Neural Machine Translation with Attention TensorFlow
Overview
In NLP, machine translation is a fascinating and challenging task. With the neural networks and deep learning, significant advancements have been made in this field. One of the key breakthroughs is the introduction of attention mechanisms, which have greatly improved the accuracy of machine translation models. In this blog, we will dive into the topic of neural machine translation with attention using TensorFlow, covering everything from the basics of recurrent neural networks (RNNs) to advanced techniques and variations.
Understanding Recurrent Neural Networks (RNNs)
Before delving into machine translation, it's essential to grasp the fundamentals of Recurrent Neural Networks (RNNs). RNNs are class of neural networks designed specifically for handling sequential data. This section will explore their architecture, how they process sequences, and their inherent limitations.
- RNNs and Their Role in Sequential Data Handling
Recurrent neural networks (RNNs) represent the cutting edge in dealing with sequential data and have found applications in popular voice assistants like Apple's Siri and Google's voice search. What sets RNNs apart is their unique ability to remember past inputs, thanks to their internal memory. This quality makes them exceptionally well-suited for machine-learning tasks that involve sequential data. RNNs stand as one of the driving forces behind the remarkable advancements in deep learning over recent years.
- Harnessing Internal Memory
RNNs can effectively retain crucial information about the input they have received. This capacity enables them to precisely predict what should happen in a sequence. Consequently, they emerge as the preferred choice for tasks involving sequential data, including time series analysis, speech recognition, natural language processing, financial data analysis, audio and video processing, weather forecasting, and more. RNNs can build a profound understanding of a sequence and its context, setting them apart from other machine learning algorithms.
- Unveiling the RNN Architecture
In Recurrent Neural Networks, information flows through a loop, primarily involving three components:
Input Layer (x): This layer receives and processes the input data before passing it to the next layer.
Middle Layer ('h'): The middle layer can comprise multiple hidden layers, each with its activation functions, weights, and biases. However, RNNs fundamentally rely on a single hidden layer with recurrent connections. This layer maintains an internal memory or context, enabling it to capture dependencies and patterns in sequential data.
Parameter Sharing: An RNN shares the same set of weights and biases across each time step to achieve its sequential processing capabilities. This parameter sharing ensures that the network retains memory of previous inputs and computations.
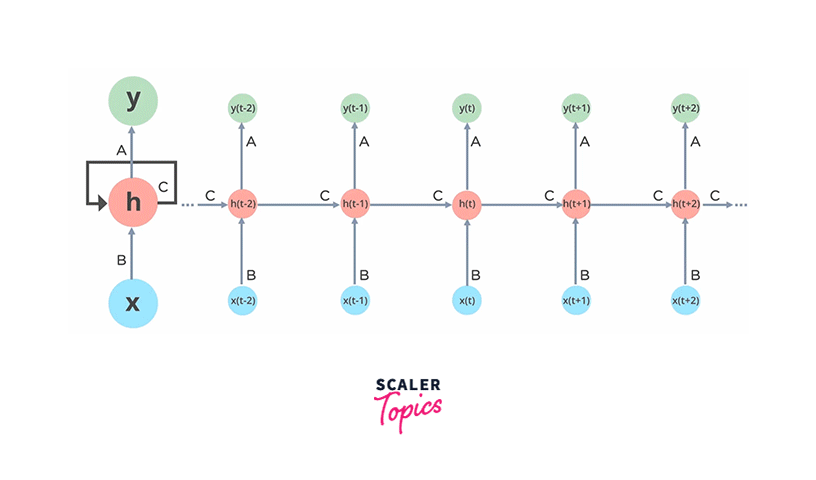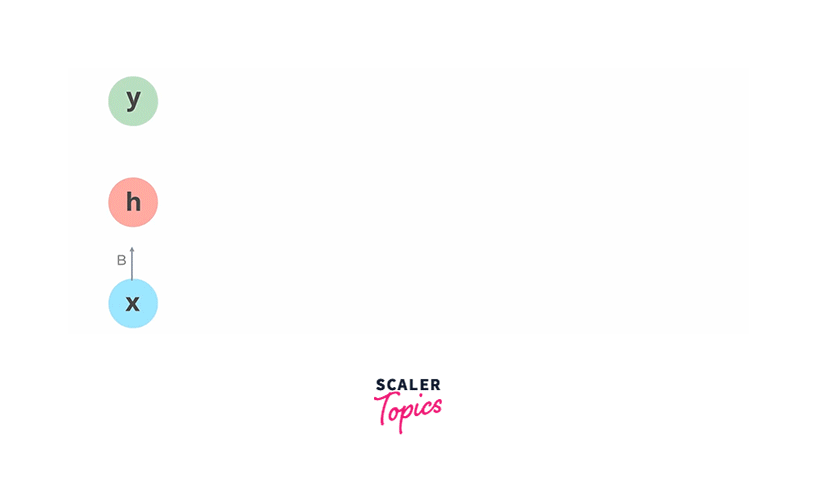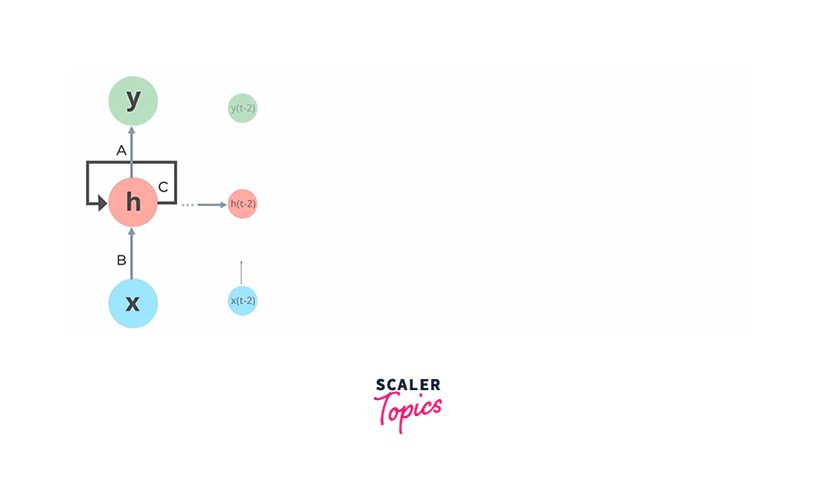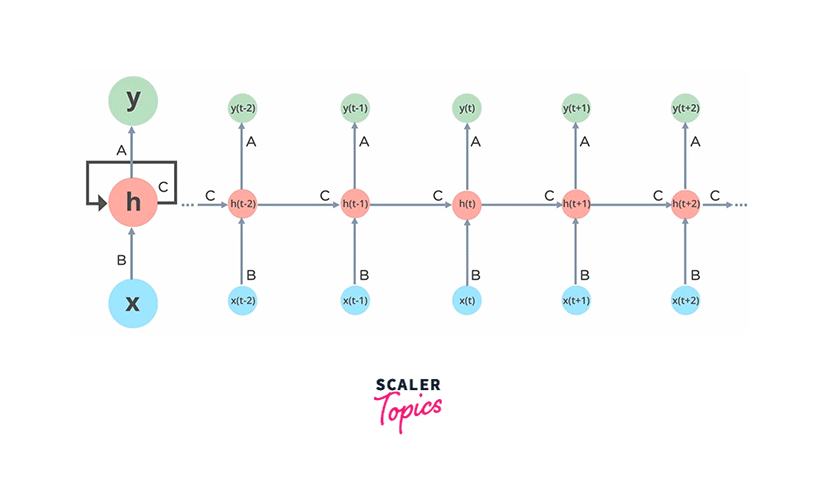
Recurrent Neural Networks are a cornerstone in machine learning, particularly for processing sequential data. Their unique ability to maintain internal memory and process sequences iteratively makes them invaluable for various applications, driving innovation across various domains.
Introduction to Translation with RNNs
One of the cool things we can use RNNs for is translating text from one language to another. In the past, this was done using hand-crafted features and many complex conditions, which took a long time to create and were complex to understand. So, let's see how RNNs make life easier and do a better job.
RNNs can perform translation tasks by treating them as sequence-to-sequence (Seq2Seq) models. The process of translation using RNNs typically involves two main phases:
- Encoding:
- The source text (in original language) is processed by the encoder RNN.
- The encoder reads the input text one token (word or character) at a time while maintaining a hidden state summarising the information it has seen.
- This hidden state, the context or thought vector, encapsulates the source text's meaning.
- Decoding:
- The context vector generated by the encoder is passed to the decoder RNN.
- The decoder generates the translated text (in the target language) one token at a time, considering both the context vector and the previously generated tokens.
- The process continues until the decoder produces the entire translation.
Benefits of RNN-Based Translation:
- Contextual Understanding: context and dependencies within sentences. This allows them to produce more contextually accurate translations.
- Flexibility: RNN-based models can be trained on various language pairs and domains, making them adaptable to various translation tasks.
- Efficiency: Compared to traditional rule-based translation methods, RNNs can automatically learn translation patterns, reducing the need for manual rule creation.
Introducing Attention Mechanism
The attention mechanism was introduced to improve performance of encoder-decoder model for machine translation. The idea behind the attention mechanism is to permit decoder to utilize the most relevant parts of the input sequence flexibly by weighted combination of all the encoded input vectors, with most relevant vectors being attributed the highest weights.
The attention mechanism solves the problem of handling long sequences and focusing on relevant parts of the input sequence when generating an output. It allows the model to selectively "attend" different parts of the input sequence when making predictions. Here's how the attention mechanism works:
-
Scoring: The attention mechanism assigns a score to each element in input sequence based on its relevance to current step in the output sequence. This scoring is often learned during training.
-
Weighted Sum: These scores are used to calculate a weighted sum of the input sequence elements. Elements with higher scores get more weight, contributing more to the output.
-
Context Vector: The weighted sum results in a context vector, a weighted combination of the input elements. This context vector captures the most relevant information from the input sequence for the current step in the output sequence.
-
Incorporation: The context vector is then incorporated into the model's decision-making process, such as in the generation of the next word in a translation or the prediction of the next element in a sequence.
-
Key Benefits of the Attention Mechanism
-
Improved Contextual Understanding: Attention mechanisms enhance a model's ability to understand the context of a given input. It helps the model focus on the right parts of the sequence, leading to better performance in tasks like machine translation and text summarization.
-
Handling Variable-Length Sequences: Attention can handle input sequences of varying lengths, making it versatile for various applications.
-
Interpretable: Attention scores can provide insights into what parts of the input sequence are most important for generating each element of the output sequence, making models more interpretable.
Attention-Based Translation with RNNs
Language translation is a complex task that involves capturing the nuances and context of one language while producing coherent text in another. Traditional machine translation methods, such as those using purely Recurrent Neural Networks (RNNs), often struggle with long sentences and maintaining context over extended sequences. This is where attention mechanisms come to the rescue.
When translating a sentence from one language to another, it's common for the source sentence to have a different length and structure than the target sentence. This misalignment presents a challenge for RNNs, as they struggle to capture the relevant context from the source sentence when generating each word of the target sentence. This is especially problematic for long sentences where important information may be distant from the current generated word.
The attention mechanism addresses the issue of contextual understanding in machine translation. Instead of relying solely on the final hidden state of the encoder RNN (which summarizes the entire source sentence), attention mechanisms enable the decoder RNN to selectively focus on different parts of the source sentence at each translation step.
Here's how attention-based translation with RNNs works:
-
Encoding: The source sentence is processed by an encoder RNN, which generates a sequence of hidden states. Each hidden state captures information about a specific word in the source sentence.
-
Decoding with Attention: While generating each word of the target sentence, the decoder RNN calculates attention scores for each hidden state of the encoder. These scores indicate the relevance of each source word to the current target word.
-
Context Vector: A weighted sum of the encoder's hidden states is computed, where the attention scores determine the weights. This results in a context vector that encapsulates the most relevant information from the source sentence for generating the current target word.
-
Predicting the Next Word: The context vector is concatenated with the decoder's hidden state, and this combined representation is used to predict the next word in the target sentence.
Benefits of Attention-Based Translation
-
Improved Translation Quality: Attention mechanisms allow the model to focus on relevant parts of the source sentence, leading to more accurate translations.
-
Handling Variable-Length Sentences: Attention-based models can handle source and target sentences of varying lengths, making them versatile for different language pairs and tasks.
-
Interpretability: Attention scores provide insights into which source words were most influential in generating each target word, making the translation process more interpretable.
Integrating attention mechanisms with RNNs has given rise to popular architectures like "Bahdanau Attention" and "Luong Attention", each with variations and improvements.
Training and Evaluation of Translation Models
Training and evaluation are critical steps in building and assessing translation models' performance, whether based on Recurrent Neural Networks (RNNs) with attention mechanisms or more modern architectures like Transformers. This guide will cover the key steps and considerations for training and evaluating translation models.
Training Translation Models
Data Preparation:
-
Data Collection: Gather parallel text data in source and target languages. These are sentence pairs where each source sentence has a corresponding translation in the target language. Large and diverse datasets are crucial for training robust models.
-
Data Cleaning and Preprocessing: Clean and preprocess the text data. This includes tokenization, lowercasing, and handling special characters. Also, split your dataset into training, validation, and test sets.
Model Architecture:
-
Choose an Architecture: Decide on the neural network architecture for your translation model. You can use traditional Seq2Seq models with attention mechanisms, but modern models like Transformer-based architectures (e.g., BERT, GPT, or their variants designed for translation) are often more effective.
-
Embeddings: Initialize word embeddings (e.g., word2vec, GloVe, or contextual embeddings like BERT embeddings) for both source and target languages. These embeddings capture semantic information.
-
Define Encoder and Decoder: In the case of Seq2Seq models, define the encoder and decoder architectures. Use a pre-trained model for Transformers and fine-tune it on your translation data.
Hyperparameter Tuning:
- Hyperparameter Selection: Tune hyperparameters such as learning rate, batch size, model depth, and attention mechanism settings. Consider using techniques like learning rate schedules and early stopping.
Training:
-
Training: Loss Function: Choose an appropriate loss function, typically a cross-entropy loss for sequence-to-sequence tasks.
-
Training Procedure: Train the model on the training data using backpropagation and optimization algorithms (e.g., Adam, SGD). Monitor the loss on the validation set to prevent overfitting.
-
Regularization: Apply dropout, layer normalization, and other regularization techniques to prevent overfitting.
-
Beam Search: For decoding, use techniques like beam search to improve the quality of generated translations during inference.
Evaluation of Translation Models
Metrics:
-
BLEU Score: The BLEU (Bilingual Evaluation Understudy) score measures the similarity between the generated translation and one or more reference translations. It's a widely used metric for translation evaluation.
-
ROUGE Score: ROUGE (Recall-Oriented Understudy for Gisting Evaluation) evaluates the quality of summaries or translations by comparing them to reference translations.
-
METEOR Score: METEOR (Metric for Evaluation of Translation with Explicit ORdering) is another metric considering precision, recall, stemming, synonyms, and more.
Cross-Lingual Evaluation:
-
Zero-shot Translation: Test the model's performance on language pairs it wasn't explicitly trained on (zero-shot translation). This assesses the model's generalization capability.
-
In-Domain Evaluation: Evaluate the model's performance on specific domains or topics relevant to your application.
-
Fine-Tuning: If necessary, fine-tune your model on domain-specific data or use reinforcement learning to improve translation quality further.
Implementing Translation with RNN and Attention
Creating a machine translation system with Recurrent Neural Networks (RNNs) and attention mechanisms is a fascinating deep learning task.Lets take an example where english sentence is translated to spanish using neural machine translation with attention tensorflow.
Step 1. Importing Libraries
In this section, you import necessary libraries for working with TensorFlow and natural language processing. This includes NumPy for numerical operations, TensorFlow for machine learning, and various modules from Keras (which is integrated into TensorFlow) for defining and training neural networks.
Step 2. Sample Dataset:
Here, you define a small sample dataset for English-to-Spanish translation. It includes pairs of English and Spanish sentences.
Step 3. Tokenization and Preprocessing:
In this section, you tokenize and preprocess the input and target sentences (English and Spanish). Tokenization involves converting text sentences into sequences of numerical tokens. The Tokenizer class from Keras is used for this purpose.
Special tokens "start" and "end" are added to the Spanish vocabulary to indicate the start and end of sentences.
Step 4. Padding Sequences
Here, you pad the sequences to a fixed length (max_seq_length) to ensure that all input and target sequences have the same length. Padding is done using the 'post' method, which adds zeros at the end of sequences.
The 'decoder_target_data' is created as one-hot encoded data to be used during training.
Step 5. Defining the Model
This section defines a sequence-to-sequence neural network model for translation. It consists of an encoder and a decoder.
The encoder processes the input sequences, and the decoder generates output sequences. An attention mechanism is used to improve translation quality.
Step 6. Compiling the Model
Here, you compile the model, specifying the optimizer, loss function, and metrics for training.
Step 7. Training the Model
This part trains the model using the provided dataset.

Step 8. Inference Code
This function is used for translating new input sentences using the trained model. It takes an English input sentence, tokenizes and pads it, and generates a Spanish translation.
Step 9. Example Usage
Finally, this section demonstrates how to use the translate_sentence function to translate an input sentence and print the results.

Advanced Techniques and Variations
Model Architectures: 1)Transformer-Based Models:
- Transformers like BERT and GPT have revolutionized machine translation.
- Models such as T5 and BERT for sequence-to-sequence tasks excel in translation.
- Self-attention mechanisms capture contextual information efficiently.
2)Multilingual Models:
- Multilingual models handle multiple languages in a single model.
- Efficient for low-resource languages and diverse language
- Examples include Google's M4 and Facebook's mBART.
3)Zero-Shot and Few-Shot Translation:
- Some models perform zero-shot translation across untrained language pairs.
- Few-shot translation involves training on a small amount of data for a new language pair.
- Enables flexibility and adaptability in translation tasks.
Training and Adaptation: 1)Transfer Learning and Fine-Tuning:
- Transfer learning pre-trains models on large datasets, followed by fine-tuning.
- Effective for improving performance with limited training data.
- Reduces the need for extensive parallel corpora.
2)Bidirectional Models:
-
Bidirectional models read text both left-to-right and right-to-left.
-
Enhance context capture and understanding.
-
Adapted for translation tasks, such as BERT-based translation.
3)Unsupervised and Self-Supervised Learning:
- Unsupervised and self-supervised approaches reduce reliance on parallel corpora.
- Valuable for low-resource languages and unsupervised translation.
- Leverages monolingual data for training.
Techniques and Applications: 1)Domain Adaptation:
- Fine-tuning models on domain-specific data improves translation quality.
- Tailors models for specialized fields like medicine or finance.
- Enhances accuracy and fluency in domain-specific translations.
2)Post-Editing and Human-in-the-Loop Systems:
- Combining machine translation with human post-editing enhances quality.
- Speeds up the translation process while ensuring accuracy.
- Effective for professional translation services.
3)Neural Machine Translation with Reinforcement Learning:
- Reinforcement learning fine-tunes models based on specific objectives.
- Optimizes translation for fluency, adequacy, or other criteria.
- Refines model performance through reinforcement.
These categories encompass various advanced techniques and approaches in neural machine translation, providing insights into model architectures, training strategies, and practical applications. Depending on specific translation requirements, these techniques can be leveraged to improve translation quality, efficiency, and adaptability.
Conclusion
In the realm of Natural Language Processing, Neural Machine Translation has witnessed a remarkable transformation, largely propelled by the advent of attention mechanisms. As we've journeyed through this exploration, several crucial takeaways have emerged:
-
The Evolution of Translation: The integration of deep learning and attention mechanisms has ushered in a new era of translation, enabling models to understand and convey language nuances with unprecedented accuracy.
-
RNNs as the Foundation: Recurrent Neural Networks (RNNs) stand as the cornerstone of machine translation, empowering models to capture the essence of sequential data and build a profound understanding of language.
-
The Seq2Seq Paradigm: The Seq2Seq approach, powered by RNNs, has revolutionized translation. It encapsulates the essence of translation by encoding source sentences and decoding them into target languages.
-
The Power of Attention: Attention mechanisms have emerged as a game-changer, addressing the challenges of long sequences and elevating contextual comprehension. They offer a dynamic and focused approach to translation.
-
Training and Beyond: The training and evaluation of translation models involve meticulous data preparation, model design, hyperparameter tuning, and rigorous assessment. Metrics like BLEU, ROUGE, and METEOR provide vital insights into translation quality.
-
Advanced Horizons: Advanced techniques such as Transformer-based models and multilingual approaches have expanded the horizons of machine translation, making it adaptable and versatile.
-
Practical Applications: In real-world scenarios, machine translation finds applications in domain adaptation, post-editing, and collaborative human-in-the-loop systems. These applications cater to specific needs and optimize the translation process.
Neural Machine Translation with Attention in TensorFlow represents not just a technological advancement, but a bridge between languages and cultures. As research continues and technology evolves, we can look forward to even more accurate, context-aware, and versatile translation systems that facilitate global communication and understanding. The journey of innovation in machine translation is far from over, and the future holds promising opportunities for further breakthroughs.