TensorFlow Federated Learning
Overview
In the era of data-driven decision-making, machine learning has become a pivotal technology in various domains. Traditional centralized machine learning methods rely on collecting data from different sources, centralizing it on a server, and training a global model. However, this approach raises privacy, security, and scalability concerns. Federated Learning (FL) emerges as a groundbreaking paradigm that addresses these challenges by enabling decentralized training while preserving data privacy. This article provides an in-depth exploration of Tensorflow Federated Learning, its architecture, working principles, advantages, limitations, applications, frameworks, privacy, and future trends.

What is Traditional Centralized Learning?
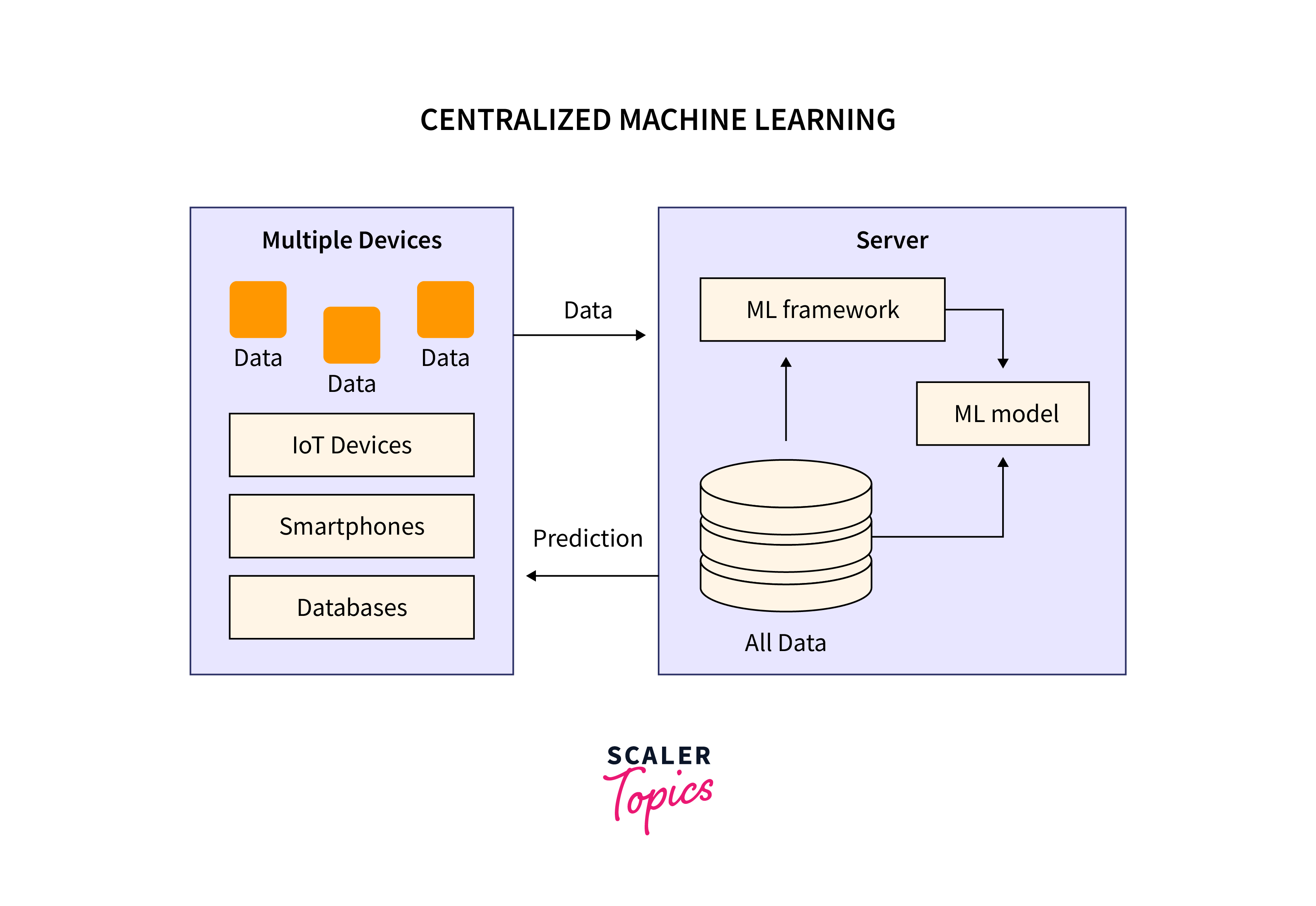
Traditional Centralized Learning is the conventional approach to machine learning, where data from multiple sources is collected, centralized, and processed on a central server to train a global model. In this setup, the central server is the data aggregation and model training hub, while the individual devices or clients act as passive data sources.
The process of traditional centralized learning can be summarized as follows:
1. Data Collection:
Data is gathered from various devices, users, or sources and sent to a central server. This data may include images, text, numerical values, or any other input relevant to the machine learning task.
2. Data Centralization:
The collected data is stored and aggregated on a central server. This data centralisation facilitates training a single, global model using all the available data.
3. Model Training:
Once the data is aggregated on the central server, a machine learning model is trained using the entire dataset. This process often uses common algorithms like deep neural networks, decision trees, or support vector machines.
4. Model Deployment:
After training, the global model is deployed to the central server, making it available for making predictions or classifying new data points.
What is Federated Learning?
Federated Learning is a decentralized machine learning approach allowing multiple devices or clients to train a shared model collaboratively without sharing their raw data with a central server. In this paradigm, the learning process occurs locally on individual devices, and only model updates are communicated back to the central server for aggregation. This unique approach overcomes the limitations of traditional centralized learning, particularly in terms of data privacy, communication overhead, and scalability.
Federated Learning Architecture
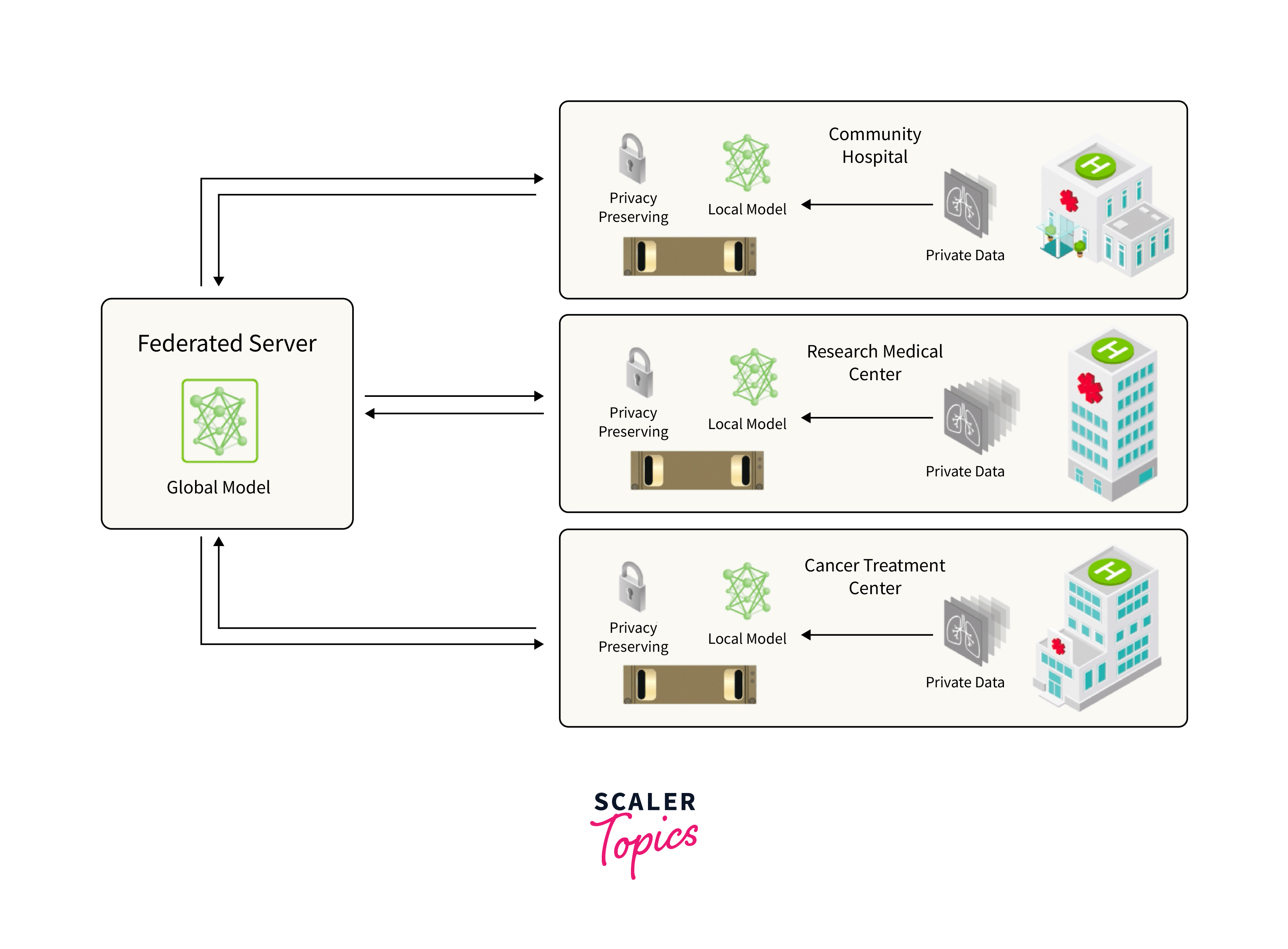
Federated Learning (FL) architecture is a decentralized machine learning approach where multiple devices or clients collaboratively train a shared model without sharing their raw data with a central server. The architecture comprises three key components: clients, a central server, and a communication interface.
- Clients (Devices/Nodes):
Clients are individual devices, such as smartphones, IoT devices, or edge servers, which hold their local datasets. During the FL process, clients perform local model training using a global model sent by the central server during initialization. Model updates from local training are sent back to the server for aggregation. - Central Server:
The central server initializes the global model and distributes it to all clients. After receiving model updates from clients, it aggregates them using techniques like Federated Averaging. The updated global model is then redistributed to clients for the next round of training. - Communication Interface:
The communication interface ensures the secure transmission of model updates between clients and the server. It employs cryptographic techniques like Secure Multi-Party Computation (SMPC) to protect data privacy during communication.
How Federated Learning Works?
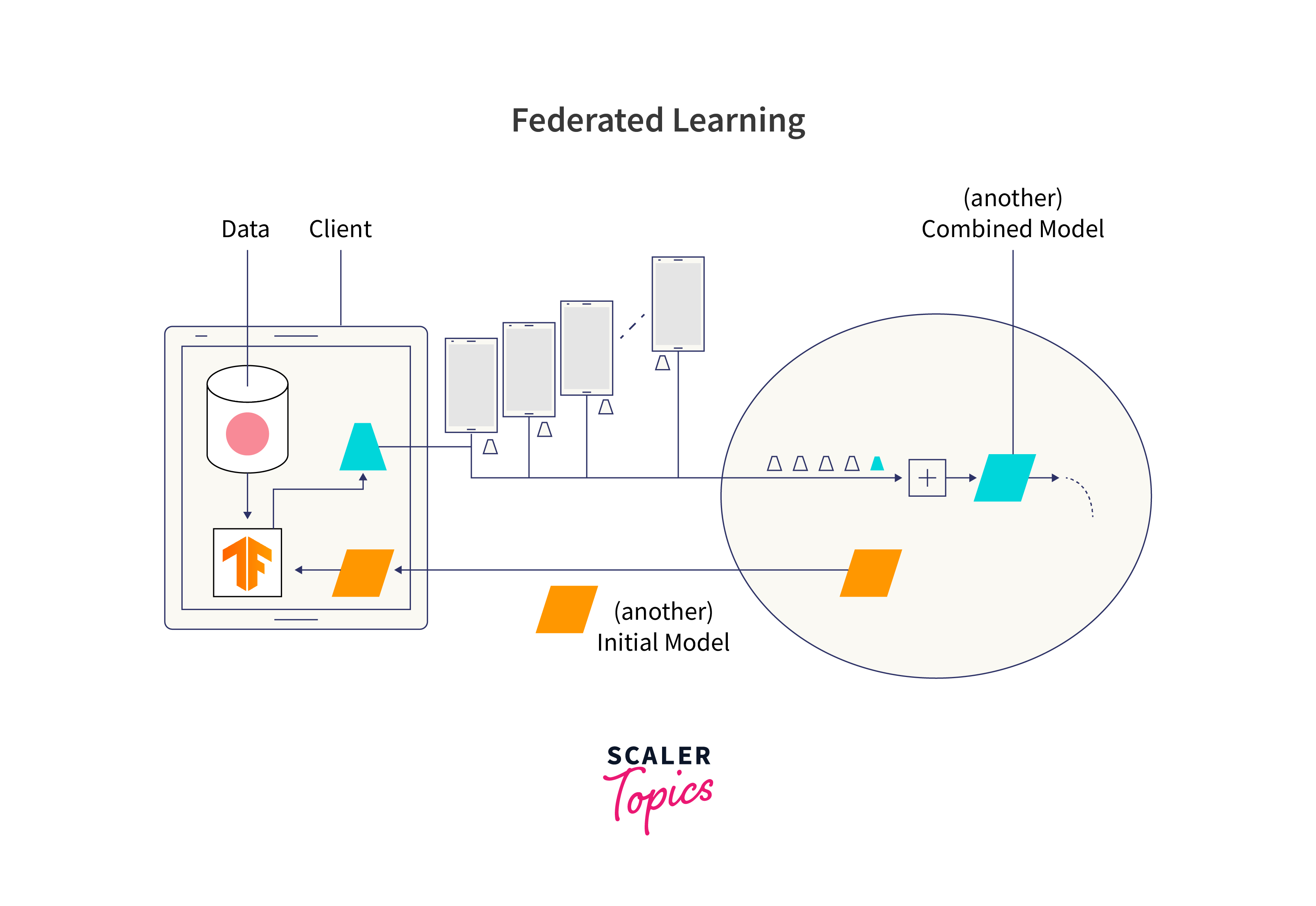
The process begins with the central server initializing a global model distributed to all clients. Each client performs local training using its data and the global model, generating model updates without transmitting raw data. These updates are securely sent to the central server, which aggregates them to improve the global model. The updated model is redistributed to clients, and the process iterates until convergence.
- Initialization:
The FL process begins with the central server initializing a global model. This global model serves as the starting point for local training on individual clients. The server then distributes the global model to all participating clients. - Local Training:
Each client performs local model training using its own local dataset and the global model received from the central server. The training process may involve multiple iterations or epochs, depending on the complexity of the model and the data available to the client. - Model Update:
After local training, each client generates a model update containing the changes made to the global model during its training process. Importantly, the raw data itself is not transmitted to the central server or shared with other clients, ensuring data privacy. - Aggregation:
The model updates from multiple clients are securely sent to the central server, where they are aggregated using techniques such as Federated Averaging. This ensures that the updates from different clients are combined in a coordinated manner to improve the global model without accessing individual client data. - Global Model Update:
Once the aggregation is complete, the central server obtains an updated global model. This updated model incorporates the knowledge gained from all participating clients local models. - Iteration:
The process of local training, model update, aggregation, and global model update iterates for multiple rounds. In each round, the clients improve their local models based on the updated global model, and the process continues until the global model converges to a satisfactory level of accuracy.
Federated Learning with TensorFlow Federated (TFF)
TensorFlow Federated (TFF) is an open-source framework developed by Google's TensorFlow team that simplifies the implementation of Federated Learning (FL) algorithms. TFF extends the capabilities of TensorFlow to support distributed training across multiple devices while ensuring data privacy and security.
-
Import required libraries:
Import the necessary libraries for the Tensorflow Federated Learning implementation. TensorFlow is used for building and training the model, while TensorFlow Federated Learning (TFF) provides the tools for Federated Learning. -
FL model architecture:
- Define the FL model architecture using TensorFlow's Keras API. The model is a simple convolutional neural network (CNN) with two layers. It takes input images of size (28, 28, 1).
- The create_federated_model_fn function returns the federated model that TFF can work with. The tff.learning.from_keras_model function wraps the model into a federated learning format, and input_spec specifies the input shape and data type of the model.
-
Loading and Preprocessing the dataset:
The preprocess function prepares the dataset for Tensorflow Federated Learning. It takes the dataset as input and preprocesses it by expanding the image dimensions
- Perform Federated Learning:
The tff.learning.build_federated_averaging_process function creates a Federated Averaging algorithm. It takes the create_federated_model_fn function to specify the model architecture.
- Test the federated model:
Tests the final Tensorflow Federated Learning model on a test dataset (emnist_test). The tff.learning.build_federated_evaluation function creates an evaluation function for the federated model.
Output:
Advantages of Federated Learning
Federated Learning (FL) offers several advantages over traditional centralized machine learning approaches, making it a powerful and promising technique for various applications. Here are the key advantages of Federated Learning:
- Data Privacy and Security:
FL allows model training to be performed directly on individual devices (clients) without sharing raw data with a central server. This decentralized approach ensures that sensitive user data remains on the client devices, reducing the risk of data breaches and preserving data privacy and security. - Reduced Communication Costs:
In FL, only model updates, rather than raw data, are transmitted between clients and the central server. This significantly reduces the communication overhead, making it more efficient, especially in scenarios where network bandwidth is limited. - Decentralization:
FL leverages the power of decentralized computing. The model training occurs on individual devices, enabling distributed learning and reducing the reliance on a central data server or data center. - Personalization:
With FL, models can be personalized for each individual device or client. This allows for more tailored and relevant experiences for users, even in the presence of diverse data and preferences.
Challenges and Limitations of Federated Learning
While Federated Learning (FL) offers significant advantages, it also faces several challenges and limitations that need to be addressed for its widespread adoption and effectiveness. Here are the key challenges and limitations of Federated Learning:
- Heterogeneity:
Client devices in Tensorflow Federated Learning often have varying hardware capabilities, network conditions, and data distributions. Handling this heterogeneity while aggregating model updates can lead to biased or suboptimal global models. - Communication Efficiency:
Communication between clients and the central server can be a bottleneck in FL, especially for devices with limited bandwidth or unreliable connections. Efficient communication protocols are required to minimize communication costs. - Security Risks:
FL introduces new security challenges, including potential model poisoning attacks, where malicious clients intentionally send adversarial model updates to compromise the global model. - Bias and Fairness:
The distributed nature of FL can lead to biased global models if certain client groups are underrepresented in the training process. Ensuring fairness and mitigating biases require careful algorithm design and data sampling techniques. - Model Convergence:
FL's asynchronous and decentralized training can lead to slower model convergence compared to traditional centralized learning. Designing efficient and effective aggregation methods is crucial to overcome this limitation.
Applications of Federated Learning
Federated Learning (FL) has gained significant attention due to its ability to address data privacy concerns while enabling collaborative model training. It finds applications in various domains and industries where data is distributed across multiple devices or clients. Here are some key applications of Federated Learning:
- Healthcare:
FL is well-suited for healthcare applications, where data privacy is crucial. Hospitals, clinics, and wearable devices can collaborate to train predictive models for disease diagnosis, personalized treatment recommendations, and monitoring patient health while keeping patient data on the respective devices. - Internet of Things (IoT):
In IoT environments, Tensorflow Federated Learning allows connected devices to collaboratively learn from their data without sending sensitive information to a central server. This enables smart devices, such as smart homes, smart cities, and industrial IoT devices, to learn and improve their functionalities locally. - Personalized Services:
FL enables providers to deliver personalized experiences without compromising user data privacy. It can be applied in personalized search, content recommendation, and targeted advertising while ensuring user data remains on user devices. - Financial Services:
Financial institutions can use FL for fraud detection, risk assessment, and customer behaviour analysis. FL allows banks and financial firms to collaborate on model training without sharing sensitive customer financial data. - Autonomous Vehicles:
FL can be employed for training models in autonomous vehicles. Cars can share insights on road conditions, traffic patterns, and weather without transmitting individual data, leading to safer and more efficient self-driving cars.
Federated Learning Frameworks and Tools
Several frameworks and tools have been developed to facilitate the implementation of Federated Learning (FL) algorithms and enable developers to build privacy-preserving, decentralized machine learning models. These FL frameworks provide a range of functionalities, including federated computation, model aggregation, privacy-preserving techniques, and integration with existing machine learning libraries. Here are some popular Federated Learning frameworks and tools:
- TensorFlow Federated (TFF):
Tensorflow Federated Learning developed by Google's TensorFlow team, is an open-source framework that extends TensorFlow to support distributed training across multiple devices. TFF provides APIs for federated computation, federated data representation, and aggregation methods. It includes pre-implemented FL algorithms like Federated Averaging and supports privacy techniques like Differential Privacy. - PySyft:
PySyft is an open-source Python library built on top of PyTorch that enables privacy-preserving Federated Learning. It implements Secure Multi-Party Computation (SMPC) and Differential Privacy to protect data privacy during model training. PySyft allows users to create federated datasets, models, and computations for FL. - Flower:
Flower (Federated Learning OrganizatiOn arChitecture) is an open-source framework that provides an end-to-end implementation of FL. It is designed to work with multiple deep learning frameworks like TensorFlow, PyTorch, and Keras. Flower supports various FL algorithms, communication protocols, and privacy techniques. - Microsoft Federated Learning (MFL):
Microsoft Federated Learning is a FL framework developed by Microsoft. It allows to train machine learning models across multiple devices while ensuring data privacy. MFL supports various model aggregation methods, secure communication, and differentially private aggregation.
Privacy and Security Considerations in Federated Learning
Privacy and security considerations are of paramount importance in Federated Learning (FL) to ensure that sensitive user data remains protected during the model training process. Tensorflow Federated Learning introduces unique challenges due to its decentralized nature, where data is distributed across multiple devices or clients. Here are the key privacy and security considerations in Federated Learning:
- Data Privacy:
The primary concern in FL is preserving data privacy. Client devices hold sensitive user data, and it is essential to prevent raw data from being shared with the central server or other clients. Techniques like Federated Averaging and Secure Aggregation ensure that model updates, rather than raw data, are transmitted to the central server. - Differential Privacy:
Differential Privacy is a technique used to add noise to the model updates, making it challenging to identify specific user data. This ensures that the global model does not learn information specific to any individual client. - Secure Aggregation:
Secure Aggregation methods, such as Secure Multi-Party Computation (SMPC), allow model updates to be aggregated without revealing individual contributions. This protects against adversaries attempting to extract sensitive information from the model updates. - Model Poisoning Attacks:
FL is susceptible to model poisoning attacks, where malicious clients deliberately send manipulated model updates to compromise the global model. Robust aggregation techniques and client validation mechanisms are necessary to detect and mitigate such attacks. - Federated Learning Server Security:
The central server plays a crucial role in FL. It must be protected against unauthorized access and security breaches to safeguard model updates and prevent adversaries from tampering with the global model.
Future Trends and Research in Federated Learning
Tensorflow Federated Learning (FL) is a rapidly evolving field with significant potential for the future of decentralized, privacy-preserving machine learning. Several trends and areas of research are emerging to further enhance the efficiency, scalability, and security of FL. Here are some key future trends and research directions in Federated Learning:
- Privacy-Preserving Techniques:
Research in advanced privacy-preserving techniques, such as Fully Homomorphic Encryption (FHE) and Secure Multi-Party Computation (SMPC), will continue to grow. These techniques enable FL without exposing raw data or sensitive model updates, providing stronger privacy guarantees. - Differential Privacy and Federated Learning:
Combining differential privacy with FL to achieve better privacy guarantees while maintaining model accuracy is an active area of research. Optimizing the trade-off between privacy and utility remains a key challenge. - Fairness and Bias Mitigation:
Addressing bias and ensuring fairness in FL models will be a significant focus. The research will explore techniques to mitigate bias and ensure equitable model performance across different user groups. - Heterogeneous Federated Learning:
Future research will aim to improve FL model performance in heterogeneous environments where clients have diverse data distributions, hardware capabilities, and network conditions. - Secure Aggregation:
Advancements in secure aggregation methods will enhance the efficiency and security of FL. Developing more efficient cryptographic algorithms for secure aggregation will be crucial for large-scale FL deployments.
Conclusion
- Tensorflow Federated Learning (FL) is a decentralized machine learning approach that allows multiple devices or clients to collaboratively train a shared model without sharing raw data with a central server.
- FL preserves data privacy by keeping sensitive information on individual devices, reducing the risk of data breaches and ensuring regulatory compliance.
- Advantages of FL include reduced communication costs, personalized models, data diversity, and scalability, making it suitable for applications in healthcare, IoT, finance, and more.
- Tensorflow Federated Learning faces challenges such as heterogeneity, model convergence, security risks, and bias mitigation, requiring ongoing research and improvements to address these limitations.