BERT using TensorFlow
Overview
In the ever-evolving field of natural language processing (NLP), BERT (Bidirectional Encoder Representations from Transformers) has emerged as a groundbreaking model. This guide explores BERT and its various applications using TensorFlow, including text classification, named entity recognition (NER), and language translation. The article breaks down the key concepts, steps, and end-to-end flows for each application, empowering readers to harness the power of BERT in their NLP projects.

Understanding BERT
BERT, Bidirectional Encoder Representations from Transformers, is a revolutionary natural language processing (NLP) model developed by Google AI in 2018. This model has significantly transformed the landscape of NLP by introducing a novel approach to pretraining and transfer learning.
- Bidirectional Contextual Understanding: Traditional language models, such as unidirectional LSTM and GPT (Generative Pre-trained Transformer), process text in a left-to-right or right-to-left manner, capturing only one side of the context. BERT, on the other hand, introduces bidirectional context by training the entire input sentence at once. This allows BERT to consider the surrounding words from both directions, leading to a deeper understanding of context and meaning.
- Transformers and Attention Mechanism: BERT is built upon transformer architecture, which has become the cornerstone of many recent advancements in NLP. Transformers are designed to handle data sequences while maintaining parallelism, making them highly efficient for training on modern hardware. The attention mechanism within transformers is central to BERT's ability to capture contextual relationships. Attention allows each word in a sequence to focus on all other words, taking into account their relevance. This mechanism is well-suited for capturing long-range dependencies and complex relationships between words.
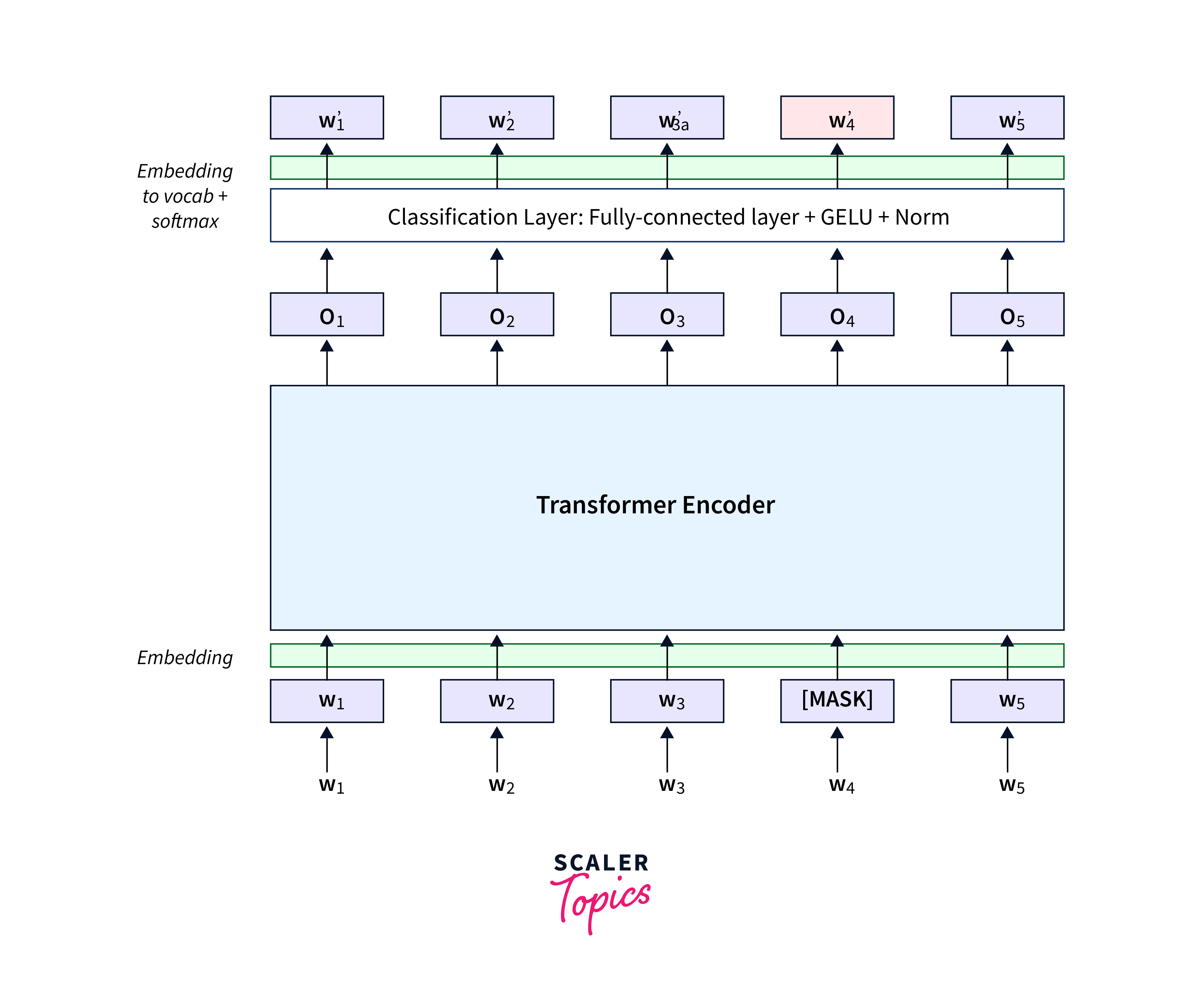
- Pretraining and Transfer Learning: BERT's training process involves pretraining and fine-tuning. In the pretraining phase, a large corpus of text is used to train the model on a masked language model (MLM) task. In this task, a percentage of the words in each sentence are randomly replaced with [MASK] tokens, and the model is trained to predict these masked words based on the surrounding context. During the fine-tuning phase, BERT is adapted to specific NLP tasks. The model is initialized with the weights learned during pretraining and then trained on task-specific labelled data. This transfer learning approach eliminates the need to train large models from scratch for each task, saving computational resources and time.
- Embeddings and Layers: BERT processes text through embeddings and multiple layers. The input text is tokenized into subword pieces or tokens, which are then mapped to corresponding embeddings. BERT uses positional embeddings to retain the order of tokens, which is crucial for understanding the structure of the text.
Preparing Data for BERT
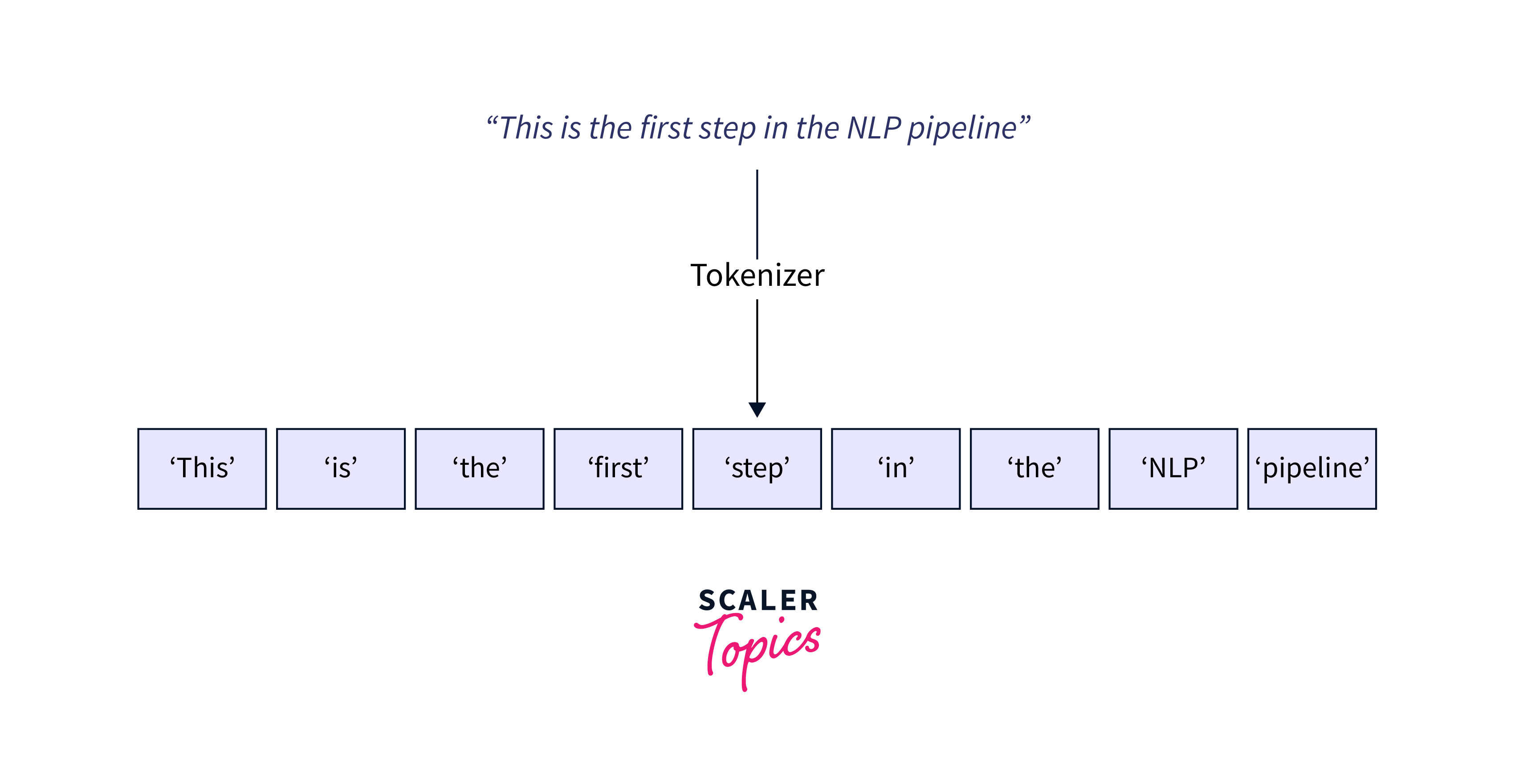
Preparing data for BERT involves several crucial steps to ensure the model can effectively learn and capture context. This includes tokenization, input formatting, and creating attention masks.
-
Step 1: Tokenization Tokenization involves breaking down raw text into small units, such as words or subwords. BERT uses WordPiece tokenization, where words are split into smaller subwords, allowing the model to handle out-of-vocabulary words.
-
Step 2: Input Formatting BERT requires specific formatting for its inputs. This includes adding special tokens like [CLS] (start of sequence) and [SEP] (end of sequence) to mark the beginning and end of sentences. Additionally, we need to segment input sequences if dealing with multiple sentences.
-
Step 3: Creating Attention Masks Attention masks help BERT distinguish between actual and padding tokens. Padding is added to make all input sequences the same length, but BERT should not pay attention to these padding tokens.
Fine-tuning BERT
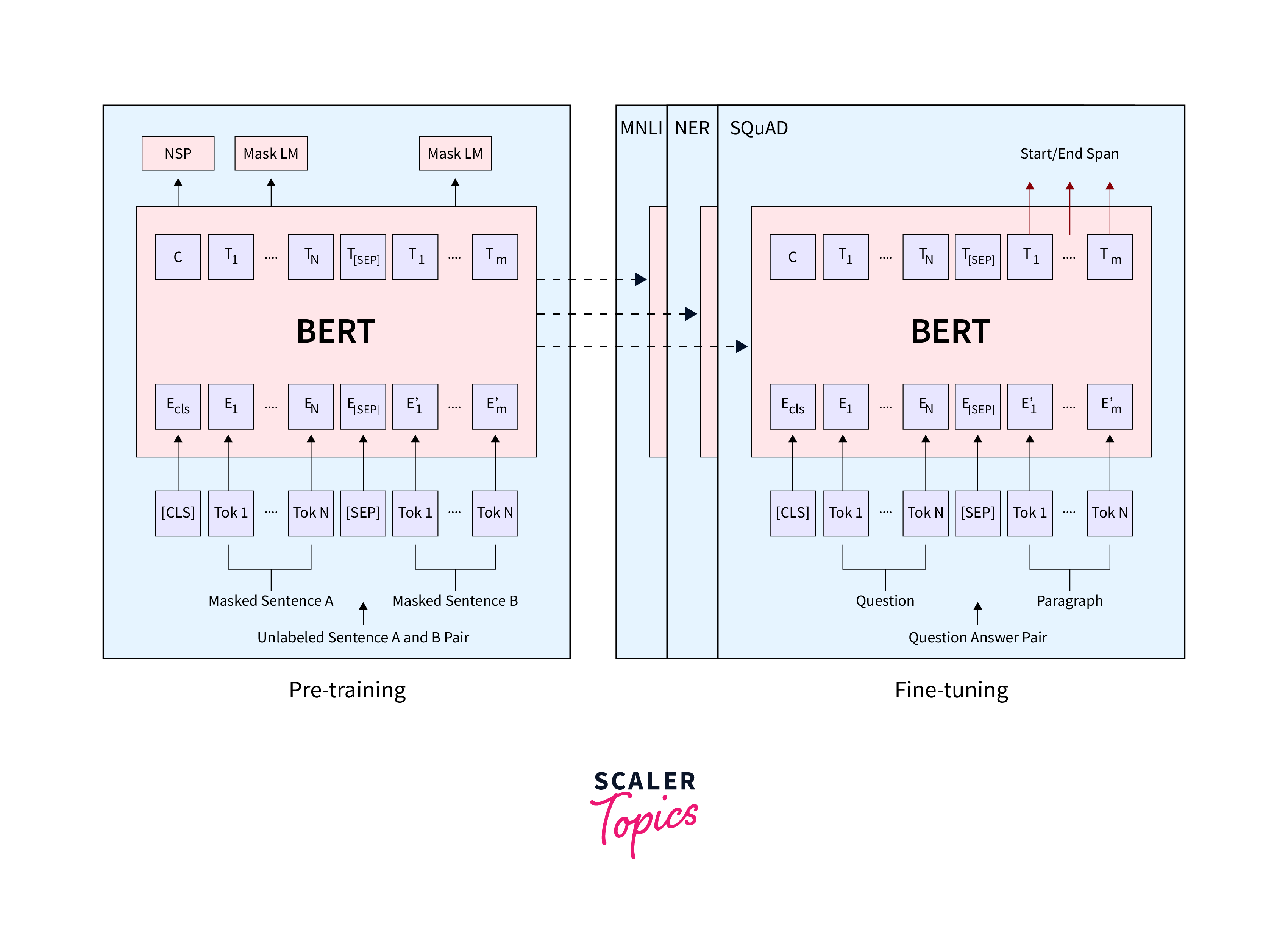
Fine-tuning BERT is a critical step that adapts the pretrained model to perform specific tasks. This process involves initializing BERT with pretrained weights and then training it on task-specific data. Let's explore the steps involved in fine-tuning BERT :
- Step 1: Before fine-tuning, BERT is pretrained on a large corpus of text data to learn general language representations. Fine-tuning leverages this pretrained knowledge and adapts it to the target task.
- Step 2: Select a dataset corresponding to your target NLP task, such as sentiment analysis, question answering, or text classification. This dataset should be labelled and aligned with the task's requirements.
- Step 3: Add a classification layer on top of BERT's architecture for classification tasks. The output of this layer will be used to make predictions based on the task.
- Step 4: Fine-tune the entire BERT model on your task-specific dataset. Use gradient-based optimization techniques like Adam to update the model's weights during training.
- Step 5: Evaluate the fine-tuned model's performance on a validation dataset. Adjust hyperparameters and experiment with different strategies if needed to improve performance
BERT for Text Classification using TensorFlow
Text classification is a natural language processing (NLP) task that involves categorizing text documents or pieces of text into predefined classes or categories. Text classification aims to automatically assign labels to text data based on its content, enabling computers to understand and organize large amounts of textual information.
Now we’re going to jump to the implementation part where we will classify text using BERT.
-
Step 1: Import Libraries: Import necessary libraries for the task, including TensorFlow,Tensorflow Hub,Tensorflow Text.
-
Step 2: Load and Preprocessing the Data: Here I have a CSV file with data that includes Category(Spam or Ham),Message,Spam(0 or 1). Load that CSV file using pandas pd.read_csv.Split the data into training and test data set using train_test_split.
-
Step 3: Import BERT and Define the Model: Now lets import BERT model ,get embeding vectors. Then build and train a model using model.fit()
Output:
-
Step 4: Evaluate the model: Now lets evaluate the model that we build using the test split.
Output:
BERT for Named Entity Recognition (NER) using TensorFlow
Named Entity Recognition (NER) is a sub-field of natural language processing (NLP) that involves identifying and classifying entities within a text into predefined categories such as names of persons, organizations, locations, dates, and more. The primary goal of NER is to extract structured information from unstructured text data and assign labels to specific entities, making it easier for computers to understand and organize the information.
The below is the implementation part where we will perform Named Entity Recognition (NER) using BERT.
-
Step 1: Import Necessary libraries including tensorflow,transformers and load the data.
-
Step 2: Tokenize the sentence and predict the pretrained model using tokenizer.encode(sentence, return_tensors="tf") and tf.argmax(outputs).
-
Step 3: After predicting the model(encoding) now lets decode the model using tokenizer.batch_decode(predictions[0]).
-
Step 4: The decoded tokens are combined with prediction, its time to extract named entities.
Output:
BERT for Language Translation using TensorFlow
Using BERT for language translation is not the most common or straightforward approach, as BERT is primarily designed for tasks like sentence classification, named entity recognition, and similar tasks, rather than sequence-to-sequence tasks like language translation.
-
Step 1: Import Libraries (Tensorflow,BertTokenizer) and Load the model and Data (input_text)
-
Step 2: After loading the model and data, let's tokenize the data and Predict it using our loaded model.
-
Step 3: After encoding the data using the bert model let's decode predictions using tokenizer.decode().
Output:
Conclusion
- BERT, powered by its bidirectional Transformer architecture, has brought about a paradigm shift in the field of Natural Language Processing (NLP).
- Pretraining BERT on vast text corpora equips it with a deep understanding of contextual relationships within language.
- In text classification, BERT's prowess is harnessed by adding a classification layer on top of its architecture, enabling accurate predictions.
- For Named Entity Recognition (NER), BERT's sequence labelling capabilities are leveraged to identify and label entities within the text.
- In the realm of language translation, BERT's encoder serves as a foundation for translation models, enhancing translation quality.