Accelerating Deep Learning with TensorFlow GPU
Overview
GPUs for deep learning, when combined with TensorFlow, play a crucial role in accelerating Deep Learning workflow. By leveraging the parallel processing capabilities of GPUs, TensorFlow enables researchers and practitioners to achieve faster model training and inference times, leading to improved performance and productivity. This article will delve into GPU acceleration in deep learning and explore how TensorFlow leverages GPUs for deep learning tasks.
Introduction
TensorFlow, a popular open-source deep learning framework developed by Google, offers comprehensive support for utilizing GPUs for deep learning tasks. By harnessing the power of GPUs, TensorFlow can leverage their parallel processing capabilities to accelerate computations, resulting in faster and more efficient deep learning workflows.
GPUs, originally designed for graphics processing with their parallel architecture, excel in handling the matrix operations and tensor calculations involved in deep learning models. TensorFlow automatically maps tensor operations to the GPU, taking advantage of thousands of cores for faster computation.
Overall, TensorFlow's support for GPUs enhances the efficiency and speed of deep learning workflows, making it a popular choice for machine learning practitioners.
Understanding TensorFlow GPUs for Deep Learning
TensorFlow, a leading deep learning framework, seamlessly integrates with GPUs to enhance performance and accelerate deep learning tasks. GPUs are specifically designed for parallel processing, enabling them to handle multiple computations simultaneously. By harnessing the power of TensorFlow GPUs, professionals can achieve faster model training and inference, making deep learning workflows more efficient and productive.
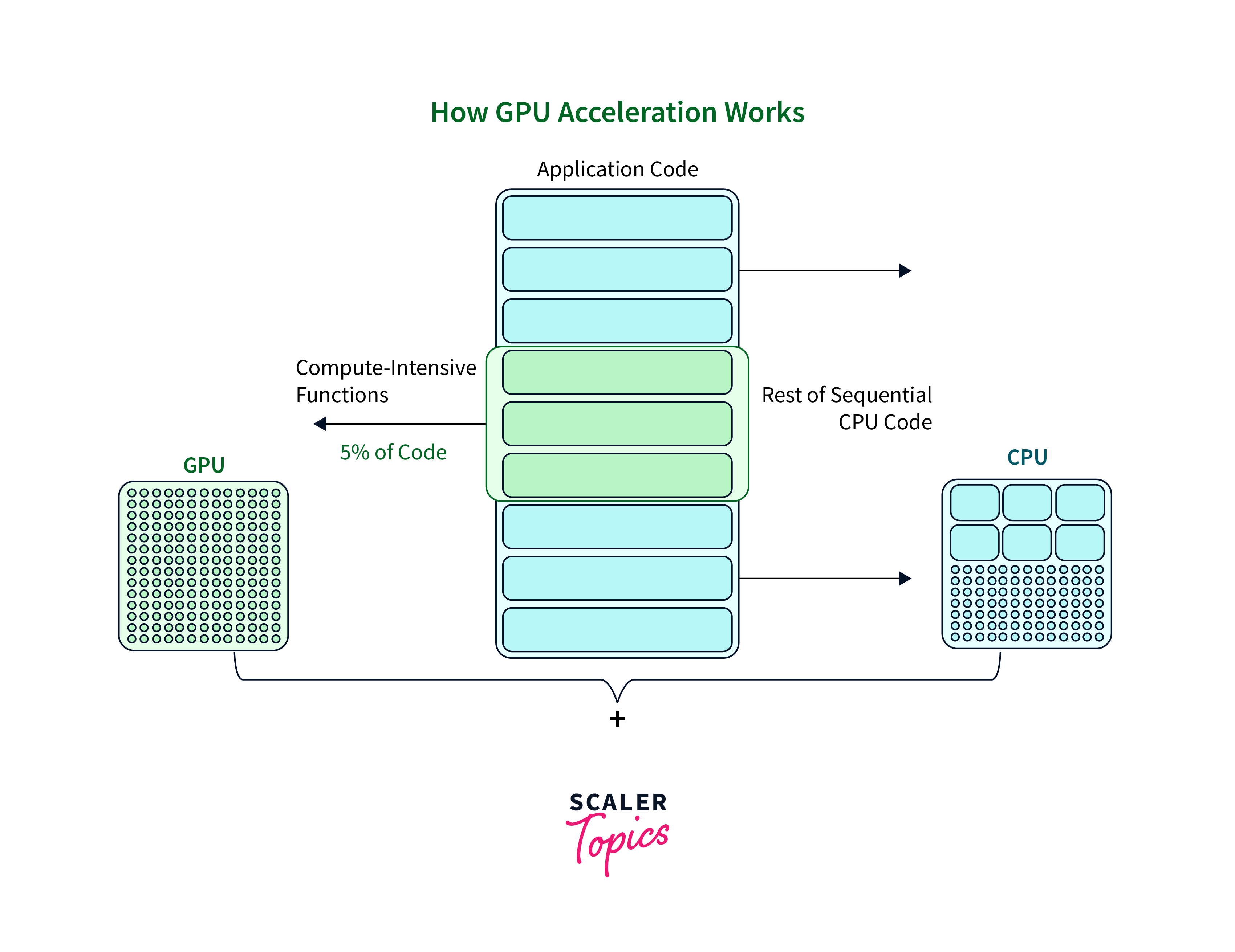
TensorFlow's GPUs for deep learning enables the more efficient training of complex architectures on large datasets, facilitating the exploration of sophisticated models and tackling real-world challenges. This integration empowers deep learning practitioners to push the boundaries of artificial intelligence and drive advancements in various domains.
By leveraging the parallel processing capabilities of GPUs, TensorFlow significantly accelerates computations, allowing for faster training times and enabling researchers to experiment with cutting-edge models and address intricate problems effectively. The combination of TensorFlow's feature-rich framework and GPU acceleration paves the way for transformative developments in the field of deep learning, fostering innovation and progress in artificial intelligence applications.

Benefits of Using GPUs for Deep Learning:
Utilizing GPUs for deep learning in conjunction with TensorFlow offers several benefits:
-
Enhanced Performance:
GPUs are optimized for parallel processing, allowing them to handle multiple computations simultaneously. By offloading computations to GPUs, TensorFlow significantly speeds up training and inference times, leading to improved performance and productivity in deep learning tasks.
-
Scalability:
Deep learning models often involve large datasets and complex architectures. GPUs provide the necessary scalability to process massive amounts of data and perform computations in parallel. TensorFlow's integration with GPUs allows for efficient scaling, enabling researchers and practitioners to tackle larger and more complex deep learning problems.
-
Cost-Effectiveness:
Although GPUs may have a higher upfront cost compared to CPUs, their efficiency and faster processing times make them cost-effective in the long run. By reducing the time required for model training and inference, GPU acceleration with TensorFlow enables organizations to iterate more quickly, optimize their deep learning workflows, and achieve faster time-to-market.
What is GPU Acceleration in Deep Learning?
GPU acceleration in deep learning refers to the utilization of Graphics Processing Units (GPUs) to enhance the computational performance of deep learning tasks. GPU acceleration in deep learning involves using Graphics Processing Units (GPUs) to accelerate the computations required for training and running deep learning models.
Additionally, GPU acceleration facilitates the deployment of real-time deep learning applications, making AI practical and applicable to a wide range of real-world challenges, from computer vision and natural language processing to autonomous systems and medical diagnosis. The combination of GPUs and deep learning has revolutionized the field of artificial intelligence, pushing the boundaries of what's possible and driving transformative advancements across industries.
- Deep learning models involve complex mathematical computations and large-scale matrix operations, which can be computationally intensive and time-consuming.
- GPUs for deep learning, designed with numerous cores and high memory bandwidth, excel at parallel processing and can perform multiple calculations simultaneously.
- By leveraging GPUs, deep learning frameworks such as TensorFlow can distribute these computations across the GPU cores, significantly speeding up the training and inference processes.
- GPU acceleration enables faster model training, quicker experimentation, and improved scalability, leading to more efficient and effective deep learning workflows.
Setting up TensorFlow GPU
Setting up TensorFlow with GPUs for deep learning support involves several steps, including ensuring hardware compatibility, installing GPU drivers, and configuring CUDA and cuDNN libraries.
Follow the instructions below to set up TensorFlow GPU on your system:
Hardware Requirements:
- Check if your system has a compatible GPU from NVIDIA. Refer to TensorFlow's official documentation for the list of supported GPUs.
- Ensure that your GPU has enough memory to accommodate your deep learning models and datasets.
Software Requirements:
- Operating System: TensorFlow GPU is compatible with Windows, Linux, and macOS.
- Python: Install the latest version of Python, preferably Python 3, as TensorFlow requires Python for its installation and usage.
Step1: Install GPU Drivers:
- Visit the NVIDIA website and download the latest GPU drivers for your specific GPU model and operating system.
- Follow the installation instructions provided by NVIDIA to install the GPU drivers.
Step 2: Install CUDA Toolkit:
- CUDA is a parallel computing platform and API model developed by NVIDIA. TensorFlow requires CUDA for GPU acceleration.
- Download the appropriate version of CUDA Toolkit from the NVIDIA Developer website, considering the compatibility with your GPU and operating system.
- Follow the installation instructions provided by NVIDIA to install
Step 3: Install cuDNN Library:
- cuDNN (CUDA Deep Neural Network) is a GPU-accelerated library specifically designed for deep neural networks.
- Sign up for the NVIDIA Developer Program and download the cuDNN library, ensuring compatibility with the installed CUDA version.
- Extract the cuDNN package and place the files in the appropriate directories as instructed in the cuDNN installation guide.
Step 4: Create a Virtual Environment (Optional):
- It is recommended to set up a virtual environment to isolate your TensorFlow installation and dependencies.
- Use a package manager like virtualenv or conda to create a virtual environment.
Step 5: Install TensorFlow GPU:
- Activate your virtual environment (if applicable).
- Install TensorFlow GPU by running the following command:
Output:
Step 6: Verify the Installation:
Run a simple TensorFlow GPU test script to ensure that TensorFlow is successfully utilizing your GPU for computation.
By following these steps, you can set up TensorFlow GPU on your system, allowing you to take advantage of the accelerated deep learning performance provided by GPU acceleration.
Configuring TensorFlow for GPU
Configuring TensorFlow to utilize the GPU for computations involves specifying the device placement and ensuring the integration with CUDA. Follow the steps below to configure TensorFlow for GPU:
-
Install TensorFlow-GPU:
- Ensure that you have already installed the TensorFlow-GPU package using the appropriate installation method (e.g., pip).
- Verify that the installation was successful by importing TensorFlow in your Python environment.
-
Verify GPU Availability:
To check if TensorFlow can detect and utilize your GPU, use the following code snippet:
Output:
If a GPU is detected, it should display information about the available GPUs. Otherwise, ensure that the GPU drivers, CUDA, and cuDNN are correctly installed.
-
Specify GPU Device Placement:
TensorFlow allows you to specify the device placement for computations, designating the GPU as the preferred device. You can use the following code to explicitly set the GPU as the device:
-
Parallelize TensorFlow Operations:
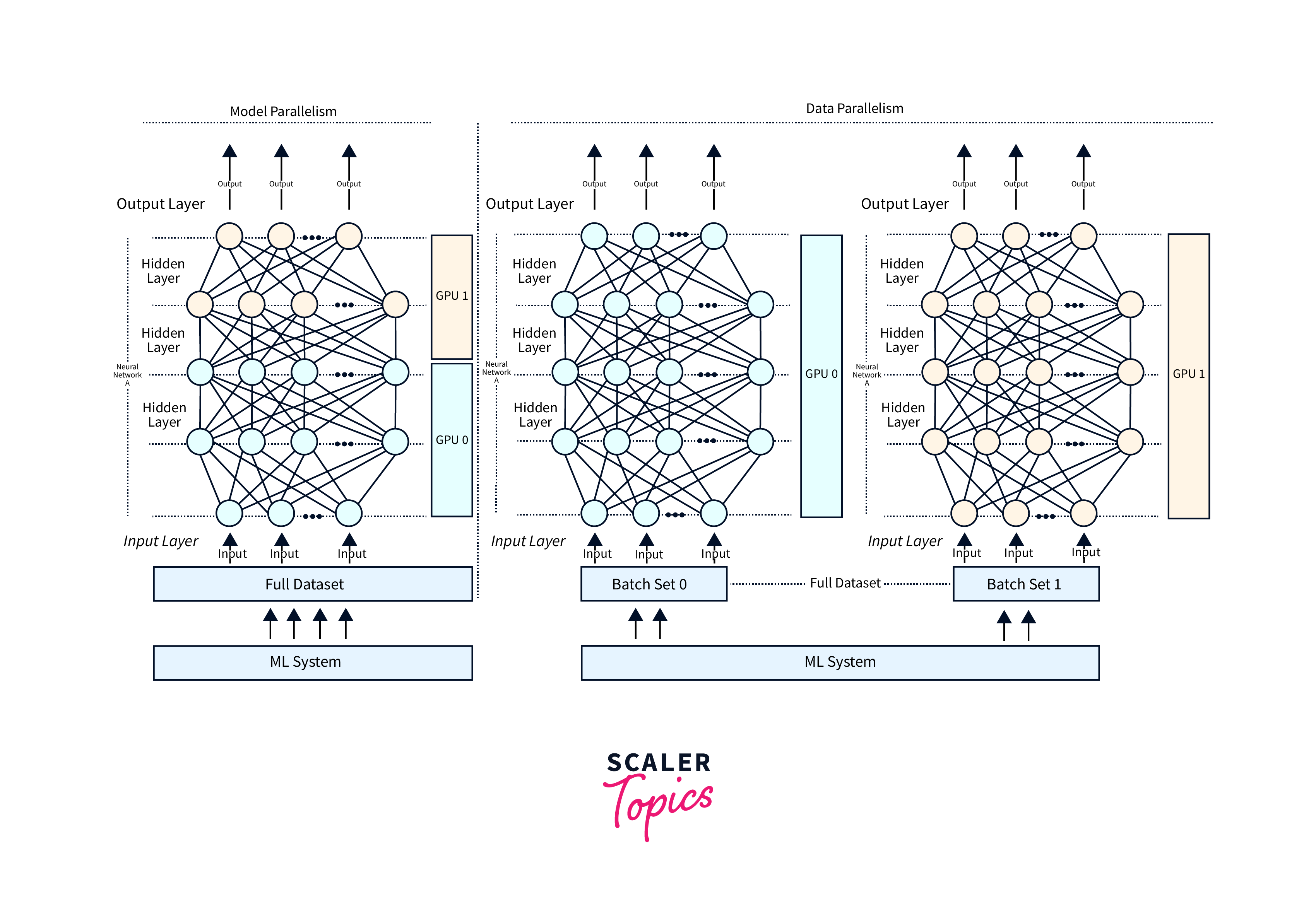
- TensorFlow automatically assigns computations to available devices. However, you can explicitly parallelize operations across multiple GPUs using TensorFlow's tf.distribute.Strategy API.
- Explore the TensorFlow documentation to learn more about distributed training and multi-GPU configurations.
-
Verify GPU Utilization:
To verify that TensorFlow is utilizing the GPU for computations, you can run a simple code snippet that performs matrix multiplication on the GPU:
Sample Output:
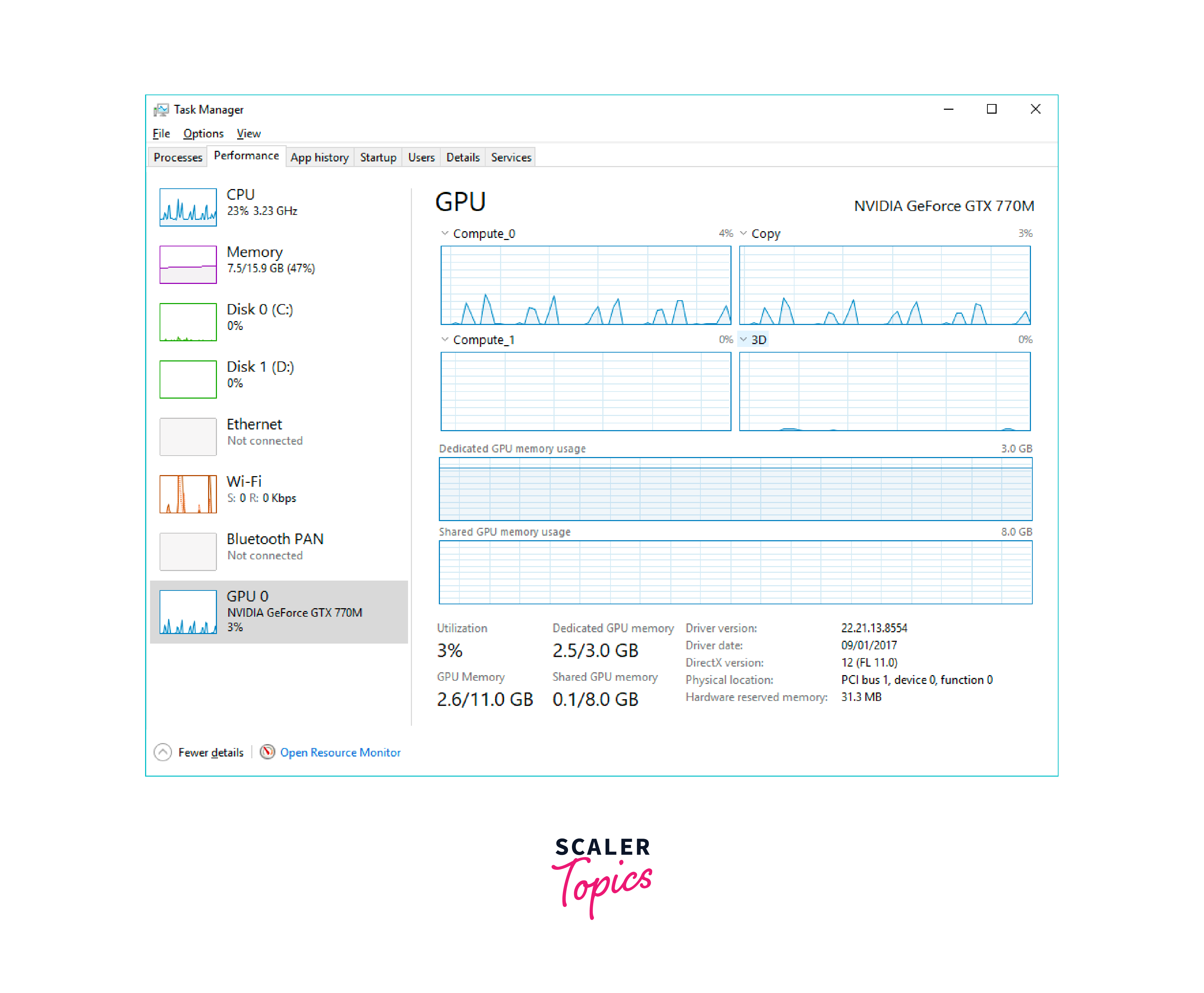
- By following these steps, you can configure TensorFlow to utilize the GPUs for deep learning. Remember to ensure proper installation of GPU drivers, CUDA, and cuDNN for successful GPU integration.
- Adjust the code examples based on your specific requirements, such as selecting a different GPU device or implementing distributed training across multiple GPUs.
- Refer to the TensorFlow documentation for further details on GPU configuration and optimizing GPU performance in TensorFlow.
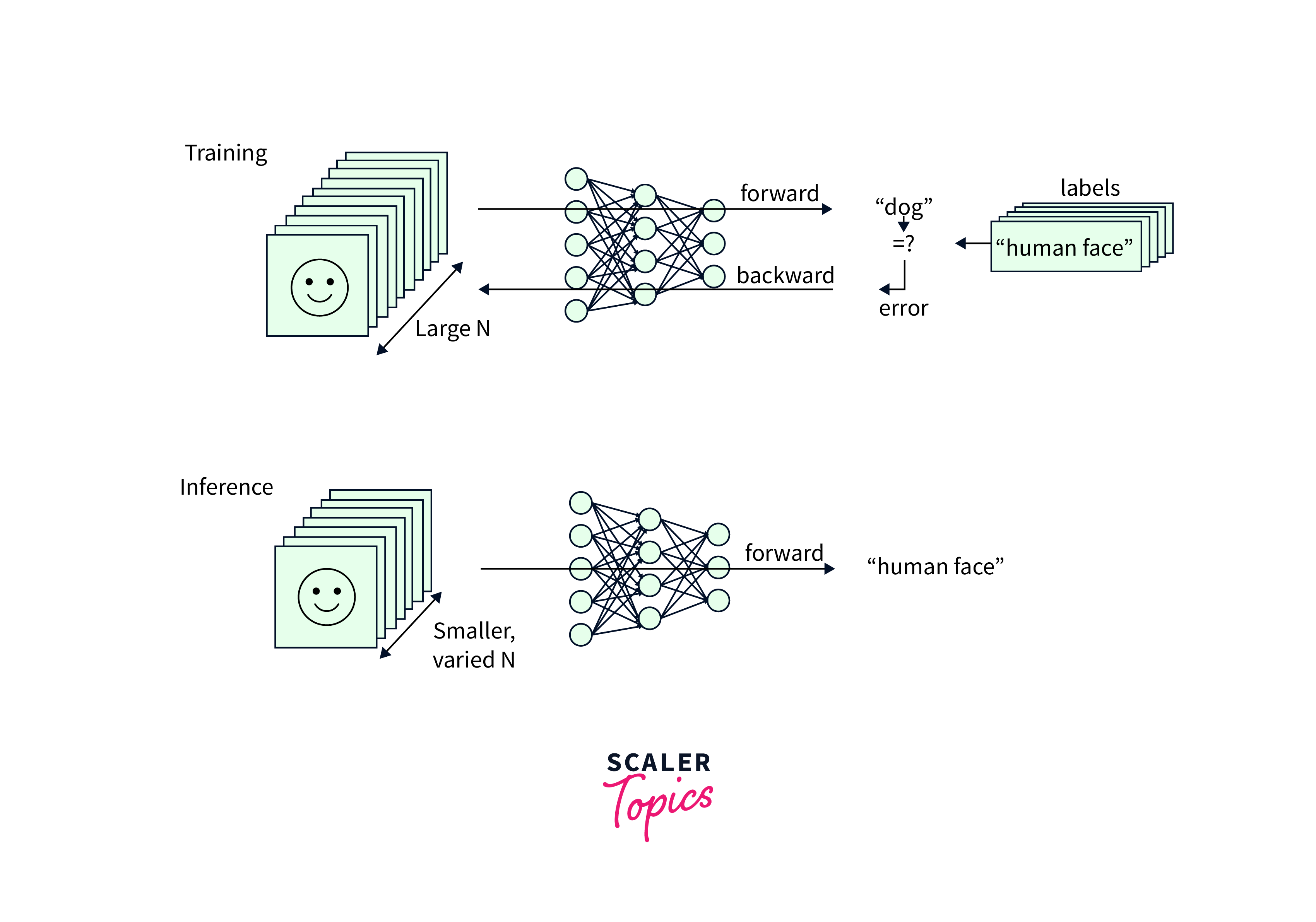
GPU-Accelerated Model Training
GPU-accelerated model training refers to the utilization of Graphics Processing Units (GPUs) to enhance the speed and efficiency of training deep learning models.
By offloading the computations involved in training deep neural networks to GPUs, the training process becomes significantly faster compared to traditional Central Processing Units (CPUs).
Here are some characteristics of GPU-Accelerated Model Training:
-
Faster Training Times:
GPUs for deep learning excel at parallel processing, allowing for faster model training compared to traditional CPUs. With GPU acceleration, deep learning models can process large batches of data simultaneously, reducing the overall training time. This enables researchers and data scientists to iterate more quickly, experiment with different architectures, and explore larger datasets.
Example: Training an image classification model on a GPU can significantly speed up the training process. With GPU acceleration, the model can process multiple images in parallel, resulting in faster convergence and improved training efficiency.
-
Handling Complex Architectures:
Deep learning models often involve complex architectures with numerous layers and parameters. GPUs provide the computational power needed to handle these intricate structures efficiently. GPUs for deep learning and GPU acceleration allows for seamless parallel processing of the computations involved in forward and backward propagation, enabling the training of complex models in a reasonable timeframe.
Example: Training a deep neural network with hundreds of layers, such as a deep residual network (ResNet), benefits greatly from GPU acceleration. The parallel processing capabilities of GPUs for deep learning enable efficient computation of the network's forward and backward passes, accelerating the training process.
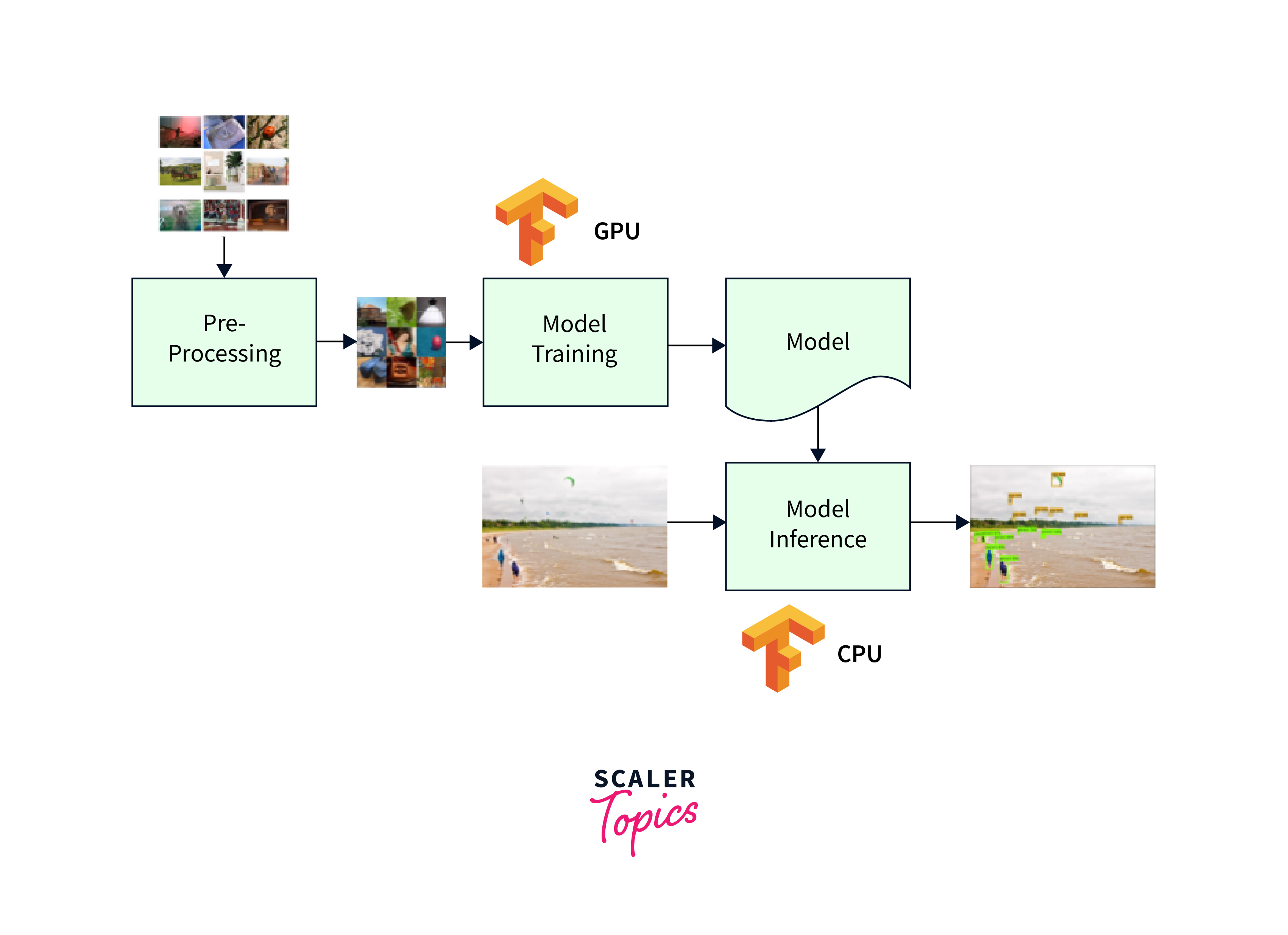
GPU-Accelerated Inference
GPU-accelerated inference refers to the use of Graphics Processing Units (GPUs) to expedite the prediction or inference process in deep learning models. After a deep learning model has been trained, it can be deployed to make predictions on new, unseen data.
GPU acceleration during inference leverages the parallel processing capabilities of GPUs to perform computations and make predictions with high speed and efficiency.
-
Real-Time Predictions:
GPUs for deep learning offer significant speed advantages during the inference stage, making real-time predictions feasible. With GPU acceleration, deep learning models can quickly process input data and generate predictions with low latency, enabling applications such as real-time object detection, video analysis, and natural language processing.
Example: Running an object detection model on a GPU allows for real-time identification and tracking of objects in a video stream, making it suitable for applications like autonomous vehicles or surveillance systems.
-
Improved Scalability:
GPUs enable efficient parallel processing, making it easier to scale inference tasks. With GPU acceleration, deep learning models can handle larger batch sizes and process multiple input samples simultaneously, resulting in improved throughput and scalability. This is especially beneficial in production environments where high throughput is essential.
Example: Deploying a language translation model with GPU acceleration allows for efficient translation of multiple sentences in parallel, improving the overall inference speed and accommodating a higher number of translation requests.
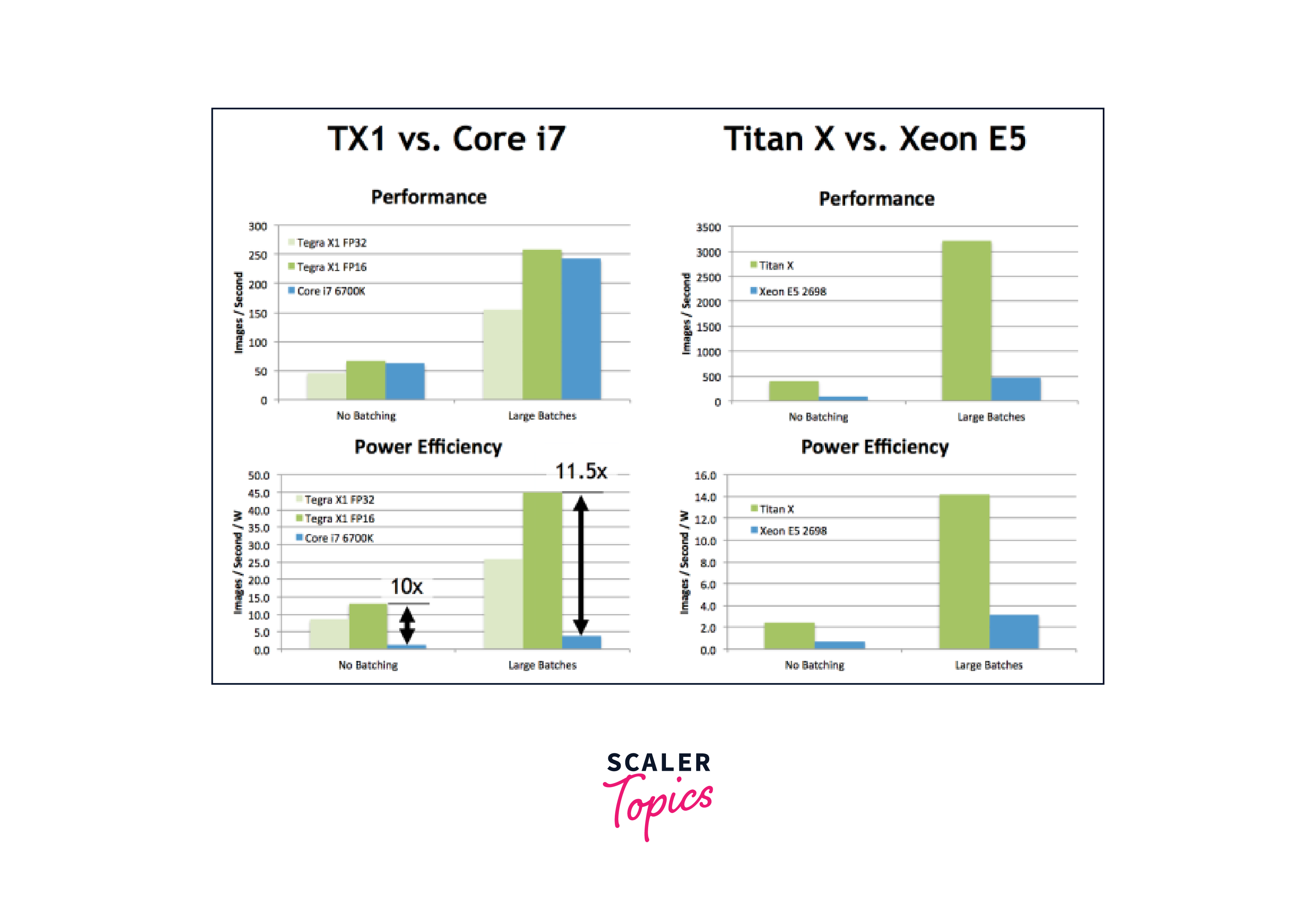
Performance Optimization Techniques
When it comes to optimizing deep learning performance, GPUs play a key role. GPUs are highly efficient in parallel processing, making them ideal for accelerating deep learning tasks. To maximize GPU utilization, batch processing is crucial.
By processing data in batches, rather than individually, you can reduce the overhead of data transfer between the CPU and GPU, resulting in faster training and inference.
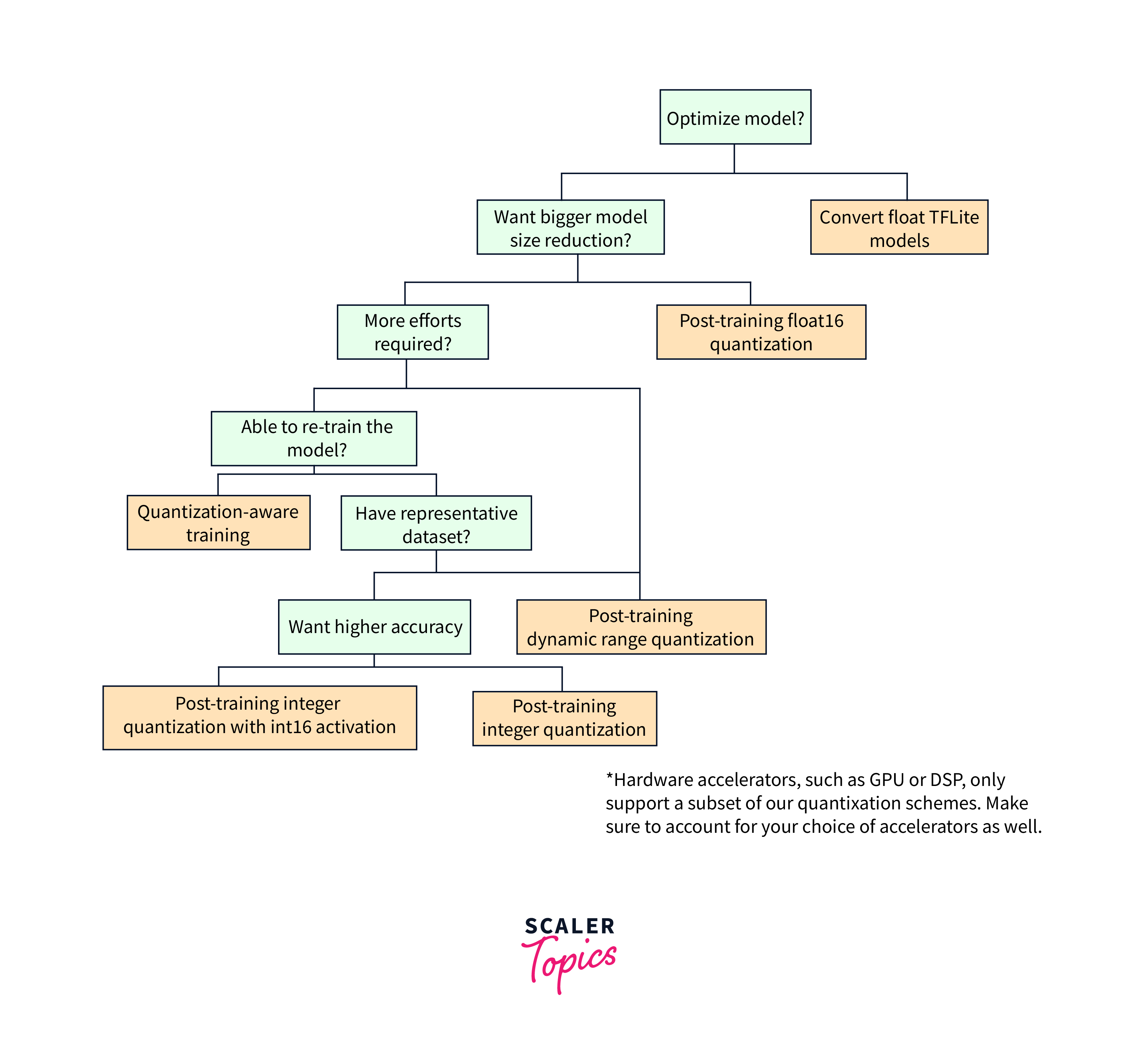
-
Another technique to leverage GPUs for deep learning is mixed precision training. By using lower-precision data types, like float16, you can significantly reduce memory usage and increase computational throughput. Automatic Mixed Precision (AMP) libraries, such as TensorFlow's AMP, simplify the implementation of mixed precision training.
-
Model architecture optimization is another important aspect. Techniques like model pruning and using more efficient architectures, such as MobileNet or EfficientNet, can speed up training and inference. Additionally, optimizing training algorithms, like tuning learning rates and batch sizes, can further enhance performance.
-
To fully utilize GPUs, it's important to consider hardware considerations. This includes ensuring proper GPU drivers, CUDA toolkit, and cuDNN library installation. Monitoring tools like TensorBoard Profiler or NVIDIA's Nsight can help identify performance bottlenecks and guide optimizations.
-
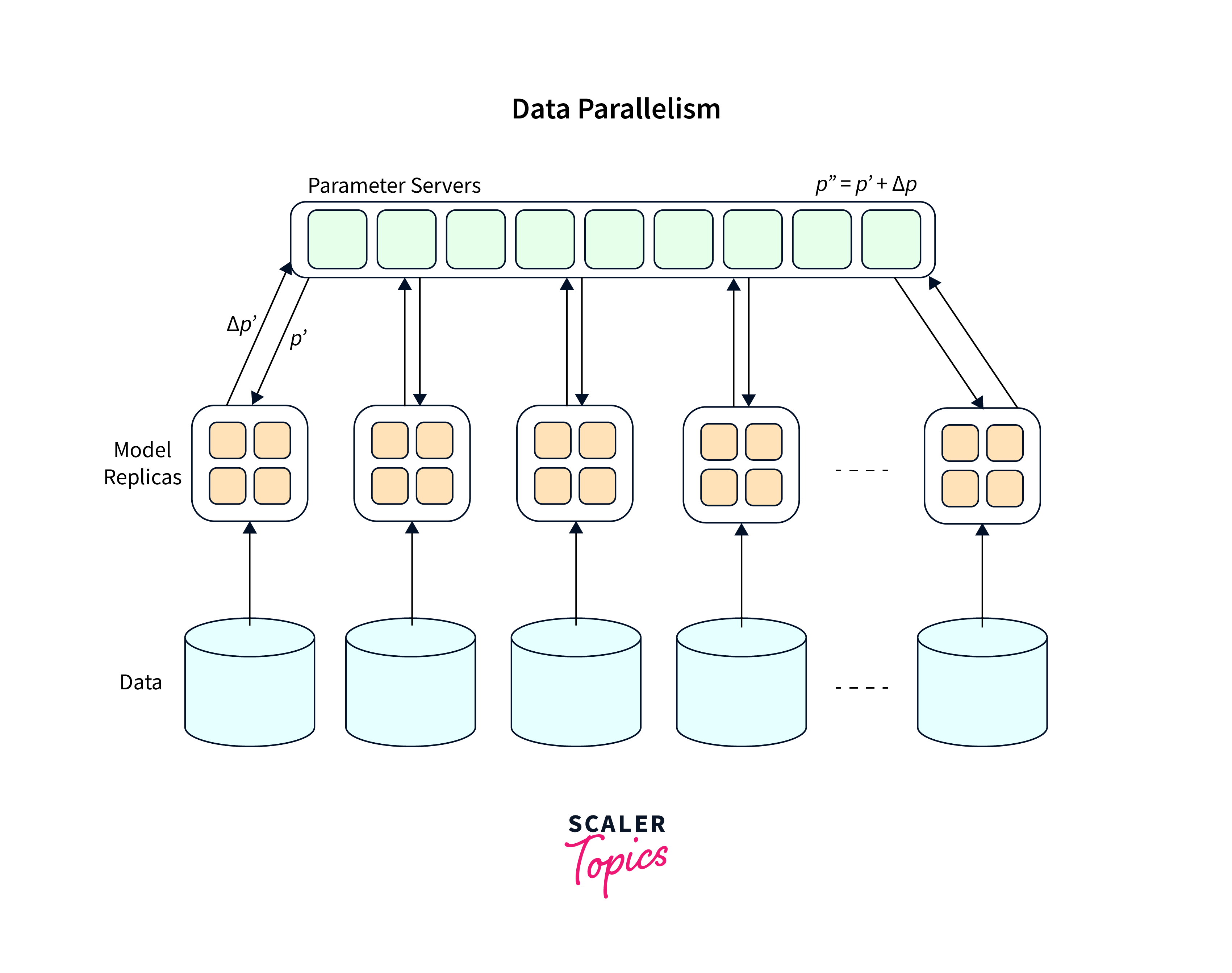
Distributed training and parallelism techniques, such as data parallelism and model parallelism, can distribute the workload across multiple GPUs or machines for faster training. Additionally, quantization and pruning techniques reduce memory usage and improve computational efficiency.
Optimizing Model Performance with GPU Acceleration
TensorFlow is a popular deep learning framework that supports GPU acceleration to speed up model training and inference. Here are some tools and techniques you can use to optimize GPU performance in TensorFlow:
-
Utilize TensorFlow GPU Support:
TensorFlow provides GPU support by leveraging libraries like CUDA and cuDNN. Ensure that you have installed the appropriate GPU drivers, CUDA toolkit, and cuDNN library to enable GPU acceleration in TensorFlow.
-
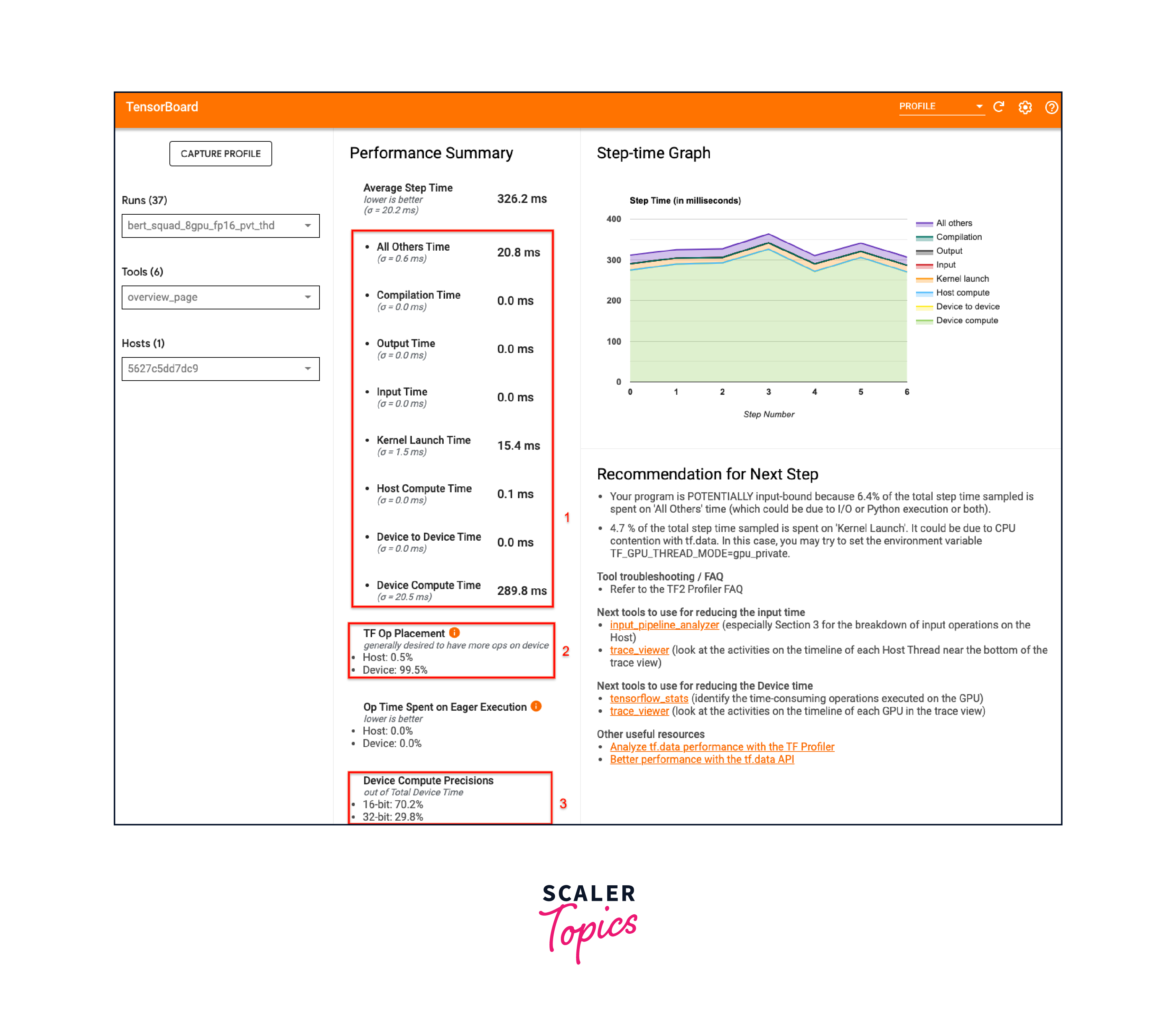
Use TensorBoard Profiler:
TensorBoard Profiler is a built-in tool in TensorFlow that helps analyze the performance of your model. It provides detailed information on GPU memory usage, compute time, and data transfer between CPU and GPU. By analyzing these metrics, you can identify bottlenecks and optimize your model accordingly.
-
Batch Processing:
GPUs for deep learning support parallel processing, so it is beneficial to process data in batches rather than individually. Batch processing allows you to maximize GPU utilization and reduce the overhead of data transfer between CPU and GPU. TensorFlow provides APIs, such as tf.data.Dataset, that facilitate efficient batch processing.
-
Tensor Core Utilization:
If you have NVIDIA GPUs with Tensor Cores (e.g., NVIDIA Volta or later architectures), you can leverage mixed precision training to accelerate computations. Mixed precision training combines lower-precision (e.g., half-precision) operations for most computations while preserving accuracy. TensorFlow's Automatic Mixed Precision (AMP) and NVIDIA's Automatic Mixed Precision (NAMP) are libraries that simplify mixed precision training.
-
Memory Optimization:
GPU memory is often a limited resource, especially when working with large models or datasets. To optimize memory usage, consider reducing the batch size, using smaller data types (e.g., float16), or applying techniques like gradient checkpointing or model parallelism.
-
Parallelize Computations:
TensorFlow provides options for parallelizing computations across multiple GPUs or multiple machines. You can use tf.distribute.Strategy to distribute the workload and take advantage of multiple GPUs to accelerate training. Additionally, frameworks like Horovod enable distributed training on multiple machines.
-
Kernel Fusion and Autotuning:
TensorFlow's XLA (Accelerated Linear Algebra) compiler can optimize and fuse multiple operations into a single kernel, reducing memory access and improving GPU utilization. XLA can be enabled using the tf.function decorator or by using the tf.xla.experimental.jit API. Additionally, TensorFlow's autotuning capabilities can automatically select the best GPU kernel configurations for improved performance.
Train Models with Mixed Precision Technique
Training models with mixed precision is a technique that leverages lower-precision data types, such as float16 (half-precision), to accelerate computations during deep learning training. It combines the benefits of reduced memory usage and increased computational throughput while still maintaining model accuracy.
Here's an informative overview of training models with mixed precision:
Precision Levels in Deep Learning
Deep learning models typically use 32-bit floating-point numbers (float32) for computations, which provide high precision but require more memory and computational resources. However, not all computations require such high precision. Lower-precision data types, like float16, can be used for certain operations without significantly impacting model accuracy.
Benefits of Mixed Precision Training
Mixed precision training offers several advantages:
-
Memory Savings:
Using float16 reduces memory usage by half compared to float32. This allows larger models and batch sizes to fit into the GPU memory, enabling training of more complex models.
-
Computational Speedup:
Operations performed in float16 can be executed faster on modern GPUs for deep learning with specialized hardware, such as Tensor Cores. These hardware accelerators are optimized for half-precision computations, enabling increased computational throughput.
-
Reduced Communication Overhead:
When transferring data between CPU and GPU or between GPUs in a multi-GPU setup, lower-precision data types require less bandwidth, reducing the communication overhead and improving overall training speed.
-
Automatic Mixed Precision (AMP) Libraries:
TensorFlow and other deep learning frameworks provide libraries that automate mixed precision training.
- The most commonly used library is TensorFlow's Automatic Mixed Precision (AMP).
- AMP automatically casts variables and operations to the appropriate precision, combining float16 for most computations and float32 for critical operations that require higher precision.
- This library simplifies the process of implementing mixed precision training.
-
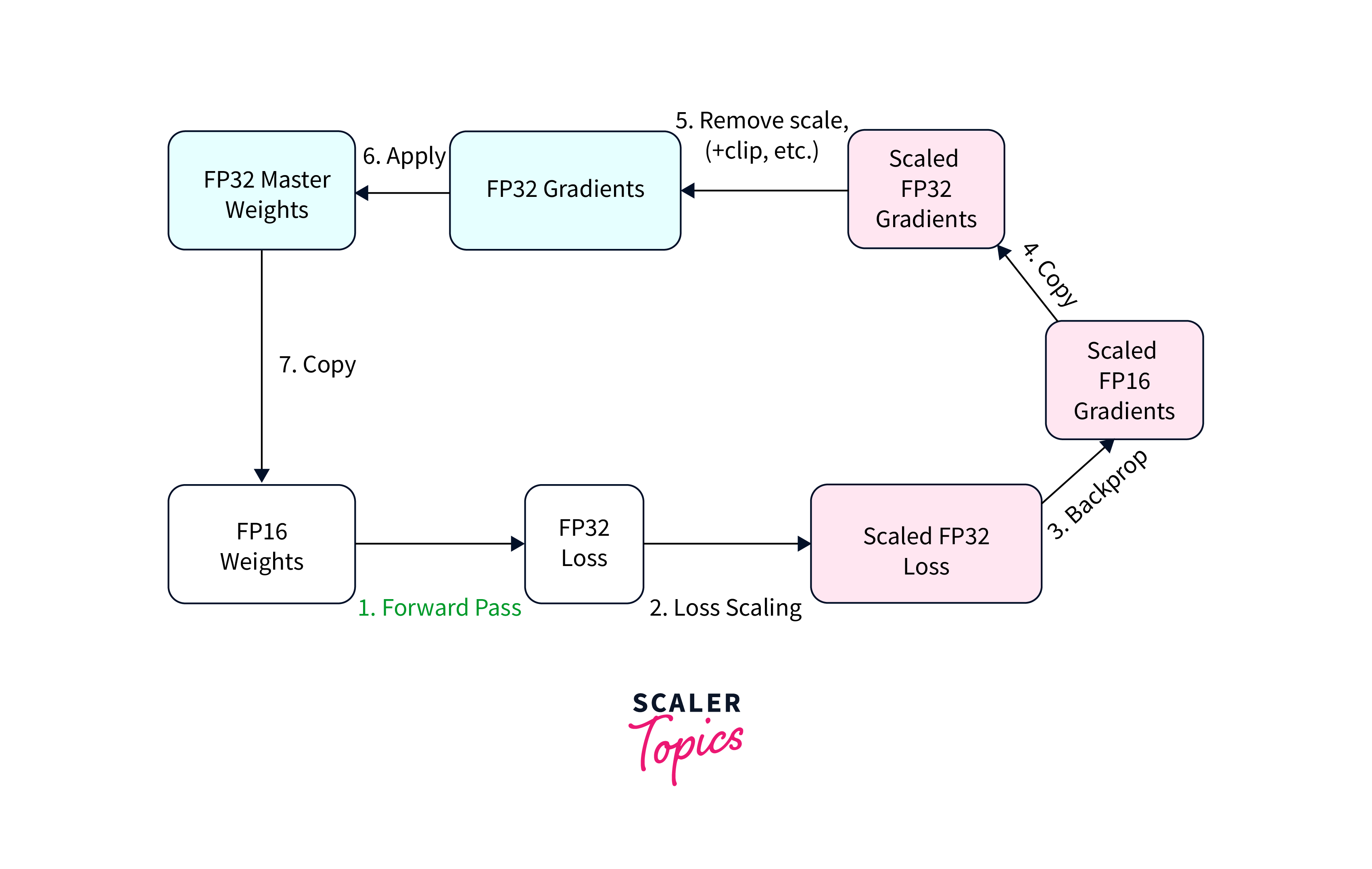
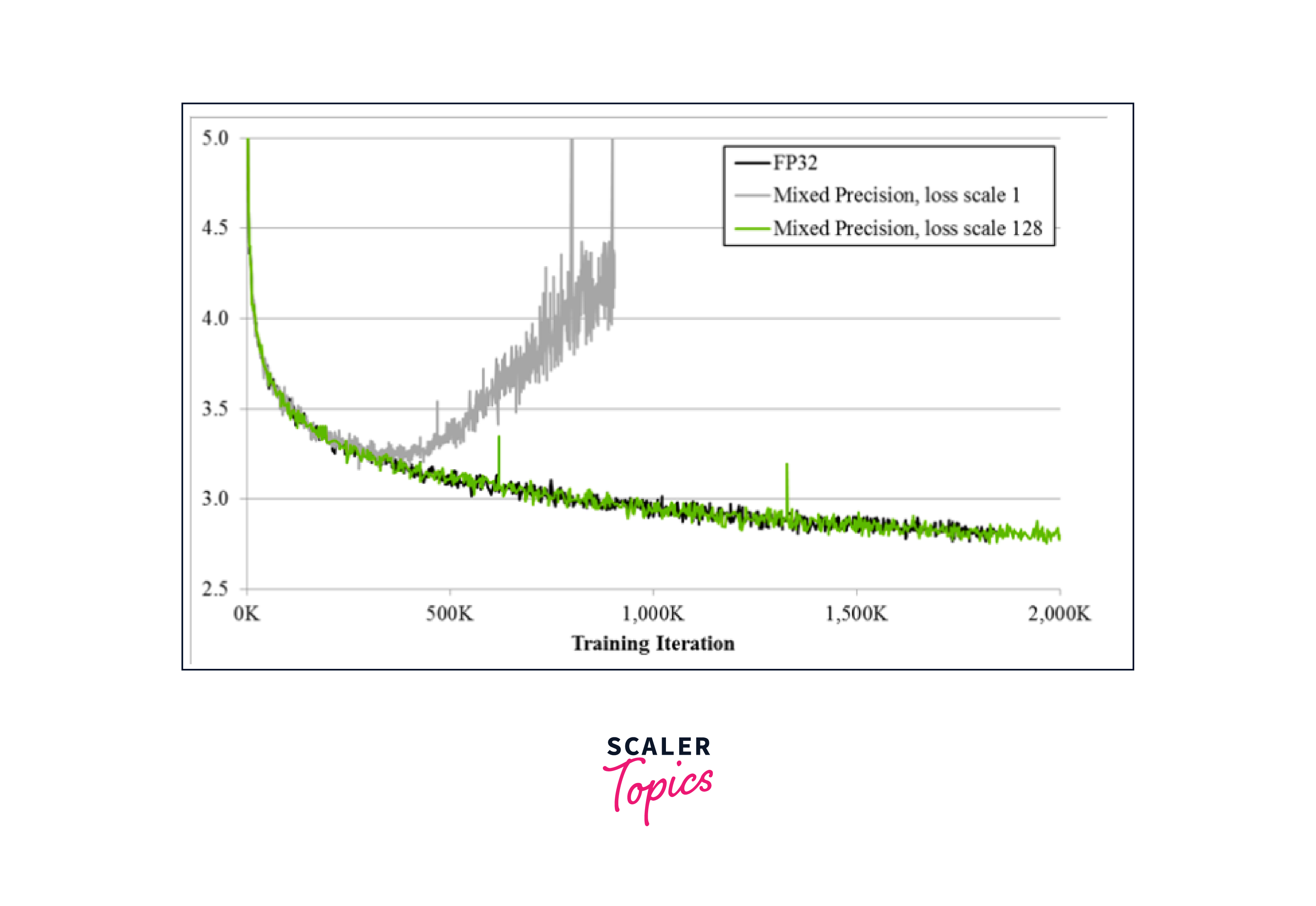
Loss Scaling:
Mixed precision training introduces the challenge of reduced dynamic range due to the lower precision of float16.
- To mitigate the impact of reduced precision on model convergence, loss scaling is applied.
- Loss scaling involves multiplying the loss value by a scaling factor before backpropagation and dividing the gradients by the same factor during gradient updates.
- This technique helps maintain numerical stability and prevents gradients from underflowing or overflowing.
-
Gradual Precision Scaling:
In some cases, models may encounter stability issues or loss of accuracy when training with mixed precision from the beginning. Gradual precision scaling is a technique where the model starts with higher precision (float32) and then gradually transitions to mixed precision by decreasing the precision of certain operations over time.
-
Evaluation in Full Precision:
While training in mixed precision, it is important to evaluate the model's performance and accuracy in full precision (float32).
- This ensures that the model's final performance is not compromised by the lower-precision computations.
- During evaluation or inference, the model's weights and activations are cast back to float32 for accurate predictions.
It is worth noting that not all models and tasks benefit equally from mixed precision training. It is recommended to experiment and validate the impact of mixed precision on your specific model and dataset.
Troubleshooting Common TensorFlow GPU Issues
When working with TensorFlow and GPU acceleration, you may encounter some common issues. Here are a few troubleshooting tips:
-
Verify GPU Compatibility:
Ensure that your GPU is compatible with the CUDA and cuDNN versions required by TensorFlow. Check the TensorFlow documentation for the recommended GPU hardware and software configurations.
-
Driver and Library Installation:
Make sure you have the latest GPU drivers installed. NVIDIA provides driver updates that include bug fixes and performance improvements. Similarly, ensure that you have the correct versions of CUDA and cuDNN installed.
-
Memory Allocation Errors:
TensorFlow uses GPU memory for computations and data storage. If you encounter "out of memory" errors, consider reducing the batch size, using smaller data types, or applying memory optimization techniques mentioned earlier.
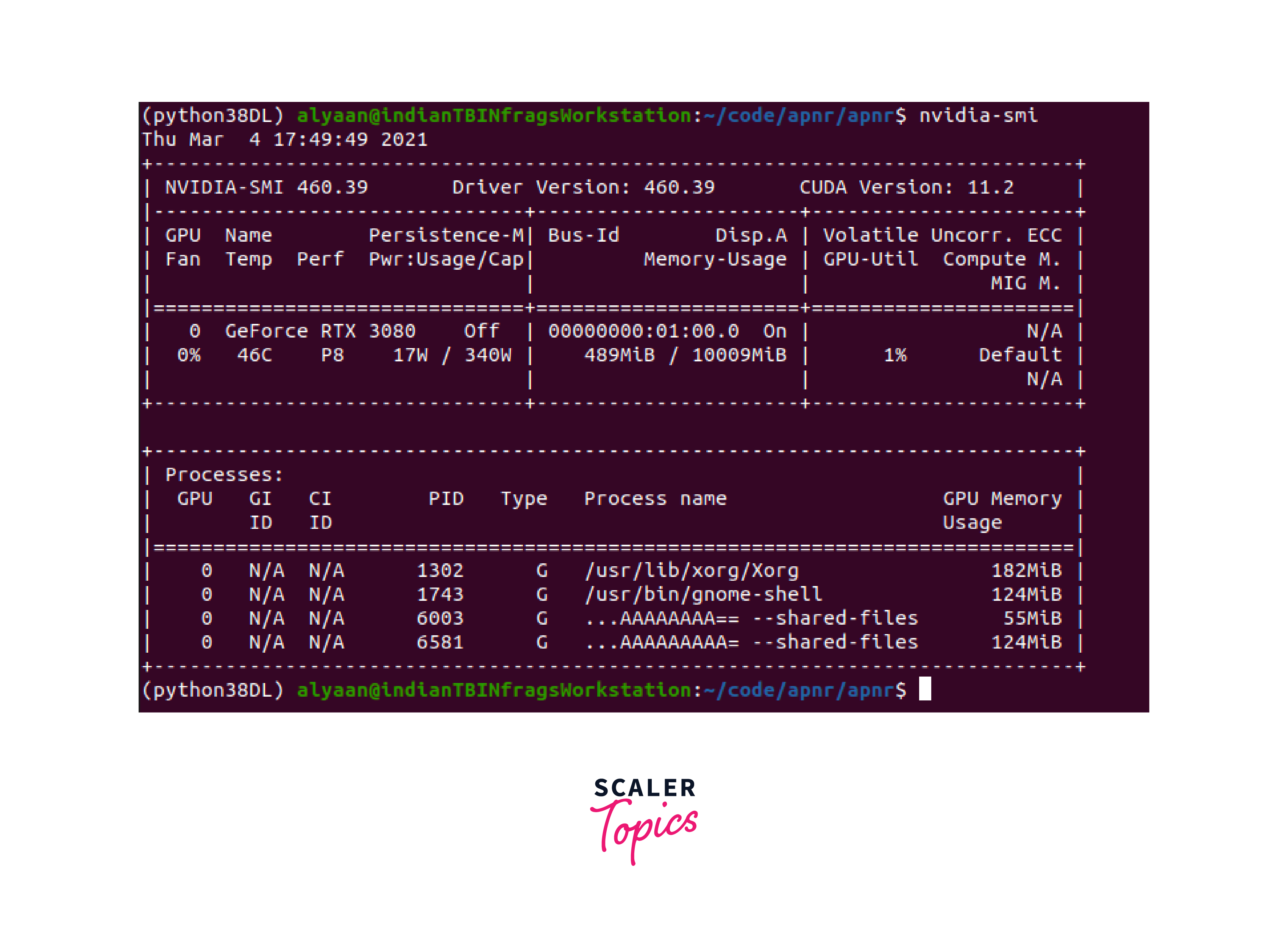
-
Version Compatibility:
Ensure that the versions of TensorFlow, CUDA, cuDNN, and other GPU-related libraries are compatible with each other. Incompatible versions may cause runtime errors or issues with GPU support.
-
Resource Conflicts:
Check if any other processes or applications are using a significant amount of GPU resources, which may impact TensorFlow's performance. Monitor GPU usage and terminate unnecessary processes to free up resources.
-
Hardware Issues:
In some cases, GPUs for deep learning performance issues can be caused by faulty hardware. Check for any signs of hardware failure or overheating. Ensure proper ventilation and cooling for your GPU.
Remember to consult the TensorFlow documentation, forums, and community resources for specific troubleshooting steps related to your GPU setup and TensorFlow version.
Profiling and Monitoring GPU Performance
Profiling and monitoring GPU performance is crucial for optimizing deep learning workflows. Here are some key techniques and tools for profiling and monitoring GPUs for deep learning performance:
-
TensorBoard Profiler:
TensorFlow's TensorBoard Profiler provides detailed insights into GPU memory usage, compute time, and data transfer between the CPU and GPU. It helps identify performance bottlenecks and optimize model training. Users can visualize and analyze these metrics to understand GPU utilization and identify areas for improvement.
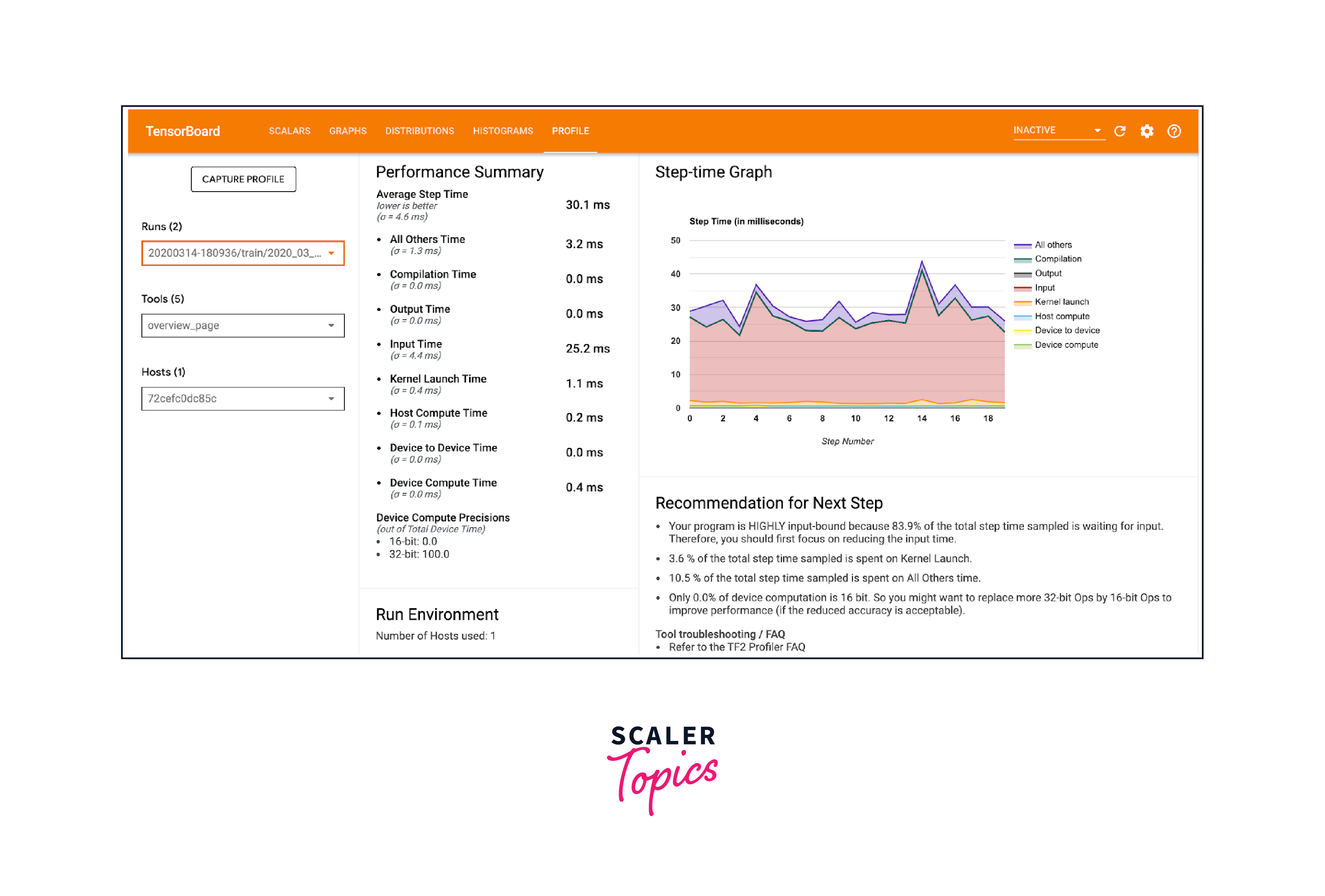
-
NVIDIA System Management Interface (nvidia-smi):
The nvidia-smi command-line tool allows users to monitor GPU utilization, memory usage, temperature, and power consumption. It provides real-time information about the GPU and helps diagnose performance issues or potential hardware limitations.
-
NVIDIA Nsight:
Nsight is a powerful profiling tool provided by NVIDIA. It offers in-depth analysis of GPU performance, memory usage, and CUDA kernel execution. Nsight allows users to capture and analyze GPU activity timelines, memory transfers, and performance counters to optimize deep learning workloads.
-
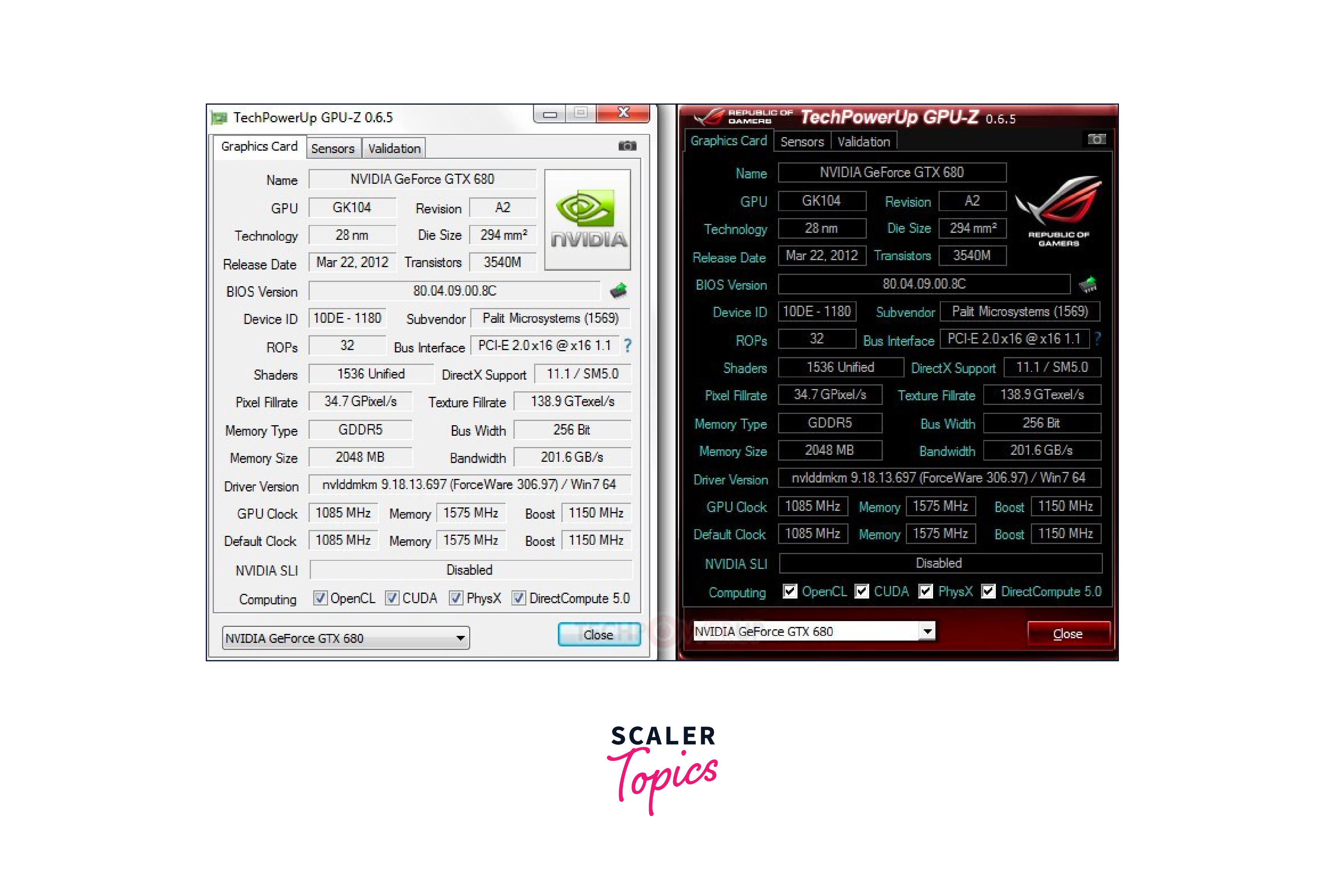
GPU-Z:
GPU-Z is a lightweight monitoring tool that provides real-time information about GPU performance and hardware specifications. It displays GPU temperature, clock speeds, memory usage, and power consumption. GPU-Z is useful for quick GPU performance checks and monitoring during deep learning tasks.
Real-World Applications of TensorFlow GPU in Deep Learning
TensorFlow's GPUs for deep learning support enables efficient deep learning across a range of real-world applications. Here are some examples:
-
Computer Vision:
Deep learning models for image classification, object detection, and segmentation heavily rely on GPUs. TensorFlow's GPU acceleration enables faster training and real-time inference for applications like autonomous driving, medical image analysis, and surveillance systems.
-
Natural Language Processing (NLP):
NLP tasks, such as text classification, sentiment analysis, and machine translation, benefit from TensorFlow's GPU capabilities. GPUs for deep learning accelerate the training of deep learning models like recurrent neural networks (RNNs), transformers, and language models, enabling faster and more accurate NLP applications.
-
Recommender Systems:
Deep learning-based recommender systems, which utilize techniques like collaborative filtering and deep neural networks, can leverage TensorFlow's GPU support for training large-scale models on massive datasets. This accelerates personalized recommendations in e-commerce, content streaming platforms, and online advertising.
-
Generative Models:
Generative models like generative adversarial networks (GANs) and variational autoencoders (VAEs) have revolutionized tasks such as image synthesis, text generation, and video generation. TensorFlow's GPU acceleration enables efficient training of these models, making them accessible for creative applications and content generation.
-
Reinforcement Learning:
Deep reinforcement learning, which combines deep neural networks with reinforcement learning algorithms, benefits from TensorFlow's GPU capabilities. GPUs accelerate the training of agents in complex environments, enabling breakthroughs in areas like robotics, game-playing, and control systems.
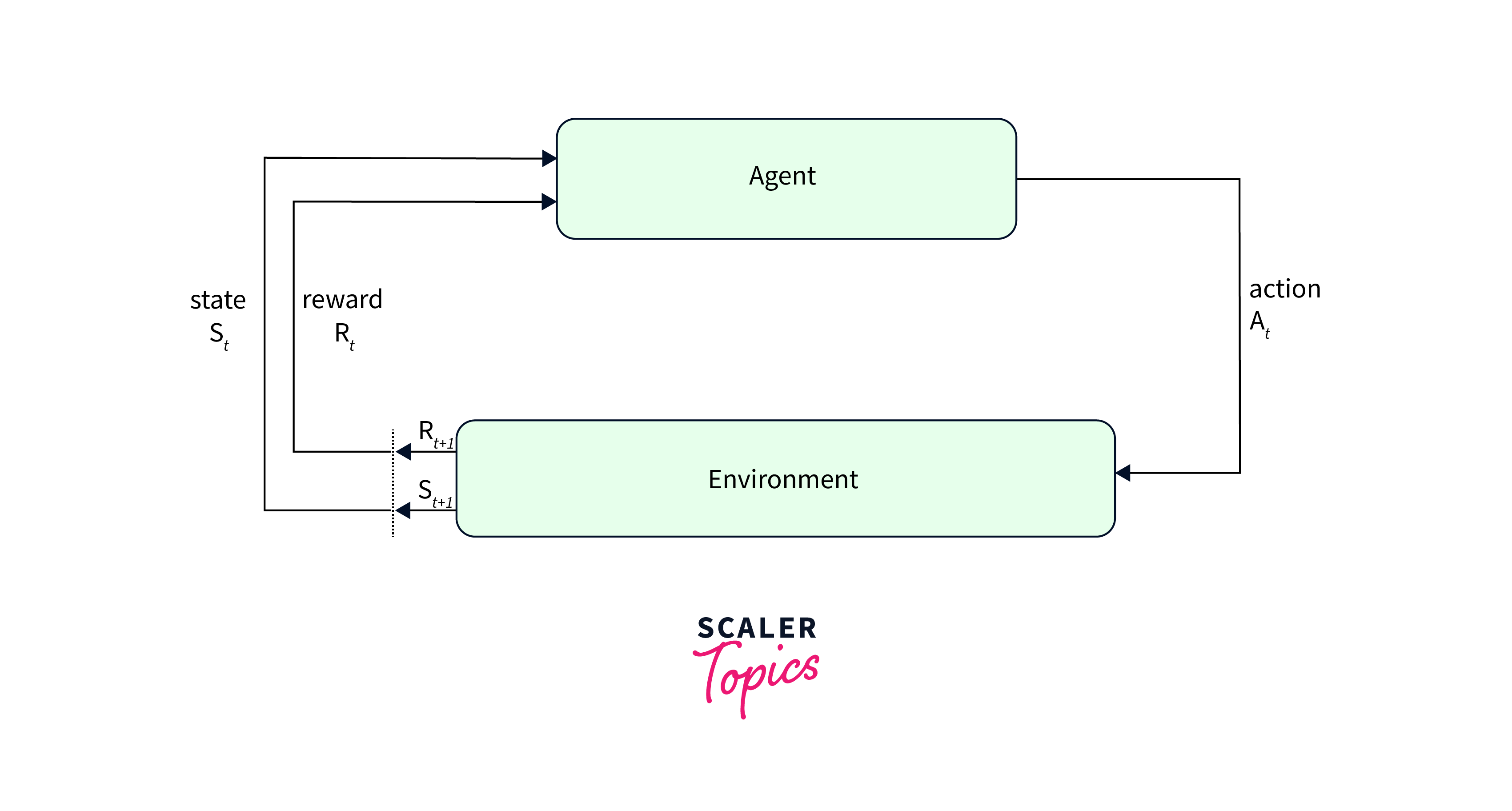
Conclusion
- GPU acceleration significantly reduces training times, enabling faster iterations and experimentation. It allows for the training of complex models and the processing of large datasets efficiently, enhancing productivity and time-to-insight.
- GPU acceleration empowers researchers and practitioners to push the boundaries of deep learning. It enables the exploration of more sophisticated architectures, the training of larger models, and the utilization of complex techniques, driving innovation and advancements in the field.
- GPUs for deep learning have become increasingly accessible and available, making GPU-accelerated deep learning more accessible to a wider audience.