Custom Training with TensorFlow
Overview
In TensorFlow, training models is a crucial process that allows machine learning algorithms to learn from data and make accurate predictions. While TensorFlow provides high-level APIs that simplify training, custom TensorFlow training loops offer more flexibility and control over the training process.
In this guide, we will explore the importance of custom Tensorflow training loops and walk you through the implementation of one using TensorFlow.
What is the TensorFlow Training Loop?
The Tensorflow training loop comprises the necessary steps to update the model's parameters, also known as weights, to minimize the difference between predicted outputs and actual target values. This difference is measured using a loss function, and the process of reducing this loss is known as optimization.
Optimization techniques, such as backpropagation and algorithms like Gradient Descent, guide the adjustment of these weights, propelling the model towards more accurate predictions. TensorFlow's arsenal of optimization tools allows practitioners to fine-tune training processes, ensuring that the model learns and adapts effectively from data, resulting in improved performance and better generalization to unseen examples.
- It involves iterating through the training data multiple times, known as epochs, to gradually improve the model's performance.
- During each iteration, the model predicts the output based on the input data, and the difference between these predictions and the actual target values is calculated using a loss function.
- The loss function quantifies how far the model's predictions are from the true values, serving as a measure of prediction accuracy.
- The primary goal of the training loop is to minimize this loss, i.e., to make the model's predictions as close to the target values as possible.
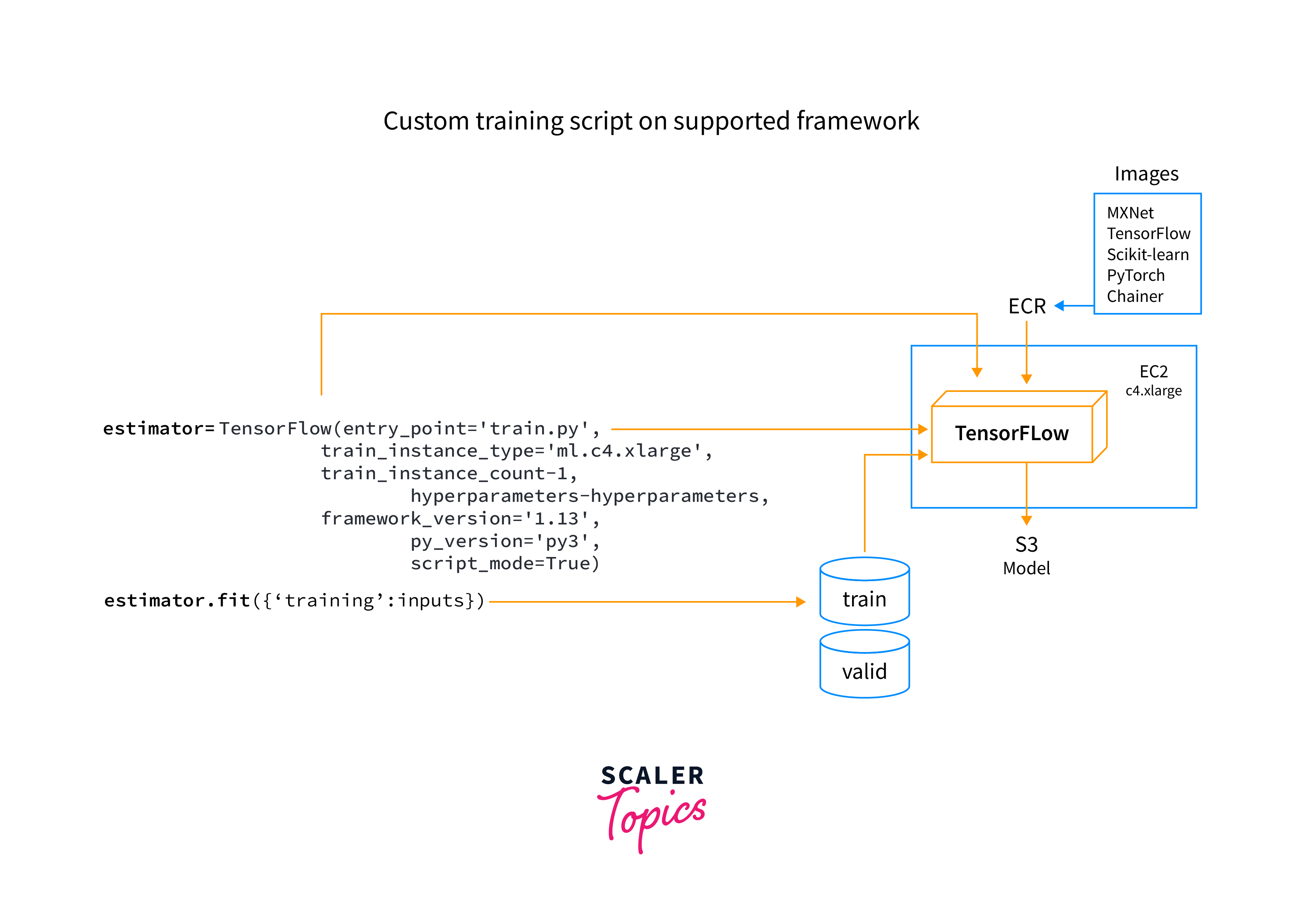
Importance of Custom Tensorflow Training Loop
Though TensorFlow offers high-level APIs like tf.keras to simplify training, custom training loops are essential when you need more fine-grained control over the TensorFlow training process. Custom loops allow you to customize the loss computation, apply advanced optimization techniques, and introduce custom metrics to monitor model performance.
TensorFlow's custom training loops provide a pathway for incorporating custom callbacks, enabling actions to be executed at specific stages during training. While high-level APIs like tf.keras offer simplicity, custom training loops step in when greater control over the TensorFlow training process is required.
-
Fine-Grained Control:
Custom TensorFlow training loops provide developers with more precise control over the training process compared to high-level APIs like tf.keras. This level of control allows for fine-tuning and adapting the training process to specific requirements and unique scenarios.
-
Customized Loss Computation:
In custom TensorFlow training loops, you can define and implement custom loss functions tailored to your specific problem. This flexibility is crucial when dealing with non-standard loss functions or specialized tasks that require unique performance measures.
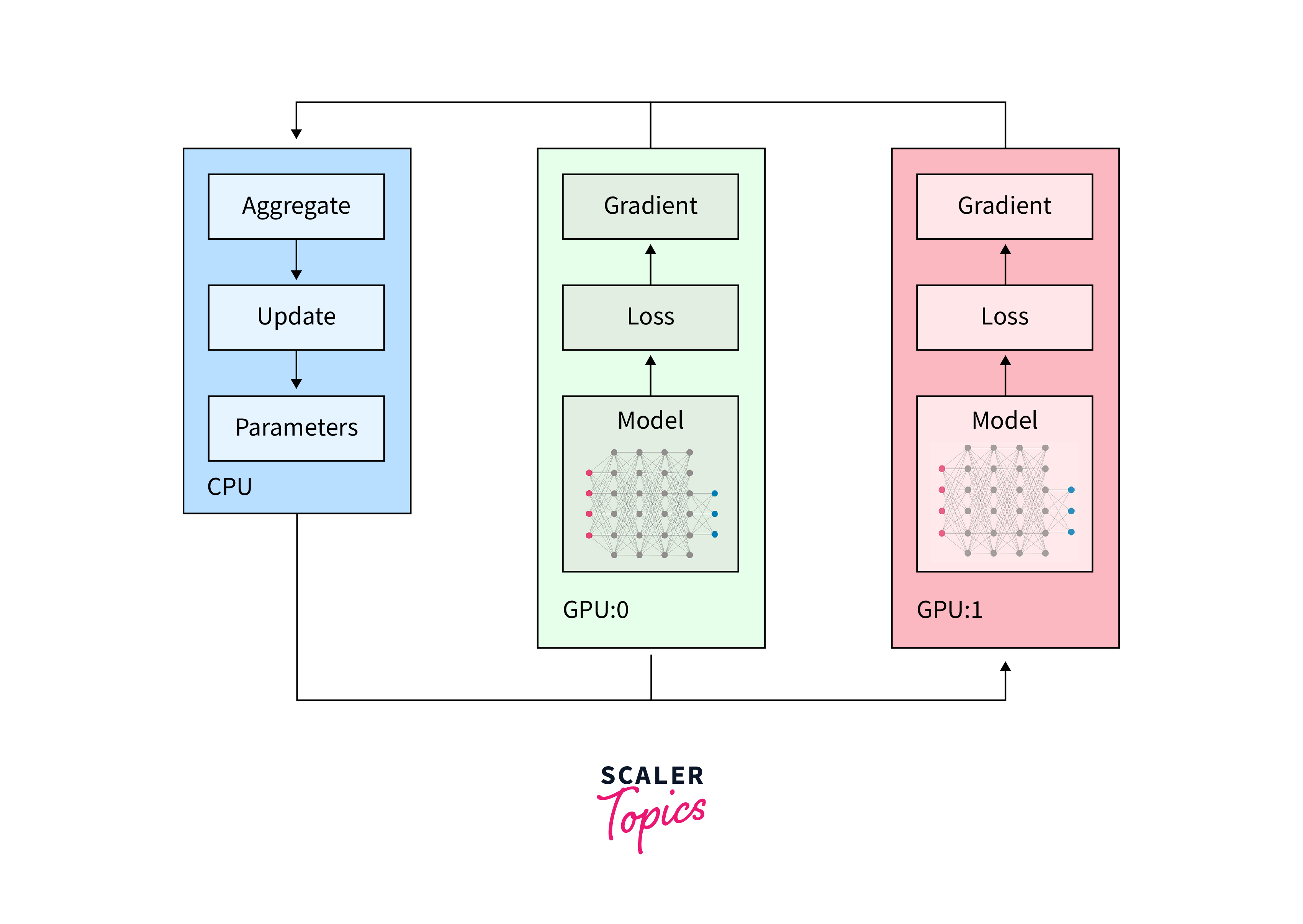
-
Advanced Optimization Techniques:
With custom training loops, you can implement advanced optimization techniques, such as learning rate schedules, weight decay, and gradient clipping. These techniques enhance model convergence and stability, leading to improved performance.
-
Custom Metrics Monitoring:
Custom TensorFlow training loops enable the incorporation of custom metrics to monitor model performance during training. This capability allows you to track specific evaluation metrics that might not be available by default in high-level APIs.
Implement a Custom TensorFlow Training Loop
By implementing a custom tensorflow training loop, you gain a deeper understanding of the training process and can experiment with various hyperparameters and techniques to improve model accuracy.
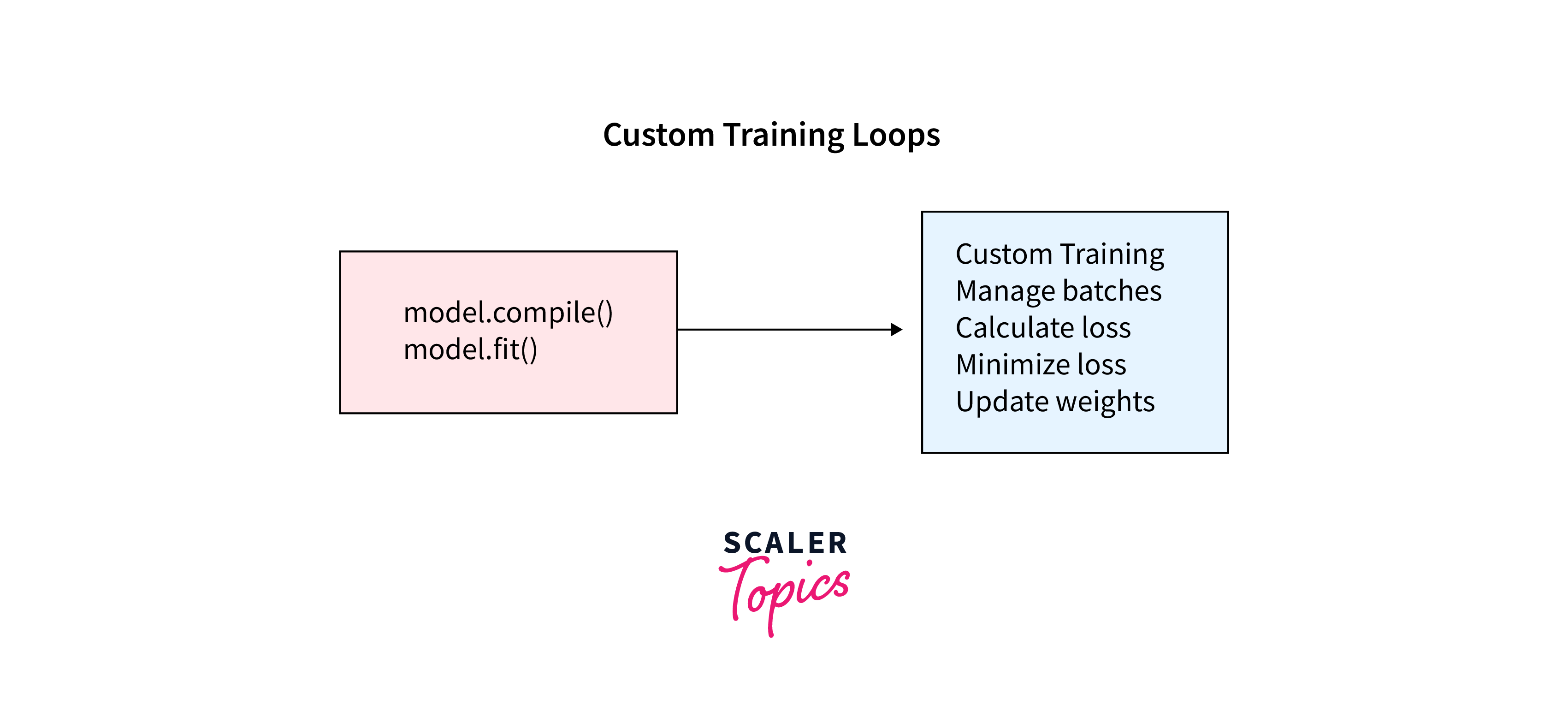
Let's delve into creating a custom training loop using TensorFlow. We'll define the following steps:
Step 1: Data Preparation:
Load and preprocess the training data involves reading the data, handling missing values, scaling numerical features, encoding categorical variables, and splitting the data into training and validation sets, ensuring it is ready for model training.
This tailored approach facilitates the incorporation of crucial practices, such as shuffling training data, which helps break patterns in the input sequence, reducing the risk of the model memorizing the order and thereby improving generalization. As a result, you wield the power to optimize every facet of training, from loss computations to optimization algorithms, enabling you to extract the utmost performance from your machine learning models.
Step 2: Model Creation:
Model Creation involves designing the structure of a neural network, specifying the number of layers, types of activation functions, and the connections between neurons, to construct a computational graph that will be trained to perform the desired task. The architecture defines the blueprint of the model, determining how it processes input data and makes predictions.
The 'softmax' activation is specifically tailored for multi-class classification problems because it produces a probability distribution over the possible classes.
Step 3: Loss Function:
Loss Function quantifies the discrepancy between the model's predictions and the actual target values, indicating how well the model is performing on the task at hand. It serves as the guide for the optimization process during training, aiming to minimize the loss to improve prediction accuracy.
For instance, in the context of classification tasks involving multiple classes, 'sparse_categorical_crossentropy' is a commonly employed loss function. This choice is appropriate when dealing with integer-encoded class labels, as it calculates the cross-entropy loss between the true labels and the predicted class probabilities.
Step 4: Optimizer:
Optimizer is a crucial component in the training process, responsible for adjusting the model's parameters (weights and biases) based on the computed loss. It uses optimization algorithms, like stochastic gradient descent (SGD) or Adam, to update the model iteratively and guide it towards minimizing the loss, leading to improved model performance.
- Optimizers like stochastic gradient descent (SGD) work by adjusting the parameters in the direction that reduces the loss, while considering only a subset (or a "mini-batch") of the training data at each iteration.
- Adam, on the other hand, adapts the learning rate for each parameter individually, combining the benefits of both adaptive methods and momentum-based techniques.
- RMSprop is another popular optimizer that effectively adjusts the learning rates based on the magnitudes of the recent gradients.
Step 5: Training Iterations:
Training Iterations involve looping through the training data multiple times (epochs), updating the model's parameters using an optimizer and computed gradients, which helps the model learn from the data and improve its predictions over time.
During these training iterations, various techniques can be employed to enhance the model's performance and prevent issues:
-
Regularization Techniques:
Regularization methods like L1 and L2 regularization can be introduced to prevent overfitting. These techniques impose constraints on the model's parameters, encouraging it to learn more robust and generalized features.
-
Learning Rate Decay:
Implementing a learning rate decay strategy can help stabilize and fine-tune the training process. Gradually reducing the learning rate over time allows the model to make smaller adjustments as it approaches convergence.
-
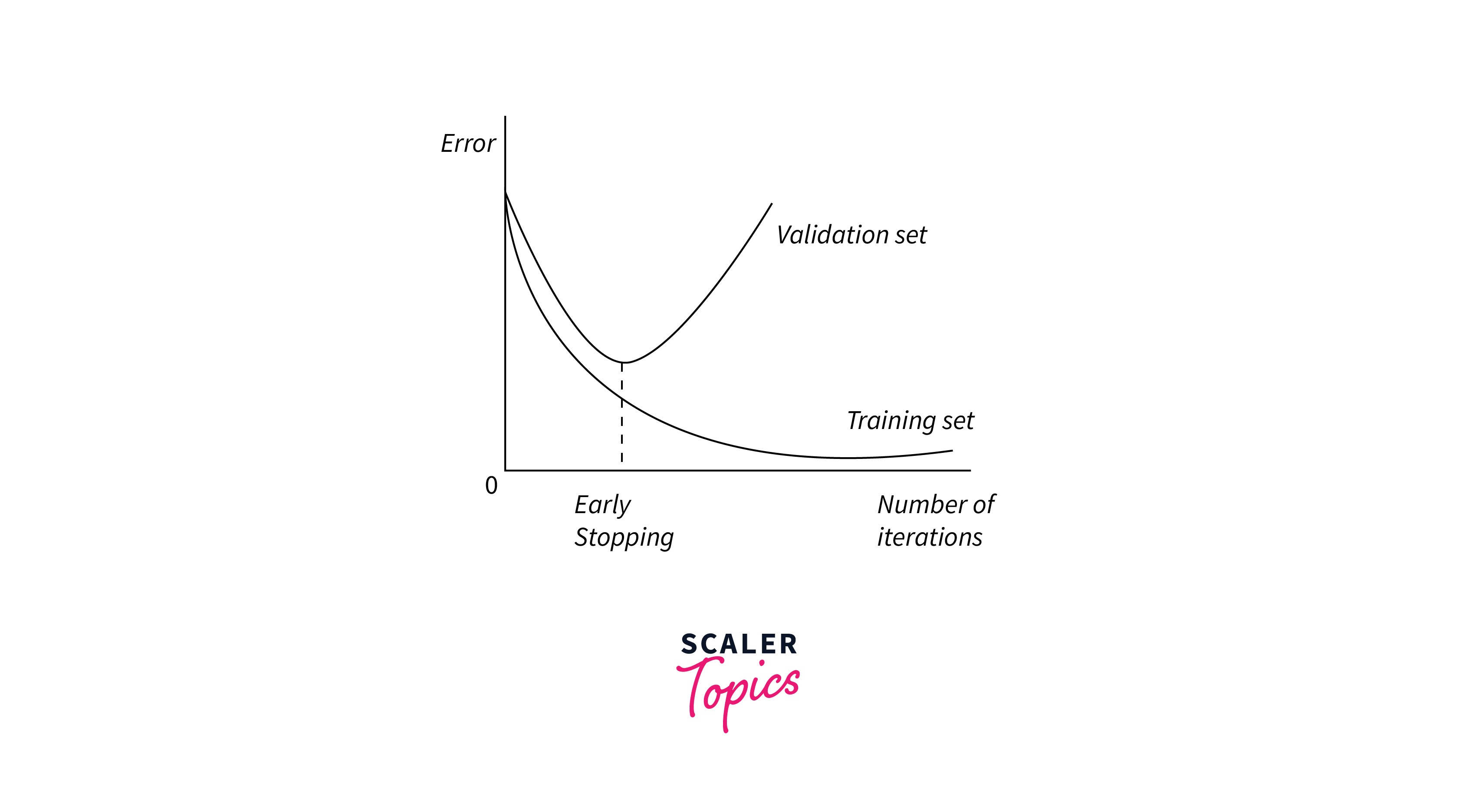
Early Stopping:
To prevent overfitting and optimize training time, early stopping can be applied. This involves monitoring a validation metric (e.g., validation loss) and halting training when the metric stops improving, indicating that further training may lead to worse generalization.
-
Error Handling and Checkpoints:
Handling potential issues during training, such as diverging model behavior, is crucial. Implementing checkpoints at regular intervals allows you to save the model's progress. In case the model starts to diverge, you can revert to a previously saved checkpoint to resume training from a stable point.
Step 6: Monitoring:
Monitoring allows you to observe and analyze various metrics, such as accuracy, loss, or custom evaluation metrics, during model training. It provides insights into the model's performance and helps identify potential issues or areas for improvement, aiding in optimizing the model's architecture and hyperparameters.
Output:

Adding Custom Logic to the TensorFlow Training Loop
In some machine learning projects, you might encounter unique scenarios that require custom logic during the training process. TensorFlow allows you to add your own custom logic to the training loop, giving you full control over how the model updates its weights and biases. This flexibility enables you to experiment with innovative strategies, adjust learning rates dynamically, or implement specialized regularization techniques.
Define Custom TensorFlow Training Loop:
To add custom logic to the TensorFlow training loop, you'll need to create a custom training function that handles the training iterations. This function will loop through the data, compute gradients, update the model, and incorporate your custom logic. This version uses a more high-level approach with model.fit() for training and validation.
Output:

Training models with Custom TensorFlow Training Algorithms
Training machine learning models is a critical step in the development of any AI system. While popular deep learning frameworks like TensorFlow provide high-level APIs that streamline the training process, there are instances where the standard training routines may not be sufficient. In such cases, creating a custom TensorFlow training loop becomes necessary to introduce specific logic and optimizations tailored to the problem at hand.
The custom TensorFLow training loop is a powerful concept that allows machine learning practitioners to exert fine-grained control over the training process. It grants the freedom to incorporate custom logic, implement advanced techniques, and experiment with novel strategies that can significantly impact model performance and convergence. After defining the custom training loop function, you can invoke it to train your model with the desired custom logic.
The standard training routines offered by high-level APIs may not always be sufficient to tackle certain tasks or datasets. The inherent constraints of these routines can limit a model's performance and adaptability, especially when dealing with complex or specialized scenarios.
For specific tasks or datasets, the intricacies of the problem may require a more tailored approach. This is where the custom TensorFlow training loop comes into play. By utilizing a custom training loop, machine learning practitioners gain the ability to exert fine-grained control over every aspect of the training process.
Sample Output:
- Within the custom TensorFlow training loop, each epoch iterates through the training data in batches, computes the gradients of the loss with respect to the model's trainable parameters using TensorFlow's GradientTape, and applies the gradients to update the model's weights using the chosen optimizer.
- This fundamental process remains intact in the custom loop, allowing for seamless integration of custom logic and advanced techniques.
Implementing Advanced TensorFlow Training Techniques
To improve model performance and convergence, you can implement advanced TensorFlow training techniques in TensorFlow. These techniques include learning rate schedules, early stopping, and gradient clipping. Leveraging these techniques can help you achieve better generalization and stability in your machine learning models.
Here are few advanced TensorFlow training techniques:
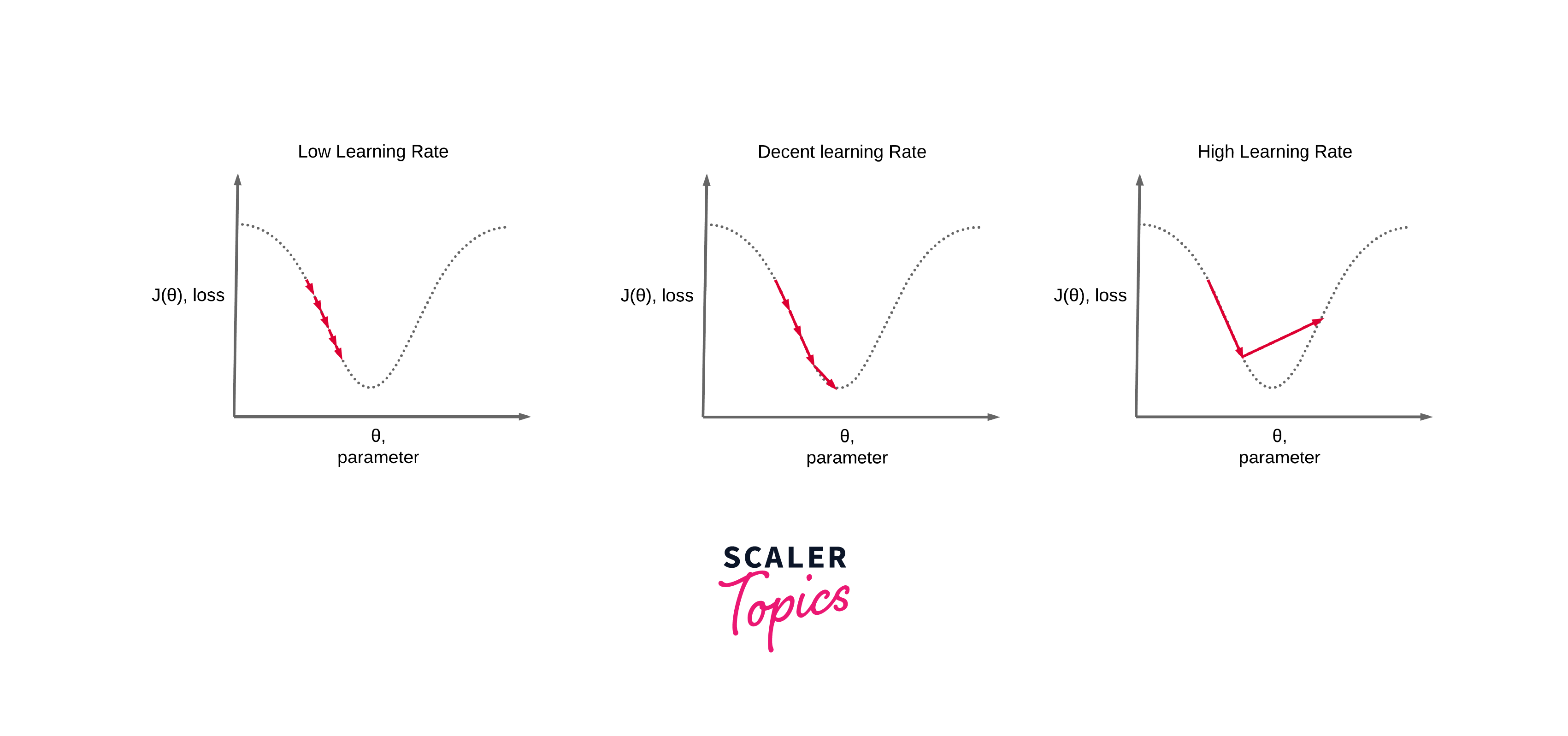
Learning Rate Schedule:
Learning rate schedules dynamically adjust the learning rate during training to fine-tune the model. One common approach is to reduce the learning rate gradually over epochs.
- In the context of TensorFlow, "callbacks" are specialized functions that can be integrated into the training process to perform specific actions at various stages. These actions can include tasks such as logging training metrics, saving model checkpoints, altering learning rates dynamically, and more. Callbacks offer a way to customize and enhance the training loop without modifying the core model architecture or training logic.
Early Stopping:
Early stopping is a technique to prevent overfitting by stopping the TensorFlow training when the model's performance on a validation set starts to degrade.
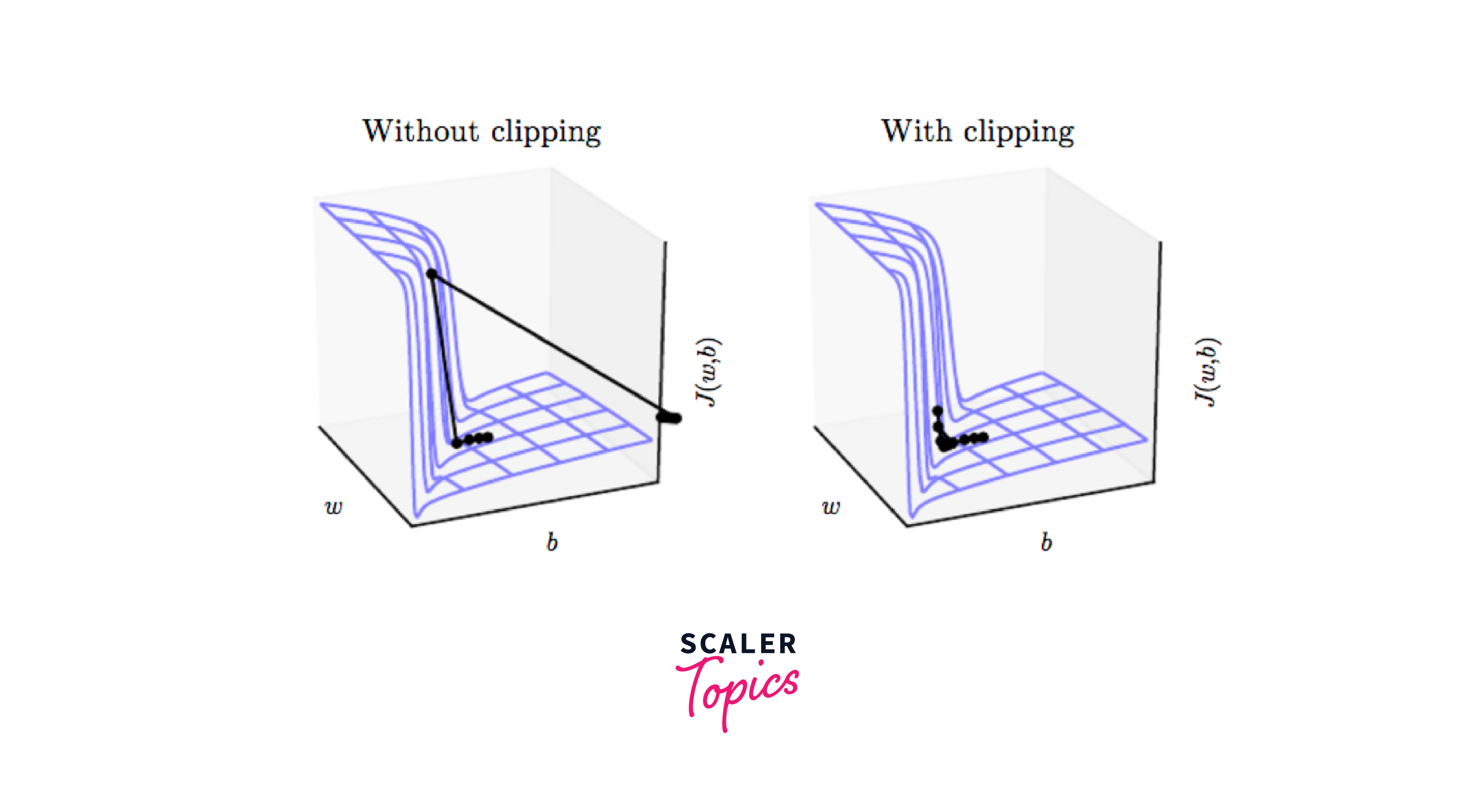
Gradient Clipping:
Gradient clipping limits the magnitude of gradients during training, which can prevent exploding gradients in deep neural networks.
By adding custom logic to the TensorFlow training loop and implementing advanced training techniques, you can enhance the performance and stability of your machine learning models in TensorFlow. These techniques empower you to experiment with various strategies and tailor your models to specific tasks or datasets.
Control Flow and Conditionals in Custom Training
In a custom training loop, you have the freedom to introduce control flow and conditionals to tailor the training process based on specific conditions. This flexibility allows you to implement strategies like warm-up periods for learning rates, different optimization algorithms for specific layers, or even adjusting batch sizes during training.
For instance, you can introduce a learning rate warm-up, where you gradually increase the learning rate during the initial epochs to help the model explore the parameter space more effectively before settling into a stable learning rate.
Here's how you can achieve that in the custom training loop:
- During the warm-up phase, the learning rate is calculated using the formula current_lr = initial_lr * (epoch + 1) / warmup_epochs.
- This formula increases the learning rate linearly from a small value to the desired initial_lr over the warm-up period.
- By incorporating this warm-up learning rate schedule, the model starts with a conservative learning rate and gradually ramps it up, helping to avoid large weight updates and potential instability early in training.
- This approach can contribute to a smoother optimization process and, in some cases, improved convergence behavior.
Fine-tuning and Transfer Learning with Custom TensorFlow Training
Fine-tuning and transfer learning are popular techniques used to leverage pre-trained models and adapt them to new tasks or datasets. With custom training, you can easily incorporate these techniques into your workflow.
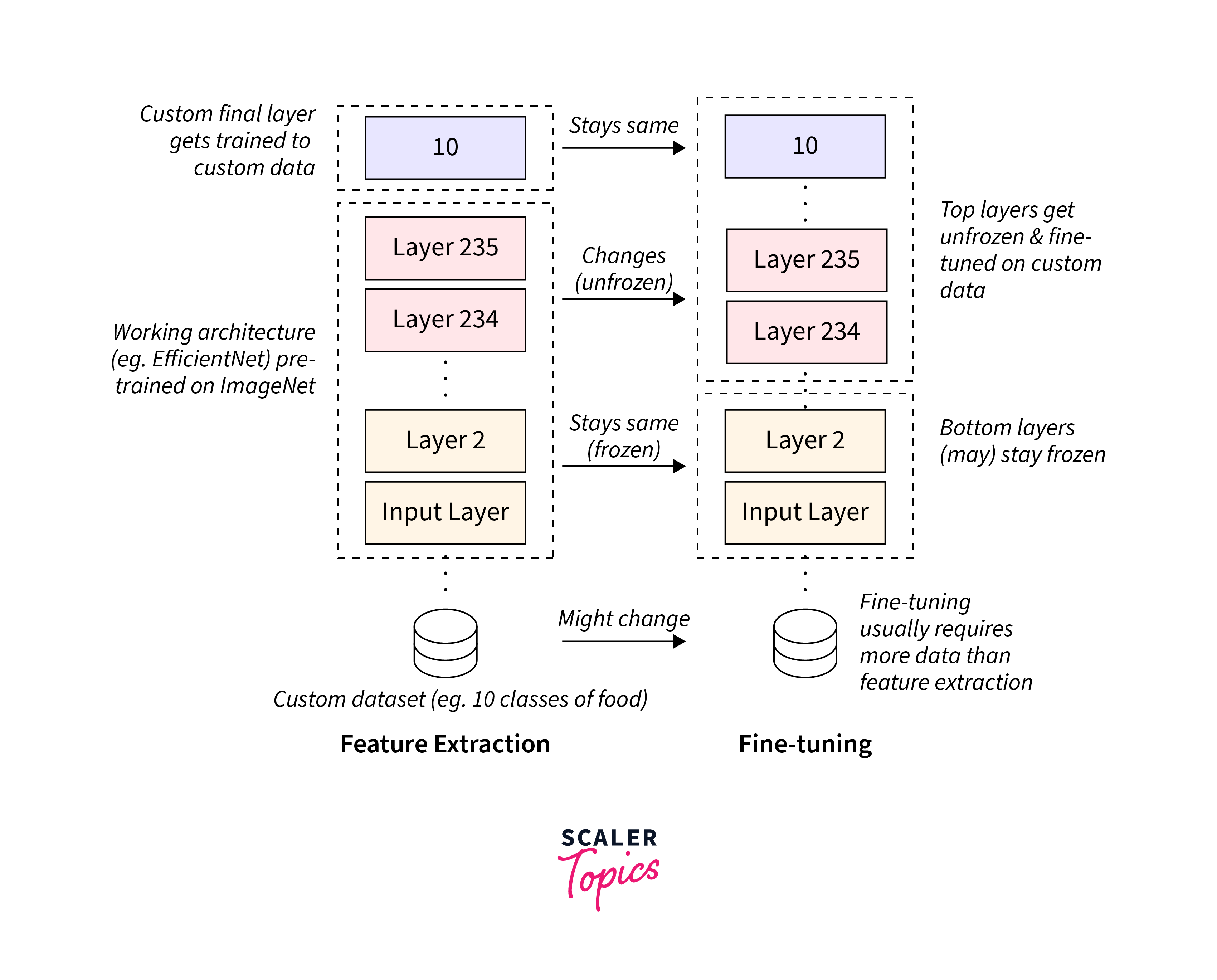
Let's say you have a pre-trained model and you want to fine-tune it on a new task with a different set of labels. You can achieve this by freezing some layers to retain the pre-trained knowledge while only training the last few layers for the new task.
Here's how you can do it using a custom training loop:
- The provided code defines a custom fine-tuning training loop for a neural network model.
- This loop is designed to fine-tune a pre-trained model for a new task or dataset by freezing a specific number of initial layers and allowing the subsequent layers to be trainable.
- During each epoch of training, the loop iterates through the model's layers, setting the first few layers as non-trainable (frozen) and the remaining layers as trainable.
- This controlled freezing and unfreezing process aims to preserve the pre-trained knowledge in the initial layers while enabling adaptation to new data in the later layers.
- The loop then proceeds with the standard training process, updating the model's weights based on computed gradients.
Conclusion
- Custom TensorFlow training provides an unparalleled level of control and flexibility in training machine learning models.
- By introducing custom logic, conditionals, and advanced techniques, you can tailor the training process to your specific needs and optimize model performance.
- Moreover, custom training allows you to seamlessly integrate fine-tuning and transfer learning, enabling you to leverage pre-trained models and adapt them to new domains or tasks efficiently.