Parameter Server Training in TensorFlow
Overview
Training large models with vast datasets has become the norm in machine learning and deep neural networks. To expedite this training process, distributed training methods have gained prominence. One such approach is Parameter Server Training, which offers an efficient way to train models on distributed computing resources. This article explores the concept of Parameter Server Training, its architecture, setup, benefits, challenges, and a comparison with other distributed training methods.
What is Parameter Server Training?
Parameter Server Training is a distributed training technique employed in machine learning and deep neural networks. It addresses the challenge of training large models effectively by leveraging the power of distributed computing resources. This approach separates the storage of model parameters from the computation nodes responsible for training, leading to enhanced scalability, resource utilization, and training efficiency.
In Parameter Server Training, the central concept revolves around a parameter server, a repository for storing and managing the model parameters. This server serves as a communication hub facilitating interaction between computation nodes, often called workers, and the central repository of parameters.
The training process involves a collaborative effort between the parameter server and the worker nodes. Workers fetch the required model parameters from the parameter server, perform computations using these parameters, calculate gradients, and then communicate the gradients back to the parameter server.
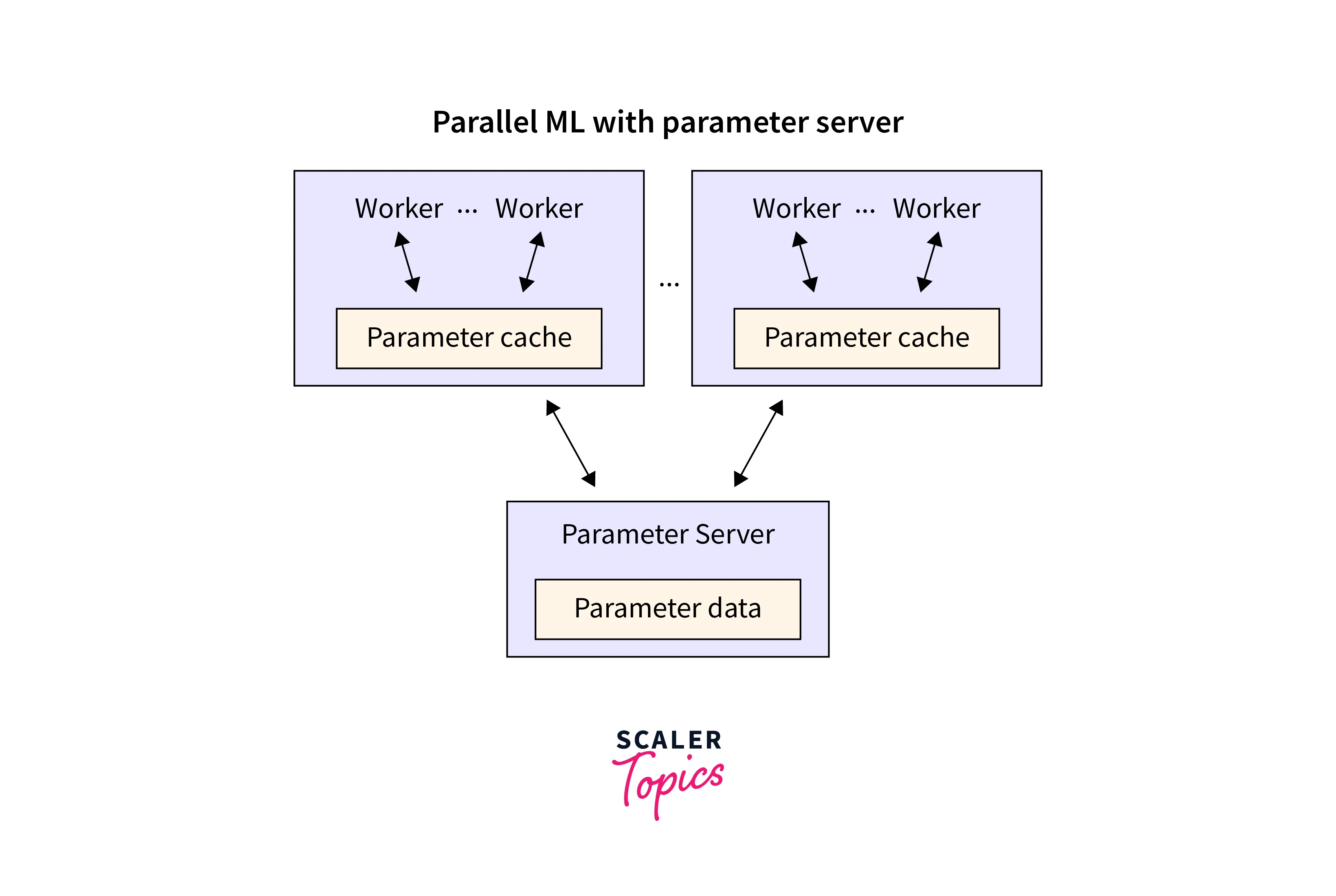
Parameter Server Architecture:
Parameter Server Architecture is the foundation of Parameter Server Training, a distributed training technique that efficiently trains machine learning models across multiple computing nodes. This architecture divides the responsibilities of managing model parameters and executing computations, allowing for scalable and efficient training.
Let's delve into the key components and interactions within the Parameter Server Architecture:
-
Parameter Server:
The central element of the architecture is the parameter server. It serves as the repository for storing and managing model parameters. The parameter server is a hub coordinating the communication between worker nodes and the central parameter storage. Parameter servers can operate in synchronous or asynchronous modes depending on the synchronization strategy.-
Synchronous Parameter Server:
In this mode, the parameter server synchronizes updates from workers at specific intervals. Workers communicate their computed gradients to the parameter server, and the server aggregates the gradients to update the model parameters. This synchronization ensures consistent updates across workers. -
Asynchronous Parameter Server:
Workers asynchronously fetch and update parameters from the parameter server without strict synchronization intervals. While this approach can lead to faster training due to reduced waiting time, it also introduces challenges related to parameter consistency and communication overhead.
-
-
Worker Nodes:
Worker nodes are responsible for performing the actual training computations. Each worker fetches the necessary model parameters from the parameter server, computes gradients based on the training data it processes, and then communicates the gradients back to the parameter server. The parameter server uses the aggregated gradients to update the model parameters. -
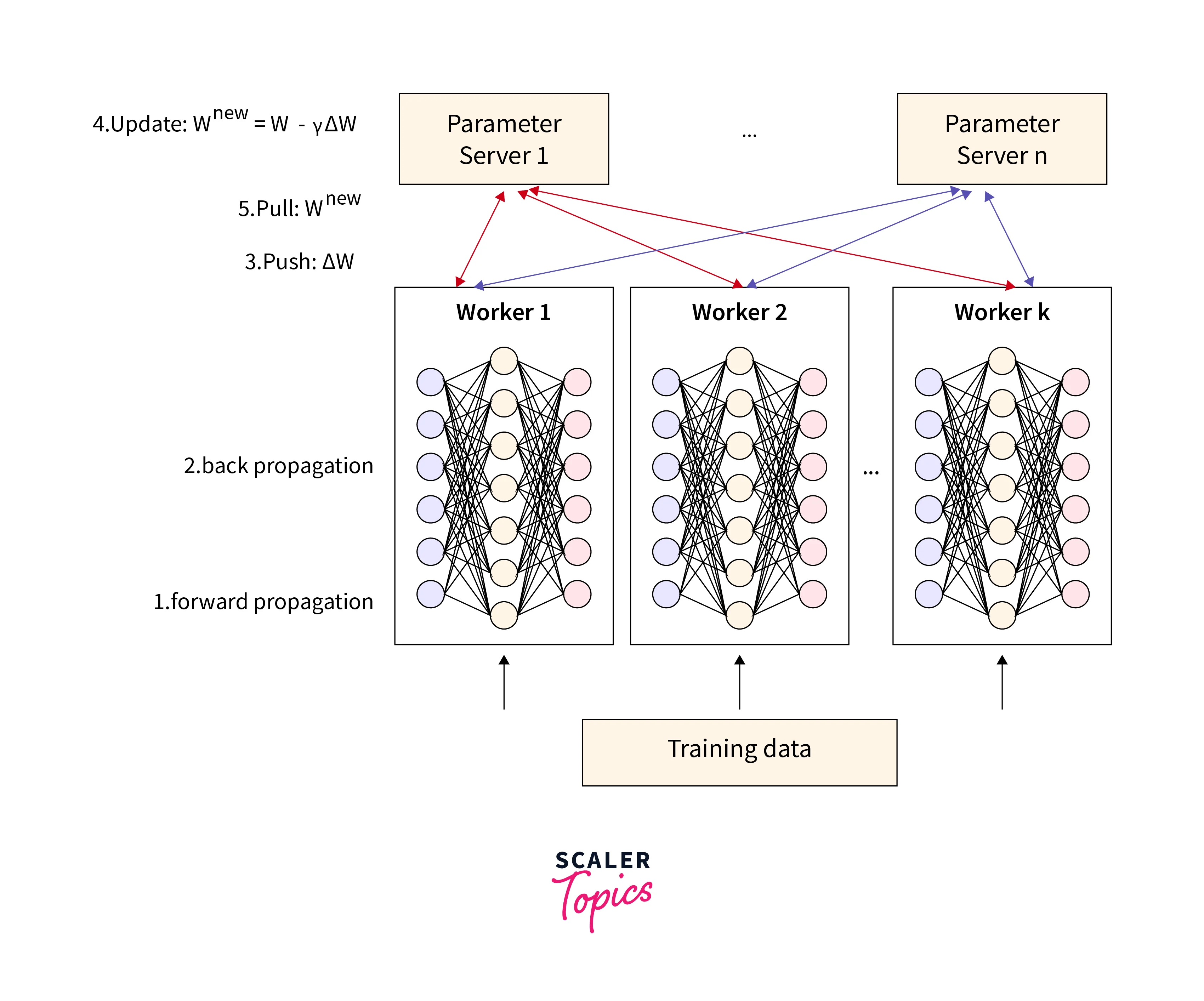
Training Loop:
The training process follows a repetitive loop involving communication between workers and the parameter server:- Workers fetch model parameters from the parameter server.
- Workers perform computations on their assigned data batches.
- Workers calculate gradients based on their computations.
- Workers communicate the gradients back to the parameter server.
- The parameter server aggregates gradients and updates model parameters.
- The loop repeats for the desired number of epochs.
Setting Up Parameter Server Training
Setting up Parameter Server Training involves initializing the parameter server, and defining the communication between worker nodes and the parameter server. Below are the steps to set up Parameter Server Training for a machine-learning model:
Step - 1: Import Libraries
Import the required libraries for your chosen framework and the dataset you intend to use.
Step - 2: Load and Preprocess Data
Load the dataset you'll use for training. In this example, we'll use the Fashion MNIST dataset. Preprocess the data by normalizing pixel values and splitting it into batches.

Step - 3: Define Model and Parameter Server
Create your machine learning model and define the parameter server. The parameter server strategy encapsulates the model creation within its scope.
Training Models with Parameter Server
In this section, we will walk through a practical example of training a neural network using the Parameter Server architecture. We will use the TensorFlow model that we created before to implement the training process.
-
Step - 1: Define Training Step:
Define a function that encapsulates the training step. This function will be executed on worker nodes. -
Step - 2: Training Loop:
Implement the training loop that fetches data, performs training steps, and updates parameters on the parameter server. -
Step - 3: Evaluation:
Evaluate the trained model's performance using a test dataset.Output:
Comparison with Other Distributed Training Approaches
Parameter Server Training is a distributed training technique used to train machine learning models across multiple computing nodes. Let's compare Parameter Server Training with two other common approaches: Data Parallelism and Model Parallelism.
1. Scalability
- Parameter Server:
Scales well for both model size and dataset size. Efficient memory utilization. - Data Parallelism:
Scales well for dataset size but can be memory-intensive for large models. - Model Parallelism:
Scales well for extremely large models but requires careful partitioning.
2. Communication
- Parameter Server:
Communication between workers and server can lead to overhead, especially asynchronously. - Data Parallelism:
Communication mainly involves parameter updates, which can lead to synchronization bottlenecks. - Model Parallelism:
Communication between model segments can impact training speed.
3. Training Speed
- Parameter Server:
Asynchronous updates can speed up training. Synchronous updates slow down due to waiting. - Data Parallelism:
Synchronous updates lead to more consistent progress but may introduce delays. - Model Parallelism:
Training speed depends on inter-segment communication.
4. Implementation Complexity
- Parameter Server:
Easier to implement due to centralized parameter management. - Data Parallelism:
Moderately complex due to synchronization and potential load balancing. - Model Parallelism:
Complex due to partitioning and coordination challenges.
5. Suitability
- Parameter Server:
Good for various model sizes and dataset sizes, particularly when resources are distributed. - Data Parallelism:
Well-suited for synchronous training with moderate resource availability. - Model Parallelism:
Specialized approach for extremely large models that can't fit in memory.
Optimizing Parameter Server Training
Optimizing Parameter Server Training involves fine-tuning hyperparameters, adjusting communication frequency, and implementing strategies to handle challenges such as communication overhead. Here are some key optimization strategies:
- Batch Size:
Adjust the batch size to balance training speed and memory usage. Larger batch sizes can lead to faster convergence but require more memory. Experiment with different batch sizes to find the optimal balance. - Learning Rate and Scheduling:
Fine-tune the learning rate and consider using learning rate schedules. Adaptive learning rate techniques such as Adam or RMSProp can help optimize convergence speed and stability. - Communication Frequency:
Balancing communication between workers and the parameter server is crucial. Frequent communication can lead to overhead, while infrequent communication can slow down convergence. Experiment with communication frequency to find the optimal trade-off. - Warm-up Phase:
Implement a warm-up phase where workers perform initial training steps independently before synchronizing with the parameter server. This can help in the impact of slow parameter server initialization.
Challenges and Considerations in Parameter Server Training
Parameter Server Training is a powerful distributed training technique, but it comes with challenges and considerations. Successfully navigating these challenges is crucial for achieving efficient and reliable distributed model training. Here's an exploration of the key challenges and considerations associated with Parameter Server Training:
- Communication Overhead:
Frequent communication between workers and the parameter server can lead to performance degradation, particularly in asynchronous setups. Optimize communication frequency and use compression techniques to reduce overhead. - Fault Tolerance:
Node failures can disrupt training. Implement backup nodes or redundancy strategies to ensure continuity in the face of failures. - Parameter Inconsistency:
Asynchronous updates may cause worker parameter inconsistencies, affecting convergence. Mitigate this with staleness control techniques to manage outdated parameters. - Stragglers:
Slow workers can impede training progress. Implement load balancing, adaptive scheduling, or dynamic batch adjustments to handle stragglers effectively. - Synchronization:
Synchronous training requires workers to wait for updates—Fine-tune synchronization intervals to balance training speed and parameter freshness. - Network Bandwidth:
Limited network bandwidth can hinder communication. Monitor usage and utilize compression to alleviate bandwidth limitations.
Conclusion
- Parameter Server Training efficiently trains models on distributed resources.
- Architecture involves parameter server and worker nodes.
- Benefits include scalability, efficiency, and adaptability.
- Optimization involves batch size, learning rate, and communication.
- Challenges encompass communication, fault tolerance, and consistency.