Image Captioning with TensorFlow
Overview
Image captioning is a fascinating use of computer vision and natural language processing (NLP) that blends visual content analysis with the production of informative textual captions. It entails automatically producing textual descriptions that correctly reflect an image's content. Image captioning offers a wide range of practical applications, including assisting visually impaired people, improving image search capabilities, and adding context to social media sharing. This blog article takes an in-depth look at Image captioning using TensorFlow, a popular deep learning framework.
Introduction
Image captioning is a fascinating convergence of visual material and textual interpretation in the realms of computer vision and natural language processing (NLP). It is an intriguing programme that generates informative captions that precisely describe the content of an image. Image captioning not only improves visual information accessibility, but it also offers up new avenues for image search, content indexing, and narrative. In this blog article, we will take a look at Image captioning using TensorFlow, a prominent deep learning framework.
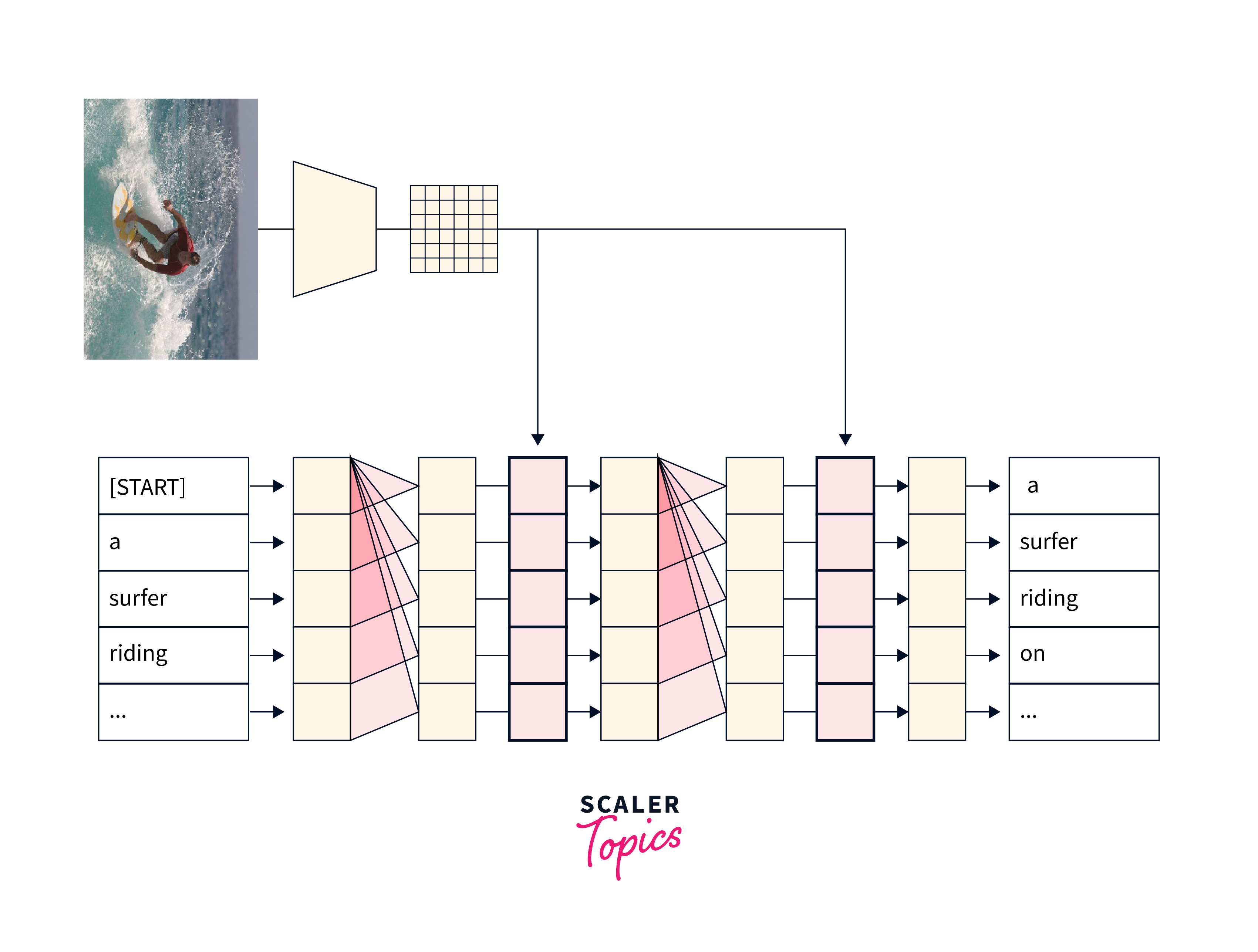
What is Image Captioning?
At the convergence of computer vision and natural language processing (NLP), image captioning is an interesting and novel application. It entails creating meaningful and contextually suitable captions for photographs automatically. The goal is for robots to be able to grasp and express Image material in human-like language.
Image captioning is significant because of its capacity to bridge the gap between visual and written comprehension. Unlike humans, robots have typically struggled with image interpretation and description. Image captioning allows robots to go beyond simple image recognition by providing meaningful textual descriptions that properly depict the visual information.

Data Preparation for Image Captioning
The preprocessing of data is critical in training good image captioning algorithms. The model's capacity to create accurate and relevant captions is directly affected by the dataset's quality and applicability.
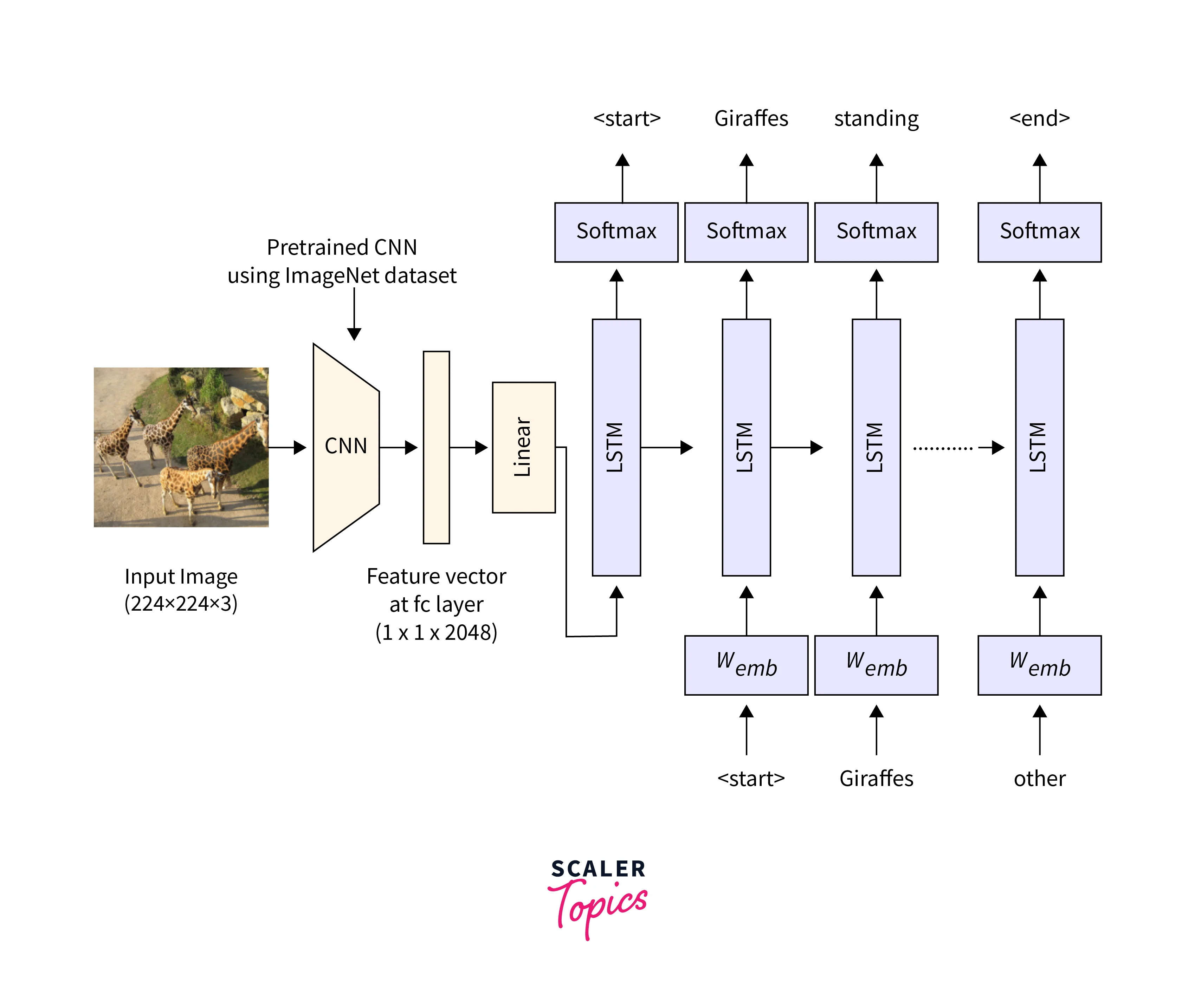
1. Image dataset:
The initial step is to get a good image dataset for training and assessment. MSCOCO (Microsoft Common Objects in Context) and Flickr30k are two popular datasets for Image captioning. These files contain a large number of photos, each with many human-annotated captions.
2. Image Preprocessing:
Image preprocessing is required to maintain consistency and compliance with the image captioning model. Some frequent preprocessing processes are as follows:
- Resizing:
Resize the photos to keep the aspect ratio while maintaining a constant resolution. - Normalisation:
To improve training convergence, normalise the pixel values to a common scale (e.g., [0, 1]). - Data Augmentation (optional):
Use manipulations such as rotation, flipping, or cropping to enhance the dataset's resilience and generalisation.
3. Preprocessing of Captions:
The textual captions linked with the images must also be preprocessed before they can be utilised for training. Caption preprocessing entails the following steps:
- Tokenization:
Tokenization is the process of separating each caption into distinct words or tokens. - Vocabulary creation:
Create a vocabulary by collecting unique tokens from all of the captions. Give each token a numerical index. - Padding:
To maintain constant input size throughout training, pad the captions to a predetermined length. This is usually accomplished by inserting special tokens such as start> and end> and filling the leftover spaces with padding tokens. - Image Text Pairing:
Pair each image with the relevant preprocessed caption(s). This produces the image-text pairings for training and assessment. Ascertain that the pairings are properly aligned and easily retrievable throughout model training. - Train-Test Split:
Split the image-text pairings into training and testing groups. The training set is used to train the image captioning model, while the testing set is used to evaluate it. A common split is to devote around 80% of the data to training and the remaining 20% to testing. - Data Loading:
Create a data loading pipeline in order to import and feed image caption pairs into the image captioning model during training. To optimise the loading process, consider applying data augmentation techniques, shuffling the data, and introducing parallel processing.
Build an Image Captioning Model
Image captioning is a tricky but exciting topic that combines computer vision and natural language processing (NLP). The objective is to build a model that can produce accurate and relevant captions for photos. In this segment, we will look at regulations involved in creating an image captioning model with TensorFlow.
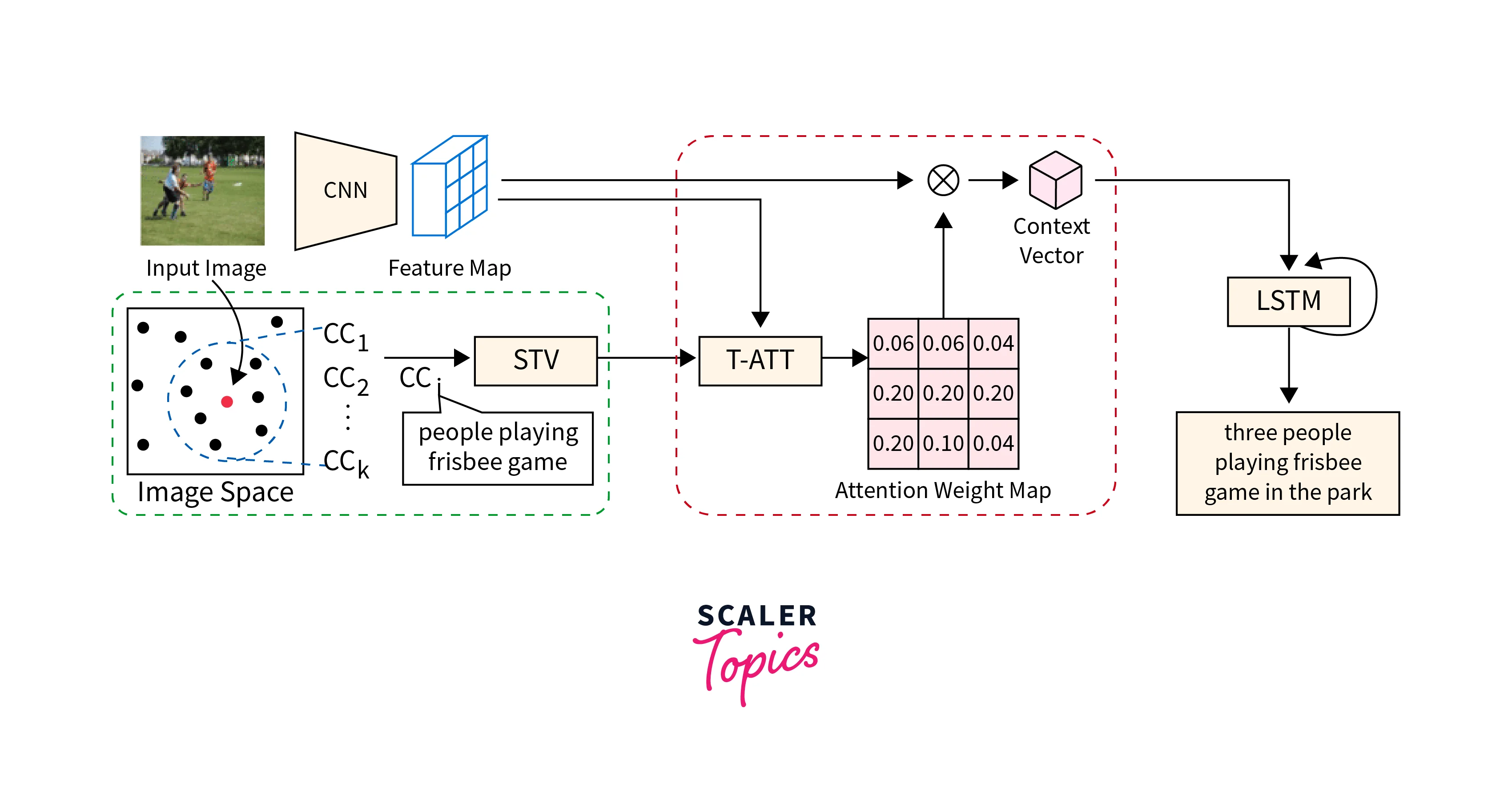
a. Train the Image Captioning Model:
Training the image captioning model entails combining the power of convolutional neural networks (CNNs) for image interpretation and recurrent neural networks (RNNs) for caption creation. The procedure may be broken down into the following steps:
-
Encoder for Images:
- As an image encoder, use a pre-trained CNN (e.g., VGG16, ResNet).
- To extract significant visual information from the input image, remove the classification layers from the CNN and keep the convolutional layers.
- The visual characteristics are obtained by passing the image through the encoder network.
-
Decoder of Text:
- To produce captions from visual characteristics, use an RNN-based text decoder (e.g., LSTM, GRU).
- To establish the link between the visual and textual contexts, initialise the RNN decoder with the encoder's last concealed state.
- Sequentially produce words by guessing the next word depending on the context and previously generated words.
-
Pipeline for Training:
- Define the loss function, such as cross-entropy loss, that will be used to compare the predicted captions to the ground truth captions.
- As inputs to the text decoder, use the encoder's visual attributes and the target captions.
- To minimise the loss, use backpropagation and gradient descent to update the model's parameters.
-
Tuning Hyperparameters:
- To improve the model's performance, experiment with hyperparameters such as learning rate, batch size, and the number of hidden units in the RNN decoder.
- To avoid overfitting, regularise the model using approaches such as dropout or L2 regularisation.
b. Create Image Captions:
Once the image captioning model has been trained, it may be used to create captions for new images. The following steps are included in the procedure:
-
Encoding of Images:
- To extract visual characteristics, run the new image through the pre-trained CNN encoder.
- Take the encoded visual elements and feed them into the text decoder.
-
Decoding Text:
- Use the encoded visual characteristics to train the RNN decoder.
- Using the preceding context and produced words, predict the next word in the caption.
- Continue creating words until you reach an end token or the maximum caption length.
-
Optional Beam Searching:
Use beam search to produce numerous potential captions and then use a scoring algorithm to determine the most likely caption.
Transfer Learning and Fine-Tuning
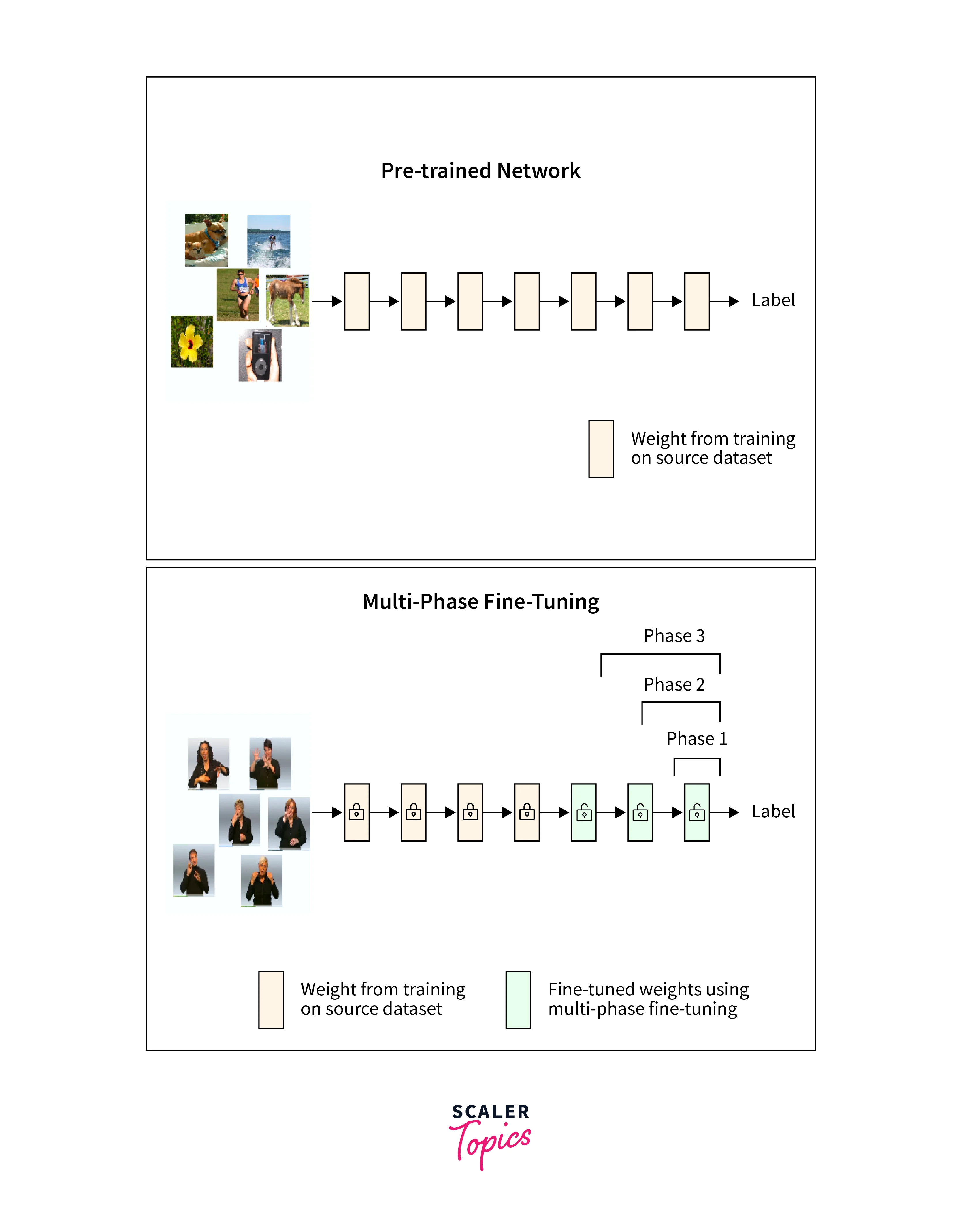
Transfer learning:
It is a popular computer vision approach that may dramatically increase the performance of image captioning models. It enables us to use the information gained from pre-trained models on large-scale image classification tasks to the area of image captioning. In this part, we will look into transfer learning and fine-tuning strategies for improving our image captioning model's capabilities.
1. Image Encoders that have been pre-trained:
- Rather than building the image encoder from scratch, we may use pre-trained image classification models such as VGG16, ResNet, or Inception that have been trained on big image datasets such as ImageNet.
- These pre-trained models have learned to recognize strong visual characteristics that collect high-level information about a variety of objects and ideas.
- We can profit from pre-trained image encoders' capacity to extract significant visual characteristics, which the text decoder may use to generate captions.
2. Image Encoder Fine-Tuning:
- We can fine-tune an image encoder once it has been pre-trained for the image captioning task.
- Fine-tuning entails utilising the captioning dataset to update the weights of the pre-trained encoder, allowing it to adapt to the unique visual patterns and semantics essential to caption creation.
- Fine-tuning learning rates are often adjusted to a lower value to ensure that previously learned characteristics are kept while new captioning-specific patterns are gradually included.
3. Trainable vs. Frozen Layers:
- We have the ability to choose which layers of the pre-trained image encoder to freeze and which layers to allow for training while fine-tuning.
- Freezing specific layers, often the early layers, prevents them from being modified during fine-tuning during training the later layers.
- When the pre-trained encoder has already learned general low-level characteristics and we want to preserve them, freezing layers is useful, but training the later layers helps the model to adapt to more specialized features necessary for the captioning task.
4. Scheduling Learning Rates:
- To manage the pace at which the model adapts during fine-tuning, use learning rate scheduling approaches such as decreasing the learning rate over time.
- Reduced learning rate as training advances aids the model's convergence towards optimal solutions while preventing catastrophic forgetting of previously learned features.
Our image captioning model may profit from pre-trained image encoders and use their learned visual characteristics thanks to transfer learning and fine-tuning. We may tailor the encoder to the unique requirements of producing captions by fine-tuning it on the captioning dataset.
Application Examples and Use Cases
Because of its numerous practical uses in a variety of sectors, image captioning has received a lot of attention. Let's look at some important use cases where Image captioning is critical:
1. Accessibility for Visually Impaired:
- Visually Impaired Access:
Image captioning technology tremendously assists visually impaired people by giving written explanations of images. These captions provide individuals access to visual material, which improves their understanding and enjoyment of digital media.
2. Image Search and Retrieval:
- Image Captioning Improves Image Search skills:
Image captioning improves image search skills by allowing users to discover specific photos based on textual searches. Search engines may index and retrieve photos more correctly by creating descriptions for images, resulting in more relevant results for users.
3. Content Organization and Indexing:
Image captioning assists with content organization and indexing by automatically creating informative and relevant captions. This enables effective image cataloging and retrieval in huge databases or content management systems.
4. Social Media Sharing:
Image Captioning allows users to post photographs with useful and interesting descriptions on social networking networks. By giving context and meaning to shared photos, it improves the narrative component of visual material and helps communication.
5. Assistive Technology for Autonomous Vehicles:
- Image Captioning can be utilised As An Assistive Technology In Autonomous cars:
Image captioning can be utilised as an assistive technology in autonomous cars. Visually challenged passengers can acquire a better grasp of their surroundings throughout the ride by creating real-time subtitles for the surrounding environment.
6. Content Generation and Creative Writing:
Image captioning models may be used to inspire creative writers, content providers, and marketers. These algorithms can help generate compelling and contextually appropriate text that complements visual material by creating captions for photos.
7. Automatic Image Annotation and Description:
Image Captioning can be used for automatic image annotation and description in a variety of applications, including image recognition systems, image databases, and multimedia content analysis. Automatically produced captions can give useful metadata and insights into image content.
8. Education and E-Learning:
Image captioning models can improve educational materials and e-learning platforms by creating captions that offer context and explanations to images used in instructional content. This enhances accessibility and comprehension for students.
Conclusion
- Image captioning is a sophisticated tool that generates informative captions for photographs by combining computer vision and natural language processing.
- Image captioning models can bridge the gap between visual and textual knowledge by utilizing convolutional neural networks (CNNs) for image interpretation and recurrent neural networks (RNNs) for caption production.
- Data preparation, which includes image and caption preprocessing, is essential for training effective image captioning models.
- Image captioning models provide a viable approach for creating accurate and relevant captions, as well as significant insights into image visual content.
- Continuous Image captioning research and development will improve the accuracy, fluency, and contextuality of produced captions.
- Image captioning will play an increasingly important role in improving accessibility, searchability, and understanding in the visual world as the discipline advances.