Data Pipelines with TensorFlow Data Services
Overview
Data processing is a fundamental step in machine learning and data analysis workflows. Data pipelines with TensorFlow Data Services (TFDS) is a component of TensorFlow that provides tools and utilities for efficiently building scalable and high-performance systems. Data pipelines with TensorFlow Data Services enable seamless loading, preprocessing, and augmentation of data, ensuring that data is properly prepared for training machine learning models.
What are TensorFlow Data Services?
TensorFlow Data Services (TFDS) is a collection of libraries and components within the TensorFlow ecosystem designed to assist in building data pipelines for machine learning tasks. TFDS provides features to handle various data formats, perform transformations, apply data augmentation techniques, and efficiently load data into memory. Data pipelines with TensorFlow Data Services offer streamlined data management. It's particularly useful when dealing with large datasets that cannot fit entirely in memory.
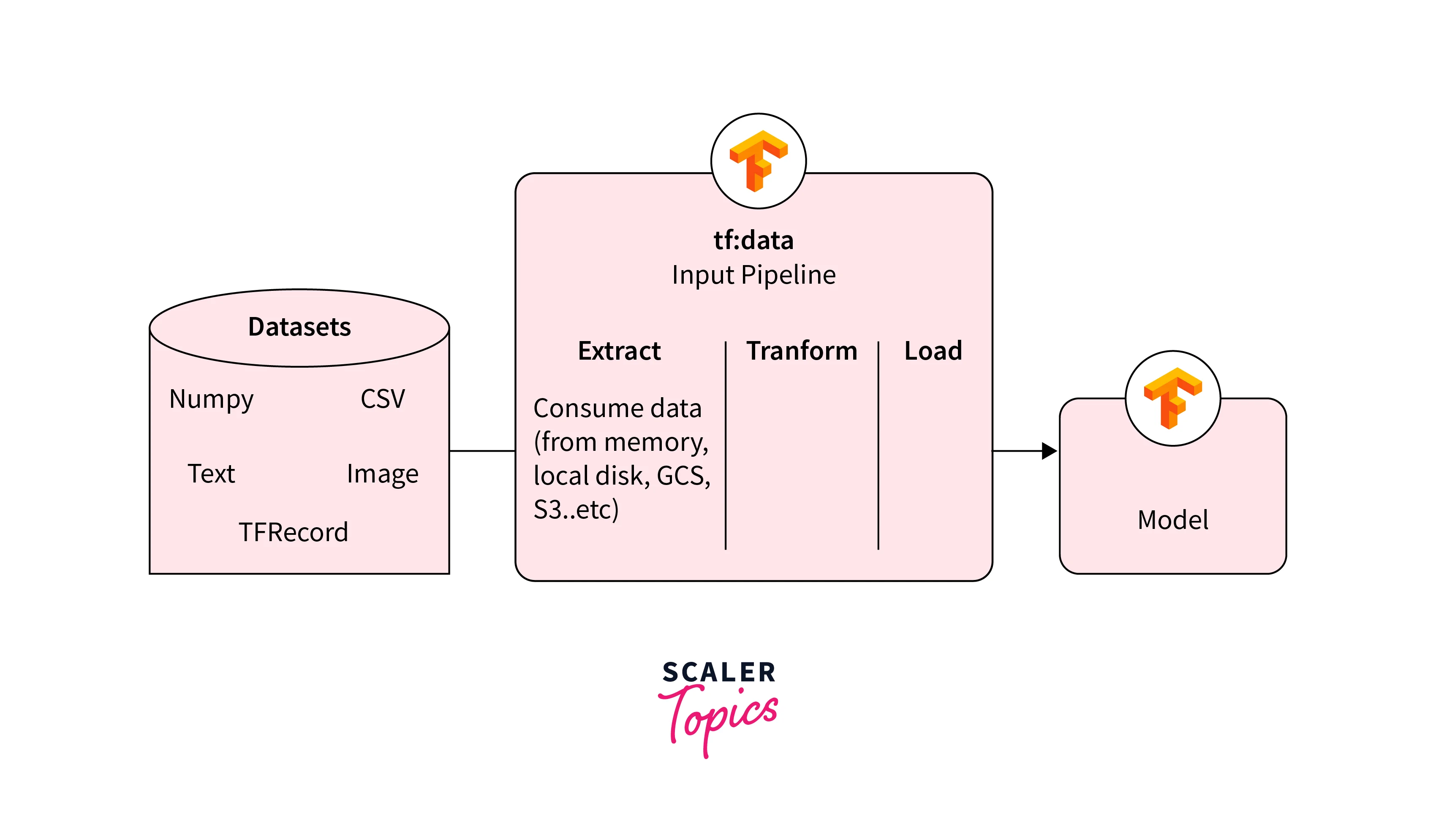
Key features of TensorFlow Data Services include:
Data Loading:
TFDS provides functions and classes for reading data from various sources such as files, databases, and network connections. It supports popular data formats like CSV, TFRecord, and more.
Data Transformation:
TFDS enables users to perform various data transformations like reshaping, normalization, and feature engineering. These transformations are crucial for preparing data before feeding it to machine learning models.
Data Augmentation:
For image data, TFDS offers tools for applying data augmentation techniques, which enhance model generalization by generating variations of training examples.
Parallelism and Performance:
TFDS optimizes data loading and preprocessing pipelines by using parallel processing and asynchronous operations, ensuring that the data pipeline doesn't become a bottleneck during training.
Integration with TensorFlow:
Data pipelines with TensorFlow Data Services seamlessly integrates with TensorFlow workflows, allowing users to directly plug data pipelines into their model training loops.
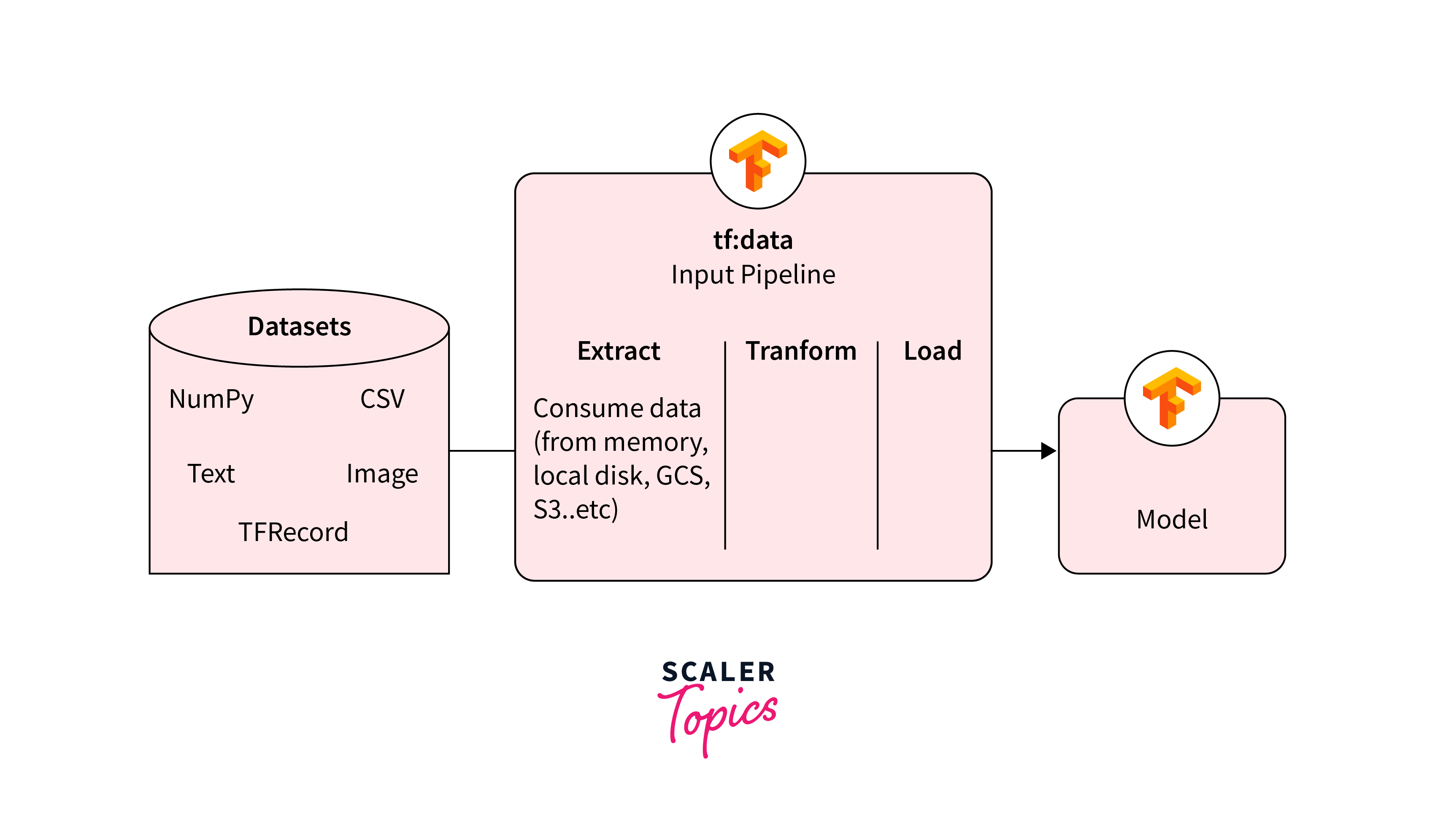
Set Up Data Pipelines with TensorFlow Data Services
To work with TensorFlow Datasets (TFDS), you can install it using one of two packages:
-
Stable Version (Released Every Few Months):
To install the stable version of TensorFlow Datasets, you can use the following command:
-
Nightly Version (Released Every Day):
To access the nightly version of TensorFlow Datasets, which contains the latest dataset versions and updates, you can use the following command:
Data Loading and Exploration using Data Pipelines with TensorFlow Data Services
Here's a step-by-step guide with detailed explanations for loading and exploring data using TensorFlow Data services (TFDS):
Step 1: Import Required Libraries
Start by importing the necessary libraries: TensorFlow, TensorFlow Datasets, Matplotlib, and NumPy.
Step 2: Load a Dataset from TFDS
Choose a dataset you want to work with. In this example, we'll use the MNIST dataset.
For the MNIST dataset, the default split ratio is as follows:
-
Training split:
Approximately 60,000 examples (commonly referred to as the "train" split).
-
Testing split:
Approximately 10,000 examples (commonly referred to as the "test" split).
These splits are standard for the MNIST dataset and are widely used for training and evaluating machine learning models. If you need a different split ratio, you can specify it explicitly using the split parameter by providing a dictionary of split names and their corresponding ratios.
Step 3: Get Dataset Information
Retrieve essential information about the loaded dataset, such as the number of classes and class names. Data pipelines with TensorFlow Data Services optimize information flow.
Output
Step 4: Explore Data Examples
Visualize a few data examples to get a better understanding of the dataset.
Sample Output:
Step 5: Interpretation and Analysis
- The ds_train and ds_test datasets are loaded using tfds.load() with the split specified as 'train' and 'test'. The shuffle_files parameter ensures that the data is shuffled.
- The ds_info object provides information about the dataset, including the number of classes and class names.
- The loaded images are displayed using Matplotlib, along with their corresponding labels. This step helps in understanding the data distribution and characteristics.
Preprocess Data Using Data Pipelines with TFDS
Preprocessing data is a crucial step before training machine learning models. Data pipelines with TensorFlow Data Services offer efficiency.

Here's a step-by-step guide on how to preprocess data using TensorFlow Data services:
Step 1: Import Required Libraries
Start by importing the necessary libraries: TensorFlow, TensorFlow Datasets, and NumPy.
Step 2: Load and Preprocess a Dataset
Choose a dataset you want to work with and load it using TFDS. In this example, we'll use the MNIST dataset.
Step 3: Batch and Shuffle
Batching and shuffling the data are common preprocessing steps. You can use the batch() and shuffle() methods on the datasets.
-
Batching:
Batching is a data preprocessing step that groups multiple data samples together into smaller batches. It is commonly used to improve training efficiency by processing multiple samples simultaneously during each training iteration.
-
Shuffling:
Shuffling is a data preprocessing step that randomizes the order of data samples within a dataset. It helps reduce bias and ensures that the model sees a variety of examples during training, preventing it from learning patterns based on the order of data.
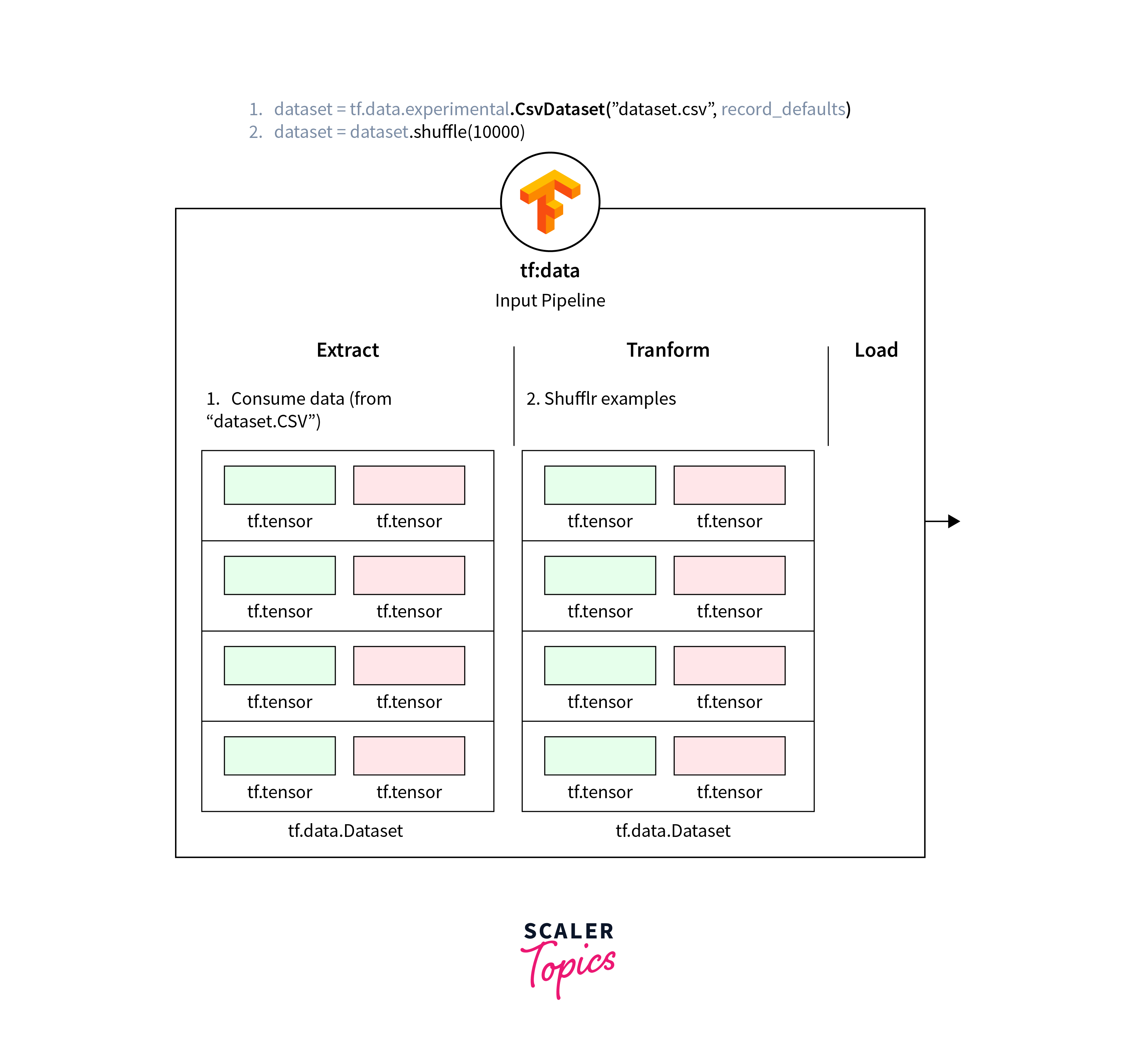
Step 4: Interpretation and Analysis
- The preprocess_image() function is defined to normalize the pixel values of the images in the range [0, 1].
- The map() function is used to apply the preprocessing function to each element in the datasets.
- Batching and shuffling improve the efficiency of model training and enhance generalization.
Build Data Pipelines with TensorFlow Data Services
Building data pipelines with TensorFlow Data pipelines is a crucial aspect of preparing data for machine learning models. TensorFlow Datasets (TFDS) offers tools to create efficient and scalable data pipelines. Here's a step-by-step guide on how to build data pipelines using TFDS:
Build your model using TensorFlow's Keras API
Building data pipelines with TensorFlow Data Services streamlines the data preprocessing phase of machine learning workflows. It ensures that data is loaded efficiently, preprocessed consistently, and made ready for model training. This efficiency not only saves time but also contributes to the reproducibility and scalability of machine learning experiments.
This code defines a simple feedforward neural network for a classification task. It takes 2D input data (28x28 images), flattens it into a 1D vector, passes it through two fully connected layers with ReLU activation, and produces 10-class probabilities as the final output using the softmax activation function.
This type of architecture is commonly used for tasks like image classification, where the goal is to classify input images into one of several predefined categories.
Once the model.compile function is executed with these settings, the model is configured for training with the specified optimizer, loss function, and metrics. After compilation, you can use the model.fit method to train the model on your training data, and it will use the specified configuration for optimization and evaluation.
In this example, we first load the MNIST dataset, apply any necessary preprocessing (in this case, normalizing pixel values), configure batch size and shuffling for the training dataset, build a simple neural network model using TensorFlow's Keras API, compile the model, and finally, train the model using the training dataset defined in the data pipeline. Efficient data handling through data pipelines is a key feature that helps ensure smooth and optimized model training.
Sample Output:
Step 5: Interpretation and Analysis
- You've built a complete data pipeline with TensorFlow Data Services that loads, preprocesses, batches, and shuffles data.
- The model training process uses the data pipeline to feed data to the model during training.
- The pipeline ensures efficient loading and preprocessing, helping in model convergence and generalization.
Applications of Using Data Pipelines with TensorFlow Data Services
Using data pipelines with TensorFlow Data Services offers several applications that streamline the process of loading, preprocessing, and utilizing data for various machine learning tasks. Here are some key applications of TFDS in data pipelines:
-
Standardized Data Loading:
TFDS provides a collection of curated datasets, each with predefined splits (train, validation, test) and data format conversions. By using these datasets in your data pipeline, you ensure standardized and consistent data loading, saving you time on data collection and formatting.
-
Efficient Preprocessing:
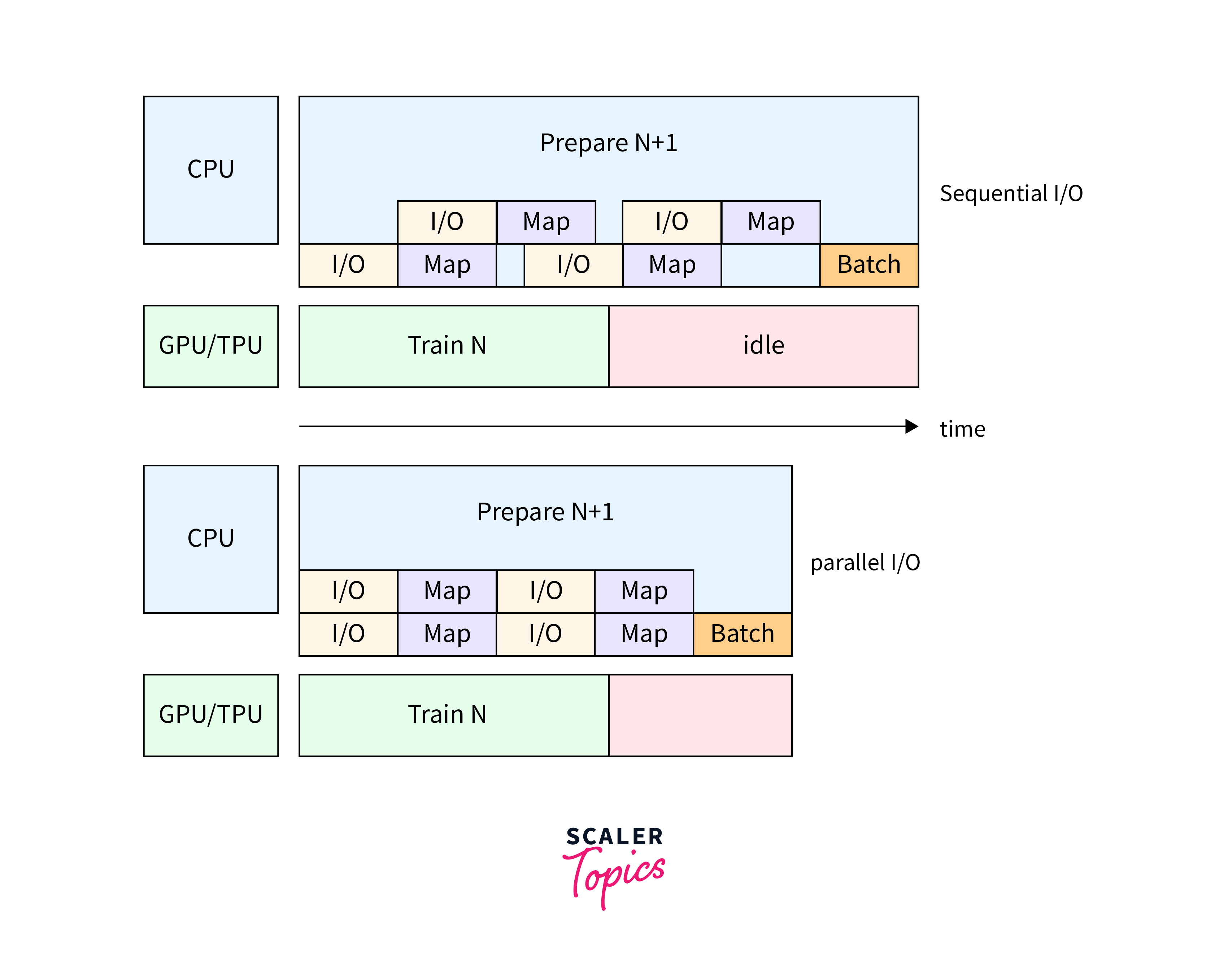
Data pipelines with Tensorflow Data Services allows you to apply data preprocessing functions directly within the data pipeline. This ensures that data preprocessing steps, such as normalization, resizing, and augmentation, are seamlessly integrated into the pipeline, improving the efficiency of model training.
-
Data Augmentation:
Data augmentation is crucial for improving model generalization. Data pipelines with TensorFlow Data Services enables you to apply data augmentation techniques directly within the pipeline, generating augmented examples on-the-fly during training.
-
Custom Data Loading:
While TFDS provides curated datasets, you can also use TFDS to build custom data loading pipelines. This is particularly useful when working with your own datasets or when adapting existing datasets to your needs.
-
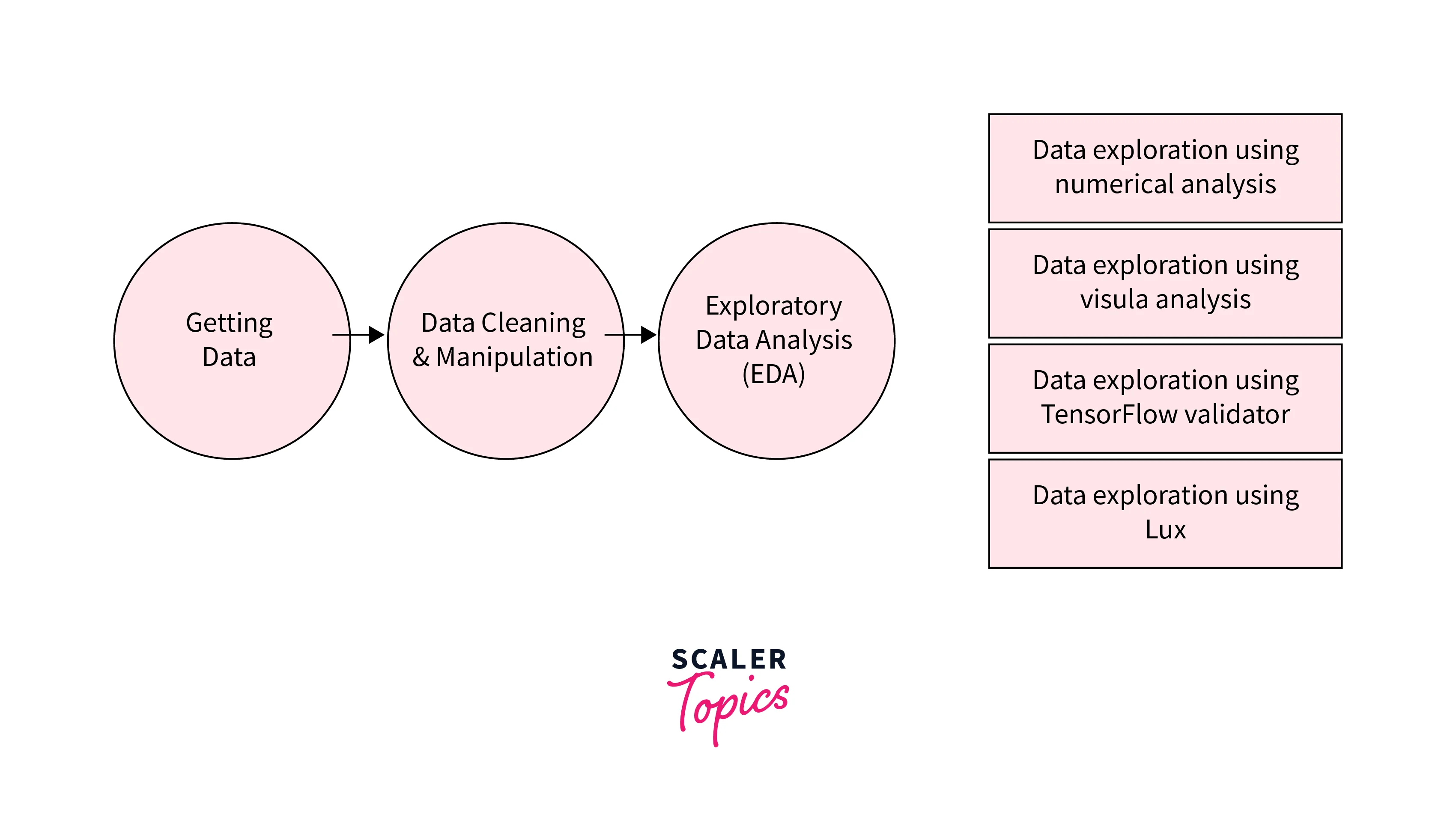
Data Exploration and Analysis:
TFDS facilitates data exploration by providing metadata and information about the loaded datasets. This helps you better understand the data you're working with and make informed decisions about preprocessing and model design.
-
Optimized Batching and Shuffling:
TFDS allows you to configure batch sizes and shuffling directly in the data pipeline. This optimization ensures efficient data loading during training, leading to faster convergence and better utilization of system resources.
-
Integration with TensorFlow Models:
TFDS seamlessly integrates with TensorFlow models and model training loops. You can directly use the TFDS datasets as input to your models, simplifying the integration process.
-
Easy Dataset Switching:
Switching between different datasets for experimentation becomes easier with TFDS. You can quickly change the dataset used in your pipeline, facilitating comparative studies and benchmarking.

-
Reproducibility:
By using TFDS datasets, you ensure that others can reproduce your results using the same data. This is valuable for sharing research and promoting transparency.
-
Research and Development:
TFDS can significantly accelerate the research and development process by providing access to a wide range of datasets. You can quickly prototype and experiment with different datasets and models.
In essence, using TFDS in data pipelines streamlines and enhances the data preparation process, making it more efficient, standardized, and versatile for various machine-learning applications.
Conclusion
- Data pipelines with TensorFlow Data Services provide curated datasets with predefined splits and formats, ensuring standardized data loading and saving time on preprocessing.
- TFDS integrates data preprocessing and augmentation directly into the pipeline, enhancing data quality and model generalization.
- The integration of batch sizing and shuffling optimizes data loading, leading to faster model convergence and efficient resource utilization.
- Data pipelines with TensorFlow Data Services support custom data loading and integrate with TensorFlow models, making it versatile for diverse tasks and expediting research and development.