Multi-worker Training with Keras
Overview
In the world of deep learning, the quest for training faster and more efficiently is never-ending. Multi-worker training with Keras is a powerful technique that leverages the capabilities of multiple machines or accelerating the training of neural networks using GPU . In this blog post, we will dive deep into the concept of multi-worker training with Keras, exploring its advantages, working principles, challenges, techniques, and how to implement it.
What is Multi-worker Training?
Multi-worker training, also known as distributed training, is a training strategy in deep learning that involves using multiple workers (machines or GPUs) to collectively train a neural network model. Instead of relying on a single machine to handle the entire training process, multi-worker training distributes the workload across multiple workers, enabling faster convergence and improved training efficiency.
Advantages of Multi-worker Training
Multi-worker training with keras offers several compelling advantages:
-
Reduced Training Time:
By parallelizing the training process, multi-worker training significantly reduces the time required to train large neural network models. This is crucial for tasks that involve massive datasets and complex architectures. -
Scalability:
It allows you to scale your training infrastructure according to your needs. You can add more workers as your dataset or model complexity increases, ensuring that your training process remains efficient. -
Resource Utilization:
Multi-worker training with keras optimally utilizes available computing resources, making efficient use of GPUs and CPUs. This leads to better resource utilization and cost savings in cloud-based environments. -
Improved Model Quality:
In some cases, multi-worker training with keras can help improve the quality of trained models. By exploring a wider range of parameter updates concurrently, it may escape local minima more effectively and discover better solutions. -
Robustness:
Distributed training can be more robust against hardware failures. If one worker fails, the training can continue on the remaining workers, reducing the risk of data loss.
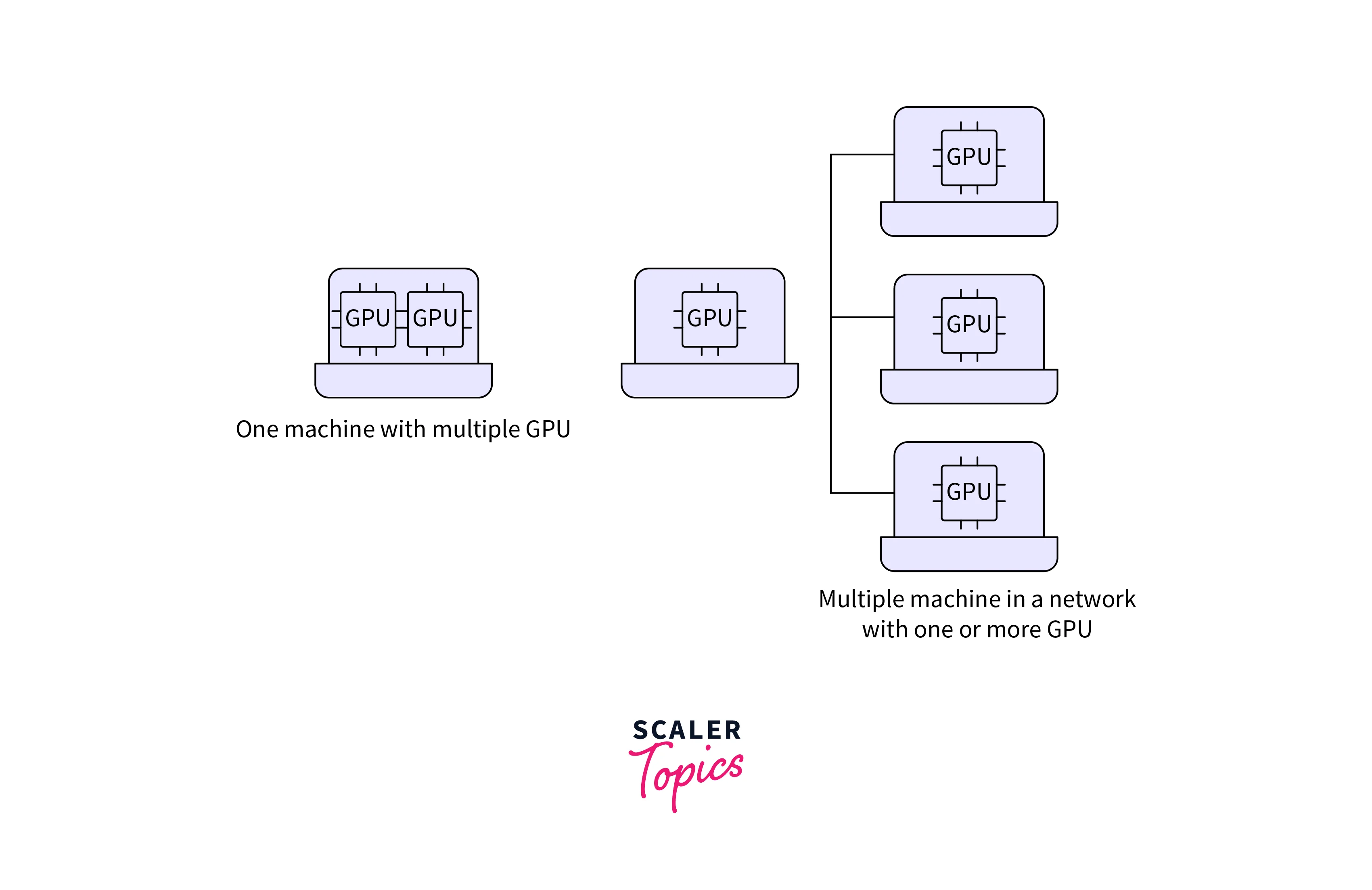
How Multi-worker Training Works
Multi-worker training with keras involves breaking down the training process into several key components:
-
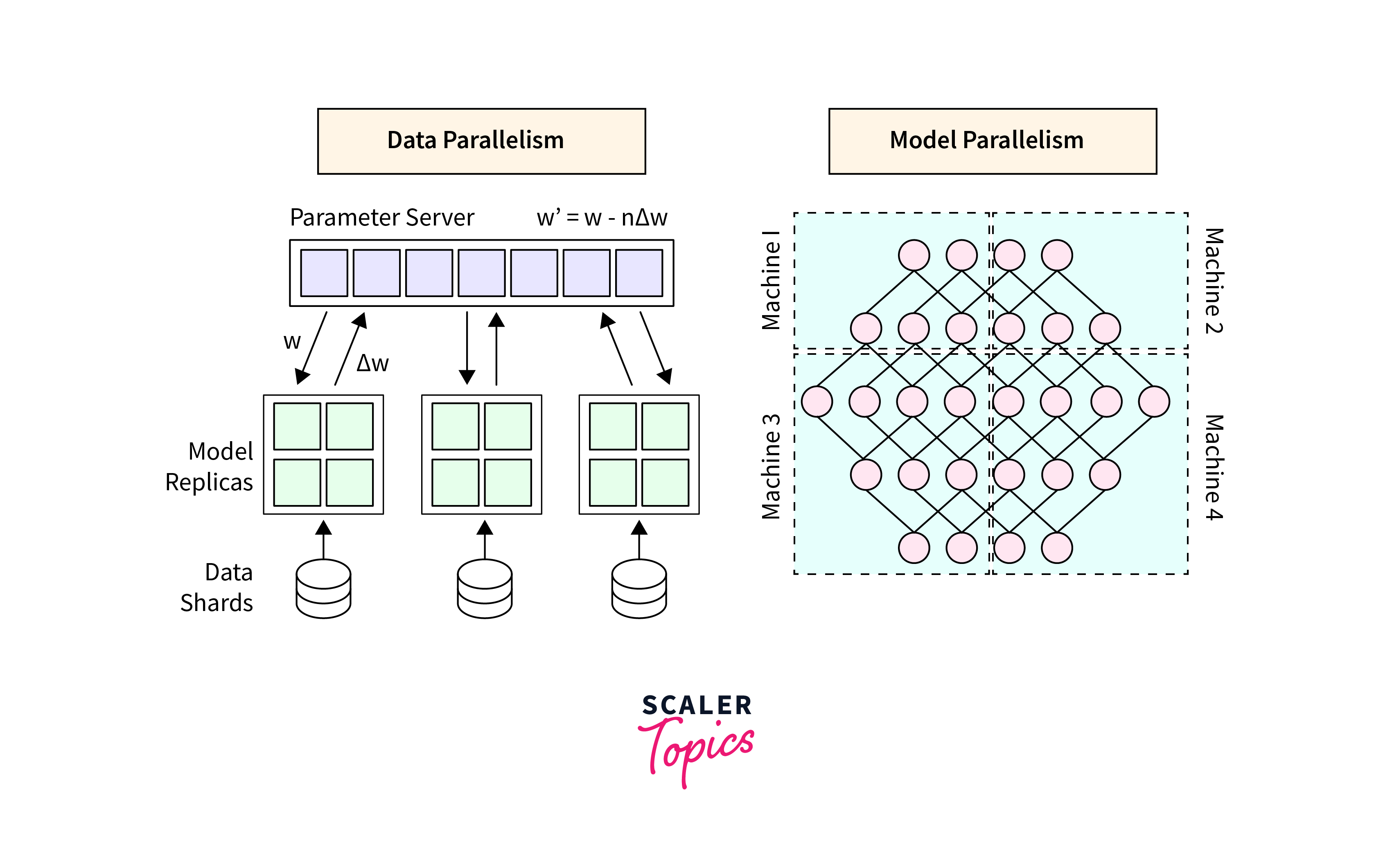
Data Parallelism:
Each worker operates on a subset of the training data. The dataset is divided into smaller batches, with each worker responsible for processing a batch. The workers then compute gradients based on their batch and share these gradients with each other. -
Model Parallelism:
The neural network model is replicated on each worker, and each worker computes gradients for a different subset of model parameters. These gradients are aggregated to update the global model. -
Parameter Server:
In some distributed training setups, a parameter server is used to store and synchronize model parameters. Workers communicate with the parameter server to exchange gradients and retrieve the latest model weights. -
Synchronization:
Proper synchronization mechanisms are crucial to ensure that all workers are updating the model at the same time. Techniques like synchronous and asynchronous training are used to manage this synchronization.
Challenges for Multi-worker Training with Keras
While multi-worker training offers significant advantages, it also comes with its fair share of challenges:
-
Communication Overhead:
Coordinating the exchange of gradients and model updates between workers can introduce communication overhead. This overhead can limit the speedup achieved by adding more workers. -
Complexity:
Distributed training setups are inherently more complex than single-worker training. Managing multiple workers, handling failures, and designing efficient synchronization strategies can be challenging. -
Data Distribution:
Dividing the dataset into batches for different workers must be done carefully to ensure that each worker receives a representative sample of data. Biased data distribution can lead to poor model performance. -
Resource Management:
Allocating and managing resources across multiple workers, especially in cloud-based environments, requires careful resource management to avoid wastage and unnecessary costs.
Multi-worker Training Techniques
To overcome the challenges of multi-worker training, various techniques and frameworks have been developed. Some of the popular ones include:
- Parameter Servers:
Parameter servers, as mentioned earlier, are used to store and synchronize model parameters. This approach offloads the communication overhead from workers and centralizes parameter management.
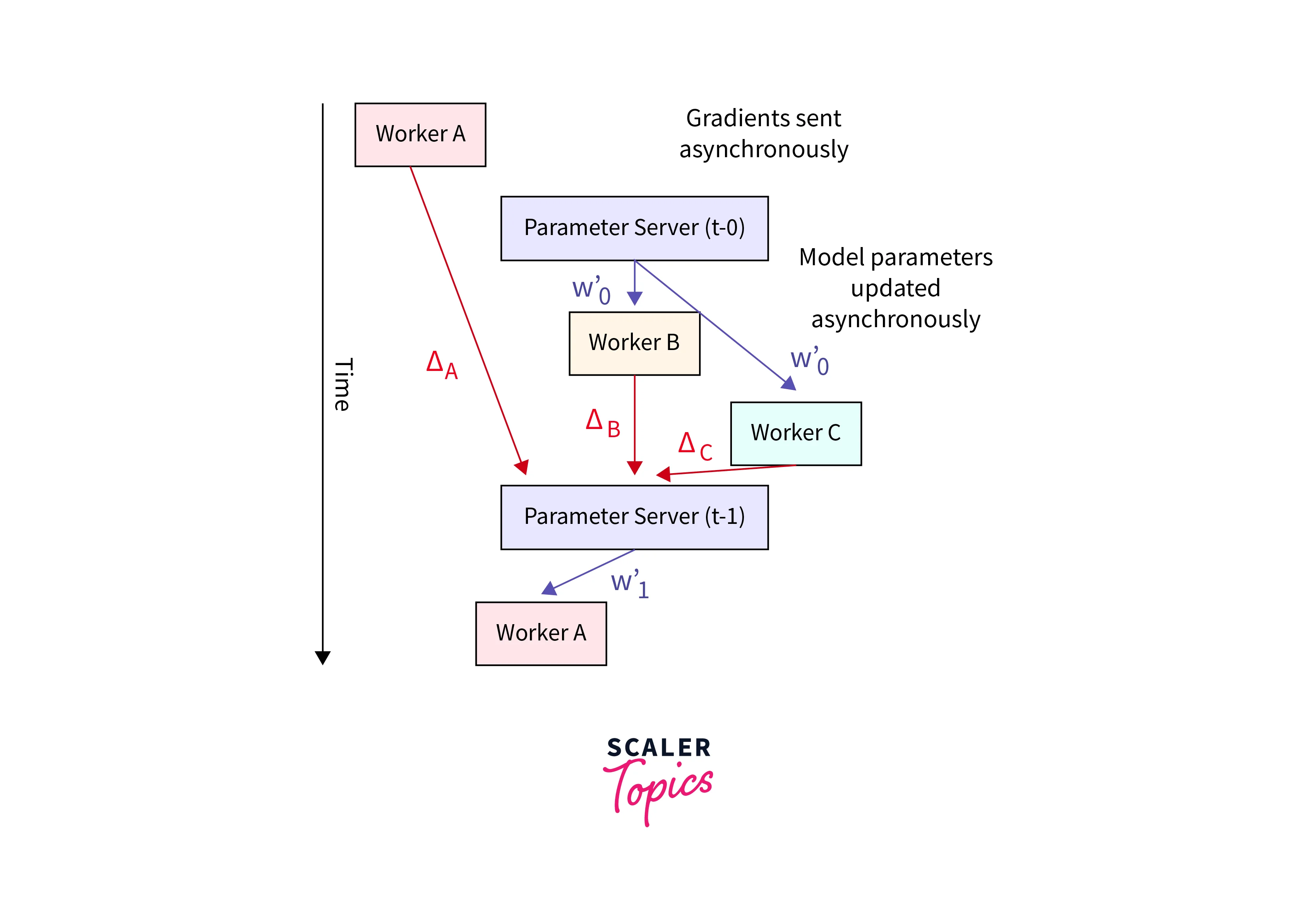
- AllReduce:
The AllReduce communication pattern is commonly used to aggregate gradients from multiple workers efficiently. Techniques like ring-based or tree-based AllReduce can be employed to minimize communication overhead.
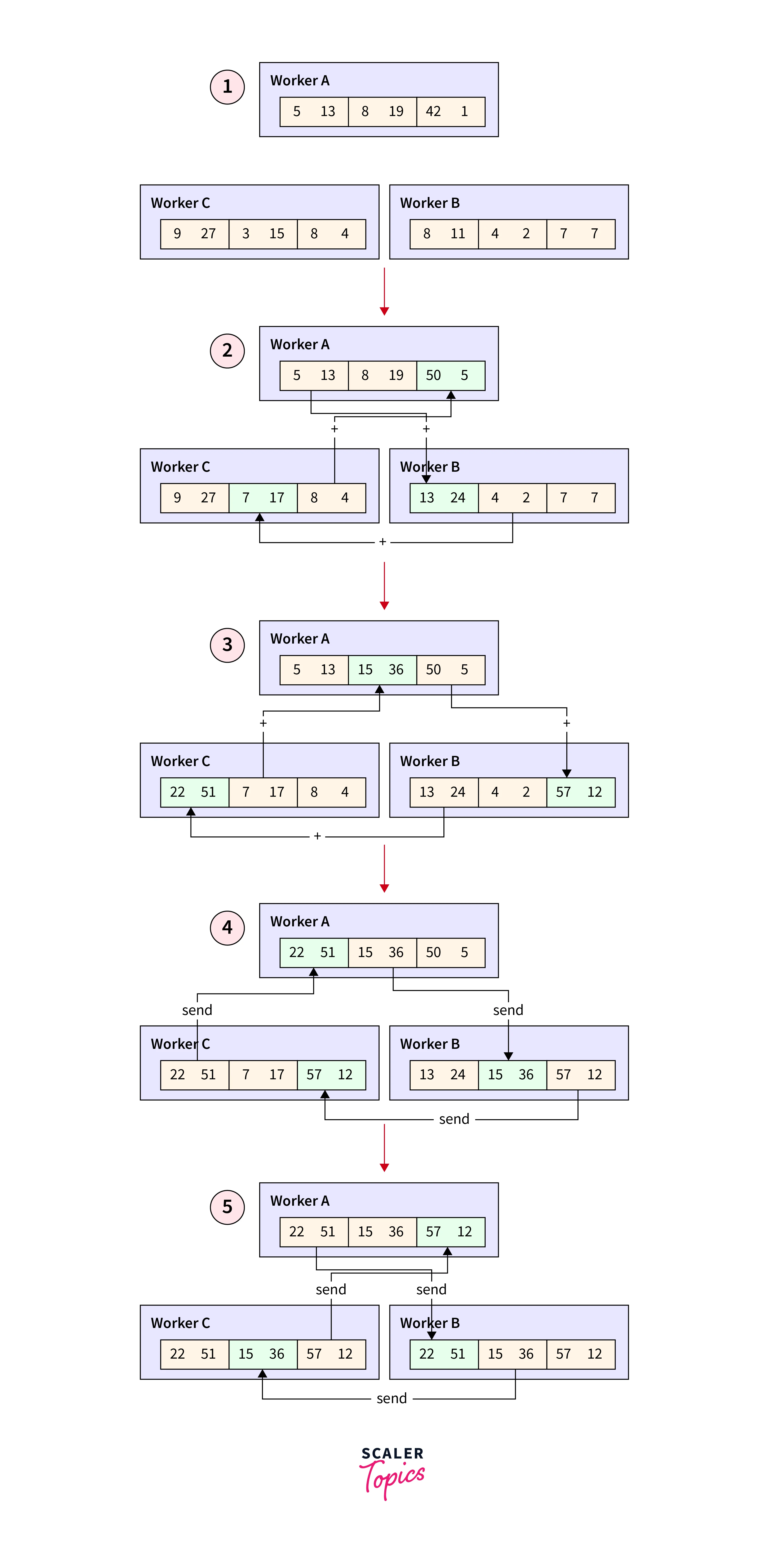
- Horovod:
Horovod is a popular open-source framework that simplifies distributed deep learning. It provides an easy-to-use API for multi-GPU and multi-node training, abstracting many of the complexities of distributed training.
![]()
- TensorFlow and PyTorch:
Both TensorFlow and PyTorch offer built-in support for distributed training. TensorFlow's tf.distribute and PyTorch's torch.nn.DataParallel modules make it easier to implement multi-worker training in these frameworks.
Implementation of Multi-worker Training in Keras
Implementing multi-worker training in Keras is made relatively straightforward with the help of TensorFlow's distributed training tools. Let's outline the steps to set up multi-worker training using Keras:
Step 1: Prepare Your Environment
Ensure you have TensorFlow 2.x installed. Multi-worker training with Keras relies on TensorFlow's distribution strategies.Prior to importing TensorFlow, you should make some adjustments to the environment:
In a practical scenario, each worker would typically be distributed across different machines. However, for the purposes of this tutorial, all workers will be executed on the same machine. Consequently, it is essential to deactivate all GPUs to avoid potential errors arising from multiple workers attempting to utilize the same GPU.
To take advantage of the new functionality introduced in TensorFlow 2.10, which allows you to control the frequency of checkpoint saving at a specific step using the save_freq argument in tf.keras.callbacks.BackupAndRestore, you should install the tf-nightly version.
Step 2: Import Necessary Libraries
Import TensorFlow and other relevant libraries in your Python script.
Step 3: Define a Strategy
Create a distribution strategy using tf.distribute.experimental.MultiWorkerMirroredStrategy which allows multiple workers train the model.
Step 4: Load and Preprocess Data
Load your dataset and preprocess it as usual. Ensure that the data is divided into batches appropriately.
Step 5: Define Your Model
Build your neural network model within the strategy.scope() context. This ensures that the model is replicated on all workers.
Step 6: Training on a single worker
Observe the results of the model by training the model for a small number of epochs to make sure everything works correctly.
Output:
Step 7: Launch Multi-worker Training
In TensorFlow, distributed training revolves around the concept of a 'cluster' which comprises multiple 'jobs' and each job can encompass one or more 'tasks.'
For effective multi-worker training, you'll require the TF_CONFIG configuration environment variable, especially when training on multiple machines, each potentially serving a distinct role. TF_CONFIG is a JSON string that serves to define the cluster configuration for every worker within the cluster.
TF_CONFIG comprises two key components: 'cluster' and 'task'.
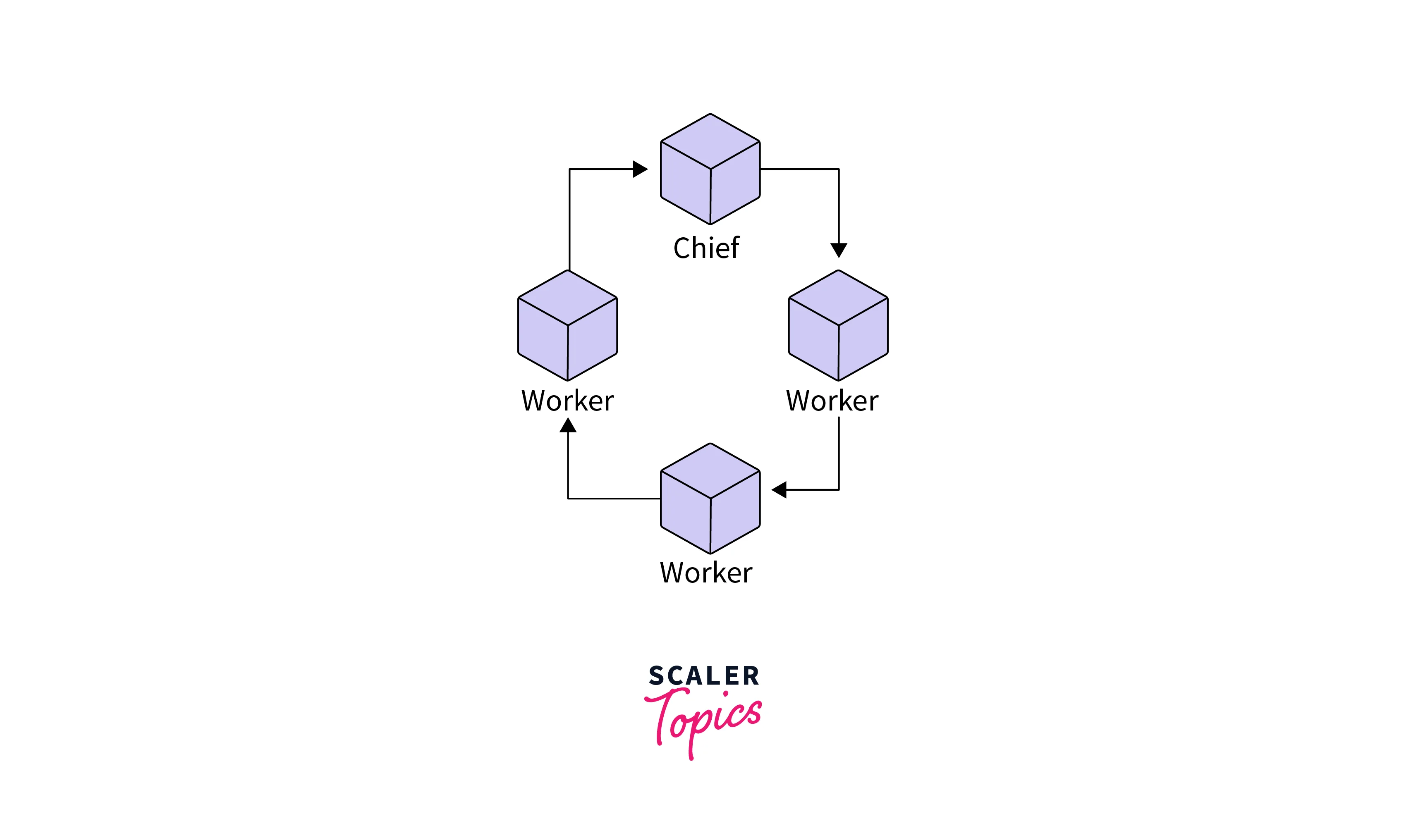
The 'cluster' component remains consistent across all workers and furnishes details about the training cluster. This 'cluster' is essentially a dictionary that contains various types of jobs, such as 'worker' or 'chief.'
In multi-worker training employing tf.distribute.MultiWorkerMirroredStrategy, there's typically one 'worker' that assumes additional responsibilities beyond those of a regular 'worker' These added tasks may include saving checkpoints and generating summary files for TensorBoard, among others. This special 'worker' is known as the 'chief worker' and is typically associated with the job name 'chief.' Conventionally, the worker with an 'index' of 0 is designated as the 'chief'
The 'task' component provides distinct information for each worker, specifying the 'type' and 'index' of that particular worker.
Note:
tf_config is local variable in python. serialize it as a JSON and place in TF_CONFIG environment to use it for training configuration.
Output:
Now we'll build main.py file which will be used to train the model.
Output:
Writing main.py
Step 8: Monitoring and Checkpointing
Monitor the training progress and save checkpoints of your model for evaluation or future training runs.
You can find a complete example and more detailed instructions in the official TensorFlow documentation here.
Case Studies and Examples
Let's explore a couple of case studies to understand how multi-worker training with Keras has been applied in real-world scenarios:
Case Study 1: Natural Language Processing (NLP)
In NLP tasks, training large language models like GPT-3 or BERT can be extremely resource-intensive. Multi-worker training with keras allows researchers to train these models more quickly. By distributing the training across multiple GPUs or machines, they can significantly reduce the time required to fine-tune these models on domain-specific tasks.
Case Study 2: Image Classification
Image classification tasks often involve large datasets and complex convolutional neural networks. Multi-worker training with keras has been employed to train state-of-the-art models like ResNet and Inception on massive datasets like ImageNet. This approach not only reduces training time but also allows researchers to experiment with different model architectures and hyperparameters more efficiently.
Conclusion
- Multi-worker training with Keras is a powerful technique that leverages distributed computing resources to accelerate the training of deep neural network models.
- It offers advantages such as reduced training time, improved scalability, and efficient resource utilization.
- However, it comes with challenges related to communication overhead, complexity, data distribution, and resource management.
- To implement multi-worker training in Keras, you can follow a series of steps that involve defining a distribution strategy, loading and preprocessing data, building your model, and training it within the strategy scope.
- Various frameworks and tools like TensorFlow's tf.distribute, Horovod, and parameter servers simplify the implementation process.