TensorFlow Pruning
Overview
Deep learning has revolutionized various fields with its remarkable performance in tasks such as image recognition, natural language processing, and more. However, as deep learning models grow in complexity and size, they become computationally expensive and memory-intensive, making their deployment on resource-constrained devices challenging. TensorFlow pruning comes to the rescue as an effective optimization technique that reduces model size without compromising performance. In this blog we will explore the concept of TensorFlow pruning, its underlying techniques, pruning-aware training, TensorFlow pruning tools, deployment with TensorFlow Lite, trade-offs between model size and accuracy, evaluating quantized models, and the limitations and future developments of pruning.

What is Pruning?
Pruning is an optimization technique used in the context of deep learning and neural networks. It involves selectively removing certain components from a neural network that are considered less important or less influential for the model's performance. The goal of pruning is to reduce the size and complexity of the neural network, making it more computationally efficient, memory-friendly, and faster during inference.
In a neural network, parameters such as weights, connections, or neurons are responsible for capturing patterns and relationships in the input data. However, not all parameters contribute equally to the model's output or prediction accuracy. Some parameters may have little impact on the model's overall performance, and removing them can lead to a more compact and efficient model without significantly sacrificing accuracy.where pruning makes it posssible.
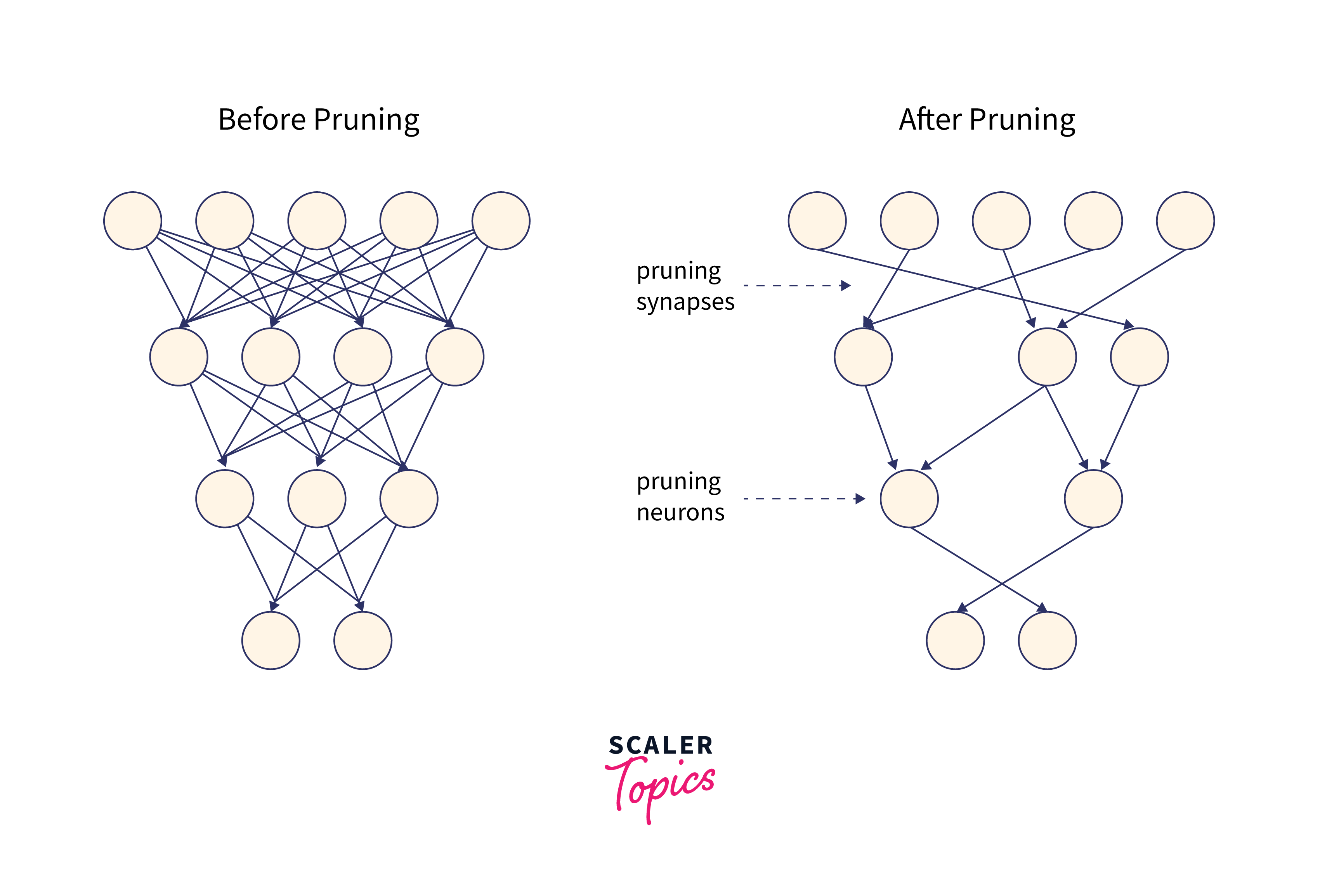
Pruning Techniques
Various pruning techniques are employed to effectively reduce model size:
1. Weight Pruning:
This technique involves removing individual weights with small magnitudes or those close to zero. These weights are deemed less important to the model's performance and can be safely pruned.
In above, We define the pruning schedule with a PolynomialDecay function, starting with 50% sparsity and gradually increasing to 90% between training steps 1000 and 3000. We then create the pruned model using prune_low_magnitude, which applies weight pruning to the original model based on the pruning schedule.
2. Filter Pruning:
Entire filters, comprising sets of neurons in a convolutional layer, are removed based on certain criteria. Filters with low activation values or minimal contributions to accuracy are pruned.
Above in the code the frequency is applied and by removing entire filters along with their kernels, Removing a filter means that the entire feature map produced by that filter will be discarded during inference. Filter pruning leads to a more structured sparsity pattern since entire filters are removed, resulting in more zero-valued weights.
3. Neuron Pruning:
Neuron pruning entails the removal of entire neurons in a dense (fully connected) layer. Neurons with little impact on the model's output are pruned.
- Step1:
In above code,In this code, we first create a simple fully connected neural network model with three layers: two hidden layers with 128 and 64 neurons, respectively, and an output layer with 10 neurons.we create a new pruned model, pruned_model, with the same architecture. - Step2:
To perform neuron pruning, we set the weights of the second layer (64 neurons) to zero. This effectively removes the neurons from the second layer and their corresponding connections to the subsequent layers. - Step3:
We then copy the trained weights from the original model to the pruned model to retain the trained weights of the remaining neurons. After setting the weights of the second layer to zero, we compile the pruned model and evaluate its accuracy on the test set.
Pruning can be performed during or after the training of the neural network. During training, pruning-aware techniques can be employed to adapt the model to the pruned structure and maintain performance. Alternatively, pruning can be applied post-training as a separate step.
Let us see about the post weigted pruning with a simple code
In the code above, we introduced two new functions, calculate_importance_scores and apply_weighted_pruning. The calculate_importance_scores function is used to compute the importance scores of weights (you can choose the method you want to use here). The apply_weighted_pruning function takes these importance scores into account when performing the pruning.
Please note that implementing a proper weighted pruning technique can be more complex and requires careful consideration of the importance metrics, pruning rate, and iterative retraining to achieve better model performance.
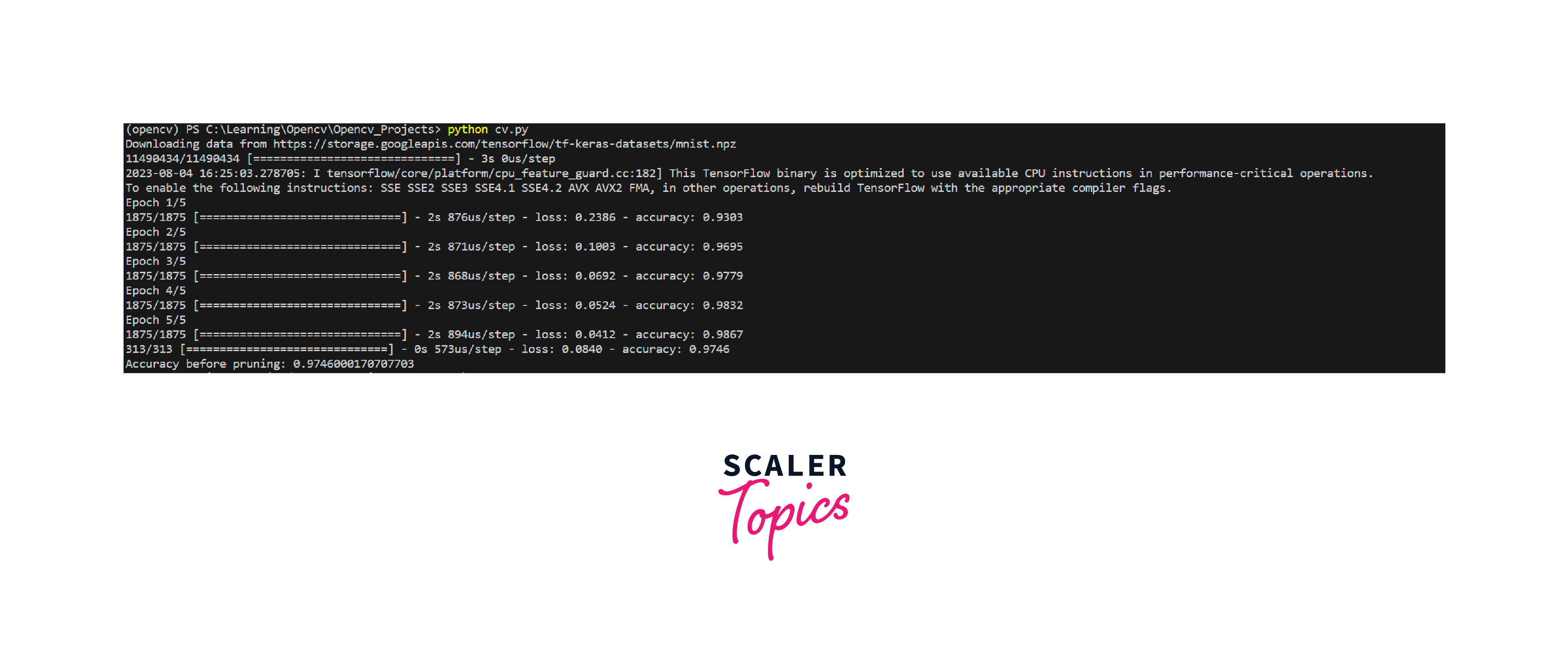
Above is the output of the code before pruning
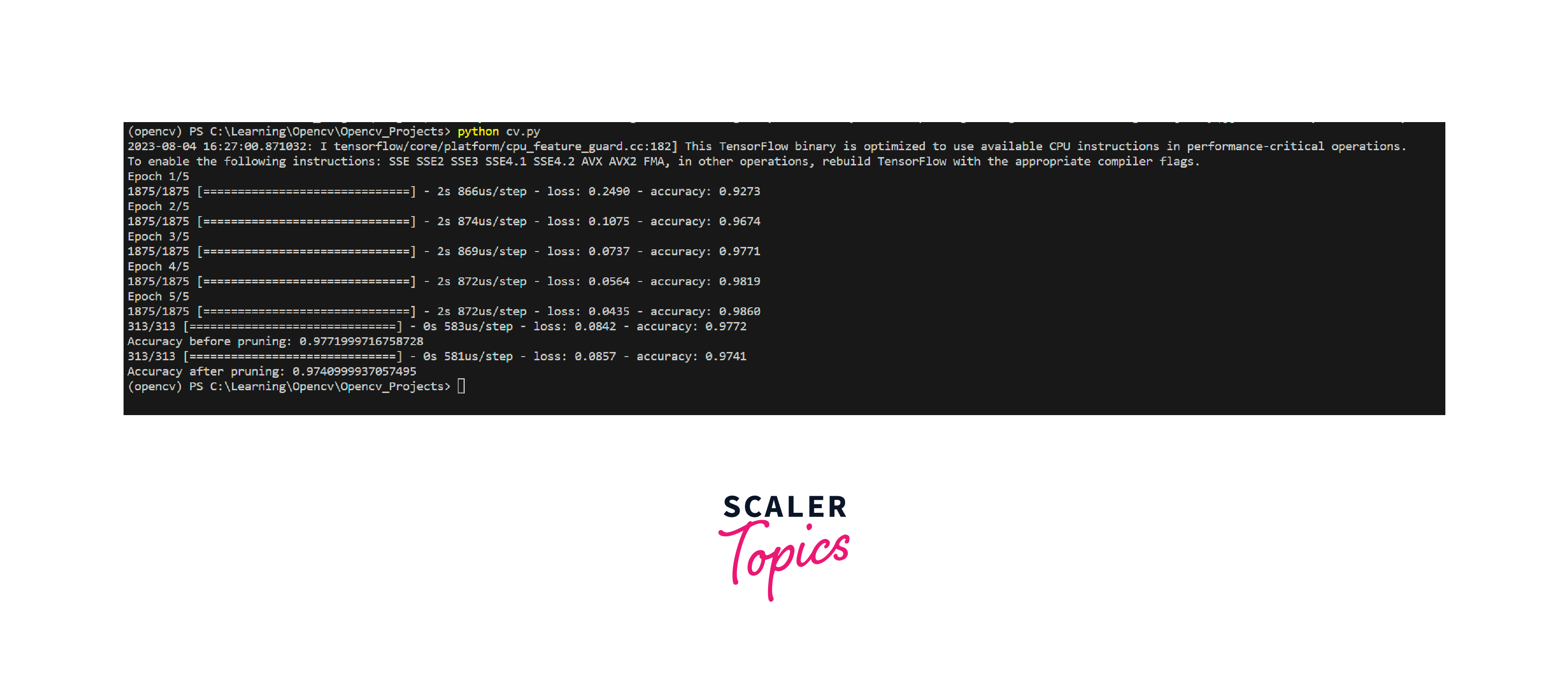
Above is the output of the code after pruning
The key benefits of pruning include:
- Reduced Model Size:
Pruning eliminates non-essential components, leading to a smaller model that requires less memory and storage. - Faster Inference:
Smaller models result in faster inference times, making them more suitable for real-time applications and resource-constrained devices. - Regularization:
Pruning can act as a form of regularization, preventing overfitting and improving generalization on unseen data.
However, it is essential to strike a balance between the degree of pruning and maintaining model accuracy. Aggressive pruning without appropriate techniques, such as pruning-aware training, can lead to significant accuracy loss. Properly applied, pruning offers a valuable tool for optimizing deep learning models and making them more efficient for real-world applications. So Pruning-Aware training is important for model Pruning.
Pruning-Aware Training
Pruning-aware training involves training neural network models in such a way that they can adapt to the pruning process and recover from any performance degradation caused by weight, filter, or neuron pruning. There are different approaches to pruning-aware training, and some of the common types include:
1. Fine-Tuning after Pruning:
In this approach, the pre-trained model is pruned, and then the pruned model is fine-tuned using a smaller learning rate on the original dataset or a subset of the training data. Fine-tuning allows the model to adjust its remaining weights to compensate for the removed weights and adapt to the sparsity introduced by pruning.
In above code, After pruning, we perform pruning- aware fine-tuning by training the pruned model on the dataset again using a smaller learning rate (0.0001) to allow the model to adapt to the pruning changes. This fine-tuning step helps the model recover from any performance degradation caused by pruning.
2. Iterative Pruning:
Iterative pruning involves applying pruning and retraining multiple times in an iterative manner.The process includes pruning, retraining the pruned model, pruning again, and repeating the cycle until the desired level of sparsity is achieved or performance stabilizes.
The iterative pruning process consists of three iterations (for i in range(3)). In each iteration, we perform weight pruning using the sparsity.prune_low_magnitude function with the pruning schedule. After pruning, we copy the pruned weights from the pruned model to the original model and compile it again.
We then train the pruned model on the dataset for five more epochs in each iteration. After each iteration, the model adapts to the pruning changes and recovers from the performance degradation.
3. Gradual Pruning:
Gradual pruning involves gradually increasing the sparsity level during training instead of applying a fixed sparsity level from the start.This approach allows the model to adapt to increasing sparsity levels gradually, leading to more stable performance.
The gradual pruning process involves gradually increasing the sparsity level during training. In the loop, we check the current step, and if it is a multiple of 100 (as specified by step % 100 == 0), we apply weight pruning to the model using the current sparsity level from the pruning schedule. The pruning process is repeated at regular intervals during training.
After each pruning step, we copy the pruned weights from the pruned model to the original model and compile it again. We can optionally train the pruned model for a few steps to allow it to adapt to the pruning changes before updating the original model with the pruned weights.
The loop continues until the desired number of steps (5000 in this example) is reached, allowing the sparsity level to increase gradually during training.
TensorFlow Pruning Tools
TensorFlow Pruning Tools are used by novices and advanced developers, which they use to optimize machine learning models for deployment and execution. One of the important tools is the Model Optimization Toolkit.
TensorFlow’s Model Optimization Toolkit (MOT) has been used widely for converting/optimizing TensorFlow models to TensorFlow Lite models with smaller sizes, better performance and acceptable accuracy to run them on mobile and IoT devices. At Present, they are also working to extend MOT techniques and tooling beyond TensorFlow Lite to support TensorFlow SavedModel. This toolkit provides a range of functionalities for optimizing and pruning deep learning models. Let's delve into some of the key tools and features it offers:
-
Weight Pruning:
Tfmot can prune individual weights in a model. Weight pruning involves identifying and removing weights with small magnitudes, often less important to the model's performance. Doing so reduces the model's size without a significant loss in accuracy. -
Structured Pruning:
Structured Pruning goes beyond individual weight pruning by removing entire neurons, channels, or other structured components from the model. This can lead to even greater model efficiency. The tfmot.sparsity.keras module within tfmot facilitates structured Pruning and allows users to define the sparsity pattern across different layers. -
Pruning Callbacks:
Tfmot supports integrating Pruning into the training process. This is achieved through custom callbacks that can apply pruning masks to the model's weights during training. This dynamic approach ensures the model adapts to the pruning process over time. -
Fine-Tuning:
After Pruning, fine-tuning is often performed to restore some of the accuracy lost during the pruning process. Fine-tuning involves training the pruned model on the data again, allowing it to relearn important connections and adjust to the changes. -
Quantization:
Though not strictly a pruning technique, tfmot also offers quantization tools that reduce memory and computation requirements by using lower precision for weights and activations.
Benefits of Model Pruning Tools
The TensorFlow model pruning tools bring several benefits to deep learning practitioners and researchers:
-
Efficiency:
Pruned models are more efficient regarding memory usage and inference speed, making them suitable for deployment on edge devices, mobile applications, and real-time systems. -
Resource Savings:
Smaller models require fewer computational resources for training and deployment, which can lead to cost savings and more environmentally friendly AI applications. -
**Deployment Flexibility
Pruned models are better suited for deployment in environments with limited computational resources, enabling a wider range of applications.
Pruning Models with TFLite
TensorFlow Lite (TFLite) is an optimized version of TensorFlow designed for mobile and edge devices. TFLite supports deploying pruned models for inference on resource-constrained platforms, making it a suitable option for real-world applications. After pruning and optionally retraining the model, convert the pruned model to TensorFlow Lite format for deployment on mobile or edge devices. TensorFlow Lite offers a converter tool to facilitate this conversion.
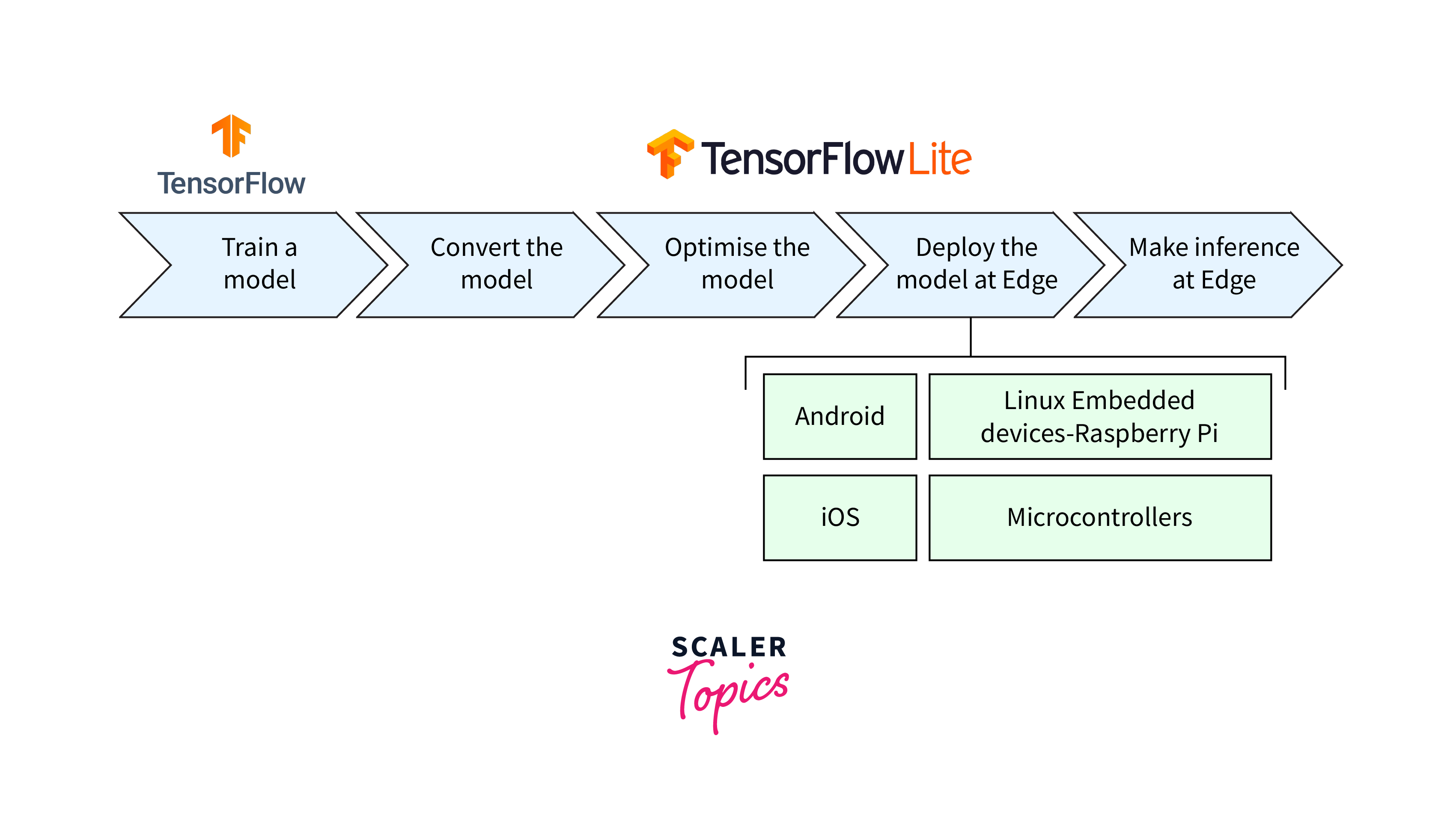
Pruning reduces model size and enhances efficiency but comes with trade-offs. Aggressive pruning may lead to a considerable reduction in model accuracy, especially without pruning-aware training. Striking the right balance between model size and accuracy is crucial when using pruning.
Trade-Offs Between Model Size and Accuracy
In the realm of machine learning, the delicate interplay between model size and accuracy is a critical consideration that impacts the feasibility and effectiveness of deploying models across various applications. As the demand for embedding artificial intelligence in resource-limited environments surges, striking the right balance between these two factors becomes paramount.
1. Model Size:
Model size refers to the number of parameters, weights, and connections within a neural network. Larger models are typically more expressive and capable of capturing intricate patterns in data, leading to higher accuracy during training. However, this expansiveness comes at the cost of increased memory and computational requirements.
2. Accuracy:
Accuracy is the model's ability to correctly predict outcomes. Higher accuracy is desirable as it ensures the model's predictions align closely with ground truth labels. Achieving high accuracy, though, often entails training complex and large-scale models.
Factors Influencing Trade-offs
-
Resource Constraints:
Deploying models on devices with limited resources, such as mobile phones and edge devices, necessitates minimizing model size to ensure efficient operation. -
Inference Speed:
Smaller models generally require less computation during inference, leading to faster predictions. This is crucial for real-time applications. -
Communication Overhead:
Transmitting models over networks consumes bandwidth. Smaller models are quicker to send, making them preferable for remote inference. -
Accuracy Requirements:
The application's accuracy needs dictate the acceptable level of accuracy drop resulting from model compression.
The best ways to achieve balance is by Pruning and Quantization, which provide a harmonious synergy between reducing model size and preserving accuracy. Pruning selectively trims away redundant connections, resulting in a linear model architecture. Meanwhile, quantization reduces the precision of weights, further compressing the model's memory footprint. Together, these techniques offer a comprehensive approach to optimizing neural networks for efficient deployment on resource-constrained devices, all while minimizing the compromise on predictive performance.But,You can also consider other techniques like Knowledge Distillation,Architecture Design,Ensemble Methods.
Evaluate Quantized Models
Quantization complements pruning by reducing the precision of model weights, further reducing model size.TensorFlow Lite provides support for quantization, enabling the deployment of quantized models on resource-constrained devices.
Below is an explanation of how to evaluate quantized models in TensorFlow Lite:
-
Step 1: Convert the Pruned Model to Quantized TensorFlow Lite Format
Before evaluation, you need to convert the pruned model to a quantized TensorFlow Lite format. You can do this by specifying the quantization mode in the TFLite converter.In above, the pruned model is converted to a quantized TensorFlow Lite model using the tf.lite.TFLiteConverter. The converter.optimizations option specifies that default optimizations for quantization should be applied. The converter.target_spec.supported_types option sets the model to be quantized using 8-bit integers (int8).
-
Step 2: Save the Quantized TensorFlow Lite Model
Save the quantized TensorFlow Lite model to a file, similar to the previous code example.In above, the quantized TensorFlow Lite model is saved to a file named 'pruned_model_quantized.tflite'.
-
Step 3: Load the Quantized TensorFlow Lite Model and Evaluate
Load the quantized TensorFlow Lite model and use a TensorFlow Lite interpreter to evaluate its performance on a test dataset.In above, the quantized TensorFlow Lite model is loaded using the tf.lite.Interpreter. The model's input and output details are retrieved using get_input_details() and get_output_details(), respectively . The loaded model is then used to perform inference on the test dataset (assumed to be loaded as 'x_test' and 'y_test'). For each test sample, the input tensor is set, the model is invoked, and the output tensor is retrieved. The predictions are collected in the 'predictions' list.
Finally, the accuracy of the quantized model is calculated by comparing the predicted labels with the true labels from the test dataset.
However, quantization may impact model accuracy, and evaluating the trade-offs between quantization and pruning is essential.
Deployment and Integration
Pruned models, along with quantization if applied, can be deployed on edge devices, mobile phones, and other resource-limited platforms. Integration into existing applications and systems can be achieved with the help of frameworks like TensorFlow Lite.
-
Model Serving:
For deployment in server environments or cloud-based applications, you may use a model server to serve the machine learning models as RESTful APIs. Frameworks like TensorFlow Serving or Flask can be used to set up the model server. -
Mobile App Integration:
For integration with mobile applications, TensorFlow Lite offers mobile-friendly APIs and SDKs for popular mobile platforms like Android and iOS. This enables seamless integration of machine learning models into mobile apps. -
Edge Device Integration:
For edge devices with hardware accelerators (e.g., Edge TPU, Coral TPU), TensorFlow Lite supports hardware acceleration to further improve inference performance. Models can be deployed to edge devices using dedicated libraries and APIs. -
Security and Privacy Considerations:
During deployment, security and privacy considerations must be taken into account. If the models involve sensitive data or operations, appropriate security measures, such as encryption, must be implemented. -
Monitoring and Maintenance:
Once deployed, monitoring the models' performance and ensuring that they are up-to-date are crucial. Model drift and concept drift should be monitored, and models may need to be retrained periodically to maintain accuracy. -
Continuous Integration and Deployment (CI/CD):
Using CI/CD practices ensures seamless deployment and integration of model updates. Automated testing and deployment pipelines help maintain consistency and reliability.
Limitations and Future Developments
Limitations of Pruning
- Performance Degradation:
Aggressive pruning may lead to significant performance degradation, especially if not combined with techniques like pruning-aware training or fine-tuning. - Sensitivity to Initialization:
Pruned models can be sensitive to weight initialization, and different initializations may result in different pruned structures and performance. - Reduced Expressiveness:
Over-pruning may lead to a loss of model expressiveness, limiting its ability to capture complex patterns in the data. - Fine-Grained Pruning Challenges:
Fine-grained pruning at the level of individual weights may require specialized hardware support for efficient inference.
Future Developments
- Automated Pruning Algorithms:
Develop more sophisticated and automated pruning algorithms that can adaptively identify redundant weights and structures in models without requiring manual tuning. - Advanced Quantization Techniques:
Explore advanced quantization techniques that mitigate the impact of quantization noise and improve model performance at lower bit precision. - Hybrid Pruning and Quantization:
Investigate the synergy between pruning and quantization techniques to achieve even more compact and efficient models for deployment. - Dynamic Pruning:
Implement dynamic pruning techniques that can prune and grow model structures during runtime based on the input data distribution. - Compression Algorithms:
Research and develop novel model compression algorithms that combine multiple techniques to achieve better trade-offs between model size and accuracy.
Conclusion
- Pruning and quantization are powerful model compression techniques that reduce the memory footprint and computational requirements of deep learning models.
- Pruning eliminates redundant connections and weights, leading to sparser models without sacrificing accuracy, making them suitable for deployment on resource-constrained devices.
- Quantization reduces the precision of model parameters, resulting in smaller model size and faster inference, making it ideal for edge devices and mobile applications.
- Pruning-aware training helps mitigate the performance degradation caused by pruning, ensuring that pruned models retain their accuracy.
- The combination of pruning and quantization enables the deployment of efficient and accurate machine learning models across a wide range of real-world applications, from mobile devices to IoT devices and edge computing, addressing real-world challenges with intelligent and resource-friendly solutions.