Text Classification with RNN
Overview
RNN for Text classification in natural language processing (NLP) tasks involves categorizing text content according to predetermined categories. Recurrent neural networks (RNNs) are a powerful method for tackling text classification issues. RNNs for text classification are particularly effective in modeling sequential data, considering word relationships and context. They are suited for text analysis due to their loop-based loops, allowing information to remain over time.
Introduction
A vast amount of textual material is produced and consumed every day in the current digital era. Text documents offer significant information that may be used for a variety of purposes, from social media postings and news stories to customer evaluations and emails. Making sense of this enormous volume of unstructured text data, however, is a difficult task undertaking. RNN for Text classification is used in this situation. The technique of automatically classifying or categorizing text documents is referred to as text classification or text categorization. RNN for text classification has several applications and is a critical issue with natural language processing (NLP). By effectively categorizing text, we may extract insights, comprehend sentiment, identify themes, detect spam, and facilitate effective information retrieval.
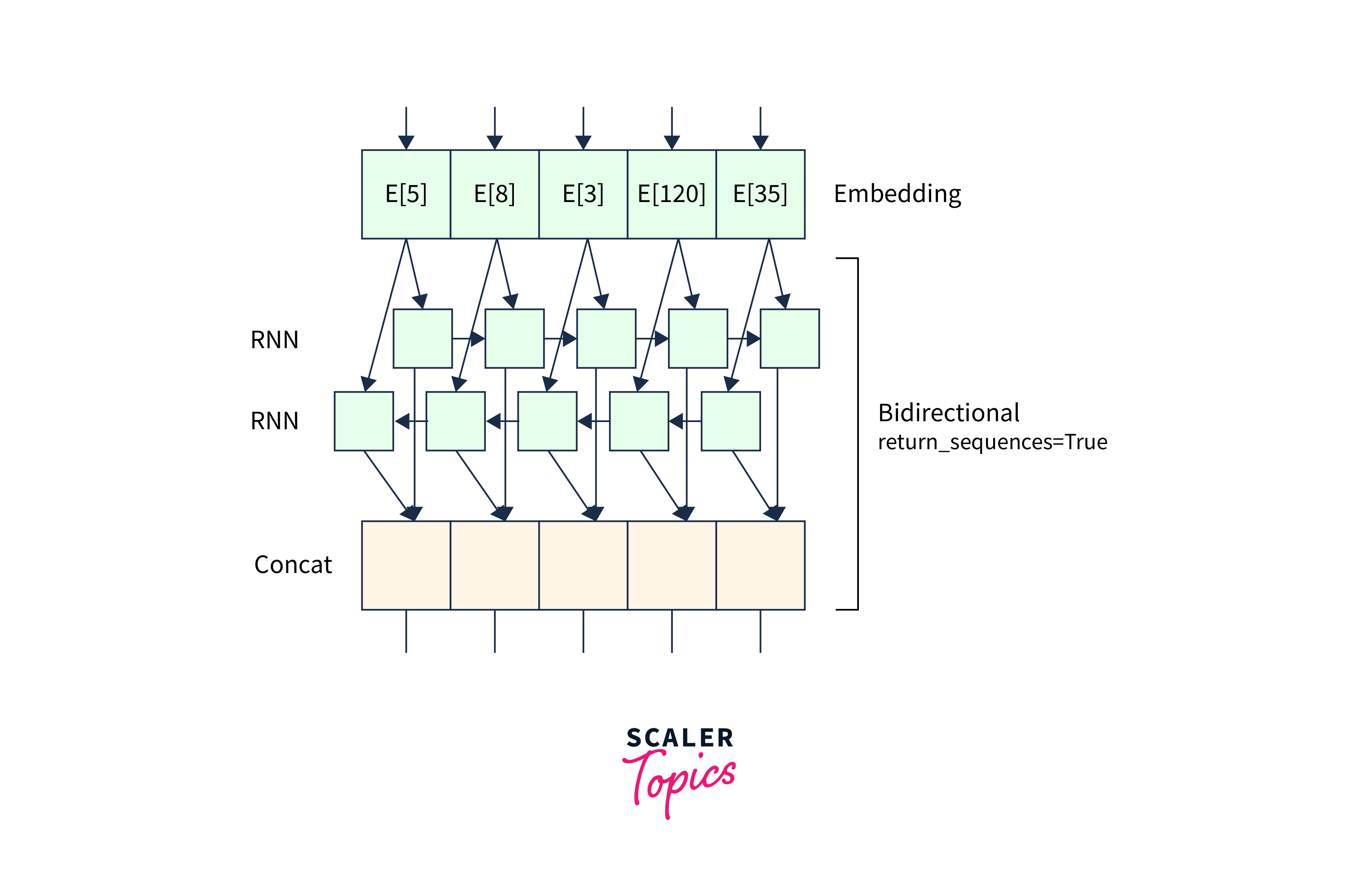
What is Text Classification?
Assigning predetermined groups or labels to text documents is known as text classification, sometimes known as text classification, and is a key activity in natural language processing (NLP). It is a type of supervised learning in which computer vision models are trained on labeled examples to categorize fresh, unexplored text input.
To organize, retrieve, and analyze textual material effectively, text classification aims to automatically analyze and categorize text documents based on their content. By giving the text the right labels or categories, we may extract useful insights, make it easier to find information, automate decision-making, and allow a variety of downstream applications.
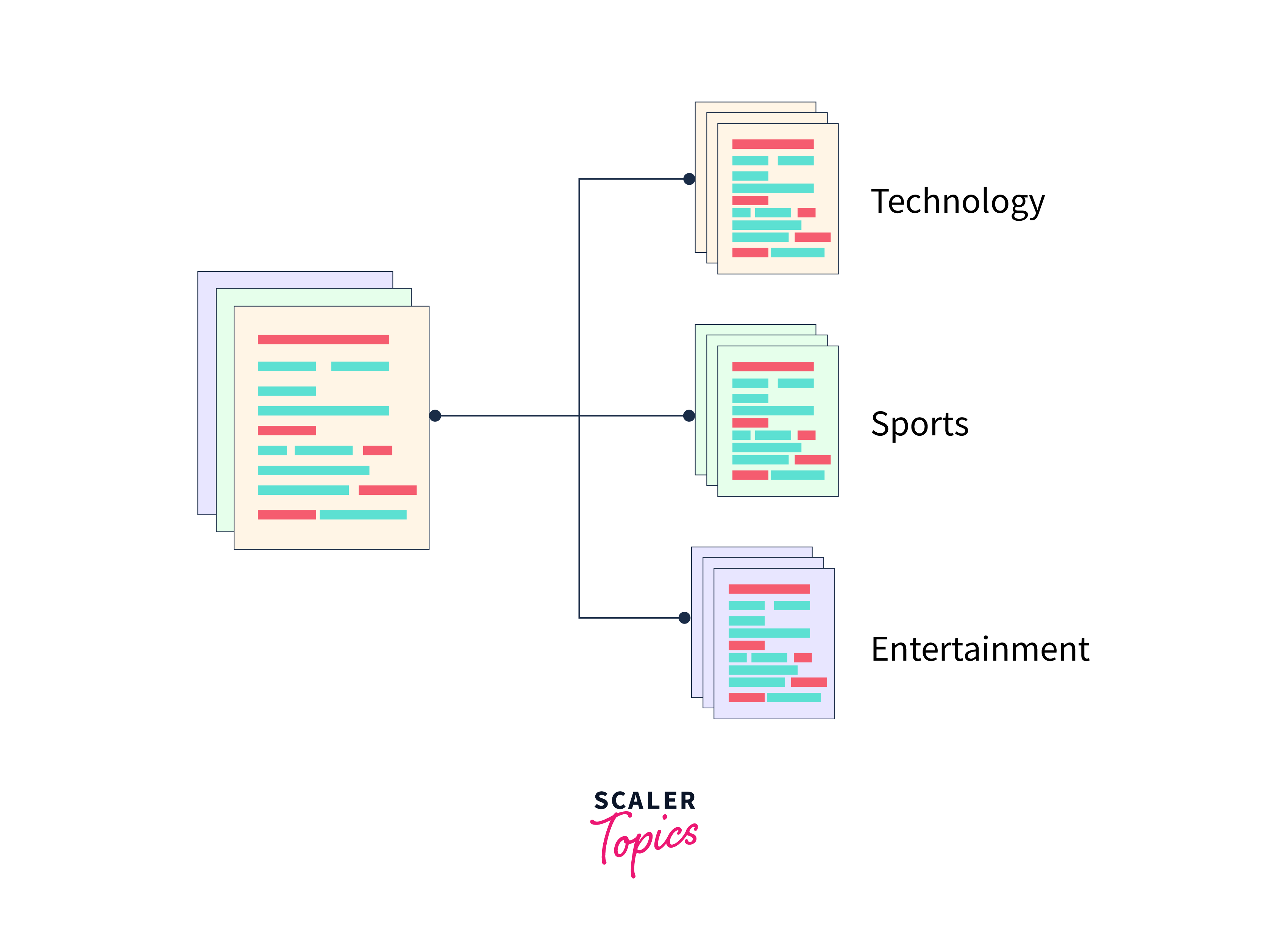
In text classification, the categories or labels reflect certain groupings or subjects to which the texts may belong and are often preset. Depending on the particular application, these categories might be either wide or detailed. In sentiment analysis, for instance, the categories might be positive, negative, or neutral, while in topic classification, the categories can reflect various subject areas like sports, politics, technology, or entertainment.
Machine learning algorithms use characteristics taken from text documents to accomplish text classification. These characteristics may be straightforward, like word frequencies or the presence or absence of certain keywords, or they may be more intricate, like word embeddings or contextual representations. The difficulty of the classification job and the availability of appropriate representations for text data influence the choice of characteristics.
Text Classification with RNN using TensorFlow
Natural language processing (NLP) is frequently used for text classification, which is categorizing or labeling text content according to predetermined standards. Recurrent Neural Networks (RNN for text classification) have been demonstrated to be effective models for encapsulating the sequential nature and contextual relationships contained in text data.

In this article, we'll look at how to use the well-known deep learning framework TensorFlow to create RNN for text classification.
The stages we'll go through for utilizing RNNs and TensorFlow to classify text are as follows:
a. Getting the Text Data Ready:
- The text data and associated labels should be loaded.
- Remove punctuation from data and perform preprocessing operations like tokenization and lowercasing.
- Create training and test sets from the data.
b. Creating an RNN Text Classification Model:
- Pick a suitable RNN architecture, such as LSTM or GRU.
- Utilise Keras, the high-level API for TensorFlow, to specify the network design.
- Indicate the model's input and output dimensions.
- Set the model's activation, loss, and optimizer functions appropriately.
c. RNN Model Training and Evaluation:
- Feed the RNN model with the preprocessed data.
- Set the training settings, such as the batch size and epoch count.
- Utilise validation data to keep track of the model's performance throughout training.
- Using gradient descent and backpropagation, modify the model's weights.
- Utilise the testing dataset to evaluate the trained model's performance.
- Calculate evaluation measures such as F1 score, recall, accuracy, and precision.
- Examine the predictions made by the model and note any shortcomings.
Dealing with Imbalanced Classes
Unbalanced classes—where some categories have a noticeably higher or lower number of instances relative to others—are frequently seen in text classification tasks. When training a model, unbalanced classes might be difficult since the model may start to favor the majority class and struggle to correctly categorize minority classes.
We may use several strategies to handle the problem of unbalanced classes in text classification using RNNs using TensorFlow. Here are a few sensible tactics:
Step 1. Resampling data:
Oversampling: By producing duplicate or fake samples, increase the number of examples in the minority class. This can be accomplished using strategies such as random oversampling, synthetic minority over-sampling method (SMOTE), or adaptive synthetic sampling (ADASYN).
Reduce the number of instances in the majority class by deleting samples at random. Maintaining the minority class' representation should be done with care. Cluster centroids and random undersampling are two undersampling methods.
Step 2. Weighting by class:
During model training, give the minority class more weight. This enables the model to focus more on the minority class and modify its learning as necessary. Class weights can be provided in the loss function of TensorFlow or while building a model.
Step 3. Threshold Modification:
Change the classification determination threshold in the minority class's favor. By reducing the threshold, even if it leads to more false positives, the model is more likely to categorize occurrences as belonging to the minority class. Depending on the particular requirements of the classification task, this trade-off might be modified.
Step 4. Ensemble Techniques:
To generate predictions collectively, ensemble approaches mix many models. Ensemble approaches like bagging, boosting, or stacking can be used to classify unbalanced text. These methods can assist in identifying various trends and enhance general performance, particularly for minority classes.
Step 5. Evaluation metrics:
Use assessment measures that are more appropriate for unbalanced classes. Accuracy by itself might not paint the whole picture, particularly when courses are severely unbalanced. More thorough insights into model performance may be gained by using metrics like accuracy, recall, F1 score, and area under the Receiver Operating Characteristic (ROC) curve.
Transfer Learning with Pre-Trained Word Embeddings
Word embeddings are vector representations of individual words that store contextual and semantic data. They are discovered using unsupervised methods like Word2Vec, GloVe, or FastText from massive volumes of textual data. Through transfer learning, this pre-trained word embeddings may be used in text classification tasks since they capture rich linguistic patterns.
We may use the knowledge we receive from one task or dataset to do better on a related task or dataset by using transfer learning. Transfer learning using pre-trained word embeddings can provide the following advantages when used with RNNs and TensorFlow for text classification:
Step 1. Dealing with Data Scarcity
Pre-trained word embeddings offer a useful resource to initialize the embedding layer of the RNN model when the amount of labeled text input is scarce. The model can benefit from a richer representation of words and enhance its performance, even with little labeled data, by utilizing the information gained from a huge corpus of text.
Step 2. Semantic and Contextual Information Capture:
Word semantic and contextual information is stored in pre-trained word embeddings. They record connections, relationships, and the context of words, which helps the RNN model comprehend and generalize better. The model may make use of this rich information and learn more quickly by leveraging pre-trained embeddings.
Step 3. Cutting Back on Training Resources and Time:
It can be computationally costly to train word embeddings from scratch, especially for big vocabularies. We can drastically cut the training time and computer resources needed to train the RNN model by using pre-trained word embeddings. This makes it possible to experiment with various architectures and hyperparameters more quickly.
Follow these steps to add pre-trained word embeddings into your text classification model using RNNs and TensorFlow:
Step 1. Acquire Pre-Trained Word Embeddings:
Pre-trained word embeddings such as Word2Vec, GloVe, or FastText can be downloaded. These embeddings are often available in pre-trained models made public by the designers of the models. They are ready for use in your TensorFlow context.
Step 2. Create the Embedding Matrix:
Make an embedding matrix using your vocabulary. From the pre-trained word embeddings, each word in your vocabulary will have a matching vector representation. Initialize the embedding matrix using the pre-trained vectors for words that appear in both the pre-trained embeddings and the vocabulary of your dataset.
Step 3. Start the Embedding Layer:
Add an embedding layer to the RNN model architecture and initialize it with the embedding matrix established in the previous step. The input words will be mapped to their pre-trained vector representations by this layer.
Step 4. Frozen Embedding Layer:
Freeze the embedding layer during training to keep the pre-trained word embeddings. The model is prevented from updating the word vectors during backpropagation, ensuring that the learned representations are preserved.
Step 5. RNN Model Training:
With the pre-trained word embeddings, train the RNN model. Depending on the availability of labeled data and the difficulty of the classification job, the additional layers of the RNN model, such as the LSTM or GRU layers, can be trained from scratch or initialized with pre-learned weights.
LSTM for Sequence Classification using TensorFlow
Text classification is a typical job in natural language processing (NLP) in which predetermined labels or categories are assigned to text sequences. Long Short-Term Memory (LSTM) networks, which are a form of Recurrent Neural Networks (RNN), have shown significant promise in capturing sequential relationships and context in text data.
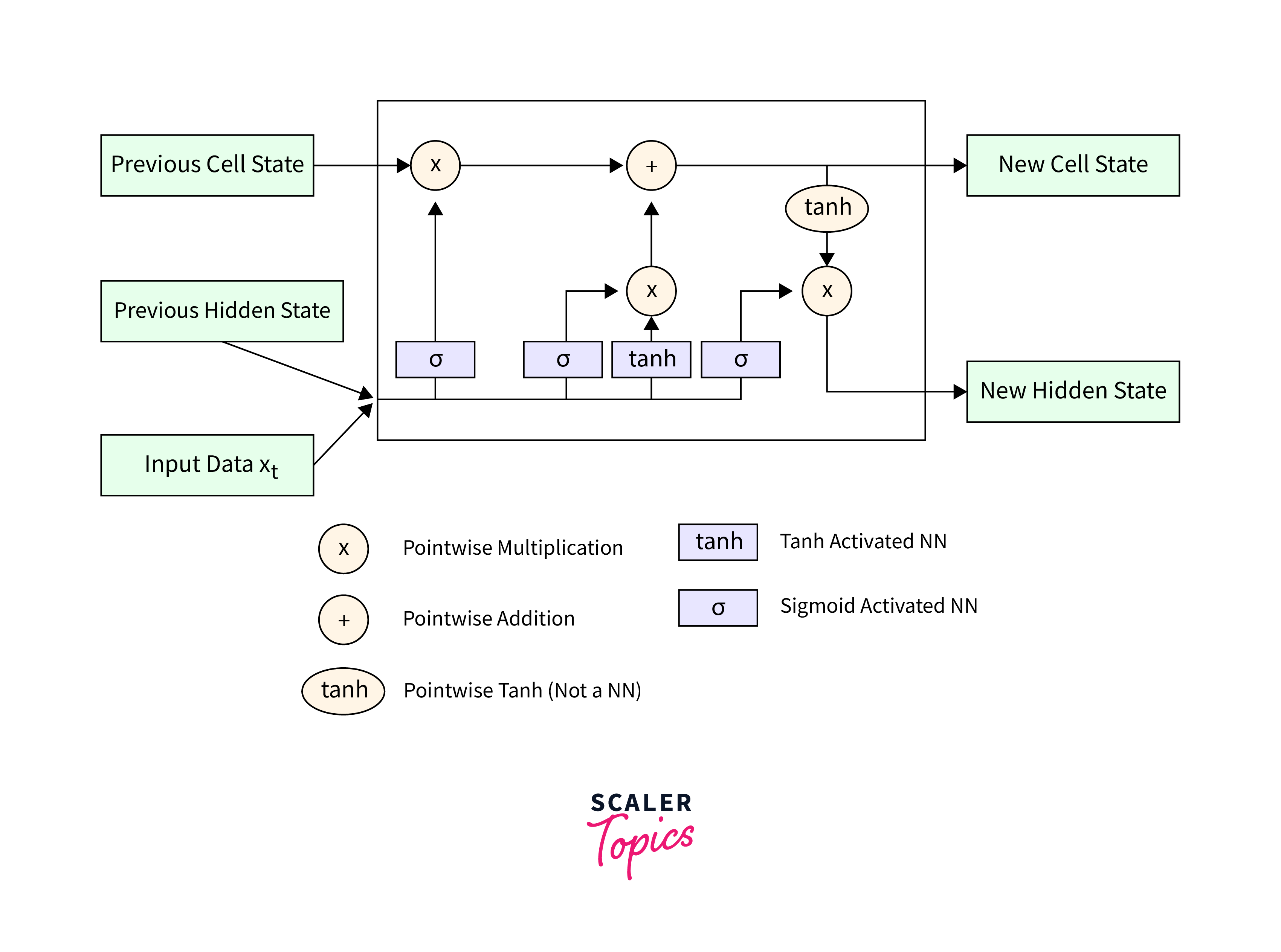
In this blog article, we will look at how to use TensorFlow, a prominent deep-learning framework, to create LSTM for sequence classification.
Here are the steps for implementing LSTM for sequence classification using TensorFlow:
Step 1. Text Data Preparation:
- Load the text data and associated labels.
- Tokenization and vectorization are two examples of essential preprocessing processes.
- Divide the data into two sets: training and testing.
Step 2. Creating an LSTM Text Classification Model:
- Create the LSTM model architecture with Keras, TensorFlow's high-level API.
- Specify the model's input shape and size.
- Configure the layers of the model, including the LSTM layer(s) and the output layer.
- Select the best activation functions, regularisation approaches, and optimization methodology.
Step 3. LSTM Model Training and Evaluation:
- Fill the LSTM model with the preprocessed data.
- Define the training parameters, such as epoch count and batch size.
- Using validation data, track the model's performance during training.
- Backpropagation and gradient descent are used to update the model's weights.
- Using the testing dataset, assess the performance of the trained LSTM model.
- Evaluate measures including accuracy, precision, recall, and F1 score.
Now, let's go through each step in detail and see how to use TensorFlow to create LSTM for sequence classification.
Step 1. Text Data Preparation:
Before we begin, we must prepare the text data for LSTM-based sequence classification. Loading the text input, conducting appropriate preprocessing processes such as tokenization and vectorization, and separating the data into training and testing sets are all part of this process.
Step 2. Creating an LSTM Model for Text Classification:
After preparing the data, we may create the LSTM model architecture for sequence classification. This comprises setting the model's input form and size, configuring the LSTM layer(s), and selecting appropriate activation functions, regularisation approaches, and optimization algorithms.
Step 3. Training and Evaluating the LSTM Model:
Now that the model architecture has been determined, we may proceed to train and evaluate the LSTM model. This includes feeding the preprocessed data into the model, specifying training parameters such as the number of epochs and batch size, monitoring the model's performance with validation data, updating the model's weights via backpropagation, and evaluating its performance with the testing dataset.
GRU with Sentiment Analysis
Sentiment analysis is a prominent natural language processing (NLP) tool that attempts to discern the sentiment or opinion represented in a piece of text. A variation of Recurrent Neural Networks (RNNs), the Gated Recurrent Unit (GRU), has emerged as an effective model for sentiment analysis applications.
In this blog article, we will look at how to utilize TensorFlow, a popular deep-learning framework, to develop GRU for sentiment analysis.
Here are the steps for implementing GRU for sentiment analysis using TensorFlow:
Step 1. Text Data Preparation:
- Load the text data as well as the sentiment labels.
- Tokenization and vectorization are two examples of essential preprocessing processes.
- Divide the data into two sets: training and testing.
Step 2. Creating a Sentiment Analysis Model:
- Create the GRU model architecture with Keras, TensorFlow's high-level API.
- Specify the model's input shape and size.
- Configure the layers of the model, including the GRU layer(s) and the output layer.
- Select the best activation functions, regularisation approaches, and optimization methodology.
Step 3. Model Training and Evaluation:
- Fill the GRU model with the preprocessed data.
- Define the training parameters, such as epoch count and batch size.
- Using validation data, track the model's performance during training.
- Backpropagation and gradient descent are used to update the model's weights.
- Using the testing dataset, assess the performance of the trained GRU model.
- Evaluate measures including accuracy, precision, recall, and F1 score.
Now, let's go through each step in detail and see how to use TensorFlow to create GRU for sentiment analysis.
Step 1. Text Data Preparation:
To begin, we must prepare the text data for sentiment analysis with GRU. Loading the text input, conducting appropriate preprocessing processes such as tokenization and vectorization, and separating the data into training and testing sets are all part of this process.
Step 2. Sentiment Analysis Model Construction:
Once the data is ready, we may create the GRU model architecture for sentiment analysis. This comprises establishing the model's input form and size, configuring the GRU layer(s), and selecting appropriate activation functions, regularisation approaches, and optimization algorithms.
Step 3. Training and Evaluating the Model:
Now that the model architecture has been created, we may proceed to train and evaluate the GRU model. This includes feeding the preprocessed data into the model, specifying training parameters such as the number of epochs and batch size, monitoring the model's performance with validation data, updating the model's weights via backpropagation, and evaluating its performance with the testing dataset.
Training RNN Models for Text Classification
Text classification is a fundamental operation in natural language processing (NLP) that includes assigning predetermined groups or labels to text resources. Recurrent Neural Networks (RNNs) have emerged as excellent text classification models due to their ability to capture sequential relationships and context in text input. In this blog article, we will go through how to train RNN models for text classification step by step.
The following are the steps for training RNN models for text classification:
Step 1. Text Data Preparation
- Load the text data as well as the labels.
- Tokenization and vectorization are examples of essential preprocessing processes.
- Separate the data into two sets: training and testing.
Step 2. Developing an RNN Text Classification Model:
- Select an RNN architecture, such as LSTM or GRU.
- Use a deep learning framework such as TensorFlow or PyTorch to create the RNN model architecture.
- Enter the model's input shape and size.
- Set up the layers, activation functions, and optimization techniques for the model.
Step 3. RNN Model Training and Evaluation:
- Feed the RNN model the preprocessed data.
- Define the training parameters, such as epoch count and batch size.
- Using validation data, track the model's performance during training.
- Backpropagation and gradient descent are used to update the model's weights.
- Using the testing dataset, evaluate the trained RNN model's performance.
- Evaluate measures including accuracy, precision, recall, and F1 score.
Let's go through each step in detail and see how to train RNN models for text classification.
Step 1. Text Data Preparation:
First, we must prepare the text data for training our RNN model for text classification. This includes importing the text data and labels, conducting appropriate preprocessing processes such as tokenization and vectorization, and separating the data into training and testing sets.
Step 2. Creating an RNN Model for Text Classification:
Once the data is ready, we may construct the RNN model architecture for text classification. This includes selecting an appropriate RNN architecture, such as LSTM or GRU, designing the layers of the model using a deep learning framework, such as TensorFlow or PyTorch, specifying the input shape and dimensions of the model, and configuring the model's layers, activation functions, and optimization algorithm.
Step 3. Training and Evaluating the RNN Model:
Now that we've specified the model architecture, we can train and evaluate the RNN model for text classification. Feeding the preprocessed data into the RNN model, defining training parameters such as the number of epochs and batch size, monitoring the model's performance using validation data, updating the model's weights via backpropagation and gradient descent, evaluating its performance using the testing dataset, and calculating evaluation metrics such as accuracy, precision, recall, and F1 score are all part of this process.
Output

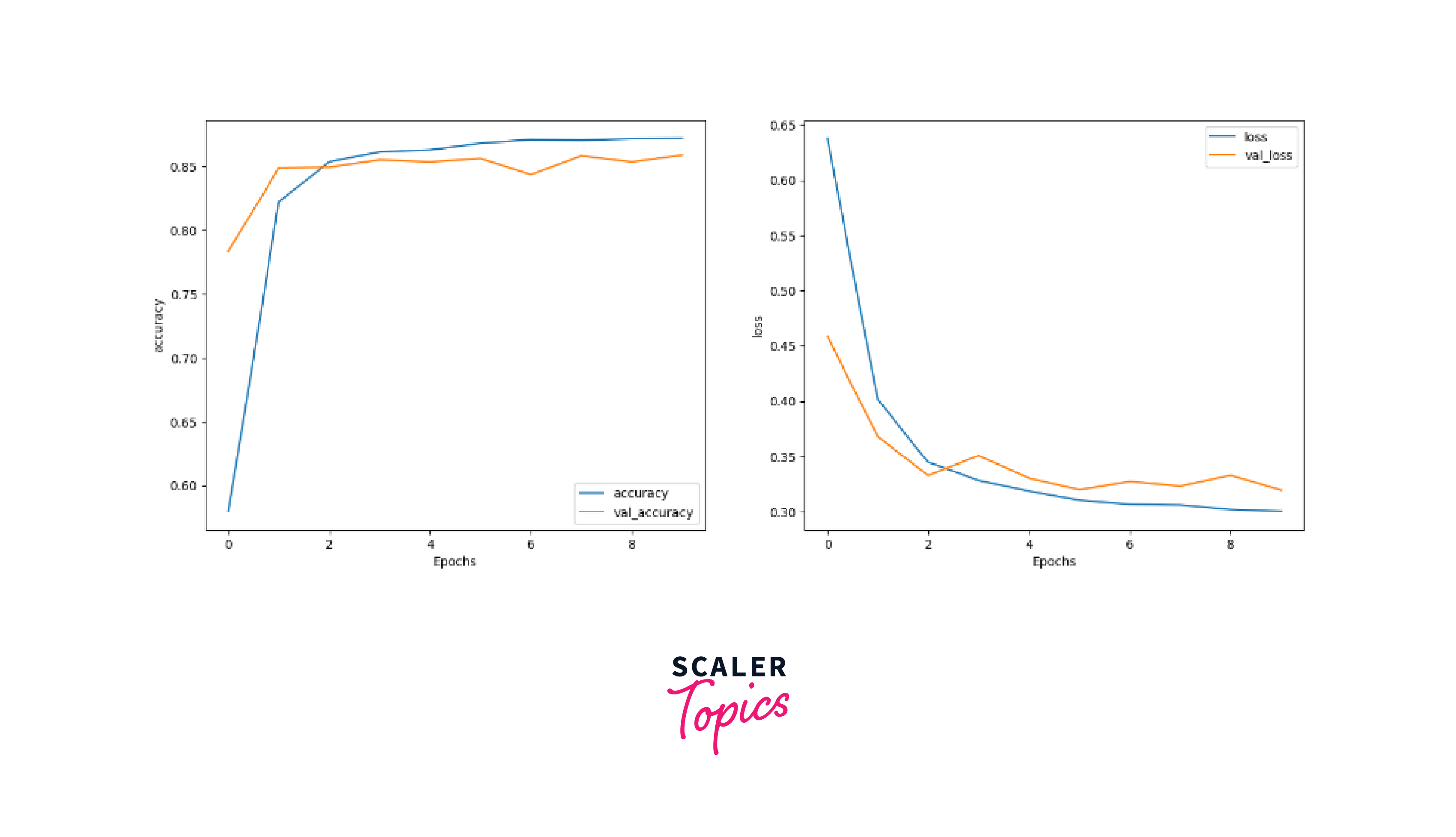
Conclusion
- RNNs for Text classification is a strong method for giving categories or labels to text documents.
- RNNs, such as LSTM and GRU, excel in capturing sequential dependencies and contextual information in text data.
- Text data preparation is critical, including preprocessing techniques such as tokenization, vectorization, and data separation.
- It is critical to optimize the RNN model by taking into account hyperparameters, regularisation approaches, and evaluation metrics.
- The trained RNN model may make predictions on fresh, previously unknown text data and glean insights from classified documents.
- Text classification results must be improved by continuous experimentation, examination, and refinement.