Distributed Training with Keras
Overview
In this article, we will explore the concept of Distributed Training with Keras. Distributed training is a technique used to train deep learning models on multiple machines or GPUs simultaneously, enabling faster and more efficient training of large-scale models. We will cover the different types of distributed training, how to set it up with Keras, and its impact on performance.
What is Distributed Training with Keras?
Distributed training with Keras is a technique used to speed up the training process of deep learning models by leveraging multiple computing devices or machines. Instead of relying on a single machine, distributed training divides the workload across several devices, such as GPUs or multiple servers.
This allows the model to process data and compute gradients in parallel, reducing the overall training time significantly. Keras provides support for distributed training through data parallelism and model parallelism. Data parallelism involves replicating the model on each device and processing different batches of data concurrently, while model parallelism divides the model's layers across devices to handle larger models efficiently.
Types of Distributed Training with Keras
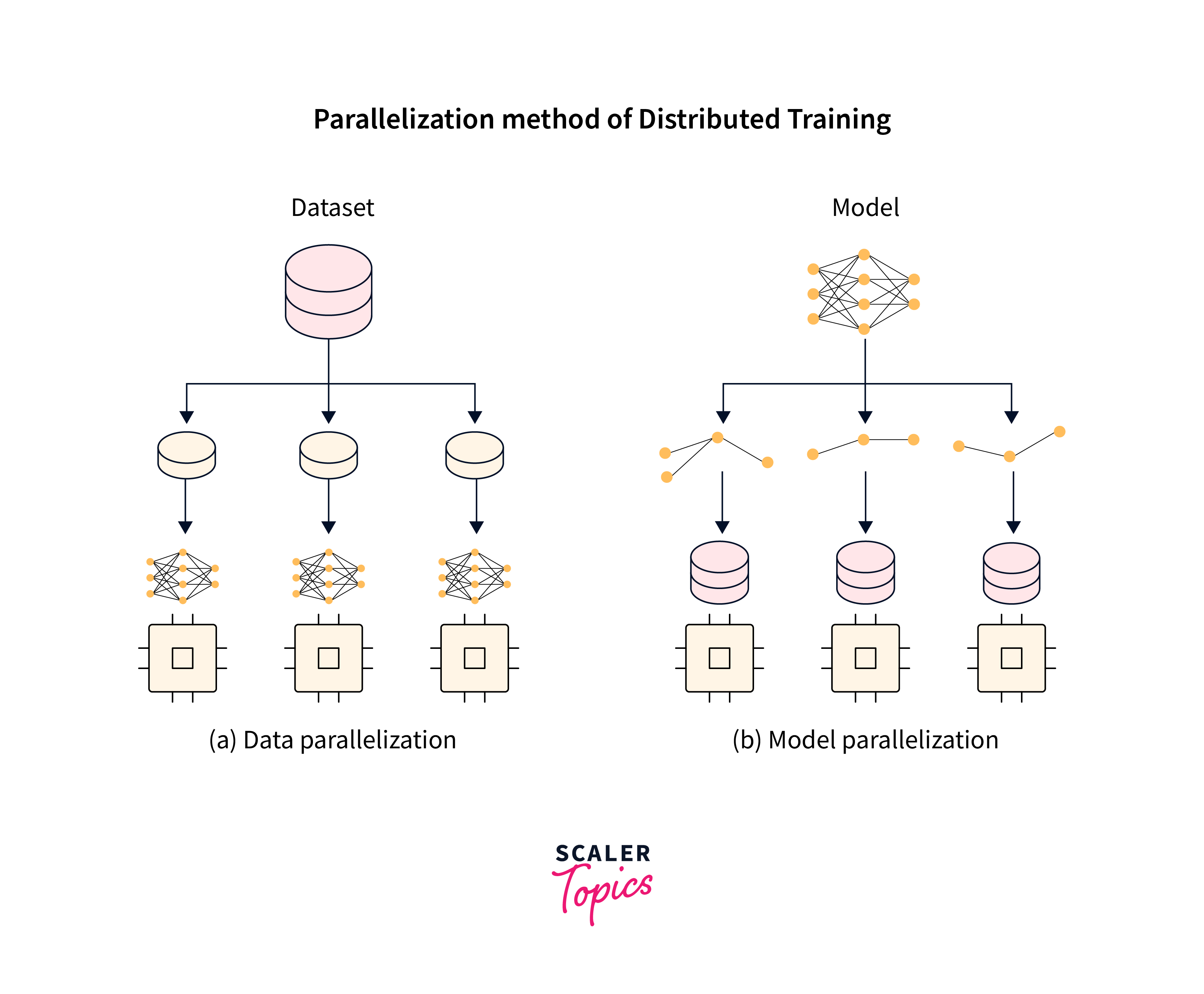
Keras supports two primary approaches for distributed training: data parallelism and model parallelism.
Data Parallelism with Keras:
Data parallelism involves replicating the model across multiple devices, and each device receives a batch of data for training. The gradients from each device are then averaged to update the shared model, ensuring consistency.
Model Parallelism with Keras:
Model parallelism splits the model across multiple devices, enabling the training of large models that may not fit into the memory of a single device. Each device is responsible for computing the forward and backward passes for a specific part of the model.
Setting up Distributed Training with Keras
Setting up Distributed Training with Keras enables the efficient utilization of multiple computing devices or machines to accelerate the training of deep learning models. By distributing the workload, the training process becomes significantly faster and can handle more extensive and complex models.
Setting up Distributed Training with Keras involves several steps to efficiently leverage multiple computing devices for faster model training. Here's a step-by-step guide:
-
Choose Distributed Backend: Keras supports multiple distributed backends, such as TensorFlow and Horovod. Select the backend that best suits your hardware setup and requirements.
-
Data Parallelism or Model Parallelism: Determine the appropriate approach for your distributed training. Data parallelism is suitable for scenarios where each device can process different batches of data in parallel, while model parallelism is preferred for large models with layers distributed across devices.
-
Install Required Libraries: Ensure you have the necessary libraries installed, such as TensorFlow, Horovod, and MPI (Message Passing Interface) for communication between nodes.
-
Prepare Data: Set up your dataset to be accessible by all the devices involved in training. Consider using distributed data loading techniques to efficiently distribute data to each device.
-
Model Definition: Create your deep learning model using Keras. Ensure that the model is compatible with distributed training, especially if you are using model parallelism.
-
Distributed Training Configuration: Configure the distributed training settings, such as the number of devices (GPUs or nodes) and the communication strategy.
-
Distributed Training Execution: Start the distributed training process, where each device works on its assigned data or model layers, and gradients are exchanged and combined to update the shared model.
-
Monitor Training Progress: Monitor the training process and performance metrics to ensure that the distributed setup is effectively speeding up the training without any issues.
-
Synchronize and Summarize: At the end of each training iteration, ensure proper synchronization and summarize the gradients across devices to maintain consistency in model updates.
-
Testing and Fine-tuning: After training, evaluate your model's performance on a separate validation set. Fine-tune the hyperparameters if needed to achieve better results.
Data Parallelism Example in Keras
Data parallelism is a distributed training technique where the model is replicated across multiple GPUs or devices, each handling a different batch of data simultaneously. Gradients are combined to update the shared model. It's useful for large models that don't fit into a single device's memory and speeds up training using multiple GPUs.
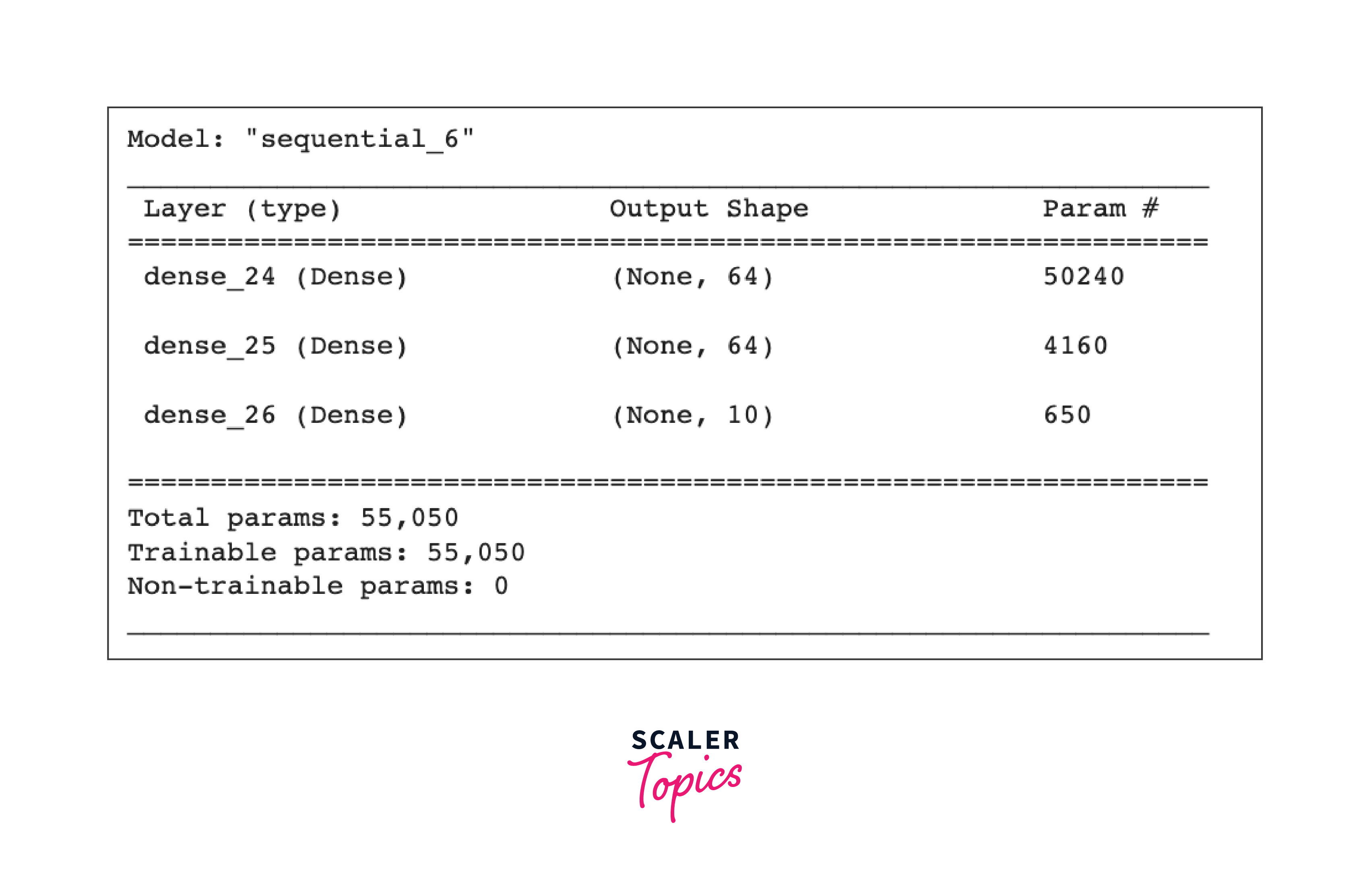
Keras distributed training supports data parallelism through tf.distribute.MirroredStrategy in TensorFlow 2.x, automatically distributing the model and data across GPUs and managing gradient communication during training.
Output:
Model Parallelism with Keras
Model Parallelism with Keras involves splitting a deep learning model across multiple devices, enabling the training of large models that may not fit into the memory of a single device. Each device is responsible for computing the forward and backward passes for a specific part of the model. Let's take an example of how to implement model parallelism with Keras using TensorFlow backend:
OUTPUT

Distributed Training Performance
Distributed training with Keras has proven to be effective in various real-world scenarios where large-scale deep learning models need to be trained efficiently. Here are a few examples:
Autonomous Vehicles: Distributed training in Keras accelerates convergence of CNNs for object detection, lane detection, and pedestrian recognition in autonomous vehicles, reducing training time and enhancing model accuracy for safer self-driving capabilities.
Language Translation: For machine translation, distributed training expedites large transformer models' convergence, enabling quicker deployment of accurate translation services, benefiting companies in the language translation sector.
Drug Discovery and Healthcare: Deep learning models for drug screening, protein structure prediction, and disease diagnosis train faster with distributed training, aiding pharmaceutical firms in rapid drug development and medical research.
Financial Risk Assessment: Distributed training shortens the training cycle of risk assessment models used by financial institutions, allowing timely updates and more efficient risk management in dynamic market conditions.
Weather Prediction and Climate Modeling: Climate models trained with distributed training yield faster and more accurate weather predictions, supporting climate scientists in enhancing forecasting and climate understanding.
E-commerce Recommendations: E-commerce platforms employ distributed training for collaborative filtering models, delivering quicker convergence and improved personalized recommendations, enhancing user engagement and sales.
High-Performance Research: Distributed training aids scientific researchers by accelerating the training of deep learning models, enabling faster insights and breakthroughs in fields like astronomy, physics, and genomics.
Conclusion
-
Keras Distributed training with Keras utilizes the power of multiple devices or machines to speed up the training process of deep learning models.
-
By dividing the training workload across devices, it allows for parallel processing of data and parameters, significantly reducing training time.
-
This approach is particularly beneficial for training large-scale models that may not fit into the memory of a single device, enabling the handling of more extensive and complex architectures.
-
Distributed training optimizes computational resources, making it an ideal choice for tackling complex deep learning tasks and handling massive datasets efficiently.
-
With faster convergence and improved performance, distributed training empowers researchers and practitioners to train state-of-the-art models effectively, taking deep learning applications to new heights.
Related Topics
Further delve deep into the following topics to know more about Distributed Training with Keras.