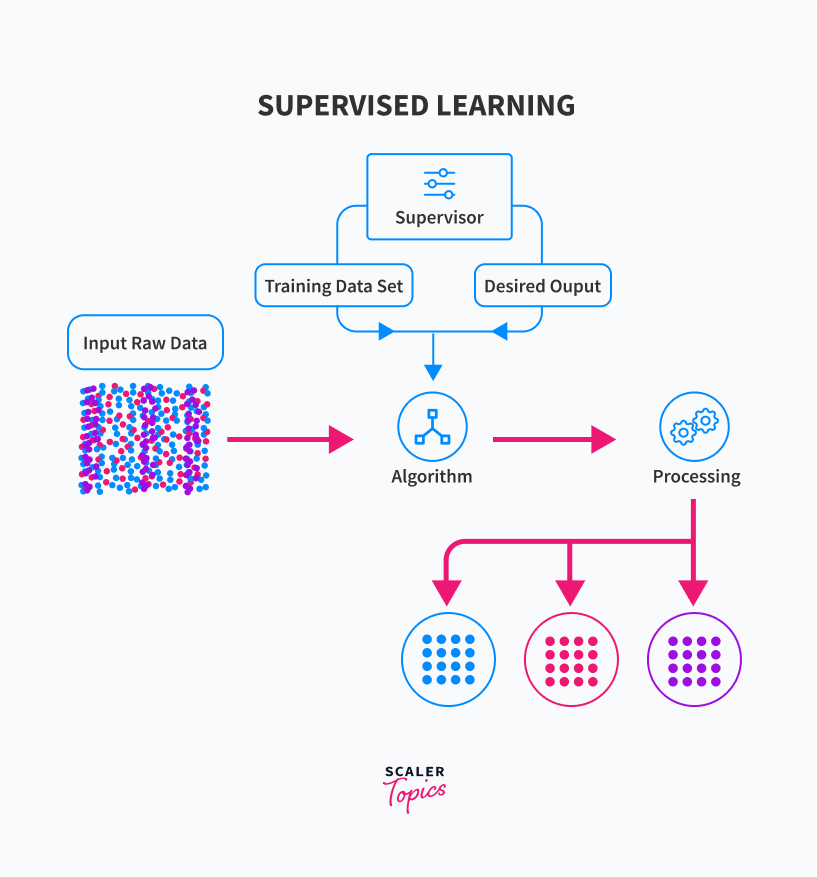
Now that we have a basic understanding of Supervised Learning, let us discuss its types.
Types of Supervised Learning
Broadly, supervised learning is of two types:
- Regression.
- Classification.
Regression is the kind of supervised learning that learns from labeled data and predicts continuous-valued output corresponding to a given input. Examples of such continuous outputs may be height, amount of money, etc.
Classification is the kind of supervised learning that learns from labeled data and is used to predict a particular class corresponding to a given input. An example of an output class can be 'cat' or 'dog' to classify if the given picture is of a cat or a dog.
Regression
Regression is a type of Supervised Machine Learning that we use to understand and map the statistical relationship between the predictor and response variables. This is generally useful with numerical data such as sales revenue and temperature trends.
The following are the major types of regression algorithms:
-
Linear Regression: In this type of supervised learning, the model aims to find the underlying relationship/pattern between the independent variables (X) and the dependent variable (Y) by plotting a best-fit line, which is (in most cases) determined by the method of least squares.
-
Simple Linear Regression: This is the type of linear regression is used when we apply our model to find the underlying relationship between a single independent variable and a single output variable.
-
Multi-linear Regression: This is similar to the simple linear regression, just the difference being that the number of independent variables, in this case, is more than one.
-
-
Logistic Regression: Contrary to linear regression, in the case of logistic regression, the model aims to solve the problems of classifications such as problems that have outcomes like 'True' or 'False,' '0' or '1' or even multiple categories. Each category is assigned a probability between 0 to 1, where all probabilities of all classes sum up to 1.
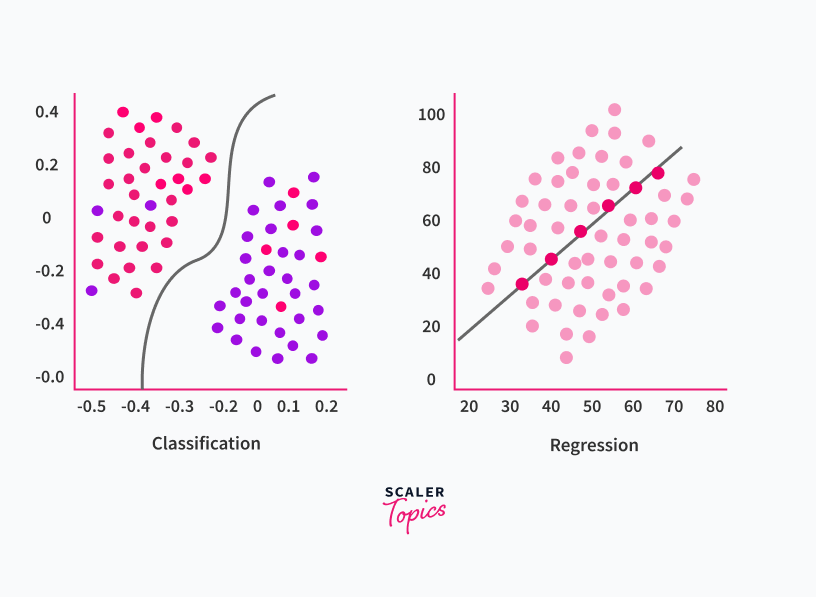
Classification
Classification is the type of Supervised Machine Learning that we use to categorize our output into one of the defined categories, such as 'spam' or 'not spam,' 'masked' or 'not masked' etc.
Classification can be done into two or more than two categories, therefore the broad categories: binary and multi-class classification.
An example of a binary classification will be to classify if an e-mail is a spam or not spam. Same way, an example of multi-class classification can be taken as a classification of dog breeds.
Following are a few examples of classification algorithms:
-
Support Vector Machines: SVMs are the most commonly used models to determine clear separations/classifications of our data points.
-
Decision Trees: As the name suggests, these are models that represent a tree, where each node represents a condition, and the branches represent the agreement or disagreement to the condition.
-
Random Forest: It involves the usage of multiple uncorrelated decision trees, whose results are combined in the end to extract the best predictions.
Advantages and Disadvantages of Supervised Learning
-
Advantages
- Supervised Learning's biggest advantage is that we can have a directed end-point to our problem. We can make the model focus clearly on the output classes that we define or desire to classify into.
- Supervised learning helps with a lot of predictive tasks, where we can make best use of past data to generate predictions corresponding to new data.
- When accuracy and correct classification are crucial factors for our problem, supervised learning models are the best choice.
-
Disadvantages
-
Training over large datasets makes Supervised Learning a computationally expensive and time-consuming process.
-
While knowing the classes we want to classify our data into prior to working on our model is considered an advantage in Supervised learning, in cases when the output classes are not known, it can be one of the drawbacks carries.
-
Data pre-processing is a big challenge while working with supervised learning algorithms.
-
What is Unsupervised Machine Learning?
Contrary to Supervised learning, Unsupervised Learning involves presenting the model with unlabelled data. This means that the data does not have any labels or categories, and there is no training involved. This type of learning can be considered as learning without any guidance. The model is left open to learning on its own by detecting the co-relations between the features without any expected output.
The basic principle of unsupervised learning is to learn in the absence of any ground truth to compare our model with. The idea is to use the underlying patterns in the data to generate a reconstruction of the input data in a useful format. By 'underlying patterns in the data, we mean that the data is then explained on the basis of similarities, hidden patterns, etc., all without any human intervention.
Some examples of unsupervised Machine Learning in real-life applications may be:
-
Recommendation Systems.
-
Customer segmentation.
-
DNA clustering.
Working of Unsupervised Learning:
Let us understand the working of unsupervised Machine Learning with the help of an example:
Suppose we give our model unlabeled images of red-colored fruits, such as pomegranates, apples, and plums. Our model hasn't seen or known any kind of fruits before and will now try to categorize the images on the basis of similarities and differences in the structure and appearance only. We will let the model discover the hidden patterns in the data itself.
Combine these two according to the first picture with a fruit example.
Same way, in recommendation systems, unsupervised learning algorithms help cluster commodities that are frequently bought together.
This further helps the sellers to provide recommendations to the buyers, many of which we have seen quite a lot of times on online selling platforms such as "Frequently bought together" and "Customers who bought this, also bought this."
Now that we have a basic understanding of Unsupervised Learning, let us discuss its types.
Types of Unsupervised Learning
Unsupervised learning is mainly of two types:
- Clustering.
- Association.
Clustering or cluster analysis is used when we want to group our dataset on the basis of inherent similarities in the data.
Association rules are used when we are trying to explain the dependence relationship between the data that are usually seen together. In simple words, we may want to explain the dependence of how Y happens after X happens, i.e.: X -> Y.
Clustering
Cluster analysis is the most common method used in Unsupervised Learning. We tend to perform cluster analysis on our dataset when we are working with unlabeled data, wherein our model discovers patterns on its own without any human intervention.
The objects in our data with similarities are grouped into a cluster, and different clusters have objects with different characteristics.
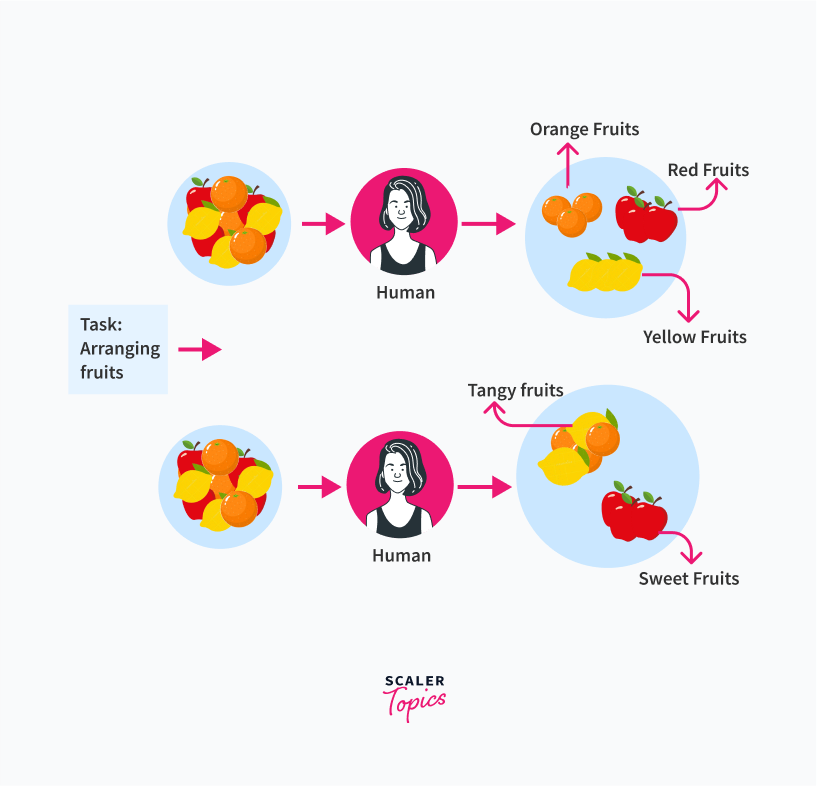
Let us understand the analogy of clustering with an example. Consider a group of people who are provided with a fruit basket with different types of fruits. They are then asked to group (or arrange) the fruits in different categories. They are not given any criteria for grouping, so there is no correct grouping that needs to be done.
Someone may group the fruits according to their taste, such as sweet, tangy, etc. Some may group the fruits according to their color, such as yellow, red, etc.
For every person, there might be a different cluster they may put fruit into. This is how clustering works too. Even with no task set, there might be various hidden patterns that cluster analysis may unfold.
There are mainly three types of clustering:
-
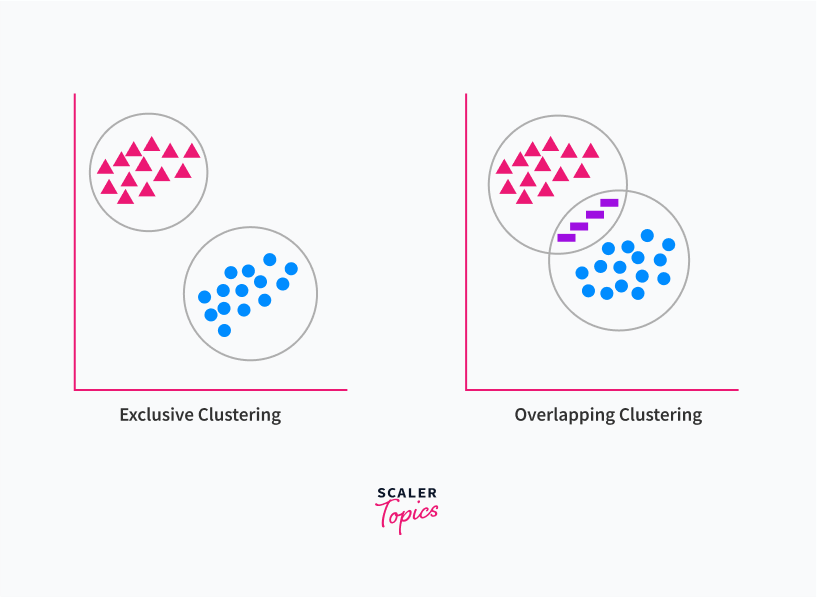
Hard Clustering: Also known as exclusive clustering, wherein one part of data can only belong to one cluster only.
An example of a Hard Clustering algorithm can be taken as K-means clustering. It is the most common type of iterative clustering performed where the data objects are put into K number of clusters.
K is the input parameter, and accordingly, the data items are assigned to the nearest cluster center and are done iteratively until the clusters are formed properly. One data point belongs to one cluster only.
-
Soft Clustering: Also known as overlapping clustering, wherein one part of data can be a part of more than one cluster.
An example of a Soft Clustering algorithm can be taken as Fuzzy K-means clustering, where one data point is not bound to a single cluster. There may be cases when due to this reason, the clusters may overlap with each other.
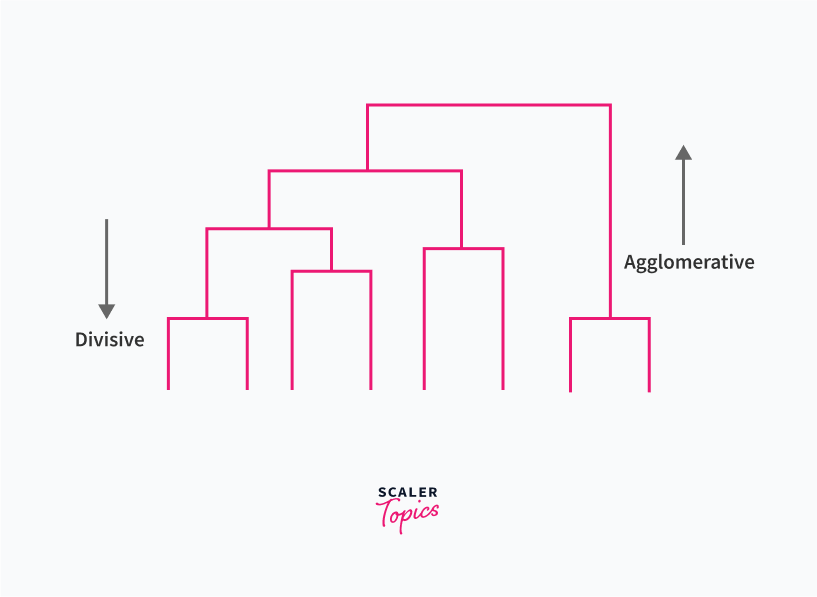
- Hierarchical Clustering: In this type, the model tends to create a hierarchy of clusters. Working with hierarchy can happen in two ways:
-
Agglomerative hierarchical clustering: This is also known as bottom-up custering. In this kind of hierarchical clustering, every data point is considered a cluster, and based on the distance between the points, they are merged iteratively until the combined clusters end up in a single cluster of all data points.
-
Divisive hierarchical clustering: This is also known as top-down clustering. This is the complete opposite of agglomerative clustering, where we start from one whole cluster and iteratively perform splits to perform separate clusters until we reach every data point as a separate cluster.
-
Association
Association rules are used when we want to find the dependence of one data item on another, such as X->Y, which means if X, then Y. One of the most common examples of association rules may be the video recommendation that we get after watching any video.
For example, on Netflix, when we watch a movie, we are provided with recommendations of similar movies under the tab "Because you watched this, you may also like it."
Application of association rules to transaction data can prove to be very useful for increasing sales and hence, profit. This is known as Market Basket Analysis, which is often used by retail companies.
We may find several hidden relationships about the items that are frequently bought together, such as computer systems and anti-virus software, bread, and milk, or a set of more than two items as well, such as vegetables that are frequently bought together. This leads to the companies having clearer insights as to what items the customers buy together.
Advantages and Disadvantages of Unsupervised Learning
-
Advantages
- Given the unavailability of labeled data and the huge amount of uncategorized data all around the world, Unsupervised Learning can prove to be very useful in drawing the best insights from data in all possible domains, such as healthcare, education, finances, etc.
- At times when the output classes are not defined, and we do not know what relationship the data items hold, unsupervised learning algorithms help discover the categories in the data.
-
Disadvantages
- Sometimes, we may have a different goal from what our model finds in the data. This may lead to a waste of computational resources and time.
- Since there is no ground truth to compare the model outputs with, we cannot make sure if our model is performing well or not. This, in turn, leads to less accurate results.
Supervsed Learning v/s. Unsupervised Learning
Now that we have discussed all Supervised and Unsupervised Learning, let us compare them to understand which type of learning we should pick for the best outcomes.
- Evaluate the type of data at hand. According to the data being labeled or unlabeled, choose Supervised or Unsupervised learning, respectively.
- Find out the level of human intervention your problem requires. In the case of Supervised Learning, we may have the ground truth and evaluation metrics to assess our model. In the case of Unsupervised Learning, we may require subject matter experts to assess if our model is performing well.
- Define a goal for your problem. Is there a particular direction you want your model to into? Are there pre-defined ground truths? Then Supervised Learning is what you should go with. On the other hand, if the problem statement at hand allows you to be open to discovering new patterns and insights, then Unsupervised Learning will help.
- Research about related problems. Research similar use cases and see what solutions were built up earlier and what kind of Machine Learning algorithms proved to be useful.
Conclusion
- With the great rise in Machine Learning in recent years, key Supervised and Unsupervised Learning algorithms are proving to be the most useful and helpful when it comes to even the most complex problems.
- While Supervised Learning involves supervision with labeled data, it paves the way for predictive tasks that can make the best use of past data to generate predictions for the future.
- On the other hand, Unsupervised Learning opens doors for tasks where we may find surprising results about the hidden patterns in the data.