Model Parallelism
Overview
Model parallelism is a technique used in deep learning to divide a large neural network model across multiple devices or machines. This approach allows for the efficient use of resources and enables the training of larger and more complex models that would not be possible with a single device. TensorFlow, a popular deep learning framework, provides built-in support for model parallelism, making it easier for researchers and developers to harness the power of distributed computing. In this blog post, we will explore the concept of model parallelism in TensorFlow and discuss its advantages and challenges.
What is Model Parallelism?
Model parallelism is a technique used in deep learning to distribute the computational workload of a large neural network model across multiple devices or machines. This allows for parallel processing and efficient resource utilization, enabling the training of larger and more complex models. In model parallelism, each device or machine is responsible for computing a portion of the model's operations. The input data is divided among the devices, and each device processes its assigned data independently. The outputs are then combined to obtain the final result.
This approach is particularly useful when training extremely large models that do not fit within the memory limits of a single device. By distributing the model across multiple devices, each device can handle a smaller portion of the model, reducing memory requirements and enabling training on a larger scale.
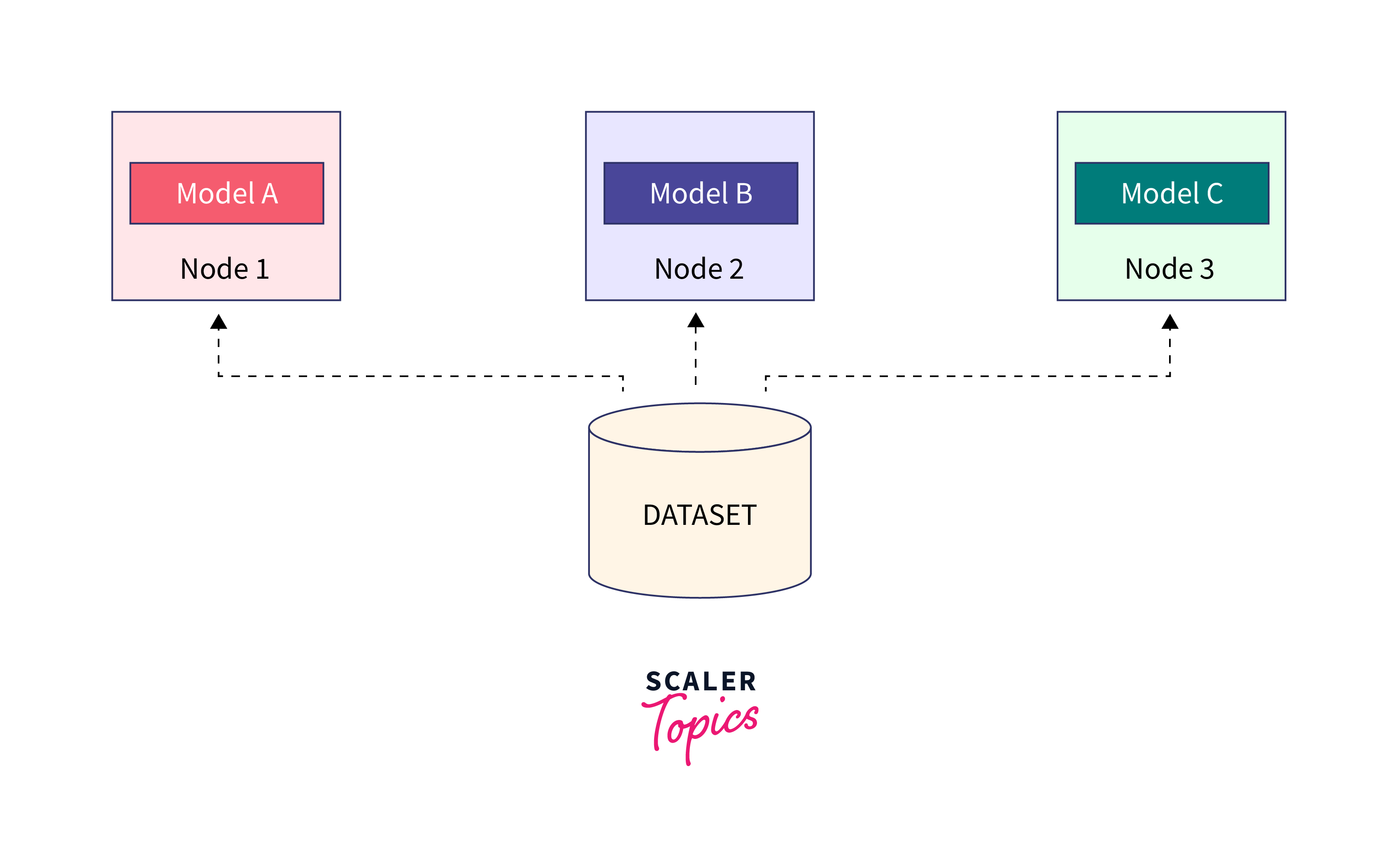
TensorFlow, as a popular deep learning framework, provides built-in support for model parallelism, making it easier for developers and researchers to leverage distributed computing resources effectively. It offers various tools and strategies to split and distribute the model across devices, ensuring efficient communication and synchronization between them.
In the next section, we will delve deeper into the different strategies and techniques used in model parallelism and explore how TensorFlow simplifies their implementation.
Advantages of Model Parallelism
Model parallelism offers several advantages that make it an essential technique in deep learning. By distributing the computational workload across multiple devices or machines, model parallelism enables the training of larger and more complex models that would otherwise be limited by the memory constraints of a single device.
One significant advantage of model parallelism is improved memory efficiency. By dividing the model into smaller portions and assigning them to different devices, each device only needs to store the parameters and intermediate results for its allocated portion. This reduces the memory requirements for each device, allowing for the training of models that would be otherwise impossible to fit in a single device's memory.
Furthermore, model parallelism also enhances parallel processing capabilities. By simultaneously computing different portions of the model on different devices, the overall training time can be significantly reduced. This leads to faster convergence and allows researchers and developers to experiment with larger models and more extensive datasets in a reasonable amount of time.
Another benefit of model parallelism is its ability to utilize distributed computing resources effectively, such as GPUs or clusters of machines. By leveraging multiple devices or machines, model parallelism can take full advantage of their computational power, enabling researchers to train models with higher accuracy and explore novel architectures
How Model Parallelism Works?
To understand how model parallelism works, let's take an example of a deep neural network with multiple layers. Instead of having all the layers on a single device, model parallelism divides the layers into smaller portions and assigns them to different devices or machines.
Each device is responsible for computing the operations related to its assigned portion of the model. This division of labor allows for parallel processing, as each device can independently execute its computations simultaneously. The intermediate results from each device are then exchanged and used by the subsequent layers to propagate the error gradients and update the model's parameters.
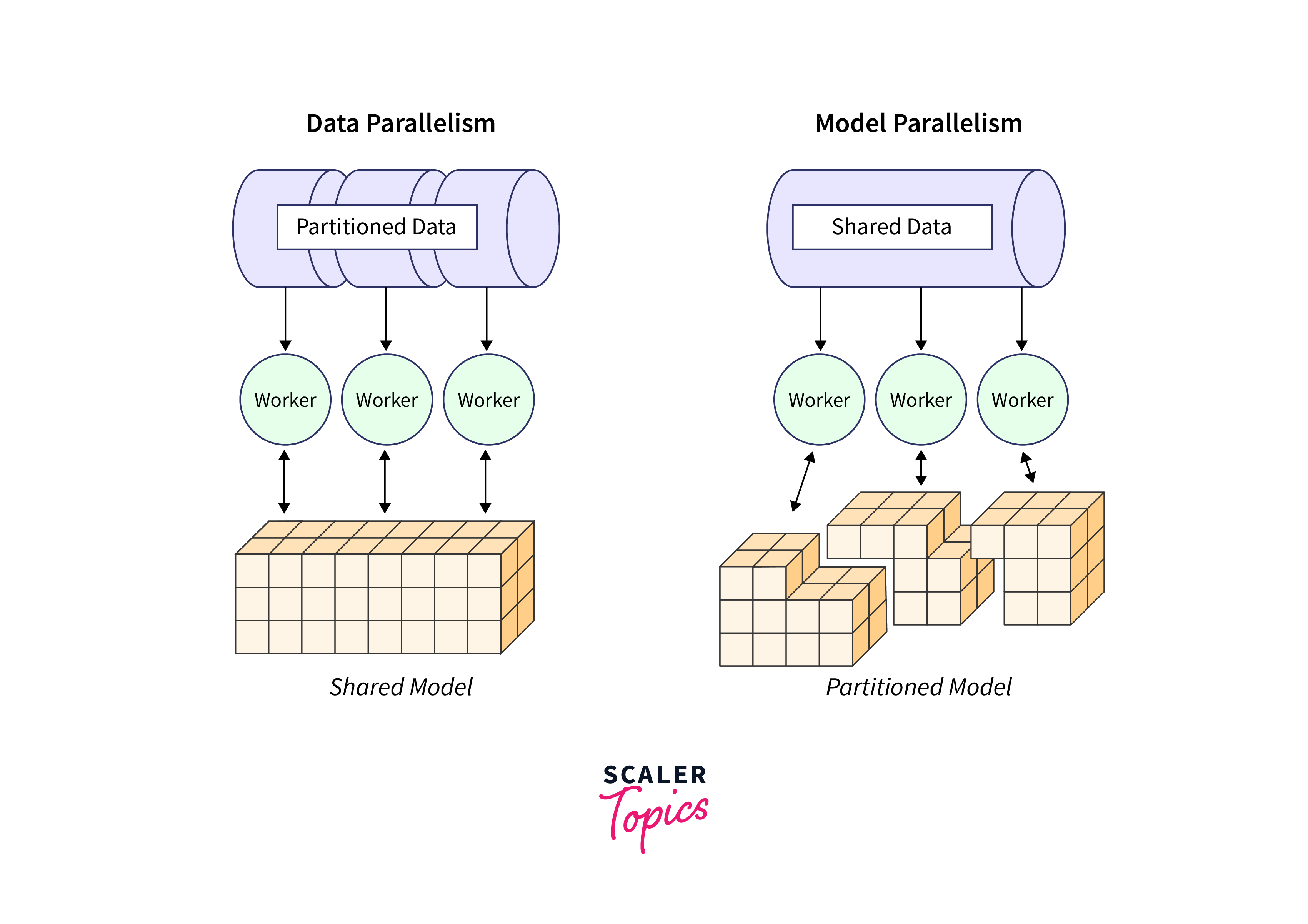
To implement model parallelism in TensorFlow, techniques such as model splitting, data sharding, and synchronization mechanisms like parameter updating need to be employed. We will explore these strategies and techniques in detail in the upcoming sections.
Stay tuned to uncover the intricacies of implementing model parallelism in TensorFlow and how it can significantly impact the training process and model performance.
Challenges and Considerations
While model parallelism can significantly improve the training process and model performance in TensorFlow, it also comes with its own set of challenges and considerations. Here are some key aspects to keep in mind:
Memory Constraints: One of the main challenges of model parallelism is dealing with the increased memory requirements. As the model is partitioned and distributed across multiple devices or machines, each device needs to have enough memory to store its assigned portion of the model and the intermediate results during computation. This can be especially challenging for larger and more complex models.
Communication Overhead: As the computation is distributed, there is a need for frequent communication between the devices or machines to exchange the intermediate results and update the model's parameters. This communication overhead can introduce latency and potentially slow down the training process. Optimizing the communication strategies and minimizing the data transfer can help mitigate this challenge.
Load Balancing: In model parallelism, it is crucial to distribute the computational workload evenly across the devices or machines to fully utilize the available resources. Load imbalances can lead to underutilization of some devices or machines and can affect the overall training performance. Effective load balancing strategies should be implemented to ensure efficient utilization of resources.
Synchronization: As the intermediate results are exchanged between the devices or machines, synchronization mechanisms need to be in place to ensure consistency and accuracy. This involves proper synchronization of parameter updates and handling race conditions. Implementing efficient synchronization techniques is essential for successful model parallelism.
Model Parallelism Techniques
Now that we have discussed the challenges and considerations of model parallelism in TensorFlow, let's explore the various techniques that can be used to overcome these obstacles and optimize the implementation of model parallelism.
-
Memory Optimization: To address the memory constraints in model parallelism, several strategies can be employed. One approach is to use memory-efficient data structures and algorithms, such as sparse tensors or quantization techniques, to reduce the memory footprint of the model. Another technique is to schedule the computation in a way that minimizes the memory usage at each device or machine. By carefully managing memory resources, the overall memory requirements can be effectively controlled.
-
Communication Optimization: Optimizing the communication overhead in model parallelism is crucial for efficient training. This can be achieved by using efficient data exchange mechanisms, such as pipelining or overlapping communication with computation. Additionally, techniques like compression or quantization can be employed to reduce the size of the data transferred between devices or machines, thereby reducing the communication overhead.
-
Load Balancing Strategies: To ensure effective load balancing, various techniques can be used. Dynamic load balancing algorithms can be implemented to dynamically distribute the computational workload based on the resources available at each device or machine. Additionally, model partitioning strategies can be adjusted to evenly distribute the computational complexity across the devices or machines, minimizing load imbalances.
-
Synchronization Techniques: Implementing efficient synchronization mechanisms is essential for maintaining consistency and accuracy in model parallelism. Techniques such as asynchronous updates or delayed gradients can be used to reduce the synchronization overhead. By carefully managing the synchronization process, race conditions can be avoided and the training performance can be improved.
Implementation of Model Parallelism in TensorFlow
Model parallelism is a crucial technique when dealing with large and complex deep learning models that may not fit within the memory constraints of a single device. In this guide, we'll walk you through the steps to implement model parallelism in TensorFlow, including code examples at each stage.
- Step 1. Setting Up the Environment
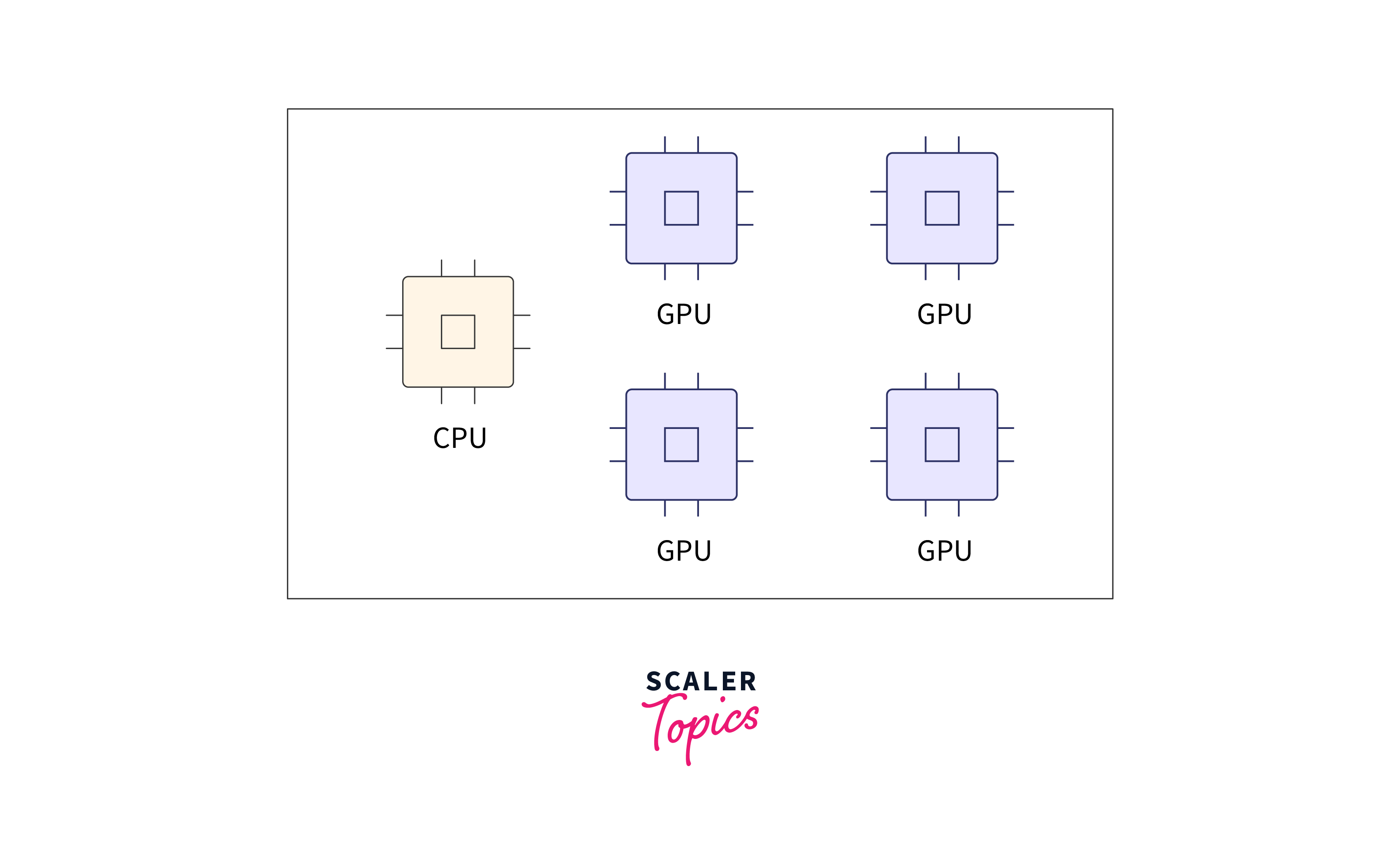
To implement model parallelism in TensorFlow, you'll need a suitable environment, including multiple GPUs. In this example, we assume you have two GPUs available, but you can adjust the code for your specific setup.
- Step 2. Generating Synthetic Data
In most real-world scenarios, you'll work with large datasets. To keep things simple for this demonstration, we'll generate synthetic data.
- Step 3. Defining Model Segments
In model parallelism, you split your neural network into segments. In this example, we create two segments using the Tensorflow Keras API.
- Step 4. Creating a Mirrored Strategy:
To enable parallelism across multiple GPUs, TensorFlow provides the MirroredStrategy. This strategy replicates your model on each GPU and manages communication during training.
- Step 5. Training Model Segments in Parallel
With the strategy in place, you can now train your model segments separately in parallel.
-
Splitting and Preparing the Dataset
To train your model segments, you need to split your dataset accordingly and convert it into TensorFlow datasets.
- Step 6. Training the Model Segments
Now, you can train both model segments in parallel.
- Step 7. Merging the Model Segments
After training the segments, it's time to merge or combine them to create the final model. This step depends on your specific use case and how you want to combine the outputs.
- Step 8. Evaluating the Final Model
With the final model ready, you can evaluate its performance on a test dataset.

Conclusion
Model parallelism is a powerful technique in deep learning that allows researchers and developers to train large and complex models by distributing the computational workload across multiple devices or machines.
-
Scalable Model Training: Model parallelism in TensorFlow breaks through memory limitations, allowing for the training of significantly larger and more complex neural network models.
-
Efficient Resource Utilization: TensorFlow's model parallelism efficiently harnesses distributed computing resources such as GPUs and clusters, maximizing their potential.
-
Key Advantages: 1)Memory Efficiency: Model parallelism reduces memory constraints, enabling the training of massive models. 2)Parallel Processing: It accelerates training by processing different parts of the model in parallel. 3)Resource Optimization: Model parallelism makes effective use of available hardware resources.
-
Recognizing Challenges:
- Memory Demands: Managing memory requirements across devices is a critical challenge.
- Communication Overhead: Effective data exchange between devices requires careful consideration.
- Load Balancing: Ensuring balanced workloads across devices is vital for efficiency.
- Synchronization: Proper synchronization mechanisms are necessary to maintain consistency in parallel processing.