Deploying TF model with FastAPI
Overview
The deployment of a TensorFlow model using FastAPI is explained in detail in this article. It addresses setting up a Tensorflow FastAPI project, developing an API endpoint for model inference, handling request and response formats, enhancing performance and scalability, testing, and monitoring the deployed model, as well as putting the model through its final stages before deployment. A summary of the method is provided in the article's conclusion.
Introduction
In today's world of web development, deploying machine learning models as API endpoints has become increasingly important. This allows applications to leverage the power of machine learning for real-time predictions and integrations with other systems. FastAPI, a modern Python web framework, offers an efficient and straightforward solution for deploying TensorFlow models as API endpoints.

Whether you are a web developer or a machine learning expert, this article will give you useful tips and a step-by-step tutorial for deploying TensorFlow models using FastAPI. Let's investigate the potent synergy of TensorFlow FastAPI for deploying machine learning models as API endpoints.
What is FastAPI?
A contemporary and speedy web framework for creating Python APIs is FastAPI. Its outstanding speed, ease of use, and potent features have helped it become quite popular among web developers. FastAPI has exceptional performance and scalability since it is based on the ASGI (Asynchronous Server Gateway Interface) standard, which enables it to handle requests asynchronously.
![fastapi]
FastAPI supports various data formats, including JSON, form data, and multipart files, making it versatile and flexible for handling different types of requests. It provides automatic data validation, serialization, and deserialization, reducing the amount of boilerplate code typically required in API development.
Prepare the TensorFlow Model for Deployment
Before deploying a TensorFlow Fastapi model, it is essential to prepare it for deployment by following these steps:
Train and Optimize the Model: Use TensorFlow's APIs to train and optimize your model. This involves defining the model architecture, selecting suitable loss functions and optimizers, and fine-tuning hyperparameters. Train the model on a representative dataset until it achieves satisfactory performance and accuracy.

Save the Trained Model: Use the tf.saved_model.save() function to save the model to disk. This will create a directory containing the model's architecture, variables, and assets.
Convert the Model (Optional): Depending on the deployment scenario, you may need to convert the model to a more optimized format. For example, if you plan to deploy the model on mobile or edge devices, you can use TensorFlow Lite to convert the SavedModel to a TensorFlow Lite model. The conversion process may involve quantization or other optimizations for better performance on resource-constrained devices.
Test the Saved Model: Load the saved model using the tf.saved_model.load() function and run inference on sample data to verify that the model produces the expected results. This step helps catch any issues with the saved model before deployment.
Output:
Set Up a FastAPI Project
Create a New Project Directory: Start by creating a new directory for your FastAPI project. Choose a suitable location on your system.
Install FastAPI and Additional Dependencies: Install FastAPI and other required packages using pip:
Create the FastAPI App File: Create a new Python file, such as main.py, in your project directory. This file will contain the FastAPI application code.
Write the FastAPI Application Code: Open the main.py file in a text editor and write the code for your FastAPI application. Start by importing the necessary modules:
Run the FastAPI Application: Start the FastAPI application using Uvicorn by executing the following command in your project directory:

Build an API Endpoint for Model Inference
Using Pydantic's BaseModel, we define the InputData class to capture the anticipated format of the input data for the tensorflow fastapi model. Using tf.keras.models.load_model, we load the TensorFlow model that has been trained. The POST request for the API endpoint /predict is defined and requires JSON data in the InputData class's format. The loaded model is used to make inferences after receiving the input features from the request and converting them to a numpy array. The response then contains the predicted value.
Please note that you may need to install the required dependencies, such as tensorflow and fastapi, before running this code.
main.py
Handle Request and Response Formats
When building a Tensorflow FastAPI application, handling different request and response formats is crucial for interoperability with clients. FastAPI provides built-in support for various formats, including JSON, form data, and multipart files.
The API endpoint /predict already appropriately handles the various request and response types. It is planned for the input data to be sent as a JSON object in the request body, and the JSONResponse class from Tensorflow FastAPI is used to return the response as a JSON object.
Request Format:
- The endpoint is defined as a POST request using the @app.post("/predict") decorator.
- The input data is received in the request body as a JSON object.
- The input data is validated against the InputData model, which ensures that the required fields (sepal_width, sepal_length, petal_length, petal_width) are present and have the correct data type.
- FastAPI automatically converts the request body JSON into an instance of the InputData model.
Response Format:
- The tensorflow fastapi model inference is performed using the loaded TensorFlow model and the input data.
- The predicted class index is obtained using np.argmax(predictions, axis=1)[0].
- The predicted class index is mapped to the corresponding class label using the class_labels list.
- The predicted class index is converted to a Python integer.
- The response JSON object is created with the predicted class and label.
- The response is returned using the JSONResponse class, which sets the appropriate content type and returns the JSON object as the response body.
The below mentioned code will send a POST request to the specified URL with the input data as JSON in the request body. The response content will be printed to the console. Make sure your local server is running and accessible at http://127.0.0.1:8000/predict for this code to work.
request.py
![request]
Performance Optimization and Scalability
Performance optimization and scalability are important considerations when building an API for model inference. Here are some approaches to improve performance and scalability:
Model Optimization:
Optimize your Tensorflow fastapi model to reduce inference time and memory usage. Techniques like model quantization, pruning, and model compression can help achieve this.
Batch Processing:
Instead of making individual predictions for each request, batch multiple requests together and process them in parallel. This reduces overhead and improves efficiency, especially when dealing with multiple concurrent requests.
Asynchronous Processing: To process several requests concurrently, use asynchronous programming techniques. By handling more requests concurrently, this enhances throughput and responsiveness on the server.
Optimize.py
request.py

Test and Monitor the Deployed Model
Testing and monitoring a deployed model is crucial to ensure its performance, reliability, and accuracy. Here are some steps you can follow to test and monitor your deployed model:
Unit Testing: Write unit tests to verify the functionality of individual components of your code, such as data preprocessing, model inference, and response handling. Use testing frameworks like pytest or unittest to create test cases and run them to validate the behavior of your code.
Integration Testing: Perform integration tests to check the interaction between different components of your application, such as the API endpoint, data serialization, and model serving. Test various scenarios, including valid and invalid input data, to ensure that your application handles them correctly.
Benchmarking: Measure the performance of your tensorflow fastapi model by running benchmarks to assess its inference speed and resource utilization. This helps identify any bottlenecks or areas for optimization. Tools like ab (Apache Benchmark) or wrk can be used to simulate multiple concurrent requests and measure response times.
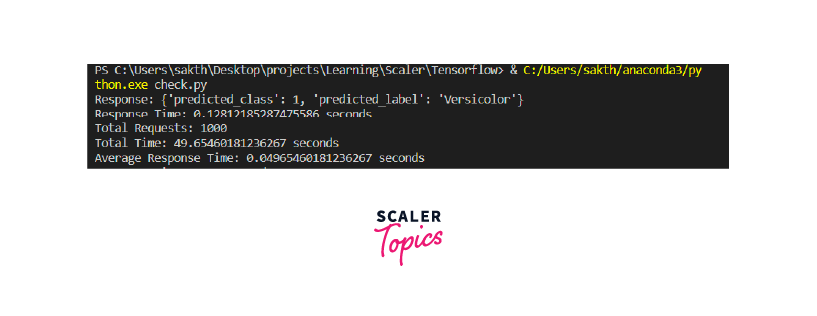
We have a test_model function that sends a POST request to the deployed model's endpoint and returns the response as JSON. We use this function to test the model's performance by measuring response time for a single request and perform load testing to simulate high request loads.
The code also demonstrates how you can monitor the model by periodically testing it and logging relevant metrics.
Conclusion
- FastAPI is a powerful framework for building APIs, providing high performance and scalability.
- When building an API for TensorFlow fastapi model inference, it is important to handle request and response formats appropriately.
- Loading the trained TensorFlow fastapi model into memory allows for efficient model inference during API requests.
- Testing the deployed model and monitoring its performance are crucial for ensuring reliability.