Distributed Evaluation and Inference
Overview
In the context of machine learning, distributed evaluation and inference in TensorFlow involve tasks like testing a model's performance on a dataset (evaluation) and making predictions or decisions based on input data (inference). By distributing these tasks across multiple nodes, organizations and researchers can harness the power of parallelism and scale up their machine-learning workloads.
In this guide, let us know about Distributed Evaluation and Inference in TensorFlow and learn how to implement it.
What is Distributed Evaluation and Inference in TensorFlow?
Distributed Evaluation and Inference in TensorFlow refer to the process of distributing the computational workload for performing evaluations and making inferences from a machine learning model across multiple machines or nodes in a distributed computing environment. This approach is particularly useful when dealing with large-scale models or datasets that cannot be efficiently processed on a single machine.
Distributed Evaluation and Inference in TensorFlow typically involve the following key components:
-
Model Distribution:
The machine learning model is distributed across multiple machines or nodes. Each node holds a part of the model, which collectively forms the complete model. -
Data Distribution:
The input data, which could be a testing dataset for evaluation or real-world data for inference, is also distributed across the nodes. Each node processes a subset of the data.
-
Parallel Processing:
The distributed nodes work in parallel to perform the evaluation or inference tasks. This parallelism significantly reduces the time required to complete these tasks compared to a single-node approach. -
Communication:
Communication between nodes is necessary for aggregating results and synchronizing the distributed components of the model. This is often managed using communication frameworks like TensorFlow, PyTorch, or distributed computing libraries.
Implementing Distributed Evaluation and Inference in TensorFlow
Implementing distributed evaluation in TensorFlow can be achieved by using TensorFlow's built-in distributed computing capabilities. Below, is a step-by-step process for implementing distributed evaluation using TensorFlow:
Step - 1: Import TensorFlow and Necessary Libraries
Step - 2: Define Your Evaluation Dataset
Prepare the dataset you want to use for evaluation. You can load data using TensorFlow's data loading APIs, such as tf.data.
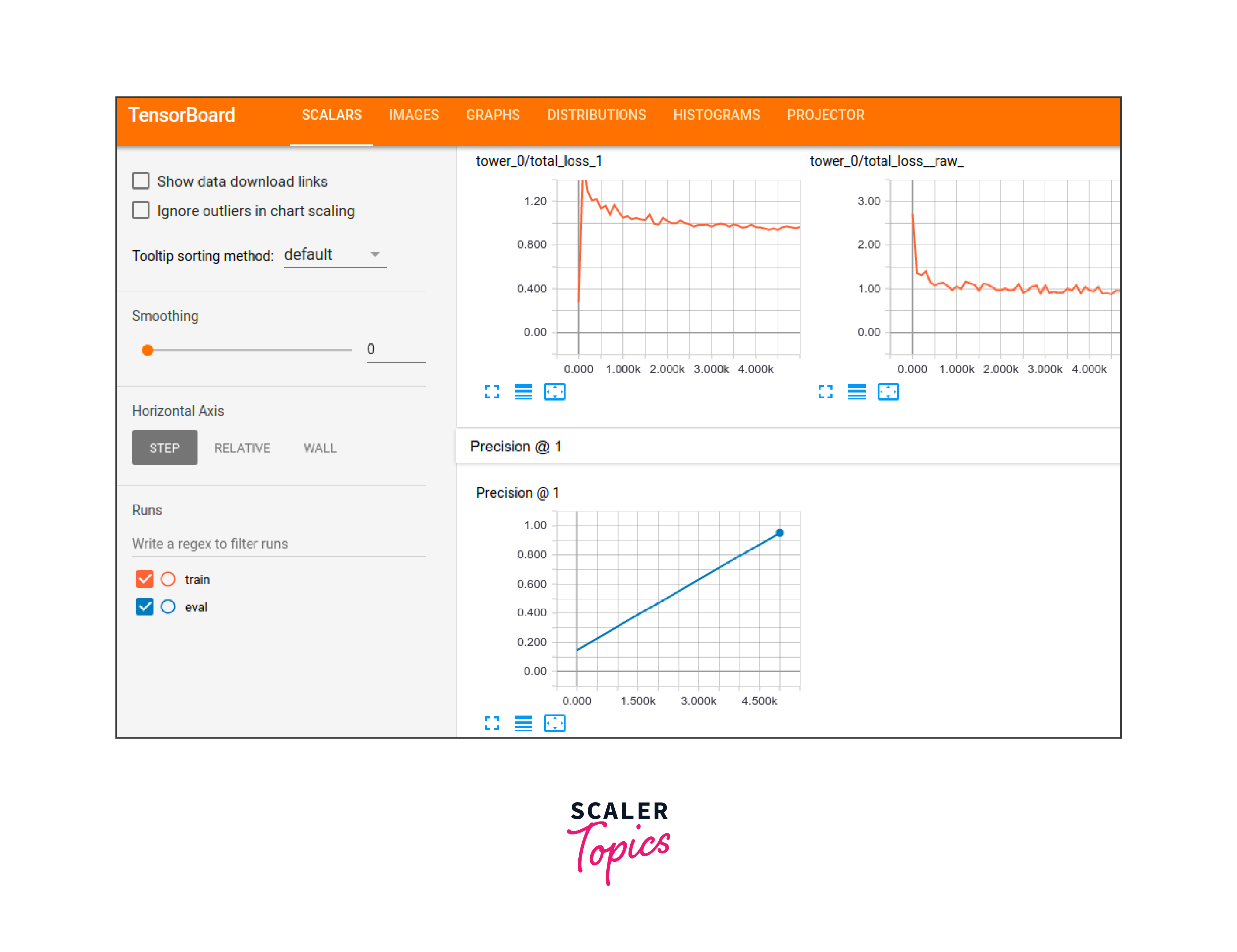
Step - 3: Create a Distributed Strategy
Choose a distributed strategy that fits your hardware configuration. Two common options are tf.distribute.MirroredStrategy for multi-GPU setups and tf.distribute.OneDeviceStrategy for single-GPU or CPU setups.
Step - 4: Define Your Evaluation Function
Define a function that encapsulates your evaluation logic. This function will be executed within the distributed strategy context.
Step - 5: Create a Distributed Dataset
Distribute your evaluation dataset across multiple devices using the strategy.experimental_distribute_dataset method.
Step - 6: Initialize and Compile Your Model
Create and compile your model within the distributed strategy scope.
Step - 7: Define a Distributed Training Loop
Define a function for the distributed evaluation loop. This function will iterate through the distributed dataset, compute losses, and aggregate results across replicas.
Step - 8: Perform Evaluation
Call the distributed_evaluation function to perform the evaluation.
Add any necessary post-evaluation steps, such as saving evaluation results, visualizing metrics, or deploying the model for inference.
This step-by-step guide demonstrates how to implement distributed evaluation and inference in TensorFlow using the tf.distribute.MirroredStrategy. Adapt it to your specific use case, dataset, and model architecture.
Advantages of Distributed Evaluation and Inference in TensorFlow
There are several advantages to using distributed evaluation and inference in TensorFlow:
-
Scalability:
Distributed computing allows for the efficient scaling of machine learning workloads. As data and model sizes increase, additional resources can be added to the cluster to maintain performance.Example: Netflix's Recommendation System
Netflix employs a distributed machine learning infrastructure to handle its vast user base and extensive content library. As the number of subscribers and available content continues to grow, distributed computing resources are crucial for scaling their recommendation system. Netflix uses clusters of servers to process user data, extract features, and train recommendation models efficiently. This scalability ensures that millions of users receive personalized recommendations in real time, contributing to user satisfaction and increased content consumption. -
Speed:
Parallel processing across multiple nodes can significantly reduce the time required for evaluation and inference tasks, making it feasible to handle large-scale applications in real-time or near real-time.Example: Google Search Ranking Algorithm:
Google's search engine relies on a distributed machine learning approach to continuously update its search ranking algorithm. Processing the enormous volume of web pages and user queries at high speeds is essential to provide relevant search results quickly. Google's distributed infrastructure allows them to parallelize tasks like web crawling, data indexing, and ranking, enabling near-instantaneous search results for users worldwide. -
Resource Utilization:
Distributing the workload ensures efficient utilization of hardware resources, as each node can make the most of available CPUs, GPUs, and memory.Example: Facebook's Ad Ranking System:
Facebook's ad ranking system is designed to serve personalized ads to billions of users while optimizing ad campaign performance. Distributed machine learning enables Facebook to efficiently utilize the computational resources across its data centers. By distributing the training of ad ranking models and the real-time serving of ads, Facebook can balance workloads and make the most of its server infrastructure, ensuring smooth user experiences and effective advertising for businesses.
-
Fault Tolerance:
Distributed systems can be designed to be fault-tolerant, ensuring that if a node fails, the system can continue processing without significant disruption. -
Cost-Efficiency:
By utilizing commodity hardware and cloud resources, organizations can achieve cost savings compared to investing in high-end single machines. -
Support for Big Data:
Distributed evaluation and inference in TensorFlow are essential for processing big data, where the dataset is too large to fit into the memory of a single machine.
Distributed Evaluation Techniques
TensorFlow, being a popular deep learning framework, provides several tools and libraries for implementing distributed evaluation and inference.
Some key techniques and components for distributed evaluation and inference in TensorFlow include:
-
TensorFlow Serving:
A system designed for serving machine learning models in production, which can be distributed across multiple servers or containers. -
TF.Data and Data API:
These components in TensorFlow allow efficient data input pipelines that can work with distributed data sources.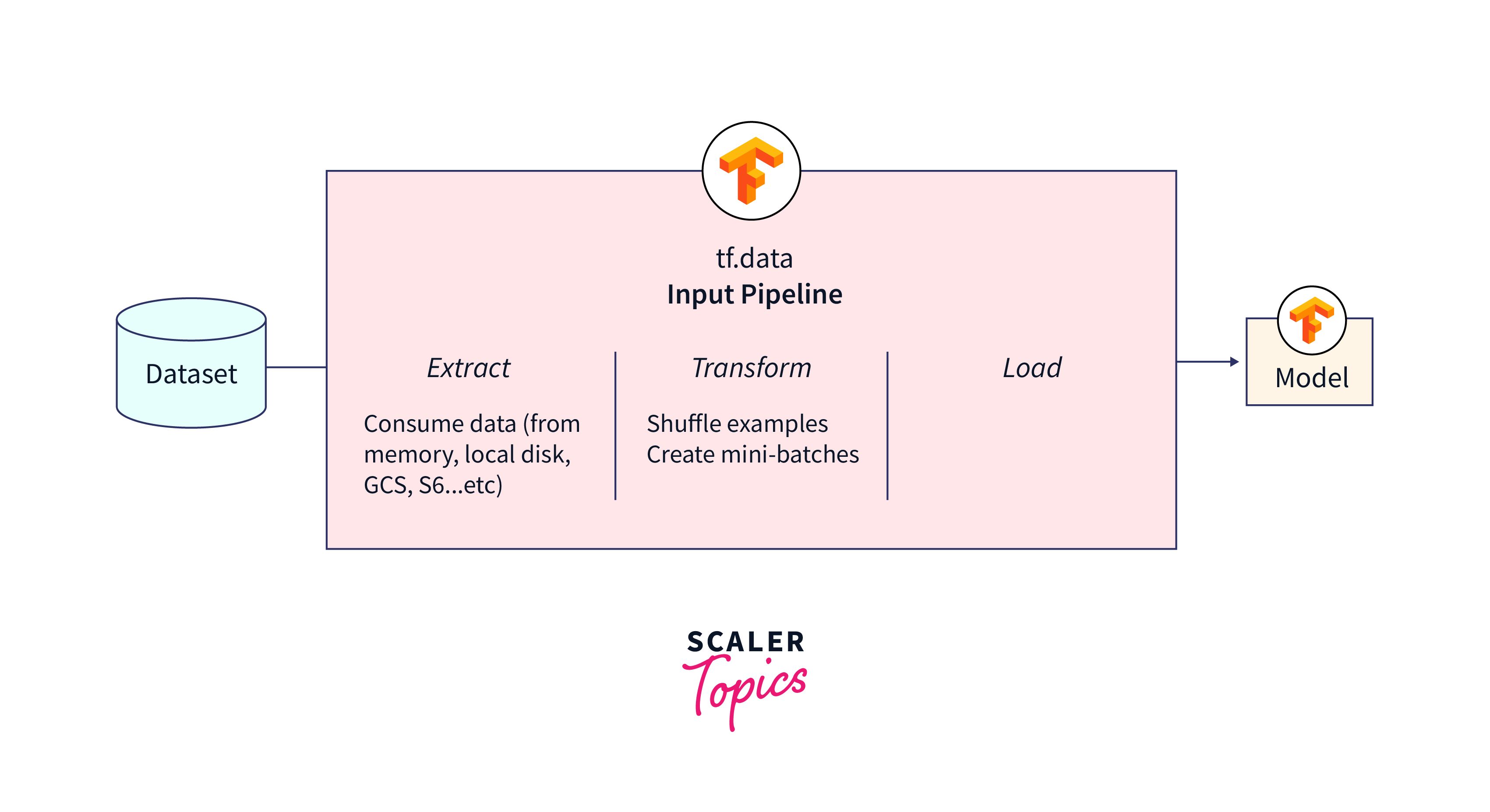
-
Distributed Training Strategies:
Techniques such as data parallelism and model parallelism can be applied to distribute model training and evaluation across multiple GPUs or machines. -
Horovod:
An open-source framework that can be integrated with TensorFlow for distributed training and inference, especially on multi-GPU setups. -
TensorFlow Extended (TFX):
A production-ready platform for deploying and managing machine learning models, which includes support for distributed evaluation and inference.
Overall, distributed evaluation and inference in TensorFlow play a crucial role in enabling the deployment of large-scale machine learning models and applications in real-world scenarios where speed, scalability, and reliability are essential.
Challenges and Considerations in Distributed Evaluation and Inference in TensorFlow
Implementing distributed evaluation and inference in TensorFlow comes with its set of challenges and considerations. These factors need careful attention to ensure the efficient and effective operation of such systems:
Challenges:
-
Data Distribution and Partitioning:
-
Data Imbalance:
Distributing data evenly across nodes can be difficult, especially with skewed datasets. Uneven data distribution can lead to resource inefficiencies and processing bottlenecks. -
Data Consistency:
Maintaining data consistency across distributed nodes, especially in dynamic environments, can be complex.To maintain data consistency, organizations can implement distributed databases or data consistency protocols. Technologies like Apache ZooKeeper or etcd can help manage distributed configuration and maintain data consistency.
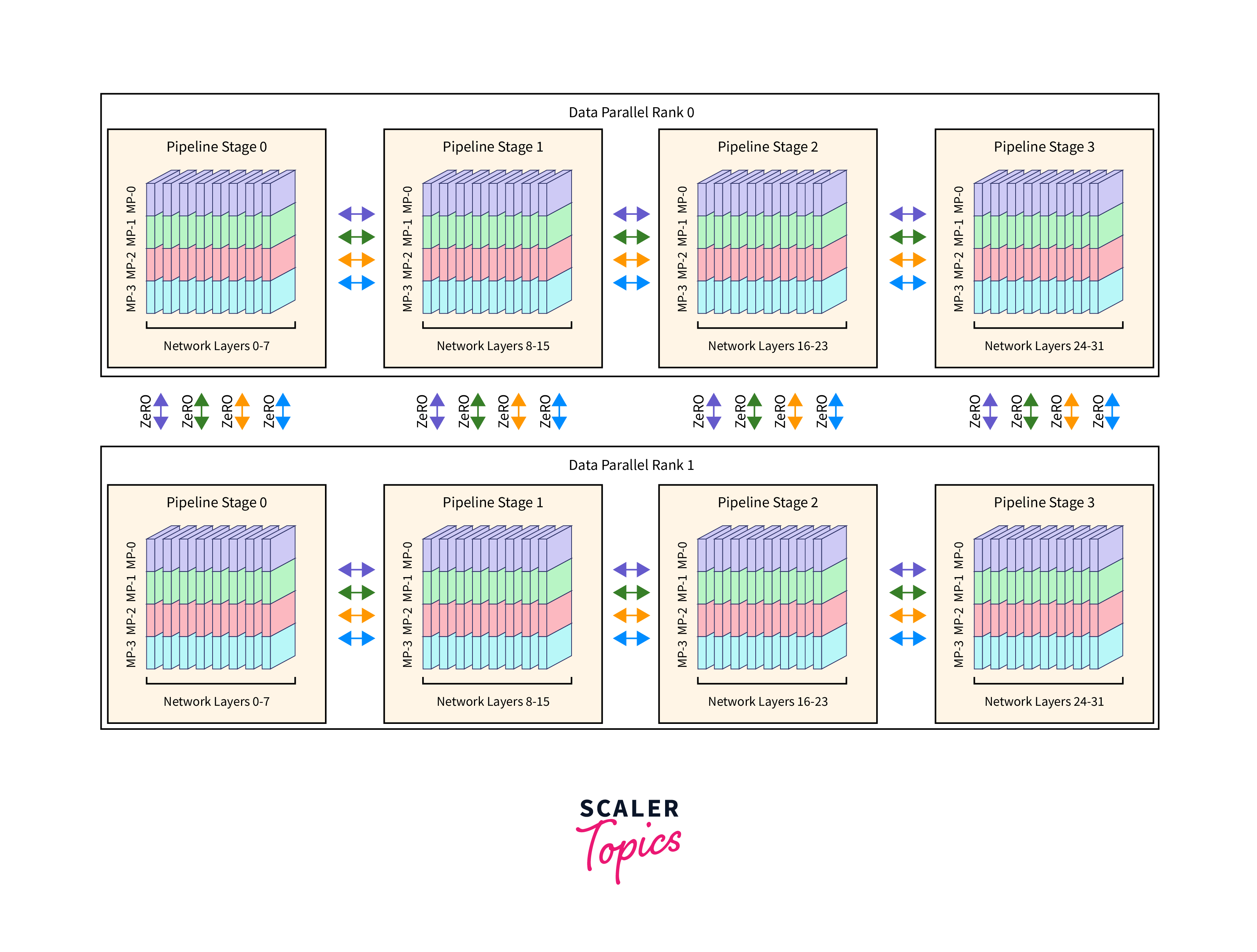
-
-
Model Distribution and Synchronization:
- Model Parallelism:
Splitting a machine learning model across multiple nodes can be challenging, as different model components may have varying computational requirements. Coordinating model updates across nodes is crucial. - Communication Overhead:
Inter-node communication for model synchronization can introduce overhead, affecting system performance. Efficient communication strategies are needed to mitigate this. - Organizations can use frameworks like TensorFlow or PyTorch, which offer built-in support for model parallelism. They can also design models with separate components that can be distributed efficiently across nodes.
- Model Parallelism:
-
Scalable Infrastructure:
-
Resource Provisioning:
Allocating and managing computational resources across a cluster of machines can be complex. Organizations need to ensure nodes have the right resources (CPU, GPU, memory) for efficient processing. -
Load Balancing:
Distributing tasks evenly across nodes is essential to prevent some nodes from becoming bottlenecks. Effective load-balancing strategies are necessary. -
Fault Tolerance:
Building fault-tolerant systems capable of handling node failures without significant disruptions is essential for system reliability.Load balancing can be achieved using load balancer software or services offered by cloud providers. Load balancers distribute incoming requests or tasks evenly among nodes, preventing overloads.
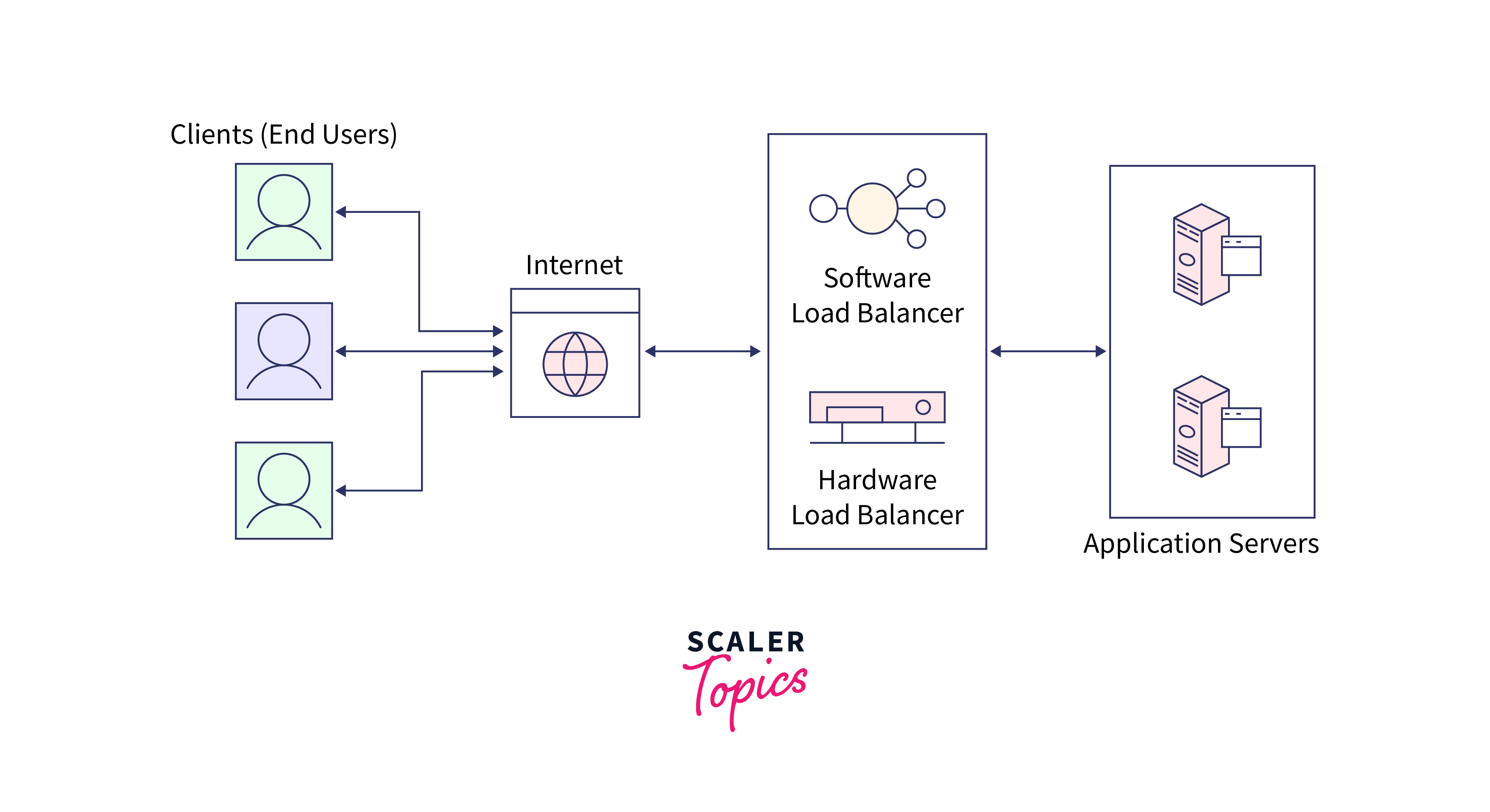
-
-
Concurrency and Parallelism:
- Concurrency Control:
In distributed systems, multiple nodes may access shared resources simultaneously, leading to potential conflicts. Implementing proper concurrency control mechanisms is vital. - Parallelism Efficiency:
Ensuring efficient parallel processing across nodes is a challenge. Overhead from parallelization, like synchronization and communication, should be minimized. - Minimizing parallelism overhead requires profiling and optimization. Tools like Apache Spark or Dask can help manage parallelism efficiently by minimizing data shuffling and optimizing task scheduling.
- Concurrency Control:
Considerations:
-
Architecture Design:
- Choose an appropriate system architecture (e.g., centralized, decentralized, hybrid) that aligns with the specific requirements and constraints of distributed evaluation and inference.
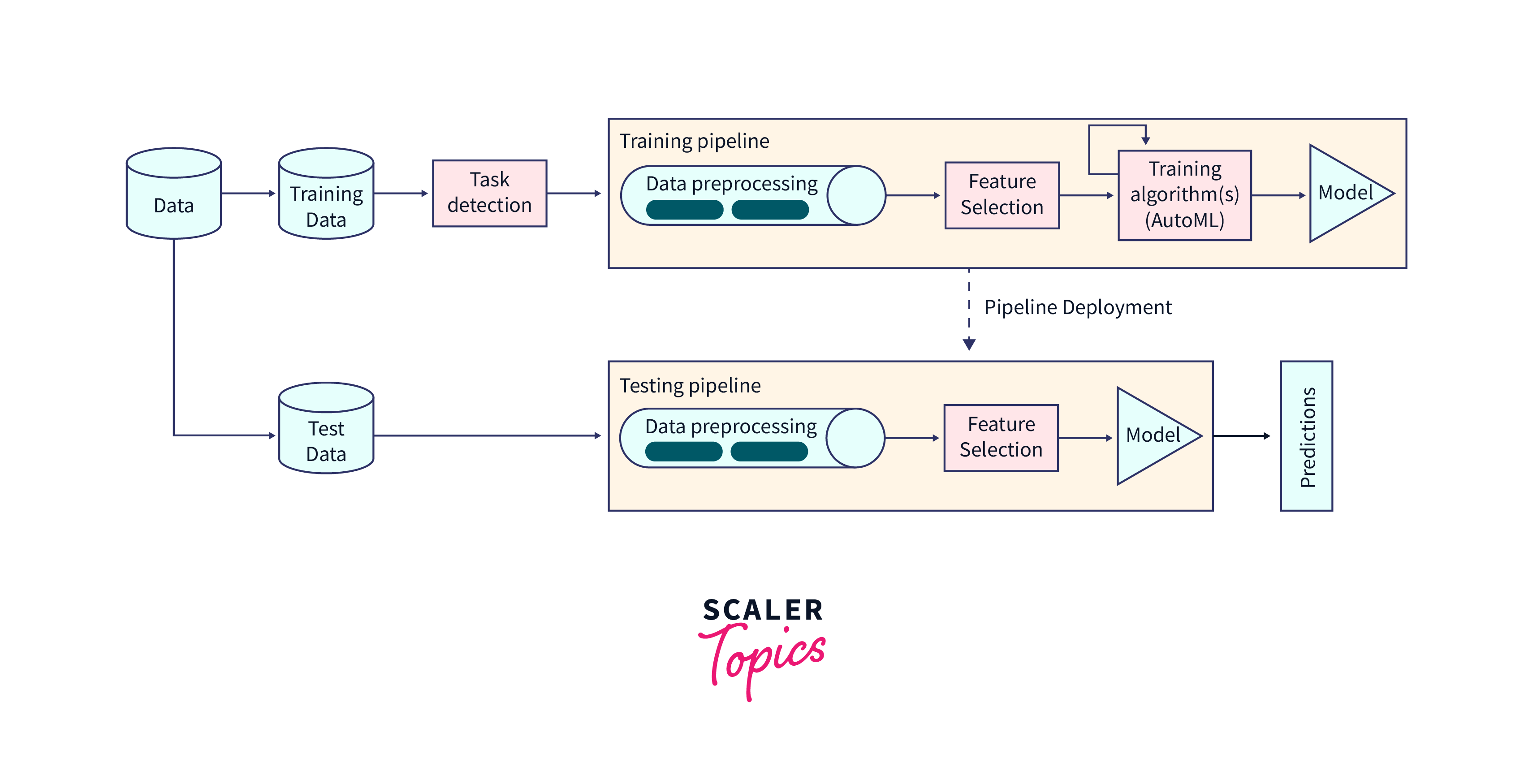
-
Scalability Planning:
- Plan for scalability from the outset to accommodate increasing data volume and user demand. Ensure the system can scale horizontally by adding more nodes when necessary.
-
Resource Monitoring:
- Implement robust monitoring and alerting systems to track resource utilization, performance metrics, and potential issues. Proactive monitoring helps identify and address problems promptly.
-
Cost Management:
- Distributed systems can incur significant costs, especially in cloud environments. Continuously analyze resource usage and optimize for cost efficiency to avoid unexpected expenses.
-
Security Measures:
- Implement comprehensive security measures to protect data and infrastructure. This includes access controls, encryption, authentication, and auditing.
-
Compatibility and Integration:
- Ensure seamless integration with existing systems and tools, including compatibility with evaluation algorithms and frameworks.
-
Documentation and Training:
- Provide thorough documentation and training for personnel responsible for managing the distributed system. This ensures effective operation and troubleshooting.
-
Testing and Simulation:
- Conduct comprehensive testing and simulation of the distributed system before deploying it at scale to identify and address potential issues and bottlenecks.
Scalable Infrastructure for Distributed Evaluation and Inference in TensorFlow
Building a scalable infrastructure for distributed evaluation involves designing and deploying a system that can efficiently handle large-scale evaluation tasks across multiple nodes or machines. Here are the key considerations and steps for creating such an infrastructure:
-
Define the Requirements:
- Workload Analysis:
Understand the nature of the evaluation tasks. Determine the volume of data to be processed, the complexity of the evaluations, and the expected workload patterns (e.g., bursty or consistent). - Scalability Needs:
Assess how much scalability is required. Consider factors like expected growth in evaluation tasks and data volume.
- Workload Analysis:
-
Select the Right Hardware:
-
Compute Resources:
Choose hardware with sufficient processing power (CPU and GPU), memory, and storage capacity to handle the anticipated workload. Cloud services like AWS, Azure, or GCP offer scalable computing resources.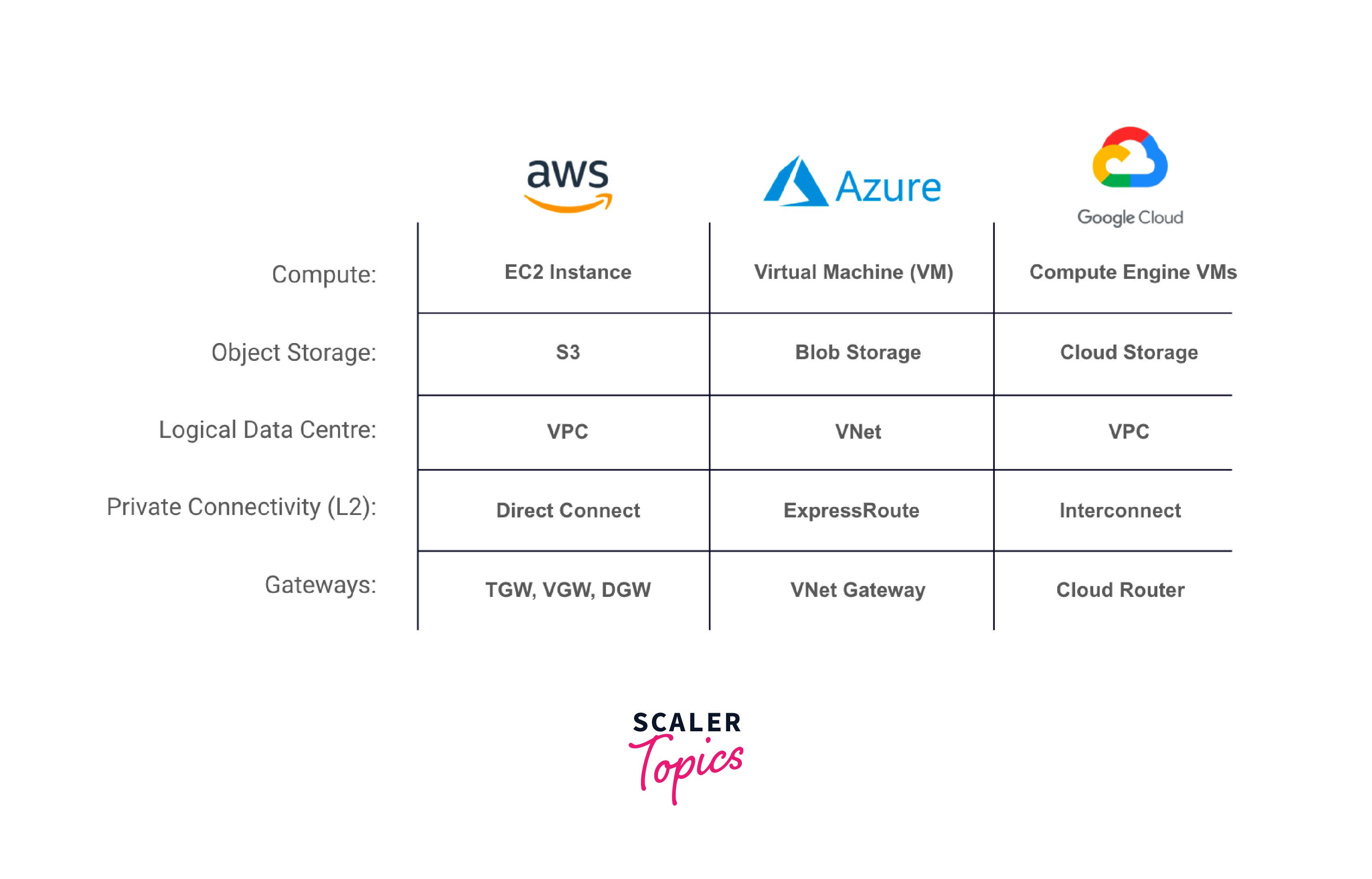
-
Network Infrastructure:
Ensure high-speed, low-latency networking between nodes to facilitate efficient data transfer and communication.
-
-
Choose Distributed Computing Frameworks:
- Select appropriate frameworks and tools for distributed evaluation. Popular options include Apache Hadoop, Apache Spark, or cloud-based platforms like AWS EMR or Google Dataprep.
- Utilize containerization technologies like Docker and orchestration platforms like Kubernetes for managing and scaling containers.
-
Data Management for Distributed Evaluation and Inference in TensorFlow:
- Implement a distributed file system or storage solution (e.g., HDFS, Amazon S3) for storing input data, intermediate results, and output data. This allows for efficient data access and sharing across nodes.
- Use data partitioning and sharding techniques to distribute data evenly across nodes and reduce data transfer bottlenecks.
-
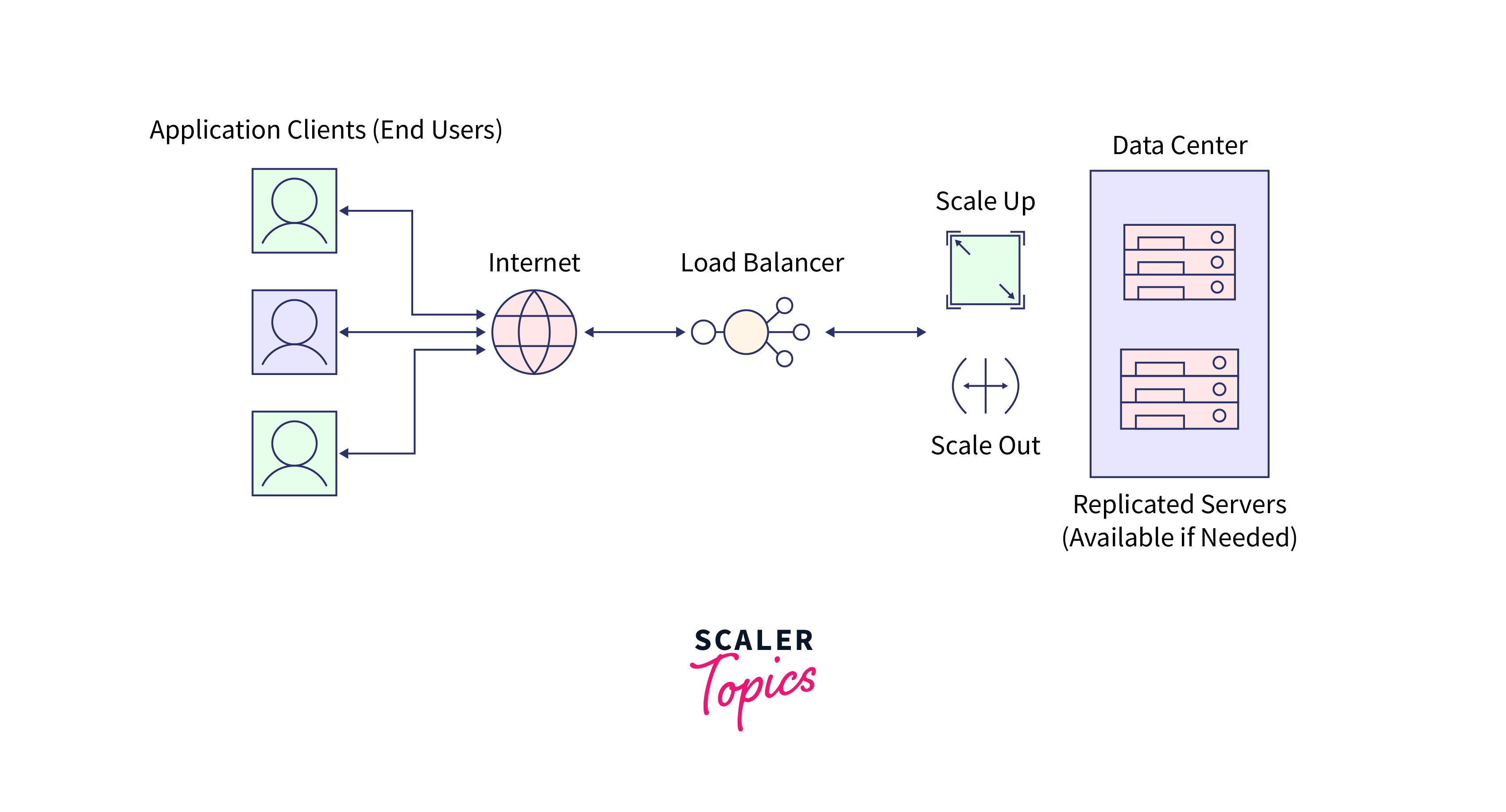
Load Balancing:
- Deploy load balancers to distribute incoming evaluation requests evenly across nodes. This prevents any single node from becoming a performance bottleneck.
- Consider using auto-scaling mechanisms that automatically add or remove nodes based on workload demands.
-
Fault Tolerance:
- Implement fault tolerance mechanisms to handle node failures gracefully. Techniques like replication, checkpointing, and backup systems can help maintain system reliability.
-
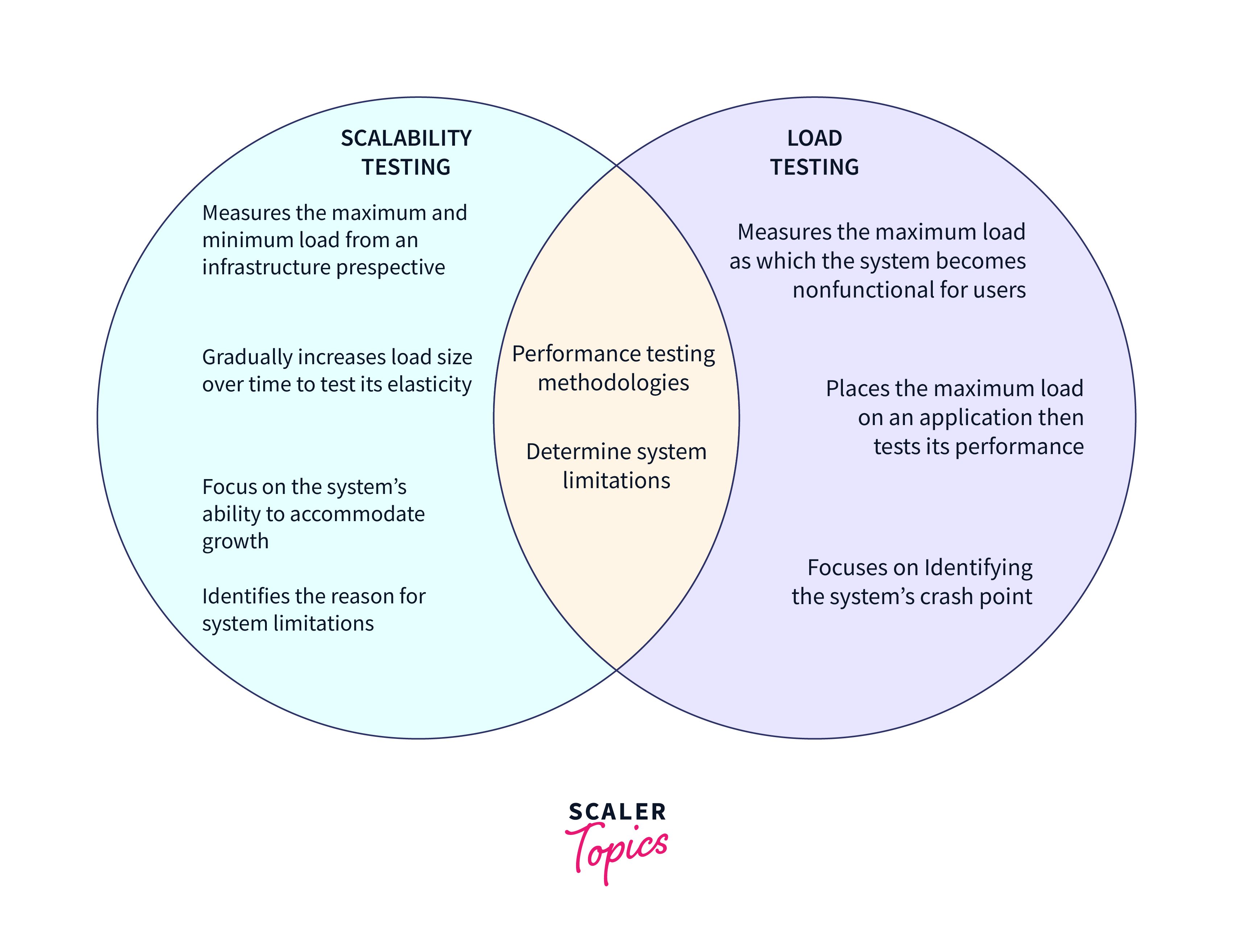
Scalability Testing:
- Conduct scalability tests to evaluate how the system performs under increasing loads. Identify potential bottlenecks and optimize the system accordingly.
-
Monitoring and Management:
- Implement comprehensive monitoring tools to track the performance, resource utilization, and health of all nodes in the distributed infrastructure.
- Use centralized management and orchestration tools to streamline the deployment, scaling, and maintenance of distributed nodes.
-
Security:
- Implement security measures to protect the infrastructure, data, and evaluation processes. This includes network security, access controls, encryption, and compliance with relevant regulations.
-
Cost Optimization:
- Continuously monitor resource usage and costs to ensure cost-effective operation. Adjust resource allocation and scaling strategies as needed to optimize costs.
-
Documentation and Training:
- Provide documentation and training for the operations team to effectively manage and troubleshoot the distributed infrastructure.
Building a scalable infrastructure for distributed evaluation is a complex task that requires careful planning, testing, and ongoing maintenance. By considering these steps and factors, organizations can create a robust and efficient infrastructure capable of handling the demands of large-scale evaluation tasks.
Distributed Evaluation vs. Distributed Training
Distributed evaluation and distributed training are two distinct phases in the lifecycle of machine learning models. While both involve leveraging distributed computing resources, they serve different purposes and have different characteristics.
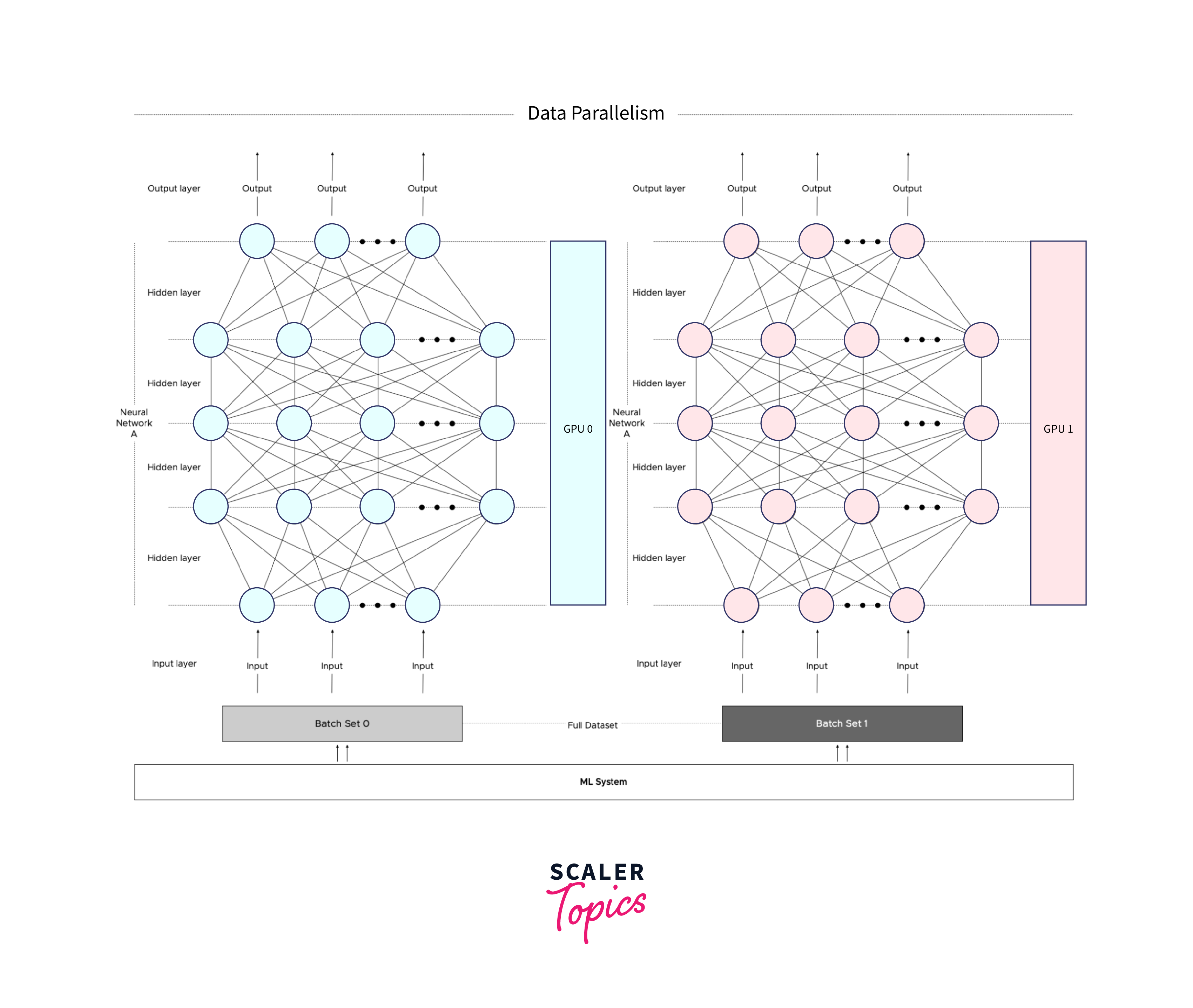
In summary, grasping the differences between distributed training and distributed evaluation in machine learning is not only important for technical reasons but also for strategic resource allocation, performance monitoring, and cost management in the development and operation of machine learning systems. It enables organizations to build scalable, efficient, and reliable ML pipelines.
Below is a comparison table highlighting the key differences between distributed evaluation and distributed training:
| Aspect | Distributed Evaluation | Distributed Training |
|---|---|---|
| Purpose | Assess model performance and generate predictions on new data. | Train machine learning models on large datasets to learn patterns and parameters. |
| Goal | Measure the model's accuracy, precision, recall, F1 score, etc. | Optimize model parameters (weights and biases) to minimize loss or error. |
| Dataset | Typically uses a separate evaluation dataset not used during training. | Utilizes a training dataset to update model parameters iteratively. |
| Computational Load | Less computationally intensive than training since it doesn't involve backpropagation. | Highly computationally intensive, involving backpropagation and gradient updates. |
| Parallelism | Can be performed in parallel across multiple nodes, but often uses fewer resources compared to training. | Requires substantial parallelism to process large batches or sub-batches of data simultaneously. |
| Data Movement | Typically minimal data movement as the evaluation dataset is fixed and doesn't change during evaluation. | Involves significant data movement during gradient computation and synchronization. |
| Resource Utilization | Uses resources efficiently for inference, especially when dealing with real-time predictions. | Requires high resource utilization, including multiple GPUs or distributed clusters, during training. |
| Model Update | No model updates; the model remains fixed during evaluation. | The model parameters are updated iteratively during training. |
| Fault Tolerance | Fault tolerance is important but not as critical as in training since evaluation doesn't involve weight updates. | Fault tolerance is crucial as failures during training can lead to data loss and model instability. |
| Example Use Cases | 1. Assessing the accuracy of a deployed image classification model. 2. Generating recommendations in a recommendation system. | 1. Training a deep neural network for image recognition. 2. Training a natural language processing model for text generation. |
In summary, distributed evaluation focuses on assessing the performance of a trained model on new data and doesn't involve weight updates. In contrast, distributed training is the process of optimizing a model by updating its parameters based on a training dataset, often requiring substantial computational resources and parallelism. Both phases benefit from distributed computing but serve different roles in the machine learning pipeline.
Conclusion
- Distributed evaluation and Inference in TensorFlow assesses model performance without weight updates, while distributed training optimizes models through parameter updates.
- Distributed evaluation uses separate data and has lower computational demands, suitable for real-time inference.
- Distributed training relies on training data, requiring significant computation and data movement, with critical fault tolerance considerations.