Image Segmentation
Overview
TensorFlow is a top deep learning framework for image segmentation, a vital computer vision task. It enables building sophisticated segmentation models like semantic, instance, and panoptic segmentation with ease. Its extensive tools and APIs simplify implementation, empowering researchers and engineers in diverse domains, from medical imaging to autonomous systems. TensorFlow's efficiency and versatility make it a go-to choice for image segmentation, driving progress and innovation in computer vision.
What is Image Segmentation?
Image segmentation is the task of partitioning an image into meaningful regions based on distinct attributes like color, texture, or shape. By breaking down an image into coherent segments, it enables precise analysis and understanding. This technique finds wide applications in computer vision, including object detection, image editing, and medical image analysis. Through image segmentation, complex images can be simplified and processed to extract valuable information, empowering various industries with enhanced visual understanding and efficient data interpretation.
Types of Image Segmentation
There are several types of image segmentation techniques, including:
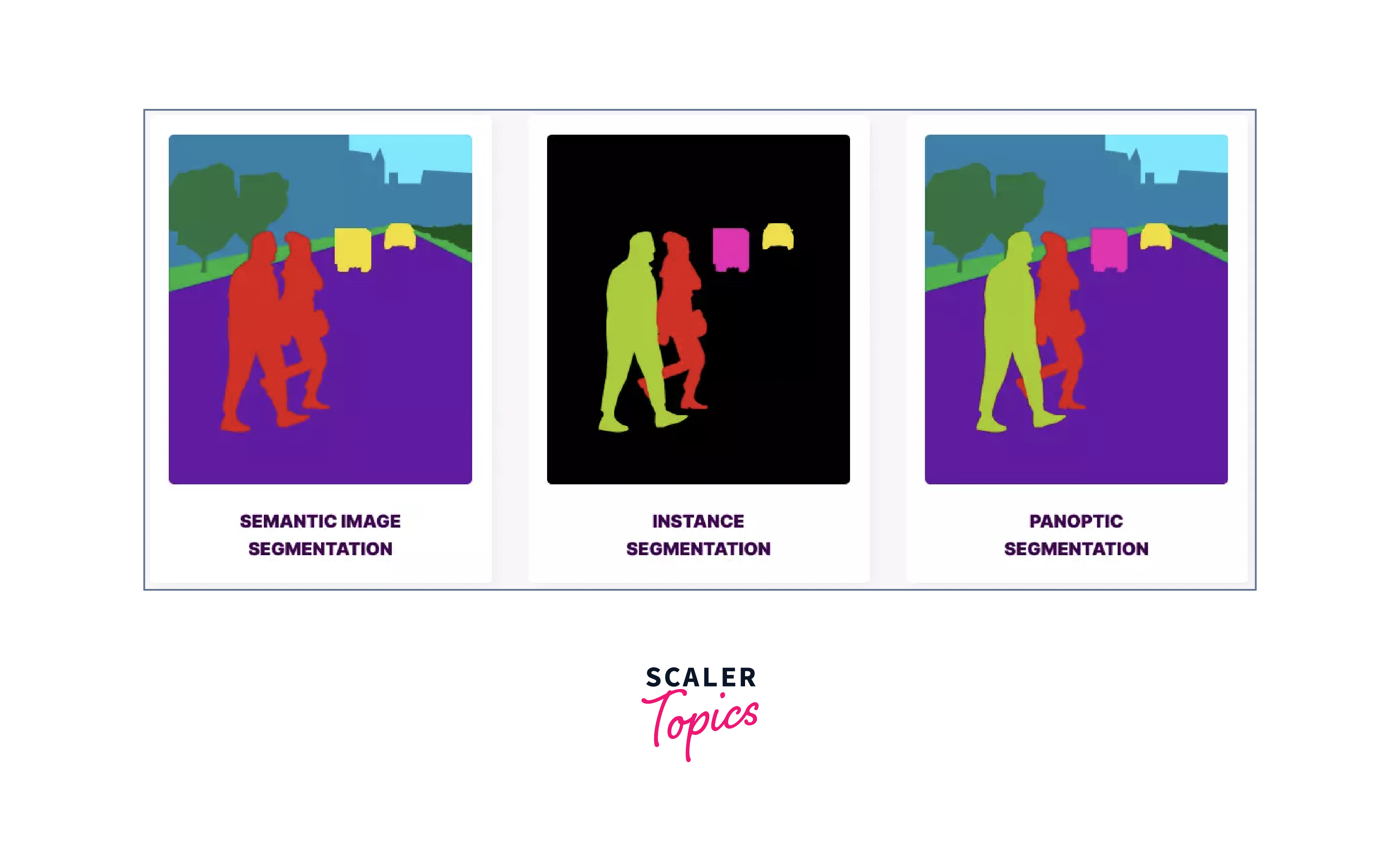
Semantic Segmentation:
- Semantic segmentation classifies each pixel in an image into predefined categories or classes.
- It enables pixel-level classification, providing a detailed understanding of different regions in the image.
- Widely used in tasks like scene understanding, object recognition, and image segmentation for self-driving cars.
Instance Segmentation:
- Instance segmentation not only identifies object classes but also distinguishes individual instances of the same class.
- It assigns a unique label to each object instance, making it ideal for scenarios with multiple objects of the same type.
- Valuable in applications like object counting, tracking, and robotics where individual object instances need differentiation.
Panoptic Segmentation:
- Panoptic segmentation combines semantic and instance segmentation to offer a holistic understanding of an image.
- It labels both thing(object instances) and stuff(background elements) in a unified manner.
- This technique provides a complete visual understanding, bridging the gap between object-level and scene-level analysis.
Dataset Preparation
Dataset preparation is a crucial step in creating an accurate image segmentation model. It involves collecting diverse images representing the target domain and annotating them with pixel-level masks for ground truth segmentation. Data augmentation enhances model generalization by applying transformations like rotation, flipping, and scaling. Splitting the dataset into training, validation, and testing subsets ensures proper model evaluation.
Preprocessing involves resizing and normalizing images and masks for consistency. Efficient data loaders and techniques like class weighting address imbalanced datasets. A well-curated dataset significantly impacts the model's performance, making it essential for successful image segmentation.
Building an Image Segmentation Model
Here's a step-by-step guide on building an image segmentation model using the Oxford-IIIT Pet Dataset.
Imports
First, you need to import the required libraries and modules. Commonly used libraries for image segmentation tasks include TensorFlow, Keras (a high-level API for TensorFlow), and relevant image processing libraries.
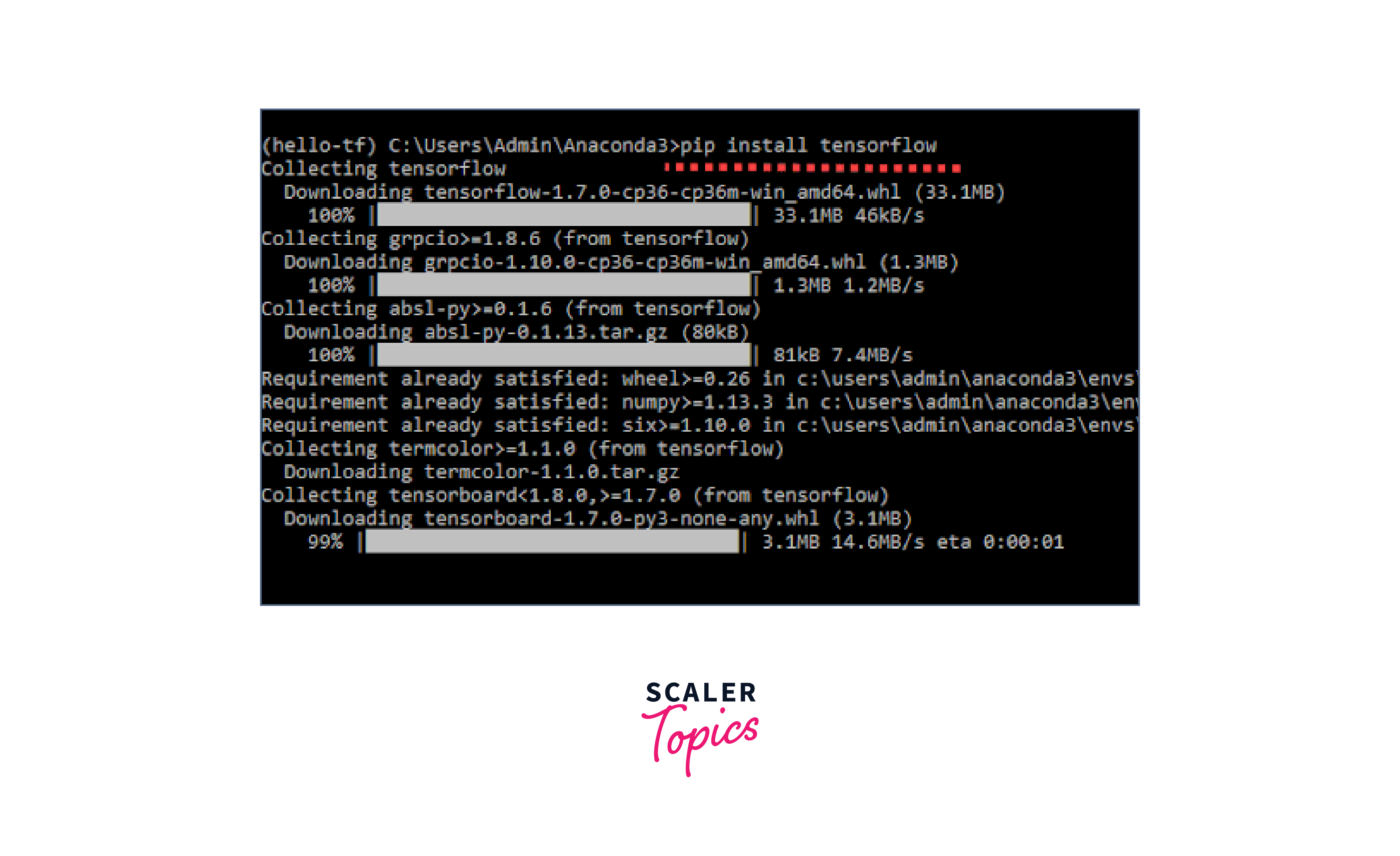
Setting Up TensorFlow
Ensure you have TensorFlow installed and set up correctly. You can install it using pip:
Data Preparation
Prepare your dataset for image segmentation. This includes loading the images and corresponding masks, preprocessing the data, and splitting it into training and validation sets.

Training an Image Segmentation Model
Choose and build your image segmentation model architecture. Commonly used architectures include U-Net, SegNet, and DeepLab. Define the loss function and optimizer for training.
The U-Net model architecture consists of an encoder, a decoder, and skip connections between them. We will create building blocks to construct the U-Net. The encoder extracts features through downsampling, while the decoder recovers spatial information through upsampling. The skip connections help preserve and combine low-level and high-level features for accurate segmentation. This U-Net design enables effective semantic segmentation for various tasks, including medical image analysis. The following are the building blocks of the U-Net model architecture
Custom Convolution Block:
-
Purpose:
The custom convolution block is the basic building block for the U-Net architecture. It consists of two consecutive convolution layers with ReLU activation. -
Need:
These convolutional layers help in capturing and learning meaningful features from the input data. ReLU activation introduces non-linearity, enabling the network to model complex relationships in the data. These blocks allow the U-Net to extract hierarchical features at different scales.
Custom Downsample Block:
-
Purpose:
The downsample block is used in the encoder part (contracting path) of the U-Net. It downsamples the spatial dimensions while increasing the number of channels (features). -
Need:
Downsampling helps reduce the spatial resolution, which reduces the computational burden and memory requirements while retaining important features. The increased number of channels allows the network to capture more abstract and higher-level features from the data.
Custom Upsample Block:
-
Purpose:
The upsample block is used in the decoder part (expanding path) of the U-Net. It upsamples the spatial dimensions while reducing the number of channels. -
Need:
Upsampling is essential to restore the spatial resolution lost during downsampling. The concatenation of features from the corresponding downsample block ensures that the decoder has access to low-level and high-level information. The convolutions in this block help refine the features and make them suitable for generating high-quality segmentation masks.Train your image segmentation model using the prepared training data.
Output:
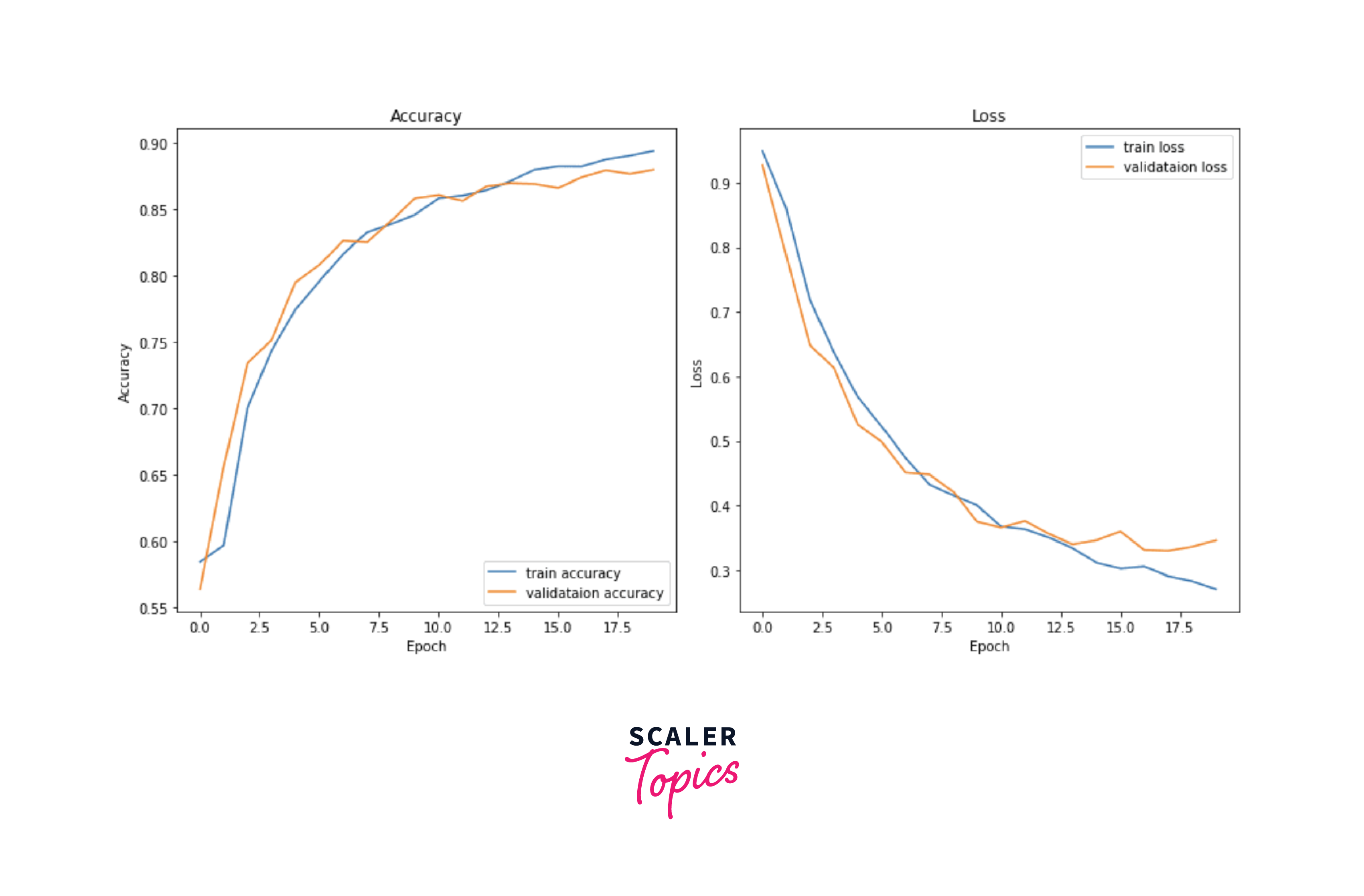
Evaluating and Fine-Tuning an Image Segmentation Model
Evaluate your model's performance on the validation set and make necessary adjustments to improve its performance.
Output:

Remember that the specific implementation details of each step may vary based on your dataset, image segmentation model, and requirements. Always adapt the code to your specific use case. Additionally, consider using data augmentation techniques and monitoring training progress to further improve your model's performance.
Application Examples and Use Cases
- Medical Image Segmentation:
TensorFlow can be employed to segment medical images such as MRI or CT scans to identify and isolate specific organs, tumors, or abnormalities. For instance, in brain MRI scans, segmenting different brain structures like the cortex, ventricles, or tumors can aid in diagnosis and treatment planning. - Autonomous Vehicles:
Self-driving cars need to perceive and interpret their surroundings accurately. Image segmentation can help in identifying and distinguishing objects like pedestrians, other vehicles, road lanes, traffic signs, and obstacles. TensorFlow-based segmentation models can contribute to safer and more efficient autonomous navigation. - Semantic Segmentation in Satellite Imagery:
Satellite images can cover large areas, making manual analysis challenging. By using TensorFlow for semantic segmentation, we can classify various land cover types like forests, water bodies, urban areas, and agricultural land, which is valuable for environmental monitoring, urban planning, and disaster response. - Object Detection and Instance Segmentation:
TensorFlow can be employed for object detection and instance segmentation tasks, where the goal is to not only identify objects in an image but also draw a precise boundary (mask) around each instance of the object. This is useful in applications like robotics, surveillance, and counting objects in crowded scenes. - Industrial Quality Control and Defect Detection:
In manufacturing settings, image segmentation can be applied to detect defects in products or identify faulty parts. By training TensorFlow models to segment out anomalies, manufacturers can improve quality control processes and ensure only high-quality products reach consumers.
Conclusion
- TensorFlow enables accurate and precise object segmentation in images.
- It is versatile and can be applied to various industries like medical imaging, autonomous vehicles, satellite imagery, and quality control.
- The rich ecosystem and community support offer a wide range of pre-trained models and tools for segmentation tasks.
- TensorFlow's efficient training and inference with hardware accelerators allow real-time segmentation in practical applications.
- Image segmentation using TensorFlow drives innovation in computer vision, leading to more advanced applications and techniques.