Distributed Data Parallelism in TensorFlow
Overview
In the field of machine learning and deep neural networks, training models on large datasets has become a common practice. As models grow in complexity and datasets become larger, the need for efficient training strategies becomes paramount. Distributed data parallelism is a technique that allows us to train these complex models on massive datasets efficiently. In this technical blog, we'll dive into the world of distributed data parallelism using TensorFlow, exploring its concepts, implementation, performance optimization, and more.
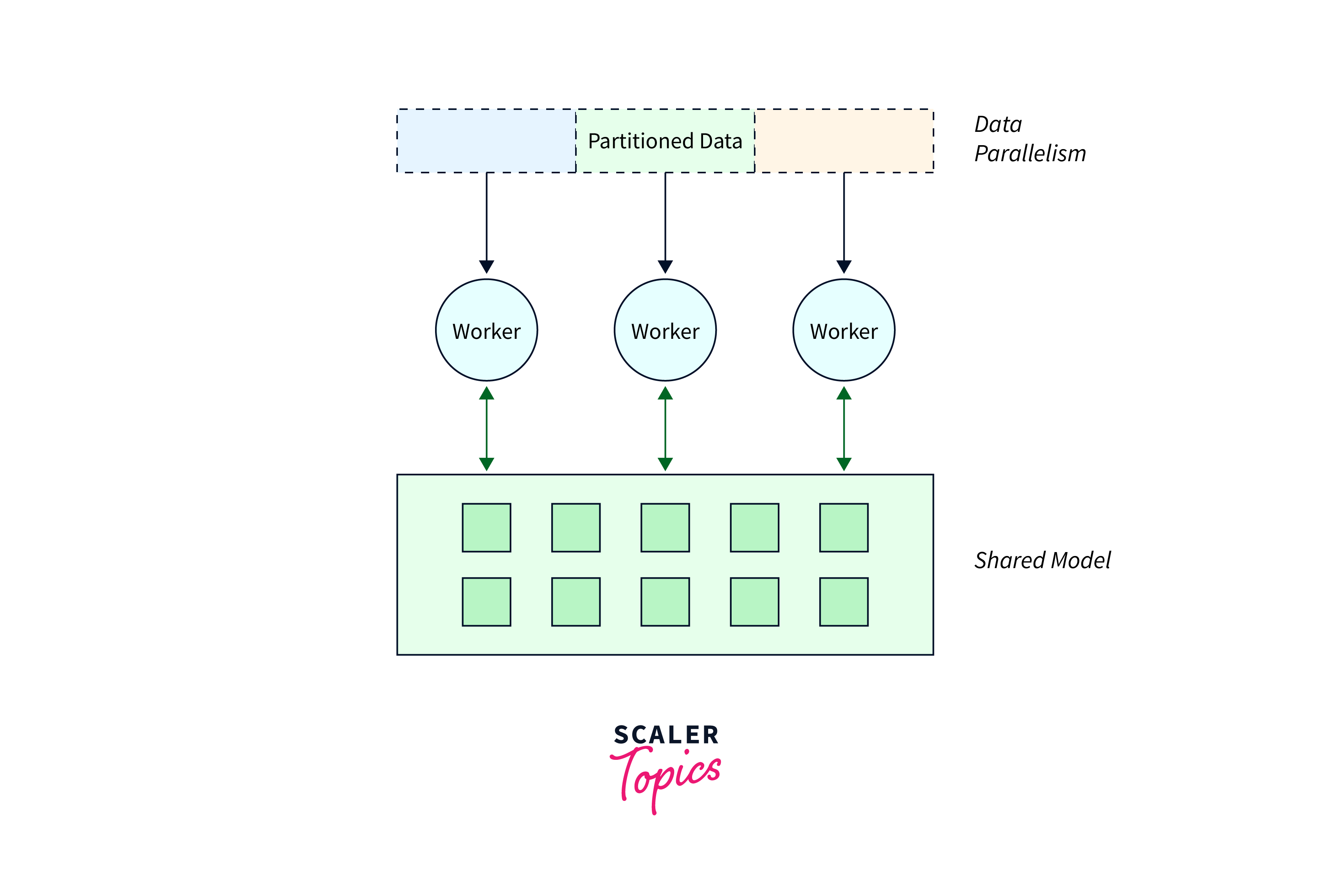
What is Distributed Data Parallelism?
Distributed data parallelism is a technique used in TensorFlow to train deep learning models across multiple devices or machines. This approach divides the model and data among these resources, allowing developers to efficiently utilize the computational power of multiple GPUs or machines.The main purpose of distributed data parallelism is to accelerate the training process for complex neural networks. By distributing the workload, developers can significantly reduce the training time for large datasets. This is particularly important as training on a single device may take days or even weeks.
In addition to speeding up the training process, distributed data parallelism offers fault tolerance and robustness. If one device or machine fails during the training, the remaining devices can continue the process without losing progress. This is especially beneficial for long-running training tasks where interruptions can have a significant impact on productivity. To implement distributed data parallelism in TensorFlow, developers need to divide the model and data, and assign them to different devices or machines. This can be done using TensorFlow's built-in distribution strategies, such as tf.distribute.MirroredStrategy or tf.distribute.experimental.MultiWorkerMirroredStrategy. These strategies handle the distribution of variables and gradients across devices or machines, enabling parallel training.
By implementing distributed data parallelism, developers can achieve higher model accuracy and faster convergence. This ultimately leads to improved performance of deep learning applications, as larger and more complex models can be trained efficiently. In the next section, we will explore the fundamental concepts and step-by-step implementation of distributed data parallelism in TensorFlow.
Different Distributed Training Strategies
When implementing distributed data parallelism in TensorFlow, developers have several strategies to choose from. These strategies determine how the model and data are distributed across devices or machines, and how the training process is coordinated.
- Mirrored Strategy: This strategy is suitable for single-device or multi-GPU training. It creates a copy of the model on each device and divides the input data among them. Each device computes the forward and backward passes independently, and the gradients are then averaged across devices to update the model. This strategy is efficient for models with small to medium-sized parameters.
- Multi-Worker Mirrored Strategy: This strategy extends the mirrored strategy to multiple machines or nodes. It uses TensorFlow's distributed communication library, called TensorFlow Collective Communications (tf.distribute.experimental.CollectiveCommunication), to synchronize gradients and update the model. It can handle both homogeneous and heterogeneous clusters, where devices may have different capabilities or configurations.
- Parameter Server Strategy: This strategy is suitable for large-scale distributed training. It separates the model parameters from the replica models, and assigns them to parameter servers. The input data is divided among the worker replicas, which compute the forward and backward passes independently. The gradients are then sent to the parameter servers, which apply the updates to the model parameters. This strategy allows for higher scalability, as the parameter servers can be distributed data parallelism across multiple machines.
- Central Storage Strategy: In this strategy, the model and data are stored in a central location, such as a shared file system or a distributed storage system. Each device or machine retrieves the necessary model parameters and input data for training. The gradients are computed locally and sent back to the central storage for aggregation and model updates. This strategy is suitable for scenarios where the devices or machines have limited storage capacity or when the model and data need to be shared across multiple training jobs.
- TPU Strategy: The TPUStrategy is used for distributed training on TPUs. It is similar in concept to the Mirrored Strategy but is optimized to work seamlessly with TPUs. TPUs are specialized hardware accelerators designed for machine learning workloads, and they can significantly speed up training and improve scalability.

Choosing the right distributed training strategy depends on factors such as the size of the model, the amount of data, the available computational resources, and the desired scalability. Developers should experiment with different strategies to find the one that best suits their specific requirements.
Implement Distributed Data Parallelism
Implementing distributed data parallelism in TensorFlow requires careful consideration of the model architecture and the distribution of data across devices or machines. In this section, we will explore the steps involved in implementing distributed data parallelism in TensorFlow.
-
Model Replication: The first step is to replicate the model across multiple devices or machines. This can be achieved using TensorFlow's MirroredStrategy, which creates a copy of the model on each device. Alternatively, the Parameter Server Strategy can be used for large-scale distributed training, where the model parameters are separated from the replica models and assigned to parameter servers.
-
Data Partitioning: Next, the input data needs to be partitioned and distributed across devices or machines. This can be done using TensorFlow's Dataset API, which provides functions for splitting and preprocessing the data. The Multi-Worker Mirrored Strategy and Central Storage Strategy also involve distributing the input data among the worker replicas or retrieving it from a central storage location.
-
Forward and Backward Pass: Each device or machine independently computes the forward and backward passes using the replicated model and the local batch of data. This step is parallelized across devices using TensorFlow's tf.distribute.Strategy API, which handles the synchronization and aggregation of gradients in the case of mirrored strategies or parameter servers.
-
Gradient Aggregation and Model Updates: After computing the gradients on each device, they need to be aggregated and used to update the model parameters. This can be done using TensorFlow's tf.distribute.Strategy API, which provides functions for gradient aggregation and model updates. The Parameter Server Strategy involves sending the gradients to parameter servers for aggregation and updating the model parameters, while the Mirrored Strategy averages the gradients across devices to update the model.
-
Synchronization and Communication: In the case of multi-worker distributed training, synchronization and communication are necessary to coordinate the training process across machines. TensorFlow's tf.distribute.experimental.CollectiveCommunication library provides functions for collective operations, such as all-reduce and all-gather, which can be used to synchronize gradients and update the model in a distributed manner.
Implementing distributed data parallelism in TensorFlow requires a thorough understanding of the model architecture, data distribution, and synchronization mechanisms. Developers should experiment with different strategies and configurations to find the optimal setup for their specific requirements.
In below,It has the code examples and best practices for implementing distributed data parallelism in TensorFlow with mirrorstrategy.
Step 1: Importing Dependencies and Preparing the Data
We start by importing the required libraries and loading the data. In this example, we'll use the MNIST dataset, a collection of hand-written digits.
Output:

Step 2: Defining the Model Next, we define the architecture of our neural network using the Sequential API.
Step 3: Creating the Mirrored Strategy We create a tf.distribute.MirroredStrategy instance to enable distributed training across multiple GPUs. This strategy automatically handles data and model replication.
Step 4: Model Compilation in the Strategy Scope The model is created and compiled within the strategy's scope, ensuring that the model and training operations are distributed.
Step 5: Creating and Preparing the Dataset We use TensorFlow's tf.data.Dataset API to create a dataset from our preprocessed data.
Step 6: Training the Model Finally, we train the model using the fit() method within the strategy's scope.

Performance Optimization and Scalability
Once distributed data parallelism is implemented in TensorFlow, developers can focus on performance optimization and scalability. This section will explore various techniques and strategies to improve the performance and scalability of distributed training.
-
Batch Size and Learning Rate: Adjusting the batch size and learning rate can have a significant impact on training performance. Batch size determines the number of examples processed in each iteration, while the learning rate controls the step size during gradient descent. A larger batch size can lead to faster convergence, but may require more memory. On the other hand, a smaller learning rate can help fine-tune the model, but may result in slower convergence. Developers should experiment with different batch sizes and learning rates to find the optimal balance.
-
Data Pipeline Optimization: Optimizing the data pipeline can also improve training performance. TensorFlow's Dataset API provides various functions for efficient data loading, preprocessing, and augmentation. Developers can use parallelism, prefetching, and caching techniques to minimize data loading and preprocessing time. Additionally, data shuffling and stratified sampling can help ensure a more representative distribution of examples across devices or machines.
-
Model Architecture Optimization: The complexity of the model architecture can impact training performance and scalability. Developers should carefully design their models, considering factors such as the number of layers, the size of hidden units, and the use of regularization techniques. Simplifying the model architecture and reducing the number of parameters can help improve training speed and reduce memory consumption. Regularization techniques, such as dropout and weight decay, can prevent overfitting and improve generalization.
-
Communication Optimization: Efficient communication between devices or machines is crucial for distributed training. TensorFlow provides various communication primitives, such as collective operations and parameter servers, to facilitate communication and synchronization. Developers should carefully consider the communication overhead and minimize unnecessary communication. Techniques like gradient compression and quantization can reduce communication bandwidth and latency, especially in bandwidth-constrained environments.
-
Hardware Acceleration: Taking advantage of hardware accelerators, such as GPUs or TPUs, can significantly speed up training and improve scalability. TensorFlow supports GPU acceleration out of the box, and TPUs can be used with the TensorFlow TPU runtime. Developers should ensure that their models and training pipeline are compatible with hardware accelerators and leverage distributed training frameworks optimized for specific hardware platforms.
-
Scalability Testing: Scalability testing is essential to ensure that the distributed training setup can handle increasing workload and data size. Developers should evaluate the scalability of their models and training pipeline by gradually increasing the number of devices or machines and measuring the training speed and memory usage. Techniques like model parallelism and data parallelism can be used to scale up training by distributing the model across multiple devices or machines.
By optimizing performance and ensuring scalability, developers can make the most of distributed data parallelism in TensorFlow. Experimenting with different techniques, configurations, and hardware platforms can help achieve faster and more efficient training, enabling the training of larger models on larger datasets. In the final section, we will summarize the key takeaways and provide additional resources for developers interested in distributed data parallelism.
Comparison with Other Distributed Training Approaches
When it comes to distributed training, TensorFlow's distributed data parallelism offers several advantages compared to other approaches. In this section, we will compare TensorFlow's approach with other popular distributed training methods.
-
Data Parallelism: Data parallelism is a common distributed training technique where each device or machine trains on a different subset of the data. The gradients computed on each device are then aggregated to update the model parameters. TensorFlow's distributed data parallelism follows a similar approach, allowing developers to train models on multiple devices or machines using synchronous training.
-
Model Parallelism: Model parallelism is another approach where the model is split across multiple devices or machines, with each device responsible for computing a portion of the model's computation graph. TensorFlow does not natively support model parallelism, but it can be combined with data parallelism using techniques like pipelining or parallel coordinates.
-
Parameter Servers: Parameter servers are a popular distributed training approach, especially in scenarios where the model is too large to fit on a single device or machine. Parameter servers distribute the model parameters across multiple devices or machines, and each device is responsible for computing a portion of the gradients. However, parameter servers introduce additional communication overhead and can be less efficient compared to TensorFlow's distributed data parallelism.
-
Horovod: Horovod is a popular distributed training framework that works with TensorFlow, PyTorch, and other deep learning frameworks. Horovod provides an easy-to-use interface for distributed training and supports techniques like data parallelism and model parallelism. However, deploying and managing a Horovod-based distributed training setup can be more complex compared to TensorFlow's native distributed data parallelism.
-
Dataflow Systems: Dataflow systems like Apache Beam and Apache Flink offer scalable and fault-tolerant execution of data processing pipelines, including deep learning training. These systems allow developers to define data processing pipelines that can be distributed across multiple devices or machines. While dataflow systems can provide scalability and fault tolerance, they require a different programming model compared to TensorFlow and may not offer the same level of flexibility and optimization for deep learning training.
Communication and synchronization in data parallelism
In distributed data parallelism, communication and synchronization are critical aspects that enable multiple devices or machines to work together efficiently during the training process. Let's dive deeper into how communication and synchronization are handled in data parallelism.
Communication
In data parallelism, each device or machine works on a portion of the dataset, computes gradients locally, and then shares these gradients with the other devices for aggregation. The aggregated gradients are then used to update the model's parameters. Efficient communication of gradients is essential to ensure that the training process remains synchronized and converges to an optimal solution.
TensorFlow provides various communication strategies and primitives to facilitate gradient communication:
-
All-Reduce: The most common communication operation in data parallelism is the "all-reduce" operation. In an all-reduce operation, each device shares its gradients with all other devices, and the gradients are summed across all devices. This results in each device obtaining the averaged gradients, which are then used for model parameter updates.
-
All-Gather: The "all-gather" operation collects data from all devices and distributes the collected data back to each device. This can be useful when information needs to be shared among all devices before performing certain operations.
-
Broadcast: The "broadcast" operation involves sending a single piece of data from one device to all other devices. It can be used, for example, to distribute the updated model parameters after they have been averaged.
-
Reduce: The "reduce" operation combines data from multiple devices using a specified reduction operation (e.g., summation, maximum, minimum). It can be used when aggregation involves operations beyond summation.
Synchronization
Synchronization ensures that all devices are working in tandem and that their computations remain consistent. In data parallelism, synchronization is primarily achieved through communication operations like all-reduce. Devices wait for each other to complete their computations and communicate gradients before moving on to the next iteration. This synchronization ensures that the model parameters are updated consistently across all devices.
Challenges
Efficient communication and synchronization can be challenging, especially as the number of devices or machines increases. Communication overhead can become a bottleneck, leading to slower training speeds. To mitigate this, techniques such as gradient compression and quantization can be employed to reduce the amount of data transferred during communication. It's important to strike a balance between communication overhead and the benefits of distributed training.
Handling large-scale datasets in distributed training
Handling large-scale datasets is a common challenge in distributed training scenarios. As models become more complex and datasets grow in size, it becomes crucial to efficiently manage and process the data across multiple devices or machines. Here are some strategies for handling large-scale datasets in distributed training using TensorFlow:
-
Data Loading and Preprocessing:
- Use TensorFlow's tf.data.Dataset API: The tf.data.Dataset API provides efficient tools for loading and preprocessing large datasets. It allows you to apply transformations, shuffling, batching, and prefetching to the data. This is essential for optimizing data loading and preprocessing, which can have a significant impact on training speed.
- Parallel Data Loading: Distribute the data loading process across devices or machines to reduce loading time. The interleave transformation in tf.data.Dataset can be used to parallelize the loading of multiple files.
- Data Shuffling: Shuffle the data before each epoch to prevent the model from seeing the same sequence of examples repeatedly. In distributed training, consider using a consistent random seed to ensure that all devices shuffle the data in the same way.
-
Distributed Data Parallelism:
- Divide Data Among Devices: Ensure that each device or machine receives a subset of the entire dataset. This can be done by creating data shards or by using techniques like tf.data.experimental.Distribute to partition the data.
- Data Parallelism Strategy: Choose an appropriate distribution strategy, such as tf.distribute.MirroredStrategy, that efficiently distributes data and model updates across devices.
-
Data Augmentation:
- Apply Data Augmentation: Data augmentation techniques can artificially increase the effective size of your dataset. Apply transformations like random cropping, flipping, and rotation to generate diverse training examples. Make sure that data augmentation is consistent across all devices to maintain synchronization.
-
Caching and Prefetching:
- Cache Data: Use the cache transformation in tf.data.Dataset to cache preprocessed data in memory. This can be particularly helpful when preprocessing is computationally expensive.
- refetching: Use the prefetch transformation to overlap data preprocessing and model execution. This reduces idle time and keeps the devices or machines better utilized.
-
Distributed File Systems:
- Use Distributed File Systems: When working with extremely large datasets that cannot fit into the memory of a single machine, consider using distributed file systems like HDFS or Google Cloud Storage. These systems allow efficient storage and retrieval of large datasets across multiple devices or machines.
-
Data Pipelines with In-Memory Data:
- Load Subset of Data: If your dataset is too large to fit into memory, you can load a subset of the data and distribute it across devices. This can be useful when the entire dataset is not needed for each training iteration.
-
Data Parallelism with Distributed Workers:
- Multi-Worker Strategies: If you're training on a cluster of machines, choose a multi-worker distribution strategy like tf.distribute.experimental.MultiWorkerMirroredStrategy. This strategy allows you to distribute the data across workers and perform synchronous training.
-
Dynamic Batching:
- Use Dynamic Batching: In cases where the dataset's size varies, consider using dynamic batching to adjust batch sizes dynamically. This can help ensure efficient memory usage and training speed.
Conclusion
- Distributed data parallelism in TensorFlow offers a groundbreaking solution for training complex neural network models on extensive datasets efficiently. As models grow in complexity and datasets become larger, the conventional training process faces limitations in terms of time and resources.
- TensorFlow provides a robust set of distribution strategies that cater to different training scenarios. The MirroredStrategy, designed for single-device or multi-GPU setups, replicates the model across devices and handles data distribution and gradient aggregation seamlessly.
- Implementing distributed data parallelism requires careful orchestration of various components. Developers need to partition the data, distribute the model, manage gradient updates, and ensure synchronization across devices or machines.
- The handling of large datasets is a critical aspect of distributed training. TensorFlow's tf.data. Dataset API is an invaluable tool for efficient data loading and preprocessing.